Modelling: movement through logistics network
74 views
Skip to first unread message

ma...@maritimedatasystems.com
Feb 16, 2015, 6:54:35 AM2/16/15
to ne...@googlegroups.com
I need some modelling advice.
We want to ask which truck has ever moved from location A to location B and what was the sequence of intermediate stops they made to get there.
In a later stage we also want to be able to ask this question if there is no truck that has stopped at location A and B. Which trucks and which sequence of stops would we have needed to get from A to B.
Right now we modeled all locations as nodes and every trip a truck has ever made as a separate edge. The edges are attributed with a truck ID and a sequence number.
We wrote our custom expander class to be used with the traversal framework and to take care of the sequence numbers and truck IDs to only get complete sequences for individual trucks.
However, this performs very badly.
Right now we have 300 locations/nodes and 300.000 trips/edges. Some stops have 20.000 outgoing trips that we are checking for truck ID and sequence number (for every outgoing relationship, get attributes and check) .
This performs too badly. 13 seconds for 900 sequences.
Finally, we want to try to scale it to 3000 locations and 20.000.000 trips.
Do you have any alternative modelling ideas?
Thanks a lot already.
ps: I was thinking of storing every trucks list as a long linear sequence of stops/nodes. The nodes are additionally linked to some identifier Node through a type of is relation: "stop x is location A".

Michael Hunger
Feb 18, 2015, 4:07:59 AM2/18/15
to ne...@googlegroups.com
Perhaps you can share some of your Expander code?
Not really sure between what your edges are?
Two ideas:
1) How many trucks do you have? Perhaps it makes sense to encode the truck-id as relationship-type? So you have fewer rels to check and can benefit from the separated storage by rel-type and direction.
2) Model the trip as a node connected to a truck, and all locations it visited (perhaps/optionally even encode the location-id as rel-id but that might be overkill) so you can quickly find all that started at "A" and then check if the trip has a rel to "B"
3) Another more verbose approach be to model each trip as a sequence of nodes (which are shadow nodes of the locations), connect the start-node of the trip to the truck (optionally all trip-nodes of the trip to the truck). And then have a relationship to each stop of the trip.
I'd probably go with model #2
HTH Michael
--
You received this message because you are subscribed to the Google Groups "Neo4j" group.
To unsubscribe from this group and stop receiving emails from it, send an email to neo4j+un...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
ma...@maritimedatasystems.com
Feb 18, 2015, 5:02:53 AM2/18/15
to ne...@googlegroups.com
Thanks, Michael.
I will end up with 50.000 trucks.
public Iterable expand(Path path, BranchState state) { // for the start node return all outgoing connections if (path.length() < 1){ return path.endNode().getRelationships(Direction.OUTGOING); } else { // for all consecutive nodes only return relations with same ID and with the next sequence number
// get previuos sequence Integer seq = (Integer)path.lastRelationship().getProperty(SEQUENCE); // increase the sequence by one to find the next sequence Integer nextSeq = seq+1;
// get ID Object lastID = path.lastRelationship().getProperty(ID);
ArrayList<Relationship> result = new ArrayList<>();
// get all outgoing rleationsships for end node Iterable<Relationship> trips = path.endNode().getRelationships(Direction.OUTGOING, TRIP); for (Relationship trip : trips) { // only return is ID is equal and sequence is the next sequence if (lastID.equals(rel.getProperty(ID, null))){ if (nextSeq.equals((Integer)rel.getProperty(SEQUENCE, null))){ result.add(rel); } }
return result;
}}The while loop over all relations is definitely sub-optimal. Just yesterday I discovered the legacy indexes for relations. I am going to give them a try. They seem to be a perfect fit. Can I query the index with multiple fields?
I have also already been using the ID as relationship type with great improvements.
I have also thought ow would this be
Thanks for the option 2. Might be worth a try!
Is Cypher in general behaving better than Java code? Or is the trick in using as much indexes as possible?
Patrick
Patrick Mast
Feb 18, 2015, 8:21:07 AM2/18/15
to ne...@googlegroups.com
Have a new Expander which greatly improves the performance:
public Iterable expand(Path path, BranchState state) { Node end = path.endNode(); // return all at the first step if (path.length() < 1){ return end.getRelationships(Direction.OUTGOING); } else { // for all others get the next step from the index relIx Relationship endRel = path.lastRelationship(); Integer lastSeq= (Integer)endRel.getProperty(SEQUENCE) + 1; Object lastID = endRel.getProperty(ID); String id_seq = lastID + "_" + lastSeq;
IndexHits<Relationship> rels = relIx.get("id_seq", imo_seq, end, null); return (Iterable) rels.iterator(); }}Now I have ~2.000.000 relations/trips, ~1.200 nodes/locations, for ~6.000 trucks and I get 5.000 results from A to B within 12 seconds on my development machine.
Michael Hunger
Feb 18, 2015, 11:07:20 AM2/18/15
to ne...@googlegroups.com
50k trucks are not an issue
Rel-indexes are legacy and only used when you really need them
The tricks is not to use more indexes but a graph model that supports your queries
M
Von meinem iPhone gesendet
Von meinem iPhone gesendet

Stefan Armbruster
Feb 18, 2015, 11:10:53 AM2/18/15
to ne...@googlegroups.com
Following up on modelling approach 1) Michael sketched previously:
With 50k trucks using a separate relationship type per truck is a bad
idea since atm Neo4j supports 65k different relationship types.
Just as a stupid idea to discuss:
* how about using 10k relationships types for all the trucks?
TRUCK_ROUTE_0001 to TRUCK_ROUTE_9999. Each individual truck is mapped
to a rel type using a modulo operation on it's identifier (think of
consistent hashing). On average one rel type is shared between 5
trucks.
* a traversal for a specific truck then need to follow just one out of
10k relationship types. Of course you still need to inspect the
relationship property to decide which of the 5 trucks it is, but it
should be faster than using the same reltype for all trucks.
/Stefan
With 50k trucks using a separate relationship type per truck is a bad
idea since atm Neo4j supports 65k different relationship types.
Just as a stupid idea to discuss:
* how about using 10k relationships types for all the trucks?
TRUCK_ROUTE_0001 to TRUCK_ROUTE_9999. Each individual truck is mapped
to a rel type using a modulo operation on it's identifier (think of
consistent hashing). On average one rel type is shared between 5
trucks.
* a traversal for a specific truck then need to follow just one out of
10k relationship types. Of course you still need to inspect the
relationship property to decide which of the 5 trucks it is, but it
should be faster than using the same reltype for all trucks.
/Stefan
Patrick Mast
Feb 25, 2015, 6:09:57 AM2/25/15
to ne...@googlegroups.com
I have been playing with the different relation ship types. The advantage is that I can select from every node only the edges with a specific type.
When i use the legacy indexes, I am able to do the same with the properties of relationships:
I presume this is the same underlying mechanism than filtering on relationship types.
Patrick Mast
Feb 25, 2015, 6:30:34 AM2/25/15
to ne...@googlegroups.com
I have modeled the problem in alternative way, like suggested by Michael. This are trips for the Truck 'Meyer'.
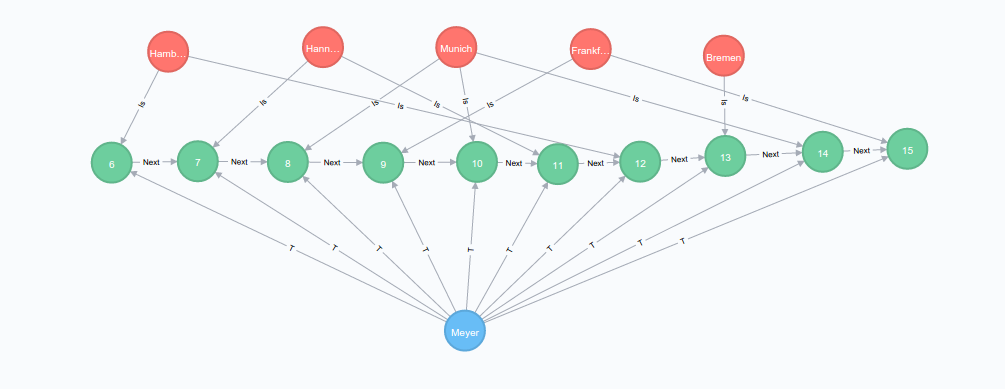
How ever while playing with it, I am facing some problems:
I want to know all trips from Hamburg to Munich. And I want to get the sequence of city names for these trips. And I want only direct trips (ever stop should occur only once).
I did not mange to 'join in' the city names so I stored the city names as properties on the sequence nodes. With that I ended up with this query:
However performance wise, I do not get big advantages above my optimized other approach.
Any tips?
Here is the a link to the console populated with the test graph: http://console.neo4j.org/r/yv6ex1

Andrii Stesin
Feb 27, 2015, 9:36:01 AM2/27/15
to ne...@googlegroups.com
What I'd do for this task. In fact we have a three dimensional model:
1 time (you omitted it completely, and I'm perfectly sure that business will be interested in this dimension!) modelled as a tree of nodes, probably granularity level of days is sufficient? or maybe hours?
2 locations
3 trips (not trucks)
Truck is a root of a "brush" of trips which are directed linked lists of events in time, each trip starts with departure event, each stop is 2 events (arrival and departure), trip ends with arrival event. Doing stats per truck won't be too big a problem because trips are (comparatively) short, maybe 1-2 dozens of stops.
Each event has relationship to one calendar :Day node with exact event timestamp stored in the property. (So you will ask, If we go this way, do we need to store event sequences in trip lists? answer is "yes" and later you may store some useful business data in the properties of relations which link events in pairs).
Also each event has relationship to one location node.
How to cope with 3+ k locations, 50+ k trucks, 20+ millions of trips? The answer again is... time. Code time periods in relationship types, I'd go for a scale of a week. So for a single relationship type you will get 52 new instances per year, say 2 events per truck per day - 700+ k of events per week and 20% (1k) of locations will take 80% (560k) of those, so each week will add some 300 incoming and 300 outgoing relationships per location. Not that big a problem, especially if you decide to create a new node per location each week. Some inconvenience will occur when processing long trips which cross week boundaries, nothing terrific. So consider the following fragment
(city:Location {name: 'Munich'})<-[ra:ARRIVED_AT_2015week4]-(e0:Event:Arrival)-[rb:ARRIVED_ON_2015week4]->(d:Day {printable_date: '2015.01.25'})
(city:Location {name: 'Munich'})-[rc:DEPARTED_AT_2015week5]->(e1:Event:Departure)<-[rd:DEPARTED_ON_2015week5]->(d:Day {printable_date: '2015.01.26'})
(t:Truck {license_plate: 'ABC123'})<-[:TRIP_2015week5]-(e1:Event:Departure)<-[:TRIP_2015week4]-(e0:Event:Arrival) // direction in sequenceAs for your code, am I correct in assumption that you just want to discover all paths between Munich and Hamburg which
a) do not contain circles,
b) were actually implemented in reality at least once.
If yes, and if we want to examine data from all weeks, won't this
MATCH (src:Location {name: 'Munich'})-->(e0:Event:Departure)
WITH e0
MATCH (e1:Event:Arrival)-->(dst:Location {name: 'Hamburg'})
WITH e0, e1 MATCH p = (e0)-[r*1..]->(e1)
WITH DISTINCT p RETURN p ORDER BY LENGTH(p) DESC;
give you what you want?
WBR,
Andrii
Patrick Mast
Mar 2, 2015, 9:23:19 AM3/2/15
to ne...@googlegroups.com
Andrii, thanks.
I do not fully understand why you put the week in the relationship type.
As for your query: it does not prevent circles. Try to find a route from Hamburg to Munich and you will get:
1. Hamburg --> Bremen --> Munich
2. Hamburg --> Hannover --> Munich
3. Hamburg --> Hannover --> Munich --> Frankfurt --> Munich
4. Hamburg --> Hannover --> Munich --> Frankfurt --> Munich --> Hannover --> Hamburg --> Bremen --> Munich
The last two results contain circles.
Andrii Stesin
Mar 11, 2015, 2:11:14 PM3/11/15
to ne...@googlegroups.com
On Monday, March 2, 2015 at 4:23:19 PM UTC+2, Patrick Mast wrote:
I do not fully understand why you put the week in the relationship type.
Speaking of 20+ millions of trips around 3+ thousands of locations, where 20% of locations take 80% of stops (according to Pareto rule, but from my practice, both Pareto and Murphy were optimists; reality often gives us a more harsh form of power distribution, much like 9% vs 91% - but anyway) we end up with 600 "hot" locations taking 16 millions of stops - ~27 k stops per "hot" location. Splitting 27k relationships into "weekly" slices of size ~300 where week is coded in relationship type gives you ability to scan just ~300 relationships for any given week instead of scanning the whole 27k relationships each time. Plain simple. Maybe you just don't bother.
As for your query: it does not prevent circles. Try to find a route from Hamburg to Munich and you will get:
1. Hamburg --> Bremen --> Munich
2. Hamburg --> Hannover --> Munich
3. Hamburg --> Hannover --> Munich --> Frankfurt --> Munich
4. Hamburg --> Hannover --> Munich --> Frankfurt --> Munich --> Hannover --> Hamburg --> Bremen --> Munich
The last two results contain circles.
Hmm, my fault, sorry. I remember that it will avoid running *multiple* circles but won't avoid output of just a single circle. Sorry for that.
Reply all
Reply to author
Forward
0 new messages