YCSB benchmark using MongoDB

Milind Shah
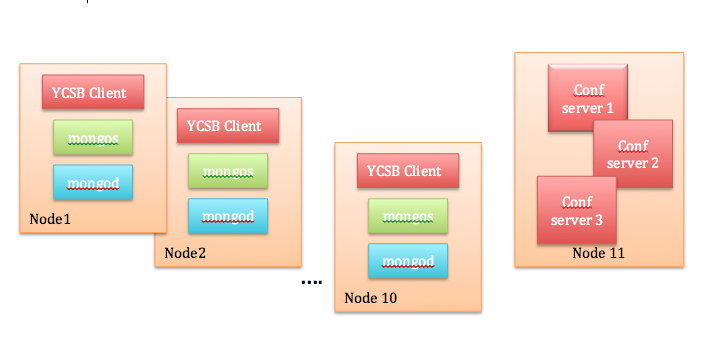
I am currently in a planning phase to run YCSB benchmark on a MongoDB cluster. I have 11 machines to run this benchmark, each with following configurations:
I am thinking about deploying a 10 node sharded MongoDB cluster with replica sets (1 primary, 2 secondary) and planning to keep 1 node for config servers. I am planning to run YCSB workloads in following order:
1) Load 2TB of data, all unique keys.
2) Run zipfian get, read all fields
3) Run range scan
4) Run mixed workload of 95% of get and 5% of update operations
5) Run mixed workload of 50% of get and 50% of update operations.
I am going to use the default 1K row size, with 10 fields/columns with 100 bytes of payload and the sharding will be done based on the key which will be in format user+'long int'.
As per MongoDB documentation, http://docs.mongodb.org/manual/tutorial/deploy-replica-set/ and http://docs.mongodb.org/manual/tutorial/deploy-shard-cluster/, I found that defining replica set and sharding adds a manual overhead during the setup.
I would appreciate if anyone could provide a guidance on what is the best way to setup the MongoDB cluster for this exercise and if you have done similar testing, what type of numbers (throughput/latency) should I expect as an outcome?
Thanks in advance.
Milind

Asya Kamsky
Hi,
Right off I see some general issues with your proposed set-up and some YCSB specific ones.
General: if you have 11 servers and you use all of them for mongod processes where will you run YCSB clients?
And note I say clients because a single YCSB client can't max out a ten shard cluster, you probably want at least 1/2 as many machines driving load as you have primaries/shards, unless the client machines are significantly more powerful than the servers.
As far as YCSB itself, the problem is that this test won't tell you much about how MongoDB would perform for your application unless your application uses exactly this format data (unlikely) and with this access pattern (same) not to mention that range scan isn't really done properly for MongoDB in YCSB (range scans are not normally done on primary keys, but rather secondary keys/indexes which YCSB doesn't test/support).
Asya
--
You received this message because you are subscribed to the Google Groups "mongodb-user"
group.
For other MongoDB technical support options, see: http://www.mongodb.org/about/support/.
---
You received this message because you are subscribed to the Google Groups "mongodb-user" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mongodb-user...@googlegroups.com.
To post to this group, send email to mongod...@googlegroups.com.
Visit this group at http://groups.google.com/group/mongodb-user.
To view this discussion on the web visit https://groups.google.com/d/msgid/mongodb-user/b91dc90c-2192-4f89-bdf8-e4217b30d6da%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

MARK CALLAGHAN
For 9 servers, do you really want only 3 dedicated to serving requests (3 hosts per replica set)? I assume 6 of the 9 would be mostly idle.
To view this discussion on the web visit https://groups.google.com/d/msgid/mongodb-user/CAOe6dJAEdGvBpZ59QfCav4XMOqVJ%2Bp%3DPe3g7Mp19JrCFFNz9Hw%40mail.gmail.com.
Milind Shah
To answer some of Asya's questions:
- I am planning to run 10 YCSB clients on the same data nodes. Previously, I have observed that YCSB clients use 4-6 CPU cores and about 6-8gb memory. Since I have 32 cores and 128gb memory on the machine, I thought running clients on the same machine will not be a problem.
- The goal of the exercise is to compare different NoSQL databases. YCSB might not reflect various application scenarios or the data sizes used in various situations, but it is a common benchmarking tool that works across multiple DBs to compare the same workloads. So the key is to define a valid set of workloads that reflect some of the real world use cases.
To answer Mark's concern:
- Per MongoDB architecture, if I want to have a replica set with 1 primary and 2 secondary, I will need 30 mongod running to achieve 10 replica sets. For that, I could run more than one mongod processes on these 10 nodes and share the resources. I think, that is a bad idea. So, I might have to work with only 3 masters. 6 nodes used for replication will be working on asynchronous replication in the background during the load phase. YCSB's MongoDB client does not use replicas to do get/scan operations. So, those 6 six nodes would be idle during other workloads as well. Should I try to measure performance of the cluster first without worrying about availability? In other words, should I use only sharding and not replication set to measure performance with only 1 master copy of the data?
Thanks,
Milind

Max Schireson
The issue I always had with YCSB is that it tends to be a least common denominator test. Yes, it reflects *some* real world use cases but is systematically excludes those that need secondary indexes which are a critical part of almost any work load and have radically varying performance across platforms. By analogy it is a bit like a drag race, you find out which car is best on a short straight road but you get no data on what happens when the road curves as it almost inevitably does and cars designed without any steering look pretty reasonable on that test.
I think it tells something, but I would strongly suggest supplementing it with some more challenging queries.
-- Max
To view this discussion on the web visit https://groups.google.com/d/msgid/mongodb-user/50856b1a-e1ad-42e9-8475-500eae61394f%40googlegroups.com.
MARK CALLAGHAN
I am curious why you want 2 replicas/master. I have not run YCSB, but with such a setup I would make sure that some reads used secondaries. If you are paying for that extra HW then I would try to make use of it.
To view this discussion on the web visit https://groups.google.com/d/msgid/mongodb-user/50856b1a-e1ad-42e9-8475-500eae61394f%40googlegroups.com.
Milind Shah
I wanted to have 2 replica/master setup to have high availability of data. But since I am more focused on benchmarking and getting the best possible number for YCSB workloads, I am going to run with only shards and do not enable replica set.
@Max
I agree with you. The tool is far from being a perfect benchmarking tool, but at the same time, in absence of generic benchmarking tools, it gets you started. As the user understands the workload and usecase, he would write custom applications to test out the database in later stages.
I have few more open questions:
1) How do I assign amount of memory to mongod process? Would it be able to use available memory on the machine efficiently?
2) How many mongos processes do I need?
3) While defining shards, I am thinking about using index+hashing for shards on _id field which YCSB generates uniquely for each row during load phase, and the distribution of the key is fairly even, too. Is this a good idea or not?
Thanks,
Milind
Milind Shah
To view this discussion on the web visit https://groups.google.com/d/msgid/mongodb-user/0b687466-e634-43f6-ac7e-45dda31636cb%40googlegroups.com.

Rob Moore

Milind Shah
@Rob
I am using the recently updated YCSB from https://github.com/brianfrankcooper/YCSB. For the insert test, I am using batchsize=100 for now. I don't want to use async client yet as I want to measure latency accurately for the operations.
Since I was not able to get a good throughput with a 10 node setup, I decided to do what Asya mentioned in the blog post - https://www.mongodb.com/blog/post/performance-testing-mongodb-30-part-1-throughput-improvements-measured-ycsb. I tried to replicate the numbers that are mentioned in the blog using a 2 node setup. The node's hardware configurations are still the same. I have 1 mongod+mongos+2 YCSB Clients running on one node and 1 node assigned for config servers.
With that setup, I ran following tests:
1) Load 30 million records (1 field with 100 bytes - as mentioned in the blog post)
2) Read uniform distribution
3) Read zipfian distribution
4) Range scan zipfian distribution
5) Mixed workload with 95% read zipfian / 5% update
6) Mixed workload with 50% read zipfian / 50% update
During the load phase, I saw mongod using between 22 and 25 cores(top showed 2200-2500% for mongod). The insert workload was CPU bound. During read and mixed workloads, mongod was using between 9 and 11 cores. During read and scan tests, I made sure using iostat that the disk was not getting hit. I also experimented with # of threads in YCSB clients and also tried adding more/less # of clients and found the sweet spot where I was getting good throughput without affecting the latency.
Here are the numbers:
| Test | # of threads /client | RowSize | Cluster Throughput | Throughput ops/sec/client | Write: Avg Lat (us) | Write: Min Lat (us) | Write: Max Lat (us) | 95th % Latency (ms) | 99th % Latency (ms) | Read: AvgLat (us) | Read: MinLat (us) | Read: MaxLat (us) | 95th % Latency (ms) | 99th % Latency (ms) |
| INSERT | 30 | 100B(1x100) | 126,430 | 63,215 | 348 | 0 | 133,534,630 | 0 | 5 | #N/A | #N/A | #N/A | #N/A | #N/A |
| READ-UNIFORM | 50 | 100B(1x100) | 76,310 | 38,155 | #N/A | #N/A | #N/A | #N/A | #N/A | 1,304 | 158 | 192,358 | 2 | 3 |
| READ-ZIPFIAN | 50 | 100B(1x100) | 76,512 | 38,256 | #N/A | #N/A | #N/A | #N/A | #N/A | 1,301 | 155 | 210,224 | 2 | 3 |
| SCAN | 25 | 100B(1x100) | 12,487 | 6,244 | #N/A | #N/A | #N/A | #N/A | #N/A | 3,999 | 247 | 11,028,849 | 6 | 8 |
| MIXED 95/5 | 50 | 100B(1x100) | 72,207 | 36,103 | 2,564 | 227 | 3,951,334 | 3 | 26 | 1,314 | 146 | 624,576 | 2 | 3 |
| MIXED 50/50 | 50 | 100B(1x100) | 62,417 | 31,209 | 2,148 | 210 | 1,129,917 | 4 | 11 | 1,037 | 152 | 683,493 | 2 | 3 |
During scan test, mongod process died twice so for now we could ignore them. The error I saw in the mongod log was:
2015-07-01T17:32:41.506-0700 E STORAGE [conn1] WiredTiger (12) [1435797161:506959][20793:0x7f03e896a700], connection.open_session: only configured to sup
port 20010 sessions (including 10 internal): Cannot allocate memory
2015-07-01T17:32:41.507-0700 I - [conn1] Invariant failure: ret resulted in status UnknownError 12: Cannot allocate memory at src/mongo/db/storage/
wiredtiger/wiredtiger_session_cache.cpp 49
2015-07-01T17:32:41.507-0700 E STORAGE [conn88] WiredTiger (12) [1435797161:507173][20793:0x7f03e1302700], connection.open_session: only configured to su
pport 20010 sessions (including 10 internal): Cannot allocate memory
2015-07-01T17:32:41.507-0700 I - [conn88] Invariant failure: ret resulted in status UnknownError 12: Cannot allocate memory at src/mongo/db/storage
/wiredtiger/wiredtiger_session_cache.cpp 49
2015-07-01T17:32:41.524-0700 I CONTROL [conn48]
0xf77369 0xf140f1 0xef99fa 0xd8eae0 0xd8efb6 0xd8a0ce 0xd8a115 0xd78165 0xa83e58 0xa078e2 0xa0801d 0xa1e595 0x9fbb7d 0xbd5714 0xbd5ac4 0xba3a54 0xab4e90
0x7fb81d 0xf2883b 0x7f03f89559d1 0x7f03f74a786d
----- BEGIN BACKTRACE -----
{"backtrace":[{"b":"400000","o":"B77369"},{"b":"400000","o":"B140F1"},{"b":"400000","o":"AF99FA"},{"b":"400000","o":"98EAE0"},{"b":"400000","o":"98EFB6"},{"b":"400000","o":"98A0CE"},{"b":"400000","o":"98A115"},{"b":"400000","o":"978165"},{"b":"400000","o":"683E58"},{"b":"400000","o":"6078E2"},{"b":"400000","o":"60801D"},{"b":"400000","o":"61E595"},{"b":"400000","o":"5FBB7D"},{"b":"400000","o":"7D5714"},{"b":"400000","o":"7D5AC4"},{"b":"400000","o":"7A3A54"},{"b":"400000","o":"6B4E90"},{"b":"400000","o":"3FB81D"},{"b":"400000","o":"B2883B"},{"b":"7F03F894E000","o":"79D1"},{"b":"7F03F73BF000","o":"E886D"}],"processInfo":{ "mongodbVersion" : "3.0.4", "gitVersion" : "0481c958daeb2969800511e7475dc66986fa9ed5", "uname" : { "sysname" : "Linux", "release" : "2.6.32-431.29.2.el6.x86_64", "version" : "#1 SMP Tue Sep 9 21:36:05 UTC 2014", "machine" : "x86_64" }, "somap" : [ { "elfType" : 2, "b" : "400000", "buildId" : "7702B4740E91E1BA6F701DB2A42553968AC09562" }, { "b" : "7FFF97C38000", "elfType" : 3, "buildId" : "5474F0D8DAF3D6177E2C4B06F3892745CB43B4D5" }, { "b" : "7F03F894E000", "path" : "/lib64/libpthread.so.0", "elfType" : 3, "buildId" : "211321F78CA244BE2B2B1B8584B460F9933BA76B" }, { "b" : "7F03F86E2000", "path" : "/usr/lib64/libssl.so.10", "elfType" : 3, "buildId" : "40BEA6554E64FC0C3D5C7D0CD91362730515102F" }, { "b" : "7F03F82FF000", "path" : "/usr/lib64/libcrypto.so.10", "elfType" : 3, "buildId" : "FC4EFD7502ACB3B9D213D28272D15A165857AD5A" }, { "b" : "7F03F80F7000", "path" : "/lib64/librt.so.1", "elfType" : 3, "buildId" : "B26528BF6C0636AC1CAE5AC50BDBC07E60851DF4" }, { "b" : "7F03F7EF3000", "path" : "/lib64/libdl.so.2", "elfType" : 3, "buildId" : "AFC7448F2F2F6ED4E5BC82B1BD8A7320B84A9D48" }, { "b" : "7F03F7BED000", "path" : "/usr/lib64/libstdc++.so.6", "elfType" : 3, "buildId" : "F07F2E7CF4BFB393CC9BBE8CDC6463652E14DB07" }, { "b" : "7F03F7969000", "path" : "/lib64/libm.so.6", "elfType" : 3, "buildId" : "98B028A725D6E93253F25DF00B794DFAA66A3145" }, { "b" : "7F03F7753000", "path" : "/lib64/libgcc_s.so.1", "elfType" : 3, "buildId" : "246C3BAB0AB093AFD59D34C8CBF29E786DE4BE97" }, { "b" : "7F03F73BF000", "path" : "/lib64/libc.so.6", "elfType" : 3, "buildId" : "59640F8CD5A70CF0391A7C64275D84336935E6AA" }, { "b" : "7F03F8B6B000", "path" : "/lib64/ld-linux-x86-64.so.2", "elfType" : 3, "buildId" : "57BF668F99B7F5917B8D55FBB645173C9A644575" }, { "b" : "7F03F717B000", "path" : "/lib64/libgssapi_krb5.so.2", "elfType" : 3, "buildId" : "54BA6B78A9220344E77463947215E42F0EABCC62" }, { "b" : "7F03F6E95000", "path" : "/lib64/libkrb5.so.3", "elfType" : 3, "buildId" : "6797403AA5F8FAD8ADFF683478B45F528CE4FB0E" }, { "b" : "7F03F6C91000", "path" : "/lib64/libcom_err.so.2", "elfType" : 3, "buildId" : "8CE28F280150E62296240E70ECAC64E4A57AB826" }, { "b" : "7F03F6A65000", "path" : "/lib64/libk5crypto.so.3", "elfType" : 3, "buildId" : "05733977F4E41652B86070B27A0CFC2C1EA7719D" }, { "b" : "7F03F684F000", "path" : "/lib64/libz.so.1", "elfType" : 3, "buildId" : "5FA8E5038EC04A774AF72A9BB62DC86E1049C4D6" }, { "b" : "7F03F6644000", "path" : "/lib64/libkrb5support.so.0", "elfType" : 3, "buildId" : "E3FA235F3BA3F776A01A18ECA737C9890F445923" }, { "b" : "7F03F6441000", "path" : "/lib64/libkeyutils.so.1", "elfType" : 3, "buildId" : "AF374BAFB7F5B139A0B431D3F06D82014AFF3251" }, { "b" : "7F03F6227000", "path" : "/lib64/libresolv.so.2", "elfType" : 3, "buildId" : "A91A53E16DEABDFE05F28F7D04DAB5FFAA013767" }, { "b" : "7F03F6008000", "path" : "/lib64/libselinux.so.1", "elfType" : 3, "buildId" : "E6798A06BEE17CF102BBA44FD512FF8B805CEAF1" } ] }}
mongod(_ZN5mongo15printStackTraceERSo+0x29) [0xf77369]
mongod(_ZN5mongo10logContextEPKc+0xE1) [0xf140f1]
mongod(_ZN5mongo17invariantOKFailedEPKcRKNS_6StatusES1_j+0xDA) [0xef99fa]
mongod(_ZN5mongo17WiredTigerSessionC1EP15__wt_connectionii+0xA0) [0xd8eae0]
mongod(_ZN5mongo22WiredTigerSessionCache10getSessionEv+0x4C6) [0xd8efb6]
mongod(_ZN5mongo22WiredTigerRecoveryUnit10getSessionEPNS_16OperationContextE+0x3E) [0xd8a0ce]
mongod(_ZN5mongo16WiredTigerCursorC1ERKSsmbPNS_16OperationContextE+0x35) [0xd8a115]
mongod(_ZNK5mongo21WiredTigerIndexUnique9newCursorEPNS_16OperationContextEi+0x55) [0xd78165]
mongod(_ZNK5mongo22BtreeBasedAccessMethod9newCursorEPNS_16OperationContextERKNS_13CursorOptionsEPPNS_11IndexCursorE+0x28) [0xa83e58]
mongod(_ZN5mongo9IndexScan13initIndexScanEv+0x62) [0xa078e2]
mongod(_ZN5mongo9IndexScan4workEPm+0x4D) [0xa0801d]
mongod(_ZN5mongo16ShardFilterStage4workEPm+0x55) [0xa1e595]
mongod(_ZN5mongo10FetchStage4workEPm+0xCD) [0x9fbb7d]
mongod(_ZN5mongo12PlanExecutor18getNextSnapshottedEPNS_11SnapshottedINS_7BSONObjEEEPNS_8RecordIdE+0xA4) [0xbd5714]
mongod(_ZN5mongo12PlanExecutor7getNextEPNS_7BSONObjEPNS_8RecordIdE+0x34) [0xbd5ac4]
mongod(_ZN5mongo8runQueryEPNS_16OperationContextERNS_7MessageERNS_12QueryMessageERKNS_15NamespaceStringERNS_5CurOpES3_+0xA74) [0xba3a54]
mongod(_ZN5mongo16assembleResponseEPNS_16OperationContextERNS_7MessageERNS_10DbResponseERKNS_11HostAndPortE+0xB10) [0xab4e90]
mongod(_ZN5mongo16MyMessageHandler7processERNS_7MessageEPNS_21AbstractMessagingPortEPNS_9LastErrorE+0xDD) [0x7fb81d]
mongod(_ZN5mongo17PortMessageServer17handleIncomingMsgEPv+0x34B) [0xf2883b]
libpthread.so.0(+0x79D1) [0x7f03f89559d1]
libc.so.6(clone+0x6D) [0x7f03f74a786d]
----- END BACKTRACE -----
2015-07-01T17:32:41.524-0700 I - [conn48]
Thanks,
Milind
MARK CALLAGHAN
To view this discussion on the web visit https://groups.google.com/d/msgid/mongodb-user/c2ba3b90-d080-4ade-b7f7-00b77ed94da8%40googlegroups.com.
Milind Shah
@Asya
I am trying to I am trying to reproduce the number that you've mentioned in blog post - https://www.mongodb.com/blog/post/performance-testing-mongodb-30-part-1-throughput-improvements-measured-ycsb. For a 30 million rows of data, 1 field of 100 Bytes, I saw insert giving me only ~126K ops/sec. Then I enabled the snappy compression on the collection and I was able to get close to 200K ops/sec. I have also moved my YCSB clients to a dedicated machine. Currently, I am trying to run mixed 95(read)/5(update) workload and not able to get more than 90K ops/sec. I also played with the thread counts and number of clients as well but could not get beyond 90K ops/sec.Blog post mentions throughput beyond 270K ops/sec which is 3x of what I am observing. Based on the setup mentioned in the blog, the only difference I see is that I have 8 disks for storage and you have 2 SSDs for the storage. This would impact the insert performance but for the read operations on 30 million rows, the type of storage should not matter as everything fits into memory. Could you suggest if there were any other tuning parameters that I should try to match the performance? I am trying to match the numbers first and then once I have a good single node setup, I want to scale it to multiple nodes and try the tests again.
Thanks,
Milind
...
Milind Shah
I have filed https://jira.mongodb.org/browse/SERVER-19273 for the scan crash that I observed.
Thanks,
Milind
...