
Attila-Mihaly Balazs
I wanted to benchmark the performance of different approaches to copying arrays of primitives (motivated by the fact that I want to submit a PR to use the most efficient one in fastutils [1]) and I got some interesting results which hopefully y'all can shed some light on.
My weirdest finding: there is "one method" which is the fastest across all primitives. In particular:
- for bytes Unsafe.copymemory is the fastest (but only slightly faster than System.arraycopy)
- for shorts Unsafe is almost ~2x faster than the other methods for shorter arrays (up to 10k in size)
- for ints Unsafe is again the fastest but by a smaller margin
- for longs manual copy using decrement is almost 2x faster than anything else!
I was really rooting for System.arraycopy since it is an intrinsic. I'm also surprised that Java code can beat arraycopy / unsafe for longs which seems to indicate that the later operate on 4 byte chuncks instead of 8 byte chunks.
Is this (the fact that they don't operate on 8 byte - or perhaps even larger - chunks) a bug / a known shortcoming?
- the benchmark was written using JMH (Hi Aleksey!) and can be found here [2]
- the scenarios benchmarked were:
- for different primitive types (byte, short, int, long)
- copy from one array to the other using:
- a for loop
- a decrementing for loop (so that the stop condition is cheaper to test)
- System.arraycopy
- Unsafe.copymemory (sorry Alaksey, had to try it :-)
- there are also some tests with using overlapping source / target (moving the elements one place to the right)
- you can find the raw results here [3] in CSV format and I also imported it to google docs [4] for some ad-hoc analysis
- I also did a (shorter) run with -XX+PrintAssembly the output of which can be seen here [5]
- the test was done on a four-core i7 (see the the full cpuinfo here [6]) using the 64 bit Oracle jdk 1.8.0_72
[2] https://github.com/gpanther/benchmark-arraycopy
[3] https://github.com/gpanther/benchmark-arraycopy/blob/master/jmh-result.csv
[4] https://docs.google.com/spreadsheets/d/1gzQ0Ww4_oTGPv195oBgt1f3fBd4ZRbkqKmgLek6m9EQ/edit?usp=sharing
[5] https://github.com/gpanther/benchmark-arraycopy/blob/master/disassembly.txt.bz2
[6] https://github.com/gpanther/benchmark-arraycopy/blob/master/cpuinfo.txt

Aleksey Shipilev
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Attila-Mihaly Balazs
What I think I found (I posted the entire output here [1]):
Bytes:
- manual copy (both increasing / decreasing) uses vmovq w/o loop unrolling [2] (so moving 8 bytes at once)
- System.arraycopy uses tight and unrolled loop of vmovdqu [3] (moving 32 bytes / 256 bits every iteration)
Unsafe.copyMemory does the same
Shorts / Ints / Longs:
- manual copy: vmovdqu
- System.arraycopy / Unsafe.copyMemory: unrolled vmovdqu
Object references (using compressed Oops - just added these):
- manual copy: some complicated combinations of movs / shrs [4]
- System.arraycopy: unrolled vmovdqu (couldn't get Unsafe.copyMemory to work :-))
[1] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt
[2] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L135
https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L483
[3] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L919
[4] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L4613
Attila-Mihaly Balazs
Could it be that the performance difference I was seeing (up to 2x) is just an artefact of the threads moving around / other processes running / affecting cache? Even if I was using JMH and let the benchmark run overnight on my laptop? From what I see, the generated code is identical and there should be no difference.
Cheers,
Attila
[1] http://www.agner.org/optimize/instruction_tables.pdf

Vitaly Davidovich
On Tuesday, February 23, 2016, Attila-Mihaly Balazs <dify...@gmail.com> wrote:
Duude, perfasm is awesome! Now I just need to stare at the AT&T syntax until my head stops hurting :)
What I think I found (I posted the entire output here [1]):
Bytes:
- manual copy (both increasing / decreasing) uses vmovq w/o loop unrolling [2] (so moving 8 bytes at once)
- System.arraycopy uses tight and unrolled loop of vmovdqu [3] (moving 32 bytes / 256 bits every iteration)
Unsafe.copyMemory does the same
Shorts / Ints / Longs:
- manual copy: vmovdqu
- System.arraycopy / Unsafe.copyMemory: unrolled vmovdqu
Object references (using compressed Oops - just added these):
- manual copy: some complicated combinations of movs / shrs [4]
- System.arraycopy: unrolled vmovdqu (couldn't get Unsafe.copyMemory to work :-))
[1] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt
[2] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L135
https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L483
[3] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L919
[4] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm.txt#L4613
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Sent from my phone
Attila-Mihaly Balazs
--
You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe.
To unsubscribe from this group and all its topics, send an email to mechanical-symp...@googlegroups.com.
Aleksey Shipilev
On 02/24/2016 07:55 AM, Attila-Mihaly Balazs wrote:
> What I think I found (I posted the entire output here
> Bytes:
> - manual copy (both increasing / decreasing) uses vmovq w/o loop
> unrolling
> - System.arraycopy uses tight and unrolled loop of vmovdqu
> Unsafe.copyMemory does the same
>
> Shorts / Ints / Longs:
> - manual copy: vmovdqu
> - System.arraycopy / Unsafe.copyMemory: unrolled vmovdqu
>
> Object references (using compressed Oops - just added these):
> - manual copy: some complicated combinations of movs / shrs
> - System.arraycopy: unrolled vmovdqu (couldn't get Unsafe.copyMemory to
> work :-))
* System.arraycopy is the go-to way to copy (as expected);
* Manual copies can be vectorized, as we see in byte/short/int/long
cases, and sometimes they don't. I would expect reference arraycopies to
match harder in vectorizers, because of the GC store barriers. I'd
recommend taking a most recent JDK 9 EA, and see if compiler changes are
in place to better vectorize these loops (Intel was doing this work);
* Notice that Unsafe.copyMemory does jlong_disjoint_arraycopy, while
System.arraycopy does jbyte_disjoint_arraycopy; while the hotloops are
indeed the same, the subtle difference might be enough to get the
difference;
* Aside: these arraycopy tests are known to be affected by
alignment-induced run-to-run variance. I'd run with multiple forks (>30)
to catch this behavior into the error margins.
If you indeed see the peculiarities in System.arraycopy behaviors on
latest JDK, then you can accurately minimize them, and submit the bug
reports.
Cheers,
-Aleksey

Gil Tene
Attila-Mihaly Balazs
A quick follow up - I took Aleksey's advice and re-ran the tests with a high fork count (30) and with a JDK 9 beta (9-ea+106-2016-02-17-203503.javare.4476.nc). I think the core issue is still there: copying manually in a decrementing loop is still ~30% faster when copying long arrays if:
- running on my machine (more accurately I think this is a processor issue - mine is "Intel(R) Core(TM) i7-4600U CPU @ 2.10GHz" - I tried to run the same benchmark with the same JDK on a "Xeon(R) CPU E5-2665" where it does not reproduce - both manual looping and System.arrraycopy have the same performance)
- using a suitable small-ish array (the issue is clearly visible on a 1kb - 128 elements - and 10kb - 1280 elements - array but starts to disappear around 1Mb and is almost non-existent around 10Mb - I'm guessing that's because at those levels the memory transfer times dominate).
I also produced a trimmed down / simplified version of the benchmark which reproduces the issue: https://github.com/gpanther/benchmark-arraycopy/blob/master/src/main/java/net/greypanther/BenchmarkLongArrayCopyStandalone.java
Aleksey, should I submit a bug with these results to the JDK bugtracker? https://bugs.openjdk.java.net/secure/Dashboard.jspa
Cheers,
Attila

Martin Thompson
--
Aleksey Shipilev
> I also produced a trimmed down / simplified version of the benchmark
> which reproduces the issue:
> https://github.com/gpanther/benchmark-arraycopy/blob/master/src/main/java/net/greypanther/BenchmarkLongArrayCopyStandalone.java
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(3)
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public class ArrayCopyVsManual {
@Param({"1024"})
int size;
byte[] pad;
long[] source, destination;
@Setup
public void setUp() {
Random r = new Random(42);
pad = new byte[r.nextInt(1024)];
source = new long[size];
destination = new long[size];
for (int i = 0; i < size; ++i) {
source[i] = r.nextInt();
}
// Promote the shit out of both arrays
System.gc();
}
@Benchmark
public void arraycopy() {
System.arraycopy(source, 0, destination, 0, size);
}
@Benchmark
public void manualCopy() {
for (int i = 0; i < size; i++) {
destination[i] = source[i];
}
}
}
...and so I ran it with JDK 9b104 and "-f 100 -wi 1 -i 1 -w 300ms -r
300ms" (notice this is dangerously quick run). The trick is then to look
for (min, avg, max), because the distribution is hardly normal:
Result "arraycopy":
277.772 ±(99.9%) 50.594 ns/op [Average]
(min, avg, max) = (134.839, 277.772, 451.066), stdev = 149.177
CI (99.9%): [227.178, 328.365] (assumes normal distribution)
Result "manualCopy":
140.605 ±(99.9%) 2.572 ns/op [Average]
(min, avg, max) = (138.687, 140.605, 211.412), stdev = 7.583
CI (99.9%): [138.033, 143.177] (assumes normal distribution)
So, while the average is indeed in favor of "manualCopy", other data
indicates extraordinarily bad variance. Note how "min" is actually on
par with vectorized manual copy. So, I think variance is our first, and
probably the only enemy here.
> Aleksey, should I submit a bug with these results to the JDK bugtracker?
> https://bugs.openjdk.java.net/secure/Dashboard.jspa
https://bugs.openjdk.java.net/browse/JDK-8150730
I need to swap out to some other high-priority work. Hopefully I would
have a chance to look into Hotspot details next week -- this would be a
next step anyway.
Cheers,
-Aleksey
Attila-Mihaly Balazs
I think you've meant to write pad = new byte[new Random().nextInt(1024)]; (since r is initialized with constant seed above) - but the results are the same.
I also ran it on the Xeon CPU I have access to and there I saw the same thing (lots of variant but the manual copy seems to have a narrower distribution than the arraycopy).
Regards,
Attila
PS. Could someone please clarify how the "pad" is supposed to work here? It seems to me that in the object instance it will always take up 8 bytes (as a reference) and there is no requirement for the three arrays (pad, source and destination) to be laid out continuously in memory, so varying "pad" size should only tangentially influence the alignment of source / destination (if at all?).
Gil Tene
The reason first he random pad is that array copying (and other streaming operations) can be highly sensitive to vector-sized alignment both of the individual arrays (hence the initial random pad) and of the relative alignment between the source and destination. Depending on platform, alignments to 8, 16 (e.g. SSE/AVX), 32 (e.g. AVX2), or 64 (e.g. AVX512/AVX3) bytes can have a significant effect on performance.
Attila-Mihaly Balazs
However, if you could indulge me a little more:
- I created a small program which allocates arrays in a loop and then checks if their address is aligned to 4/8/16/32 bytes and also if the address of the first element is aligned to 4/8/16/32 bytes
- the first question is if the code is correct since it gets the physical/virtual address of the object in a round about way
- also, perhaps we're talking about the physical address alignment here? (but I think that the alignment of the physical and virtual address are the same since the later is mapped to the former in 4k/2M chunks)
- What was NOT surprising to me:
- for long[]s the alignment of the object and the first element always coincided while for byte[]s it could differ
- What WAS surprising to me:
- that not all arrays objects (not even all long[] arrays) are 8 byte aligned. Should not that be the case given that on my machine -XX:ObjectAlignmentInBytes has a value of 8?
Now getting back to my original question: do the following two pieces of code differ substantially regarding the alignment of the resulting objects? (assuming that pad, source and destination are fields on the object)
pad = new byte[new Random().nextInt(1024)];
source = new long[size];
destination = new long[size];
System.gc();
And:
source = new long[size];
destination = new long[size];
System.gc();
My reasoning as to why these are the same (with regards to alignment):
- pad, source and destination are all references so they are aligned in the object itself
- the arrays they point to can be laid out in memory however the runtime pleases. In fact probably:
- on initial allocation they are laid out sequentially in the eden space
- but during GC they are promoted "randomly" to old generation
- so having the initial pad byte array should not influence the alignment of the other two arrays
If we want to test the influence of alignment on copying, wouldn't it be better to allocate a byte[] array and arraycopy from/to it using random starting offsets? (given that arraycopy would move 32 bytes anyway per iteration).
Cheers,
Attila
Attila-Mihaly Balazs
Attila
Aleksey Shipilev
which are not guaranteed to align at all, since they borrow the right
zero alignment bits. So:
> What WAS surprising to me: that not all arrays objects (not even all
> long[] arrays) are 8 byte aligned. Should not that be the case
> given that on my machine -XX:ObjectAlignmentInBytes has a value of
> 8?
greater good:
http://openjdk.java.net/projects/code-tools/jol/
> If we want to test the influence of alignment on copying, wouldn't it
> be better to allocate a byte[] array and arraycopy from/to it using
> random starting offsets? (given that arraycopy would move 32 bytes
> anyway per iteration).
deterministic alignment test, and you can only make random testing,
correlating actual alignment with performance data, like I did in
JDK-8150730.
There is little sense in having a random base alignment *and* a random
in-array starting point to begin with. Having a random-sized pad array
allocated before the array seems to be a simpler way to introduce more
randomness in that test (at least in some configurations of mine) --
*without* affecting the actual arraycopy code you are testing, always
presenting VM with exactly the same work, but in subtly different
conditions.
The art of benchmarking is about isolating one effect at a time.
-Aleksey
Attila-Mihaly Balazs
Could you please point out where the arrays are transposed? As far as I can see they are correctly treated as source / destination.
Also, these operations can't be optimized away since they are on instance fields (which may be read later as far as the JVM is concerned), so IMHO there is no need to return them (but yes, generally it's good idea to guard against dead code elimination in benchmarks.
Cheers,
Attila
Martin Thompson
Only on my phone now but I think the version I looked at had the destination, rather than the source, array filled with random data.
--
Martin Thompson
Attila-Mihaly Balazs
Thank you for pointing me towards VMSupport.addressOf - the result now make much more sense (ie. objects are now always 8 byte aligned, but only sometimes 16/32 byte aligned).
Sorry for repeating this, but I still don't understand why putting a byte padding in the front should change anything?
What I imagine is happening:
- class instance contains 3 x 8 byte references (pad, source, destination)
- the actual arrays can be anywhere on the heap (ie. they can be placed as <pad><source><destination> - in which case the size of pad would make a difference, but they can also be placed as <source><destination><pad> or even non one after the others)
In my mind a better way measure alignment effects would be the following:
- allocate a pair of byte arrays to be used for the entire benchmark (@State(Scope.Benchmark)) and use a single fork (@Fork(1)) so that the arrays are the same between tests (also forced GC like in your example so that they're in old-gen and probably don't move any more)
- now use different source and target offsets for copying and do the measurement.
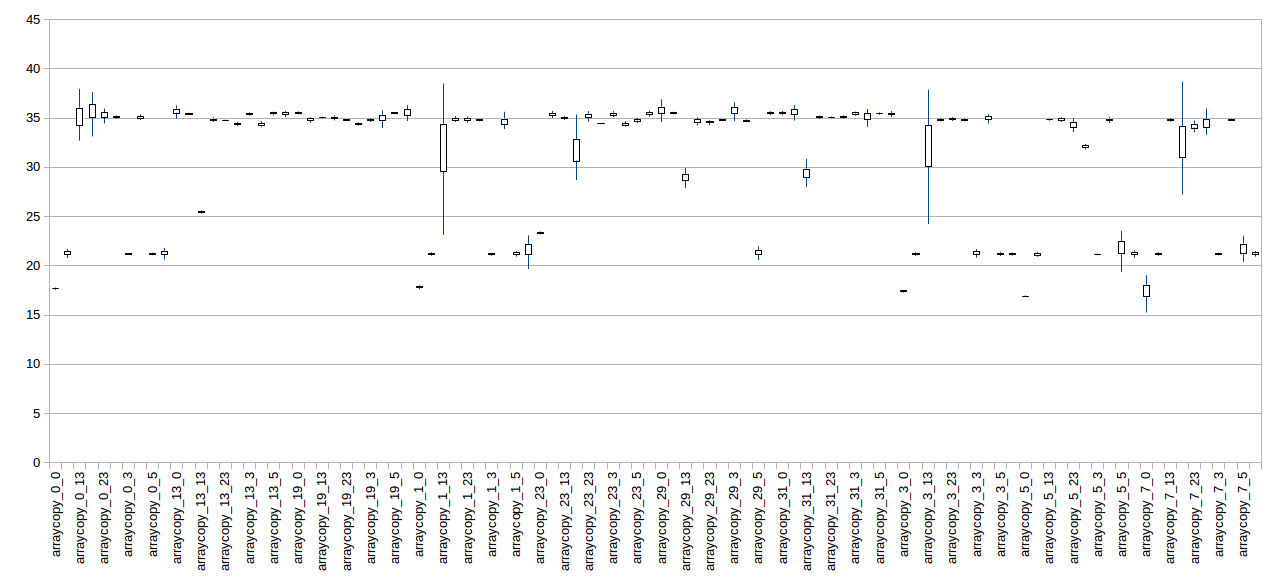
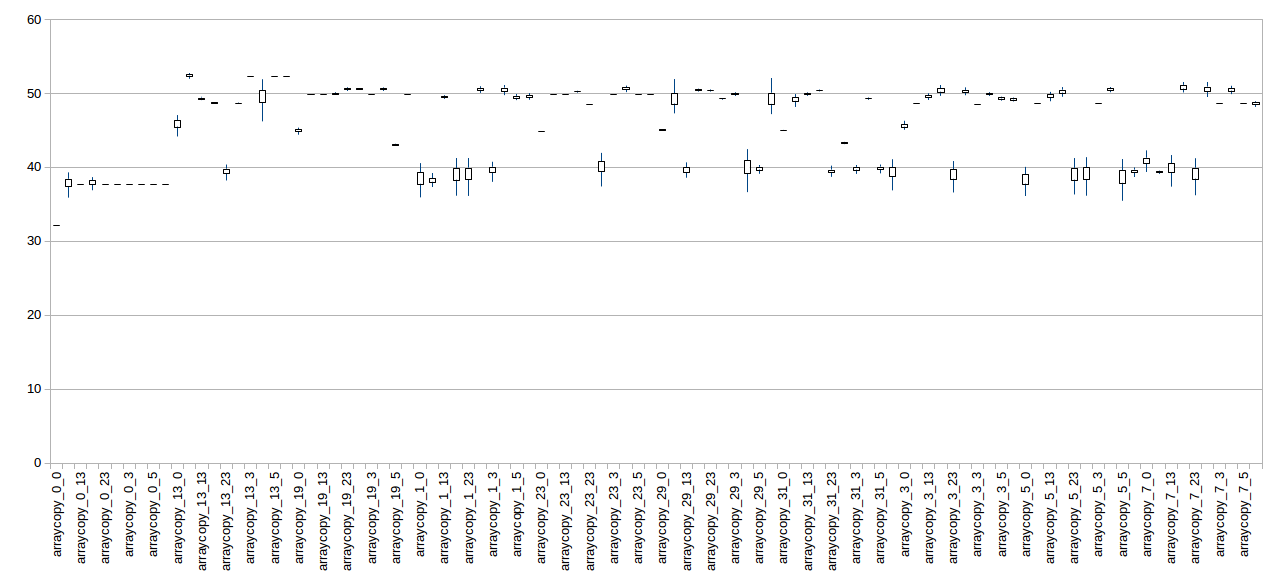
I did exactly that here [1] (although I didn't try all the combinations). You can see the results drawn on candlestick charts here [2] and here [3] (I also attached it to the email for convenience). The first chart is for an i7 and the second one is for a Xeon.
Both of them show strong bi-modality, so alignment definitely matters - and I'm still unsure how the benchmark attached to the Jira issue variens the alignment - other than the pure randomness of memory allocation.
Also, perhaps the arraycopy code could account for alignment by copying the
first/last few elements differently and only copy the aligned data in the main loop.
Cheers,
Attila
[2] https://github.com/gpanther/benchmark-arraycopy/blob/master/alignment-i7.png
[3] https://github.com/gpanther/benchmark-arraycopy/blob/master/alignment-xeon.png
Attila-Mihaly Balazs
Attila
Attila-Mihaly Balazs
Source code here [1] - what is (hopefully) happening:
- it allocates the source and destination array once in a static block (can't use @Setup because that is executed multiple times during benchmark run)
- it re-allocates the arrays until they are 32 byte aligned (the best case scenario)
- uses @Fork(0) to ensure that all tests are run in the same JVM
- use @Setup to verify that the arrays are still aligned
Now it tests three scenarios:
- System.arraycopy
- manual copy in increasing direction
- manual copy in decreasing direction
Benchmark (size) Mode Cnt Score Error Units
BenchmarkLongArrayCopyStandalone2.arraycopy 1024 avgt 20 163.974 ± 3.340 ns/op
BenchmarkLongArrayCopyStandalone2.manualCopy 1024 avgt 20 324.006 ± 0.853 ns/op
BenchmarkLongArrayCopyStandalone2.manualCopy_Dec 1024 avgt 20 90.813 ± 2.726 ns/op
Other interesting observations:
- perf stat reports a higher number of instructions but a lower number of branches and a considerably lower number of branch misses than in the case of arraycopy:
Performance counter stats for 'jdk-9/bin/java -Djol.tryWithSudo=true -jar target/benchmarks.jar BenchmarkLongArrayCopyStandalone2.arraycopy':
41886,813709 task-clock (msec) # 0,881 CPUs utilized
4.845 context-switches # 0,116 K/sec
509 cpu-migrations # 0,012 K/sec
22.246 page-faults # 0,531 K/sec
133.105.085.141 cycles # 3,178 GHz
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
193.885.831.009 instructions # 1,46 insns per cycle
33.125.314.936 branches # 790,829 M/sec
265.929.932 branch-misses # 0,80% of all branches
47,536583457 seconds time elapsed
Performance counter stats for 'jdk-9/bin/java -Djol.tryWithSudo=true -jar target/benchmarks.jar BenchmarkLongArrayCopyStandalone2.manualCopy_Dec':
42285,417423 task-clock (msec) # 0,832 CPUs utilized
5.334 context-switches # 0,126 K/sec
641 cpu-migrations # 0,015 K/sec
24.344 page-faults # 0,576 K/sec
134.267.708.056 cycles # 3,175 GHz
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
352.602.712.109 instructions # 2,63 insns per cycle
32.350.320.916 branches # 765,047 M/sec
37.570.206 branch-misses # 0,12% of all branches
50,815428124 seconds time elapsed
- the Xeon machine does not exhibit this anomaly (both arraycopy and manualCopy_Dec perform the same there):
Benchmark (size) Mode Cnt Score Error Units
BenchmarkLongArrayCopyStandalone2.arraycopy 1024 avgt 20 194.047 ± 0.005 ns/op
BenchmarkLongArrayCopyStandalone2.manualCopy 1024 avgt 20 263.778 ± 0.036 ns/op
BenchmarkLongArrayCopyStandalone2.manualCopy_Dec 1024 avgt 20 196.387 ± 0.040 ns/op
- One possible difference source for the difference is that arraycopy moves 2 QWORDS per iteration:
2.49% 1.28% │ ↗ │││ 0x00007f79d5773a70: vmovdqu -0x38(%rdi,%rdx,8),%ymm0
2.61% 1.60% │ │ │││ 0x00007f79d5773a76: vmovdqu %ymm0,-0x38(%rcx,%rdx,8)
3.39% 0.84% │ │ │││ 0x00007f79d5773a7c: vmovdqu -0x18(%rdi,%rdx,8),%ymm1
28.53% 16.22% │ │ │││ 0x00007f79d5773a82: vmovdqu %ymm1,-0x18(%rcx,%rdx,8)
56.50% 73.29% ↘ │ │││ 0x00007f79d5773a88: add $0x8,%rdx
╰ │││ 0x00007f79d5773a8c: jle Stub::jlong_disjoint_arraycopy+48 0x00007f79d5773a70
- While manualCopy_Dec moves 8 (!) of them - and even though it reuses the same register, probably register renaming prevents that from being a bottleneck:
2.68% 1.67% │││││ │↗ 0x00007f233c9a98b0: vmovdqu -0x8(%r11,%rbx,8),%ymm0
0.24% 0.21% │││││ ││ 0x00007f233c9a98b7: vmovdqu %ymm0,-0x8(%r10,%rbx,8)
10.44% 11.96% │││││ ││ 0x00007f233c9a98be: vmovdqu -0x28(%r11,%rbx,8),%ymm0
0.03% 0.05% │││││ ││ 0x00007f233c9a98c5: vmovdqu %ymm0,-0x28(%r10,%rbx,8)
8.94% 10.19% │││││ ││ 0x00007f233c9a98cc: vmovdqu -0x48(%r11,%rbx,8),%ymm0
0.11% 0.05% │││││ ││ 0x00007f233c9a98d3: vmovdqu %ymm0,-0x48(%r10,%rbx,8)
9.62% 10.50% │││││ ││ 0x00007f233c9a98da: vmovdqu -0x68(%r11,%rbx,8),%ymm0
0.08% 0.11% │││││ ││ 0x00007f233c9a98e1: vmovdqu %ymm0,-0x68(%r10,%rbx,8)
9.28% 7.94% │││││ ││ 0x00007f233c9a98e8: vmovdqu -0x88(%r11,%rbx,8),%ymm0
0.20% 0.03% │││││ ││ 0x00007f233c9a98f2: vmovdqu %ymm0,-0x88(%r10,%rbx,8)
10.83% 8.90% │││││ ││ 0x00007f233c9a98fc: vmovdqu -0xa8(%r11,%rbx,8),%ymm0
0.17% 0.08% │││││ ││ 0x00007f233c9a9906: vmovdqu %ymm0,-0xa8(%r10,%rbx,8)
10.49% 8.92% │││││ ││ 0x00007f233c9a9910: vmovdqu -0xc8(%r11,%rbx,8),%ymm0
0.08% 0.06% │││││ ││ 0x00007f233c9a991a: vmovdqu %ymm0,-0xc8(%r10,%rbx,8)
8.87% 6.60% │││││ ││ 0x00007f233c9a9924: vmovdqu -0xe8(%r11,%rbx,8),%ymm0
0.12% 0.05% │││││ ││ 0x00007f233c9a992e: vmovdqu %ymm0,-0xe8(%r10,%rbx,8)
│││││ ││ ;*lastore {reexecute=0 rethrow=0 return_oop=0}
│││││ ││ ; - net.greypanther.BenchmarkLongArrayCopyStandalone2::manualCopy_Dec@20 (line 105)
8.55% 7.71% │││││ ││ 0x00007f233c9a9938: add $0xffffffffffffffe0,%ebx ;*iinc {reexecute=0 rethrow=0 return_oop=0}
│││││ ││ ; - net.greypanther.BenchmarkLongArrayCopyStandalone2::manualCopy_Dec@21 (line 104)
0.03% │││││ ││ 0x00007f233c9a993b: cmp $0x1e,%ebx
│││││ │╰ 0x00007f233c9a993e: jg 0x00007f233c9a98b0 ;*iflt {reexecute=0 rethrow=0 return_oop=0}
│││││ │ ; - net.greypanther.BenchmarkLongArrayCopyStandalone2::manualCopy_Dec@8 (line 104)
Cheers,
Attila
[1] https://github.com/gpanther/benchmark-arraycopy/blob/master/src/main/java/net/greypanther/BenchmarkLongArrayCopyStandalone2.java
Attila-Mihaly Balazs
Cheers,
Attila
Gil Tene
Sent from Gil's iPhone
--
You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe.
To unsubscribe from this group and all its topics, send an email to mechanical-symp...@googlegroups.com.
<alignment-i7.png>
<alignment-xeon.png>
Gil Tene
You should also throw 64 byte alignments into the mix. Starting with sky lake cores ("v5" in Xeon models) the AVX vectors go that wide.
Sent from Gil's iPhone
>
> ------=_Part_1756_305911719.1456587267079
> Content-Type: text/plain; charset="UTF-8"
> You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.
> To unsubscribe from this topic, visit https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe.
> To unsubscribe from this group and all its topics, send an email to mechanical-symp...@googlegroups.com.
> ------=_Part_1756_305911719.1456587267079
> Content-Type: text/html; charset="UTF-8"
>
> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"><div dir="ltr">Long story short, I think that the JVM does much more aggressive loop unrolling for manualCopy_Dec which seems to be a good match for the particular model of i7.<br><br>Cheers,<br>Attila<br></div>
>
> <p></p>
>
> -- <br>
> You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.<br>
> To unsubscribe from this topic, visit <a href="https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe">https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe</a>.<br>
> To unsubscribe from this group and all its topics, send an email to <a href="mailto:mechanical-sympathy+unsub...@googlegroups.com">mechanical-sympathy+unsub...@googlegroups.com</a>.<br>
> For more options, visit <a href="https://groups.google.com/d/optout">https://groups.google.com/d/optout</a>.<br>
>
> ------=_Part_1756_305911719.1456587267079--
>
> ------=_Part_1755_1972814854.1456587267079--

Peter Booth
On Saturday, February 27, 2016 at 10:53:20 AM UTC-5, Gil Tene wrote:
You may want to list the specific processor model in each case. "i7" and "Xeon" are not specific enough to know what core model is used. Vector sizes and processor optimization of steaming copy loops (and for increasing vs. decreasing directions) can vary a bunch across generations of cores.
You should also throw 64 byte alignments into the mix. Starting with sky lake cores ("v5" in Xeon models) the AVX vectors go that wide.
Sent from Gil's iPhone
> On Feb 27, 2016, at 7:34 AM, Attila-Mihaly Balazs <dify...@gmail.com> wrote:
>
> ------=_Part_1756_305911719.1456587267079
> Content-Type: text/plain; charset="UTF-8"
>
> Long story short, I think that the JVM does much more aggressive loop
> unrolling for manualCopy_Dec which seems to be a good match for the
> particular model of i7.
>
> Cheers,
> Attila
>
> --
> You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.
> To unsubscribe from this topic, visit https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe.
> To unsubscribe from this group and all its topics, send an email to mechanical-sympathy+unsub...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
>
> ------=_Part_1756_305911719.1456587267079
> Content-Type: text/html; charset="UTF-8"
>
> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"><div dir="ltr">Long story short, I think that the JVM does much more aggressive loop unrolling for manualCopy_Dec which seems to be a good match for the particular model of i7.<br><br>Cheers,<br>Attila<br></div>
>
> <p></p>
>
> -- <br>
> You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.<br>
> To unsubscribe from this topic, visit <a href="https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe">https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe</a>.<br>
> To unsubscribe from this group and all its topics, send an email to <a href="mailto:mechanical-sympathy+unsu...@googlegroups.com">mechanical-sympathy+unsu...@googlegroups.com</a>.<br>
Attila-Mihaly Balazs
Sorry for the delay - I now found some more free time to follow up on this thread.
First: what are the exact processor models used?
I test on my laptop (Intel(R) Core(TM) i7-4600U) and a server (Xeon(R) CPU E5-2665).
Second, Gil / Aleksey: I agree that alignment plays a big role in the behaviour of array copy. I even produced some charts ([1] and [2]) trying to quantify their impact. You can clearly see a bi-modal distribution (ie. some combination of source / destination alignment work well, other work poorly). The numbers were produced by thin benchmark [3] which does the following:
- allocates the arrays at startup statically
- disables JMH forking so that all tests reuse the exact same arrays
- find the "zero point" in the arrays (the first byte the address of which is 64 byte aligned)
- benchmarks from there
BTW, Gil, I see no reason why the JVM would need to access the array's length since arrays can't be resized in java (ie. their length can be cached).
[1] https://github.com/gpanther/benchmark-arraycopy/blob/master/alignment-i7.png
[2] https://github.com/gpanther/benchmark-arraycopy/blob/master/alignment-xeon.png
[3] https://github.com/gpanther/benchmark-arraycopy/blob/master/src/main/java/net/greypanther/BenchmarkAlignment.java
Aleksey Shipilev
> First: what are the exact processor models used?
SandyBridge Xeons), seen similar behaviors, and sticked with desktop i7
for a time being.
> Second, Gil / Aleksey: I agree that alignment plays a big role in the
> behaviour of array copy. I even produced some charts ([1] and [2])
> trying to quantify their impact. You can clearly see a bi-modal
> distribution (ie. some combination of source / destination alignment
> work well, other work poorly). The numbers were produced by thin
> benchmark [3] which does the following:
now we know significantly more. You might want to read the comments and
see the data in the original bug report:
https://bugs.openjdk.java.net/browse/JDK-8150730
> - disables JMH forking so that all tests reuse the exact same arrays
debugging, not for actual performance runs.
-Aleksey

{kind=link}
{kind=link}
Sergey Kuksenko
On Thursday, March 31, 2016 at 9:12:19 AM UTC-7, Aleksey Shipilev wrote:
Well, you seem to be where we (Sergey and me) were three weeks ago, but
now we know significantly more. You might want to read the comments and
see the data in the original bug report:
https://bugs.openjdk.java.net/browse/JDK-8150730
Vitaly Davidovich
On Thursday, March 31, 2016, Attila-Mihaly Balazs <dify...@gmail.com> wrote:
Hello all,
Sorry for the delay - I now found some more free time to follow up on this thread.
First: what are the exact processor models used?
I test on my laptop (Intel(R) Core(TM) i7-4600U) and a server (Xeon(R) CPU E5-2665).
Second, Gil / Aleksey: I agree that alignment plays a big role in the behaviour of array copy. I even produced some charts ([1] and [2]) trying to quantify their impact. You can clearly see a bi-modal distribution (ie. some combination of source / destination alignment work well, other work poorly). The numbers were produced by thin benchmark [3] which does the following:
- allocates the arrays at startup statically
- disables JMH forking so that all tests reuse the exact same arrays
- find the "zero point" in the arrays (the first byte the address of which is 64 byte aligned)
- benchmarks from there
BTW, Gil, I see no reason why the JVM would need to access the array's length since arrays can't be resized in java (ie. their length can be cached).
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Gil Tene
On Thursday, March 31, 2016 at 9:32:46 AM UTC-7, Vitaly Davidovich wrote:
On Thursday, March 31, 2016, Attila-Mihaly Balazs <dify...@gmail.com> wrote:Hello all,
Sorry for the delay - I now found some more free time to follow up on this thread.
First: what are the exact processor models used?
I test on my laptop (Intel(R) Core(TM) i7-4600U) and a server (Xeon(R) CPU E5-2665).
Second, Gil / Aleksey: I agree that alignment plays a big role in the behaviour of array copy. I even produced some charts ([1] and [2]) trying to quantify their impact. You can clearly see a bi-modal distribution (ie. some combination of source / destination alignment work well, other work poorly). The numbers were produced by thin benchmark [3] which does the following:
- allocates the arrays at startup statically
- disables JMH forking so that all tests reuse the exact same arrays
- find the "zero point" in the arrays (the first byte the address of which is 64 byte aligned)
- benchmarks from there
BTW, Gil, I see no reason why the JVM would need to access the array's length since arrays can't be resized in java (ie. their length can be cached).In short, range checks.
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Vitaly Davidovich
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Sent from my phone
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
Attila-Mihaly Balazs
- As you say there alignment can be an issue and there is no way to ensure that both source and destination are aligned by doing partial prefix copies
- Aligning destination brings a nice speedup.
However I can still reliably reproduce the issue on my i7 (Intel(R) Core(TM) i7-4600U) using this benchmark [1]. Running it JDK-9 ea-111 I get:
~/jdk-9-111/bin/java -Djol.tryWithSudo=true -jar target/benchmarks.jar BenchmarkLongArrayCopyStandalone2
...
BenchmarkLongArrayCopyStandalone2.manualCopy 1024 avgt 20 88.493 ± 9.203 ns/op
BenchmarkLongArrayCopyStandalone2.manualCopy_Dec 1024 avgt 20 85.455 ± 0.328 ns/op
~/jdk-9-111/bin/java -DalignFirstElement -Djol.tryWithSudo=true -jar target/benchmarks.jar BenchmarkLongArrayCopyStandalone2
...
BenchmarkLongArrayCopyStandalone2.manualCopy 1024 avgt 20 86.290 ± 0.433 ns/op
BenchmarkLongArrayCopyStandalone2.manualCopy_Dec 1024 avgt 20 85.264 ± 0.371 ns/op
Both runs do the following:
- Allocate two arrays which are 64 byte aligned
- Do not fork to ensure that all the testing is done in the same memory region
- Before each warmup / measurement ensure that the arrays have not moved in memory
- Perform the measurements
Now the difference without -DalignFirstElement and with -DalignFirstElement is that in the first case the benchmark aligns the start of the array and in the second case it aligns the first element of the array [2]. As you can see if the actual first element is aligned there is no performance difference (btw, somewhere between JDK-9 ea-106 and ea-111 it also picked up the ability to optimize the incrementing loop in addition to the decrementing one - cool!), however if the actual elements are misaligned, the manual copy seems to do a much better job on this model of i7 (Intel(R) Core(TM) i7-4600U).
From perfasm I can see that the difference between system.arraycopy and manual copy is that the first (system.arraycopy) unrolls just two steps and uses different registers [3] while the manual copies unroll eight steps [4] but all of the eight steps use the same register (however this is probably not a bottleneck for the CPU since it probably can do register renaming).
Cheers,
Attila
PS. You guys are quick to respond! I just watched the final Mythbuster episodes and my inbox is full like the christmas tree with gifts :-)
[1] https://github.com/gpanther/benchmark-arraycopy/blob/master/src/main/java/net/greypanther/BenchmarkLongArrayCopyStandalone2.java
[2] https://github.com/gpanther/benchmark-arraycopy/blob/master/src/main/java/net/greypanther/BenchmarkLongArrayCopyStandalone2.java#L129
[3] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm2.txt#L59
[4] https://github.com/gpanther/benchmark-arraycopy/blob/master/perfasm2.txt#L532
Attila-Mihaly Balazs
> - disables JMH forking so that all tests reuse the exact same arrays
Disabling forking is bad for JMH, this should be used only for
debugging, not for actual performance runs.
I disabled it so that I can ensure that the exact same memory regions were being used for every test, reducing the variables between test runs. This is a particular case and in general I agree that forking should not be disabled.
Cheers,
Attila
Attila-Mihaly Balazs
BTW, Gil, I see no reason why the JVM would need to access the array's length since arrays can't be resized in java (ie. their length can be cached).In short, range checks.
Sorry for being dense, but why do you need range checking in the loop? You know the exact size of the array beforehand, you know how many bytes you will move, you can just hoist the range check outside of the loop.
Cheers,
Attila
Attila-Mihaly Balazs
On certain models of processors (of which Intel(R) Core(TM) i7-4600U is one), System.arraycopy should be unrolled 8 steps using the same register. This gives a constantly optimal performance regardless of the alignment while the two-step unrolling which the JIT does currently for system.arraycopy is ~2x slower when the longs are not aligned (I'm not sure if they need to be aligned at 16, 32 or 64 byte boundaries).
Cheers,
Attila
Vitaly Davidovich
Cheers,
Attila
Aleksey Shipilev
> However I can still reliably reproduce the issue on my i7 (Intel(R)
> Core(TM) i7-4600U) using this benchmark [1]
see no value in trying to showcase how bad current arraycopy is. We have
established that already, it's time to move on.
patch) in https://bugs.openjdk.java.net/browse/JDK-8150730, you will see
that we are unrolling heavily to amortize the penalties.
And no, not in the way manual copy vectorizes that -- Nx(Load+Store)
pairs over the same register are slower than NxLoad+NxStore over
multiple registers -- partial address stalls are bitchy.
Cheers,
-Aleksey
Attila-Mihaly Balazs
--
You received this message because you are subscribed to a topic in the Google Groups "mechanical-sympathy" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/mechanical-sympathy/sug91A1ynF4/unsubscribe.
To unsubscribe from this group and all its topics, send an email to mechanical-symp...@googlegroups.com.