Befuddling deadlock (lock held but not in stack?)
884 views
Skip to first unread message

Todd Lipcon
Oct 10, 2017, 9:05:48 PM10/10/17
to mechanica...@googlegroups.com
Hey folks,
Apologies for the slightly off-topic post, since this isn't performance related, but I hope I'll be excused since this might be interesting to the group members.
We're recently facing an issue where a JVM is deadlocking in some SSL code. The resulting jstack report is bizarre -- in the deadlock analysis section it indicates that one of the locks is held by some thread, but in that thread's stack, it doesn't show the lock anywhere. Was curious if anyone had any ideas on how a lock might be "held but not held".
jstack output is as follows (with other threads and irrelevant bottom stack frames removed):
Found one Java-level deadlock:
=============================
"Thread-38190":
waiting to lock monitor 0x00000000267f2628 (object 0x00000000802ba7f8, a sun.security.provider.Sun),
which is held by "New I/O worker #1810850"
"New I/O worker #1810850":
waiting to lock monitor 0x000000007482f5f8 (object 0x0000000080ac88f0, a java.lang.Class),
which is held by "New I/O worker #1810853"
"New I/O worker #1810853":
waiting to lock monitor 0x00000000267f2628 (object 0x00000000802ba7f8, a sun.security.provider.Sun),
which is held by "New I/O worker #1810850"
Java stack information for the threads listed above:
===================================================
"Thread-38190":
at java.security.Provider.getService(Provider.java:1035)
- waiting to lock <0x00000000802ba7f8> (a sun.security.provider.Sun)
at sun.security.jca.ProviderList.getService(ProviderList.java:332)
at sun.security.jca.GetInstance.getInstance(GetInstance.java:157)
at javax.net.ssl.SSLContext.getInstance(SSLContext.java:156)
at org.apache.kudu.client.SecurityContext.<init>(SecurityContext.java:84)
...
"New I/O worker #1810850":
at sun.security.ssl.CipherSuite$BulkCipher.isAvailable(CipherSuite.java:542)
- waiting to lock <0x0000000080ac88f0> (a java.lang.Class for sun.security.ssl.CipherSuite$BulkCipher)
at sun.security.ssl.CipherSuite$BulkCipher.isAvailable(CipherSuite.java:527)
at sun.security.ssl.CipherSuite.isAvailable(CipherSuite.java:194)
at sun.security.ssl.Handshaker.getActiveProtocols(Handshaker.java:712)
at sun.security.ssl.Handshaker.activate(Handshaker.java:498)
at sun.security.ssl.SSLEngineImpl.kickstartHandshake(SSLEngineImpl.java:729)
- locked <0x000000008eca76f8> (a sun.security.ssl.SSLEngineImpl)
at sun.security.ssl.SSLEngineImpl.beginHandshake(SSLEngineImpl.java:756)
at org.apache.kudu.client.shaded.org.jboss.netty.handler.ssl.SslHandler.handshake(SslHandler.java:361)
- locked <0x000000008eca8298> (a java.lang.Object)
at org.apache.kudu.client.Negotiator.startTlsHandshake(Negotiator.java:432)
...
"New I/O worker #1810853":
at java.security.Provider.getService(Provider.java:1035)
- waiting to lock <0x00000000802ba7f8> (a sun.security.provider.Sun)
at sun.security.jca.ProviderList$ServiceList.tryGet(ProviderList.java:444)
at sun.security.jca.ProviderList$ServiceList.access$200(ProviderList.java:376)
at sun.security.jca.ProviderList$ServiceList$1.hasNext(ProviderList.java:486)
at javax.crypto.Cipher.getInstance(Cipher.java:513)
at sun.security.ssl.JsseJce.getCipher(JsseJce.java:229)
at sun.security.ssl.CipherBox.<init>(CipherBox.java:179)
at sun.security.ssl.CipherBox.newCipherBox(CipherBox.java:263)
at sun.security.ssl.CipherSuite$BulkCipher.newCipher(CipherSuite.java:505)
at sun.security.ssl.CipherSuite$BulkCipher.isAvailable(CipherSuite.java:572)
- locked <0x0000000080ac88f0> (a java.lang.Class for sun.security.ssl.CipherSuite$BulkCipher)
at sun.security.ssl.CipherSuite$BulkCipher.isAvailable(CipherSuite.java:527)
at sun.security.ssl.CipherSuite.isAvailable(CipherSuite.java:194)
at sun.security.ssl.SSLContextImpl.getApplicableCipherSuiteList(SSLContextImpl.java:346)
at sun.security.ssl.SSLContextImpl.getDefaultCipherSuiteList(SSLContextImpl.java:297)
- locked <0x000000008ebd1880> (a sun.security.ssl.SSLContextImpl$TLSContext)
at sun.security.ssl.SSLEngineImpl.init(SSLEngineImpl.java:402)
at sun.security.ssl.SSLEngineImpl.<init>(SSLEngineImpl.java:349)
at sun.security.ssl.SSLContextImpl.engineCreateSSLEngine(SSLContextImpl.java:201)
at javax.net.ssl.SSLContext.createSSLEngine(SSLContext.java:329)
...
Note that multiple threads are waiting on "0x00000000802ba7f8, a sun.security.provider.Sun" but no thread is listed as holding this in its stacks.
The additional thread info from higher up in the jstack is:
"Thread-38190" #2454575 prio=5 os_prio=0 tid=0x0000000040fff000 nid=0x8b12 waiting for monitor entry [0x00007ff9a129e000]
"New I/O worker #1810850" #2448031 daemon prio=5 os_prio=0 tid=0x00007ff87df00000 nid=0x42bf waiting for monitor entry [0x00007ff918a61000]
"New I/O worker #1810853" #2448034 daemon prio=5 os_prio=0 tid=0x00007ff87df02800 nid=0x42c4 waiting for monitor entry [0x00007ff911654000]
Native frames look like normal lock acquisition:
0x00007ffa4e6546d5 __pthread_cond_wait + 0xc5
0x00007ffa50516f7d _ZN13ObjectMonitor6EnterIEP6Thread + 0x31d
0x00007ffa50518f11 _ZN13ObjectMonitor5enterEP6Thread + 0x301
0x00007ffa505cc8ff _ZN13SharedRuntime26complete_monitor_locking_CEP7oopDescP9BasicLockP10JavaThread + 0x9f
Other relevant info:
- JVM: Java HotSpot(TM) 64-Bit Server VM (25.102-b14 mixed mode) (jdk1.8.0_102)
- OS: RHEL 7.2 (kernel 3.10.0-327.36.2.el7.x86_64) [not that infamous futex bug]
- libc version: glibc-2.17-157.el7.x86_64
- nothing interesting in dmesg
- this app actually is a native application which embeds a JVM using JNI, if that makes a difference.
Anyone else seen issues like this with relatively recent Java 8? Or any ideas on next steps to debug the phantom lock holder?
-Todd

kedar mhaswade
Oct 11, 2017, 12:04:47 AM10/11/17
to mechanica...@googlegroups.com
I am not sure as I don't remember the held lock not being found elsewhere in the thread dump. This also is a rather atypical application. A few suggestions:
- Try kill -3 <pid> to get a thread dump, perhaps it will show something more conclusive (although, allegedly, both jstack and kill -3 dumps are expected to be same).
- Are there multiple JVM's embedded in the same process? I see that #1810850 is waiting to lock a Class object which suggests that there may be a class loading race.
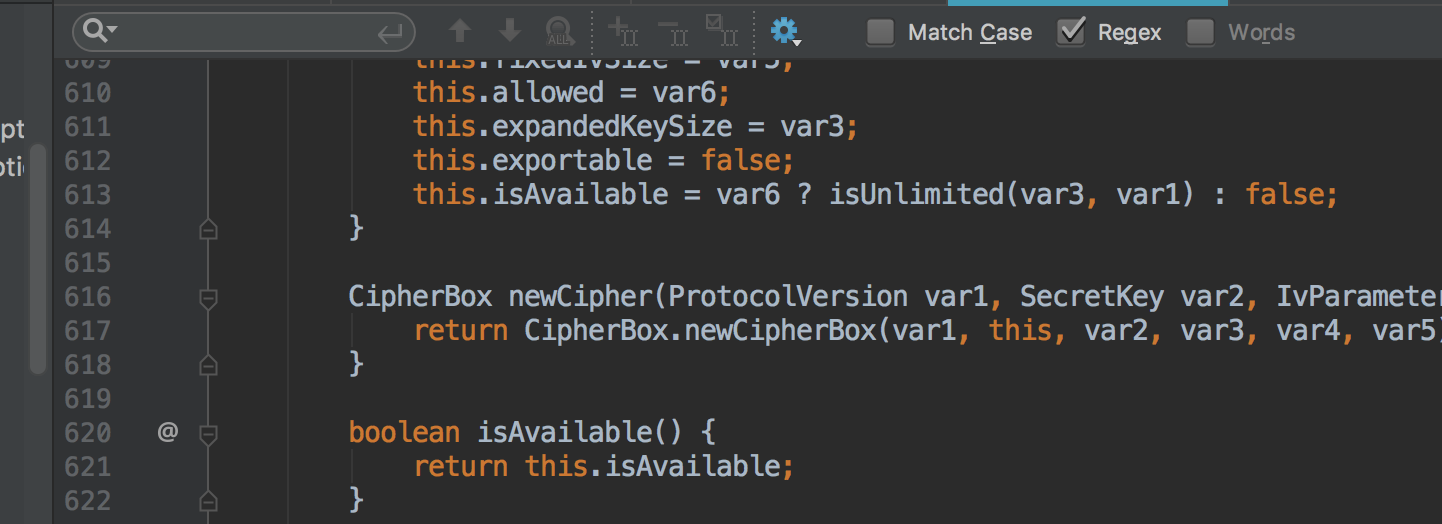
- Can you try with a more recent build (e.g. JDK 1.8.0_144)? I see the following code in BlockCipher.java and the line numbers do not seem to match.
Regards,
Kedar
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Kirk Pepperdine
Oct 11, 2017, 3:29:43 AM10/11/17
to mechanica...@googlegroups.com
Not at all off topic… first, thread dumps lie like a rug… and here is why…
for each thread {
safe point
create stack trace for that thread
release threads from safe point
}
And while rugs may attempt to cover the debris that you’ve swept under them, that debris leaves a clearly visible lump that suggests that you have a congestion problem on locks in both sun.security.provider.Sun and java.lang.Class…. What could possibly go wrong?
Kind regards,
Kirk
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.

Avi Kivity
Oct 11, 2017, 4:27:17 AM10/11/17
to mechanica...@googlegroups.com, Kirk Pepperdine
If this is not off topic, what is the topic of this group?
Is it a Java support group, or a "coding in a way that exploits
the way the hardware works" group?
Todd Lipcon
Oct 11, 2017, 6:08:20 AM10/11/17
to mechanica...@googlegroups.com
On Wed, Oct 11, 2017 at 12:29 AM, Kirk Pepperdine <ki...@kodewerk.com> wrote:
Not at all off topic… first, thread dumps lie like a rug… and here is why…for each thread {safe pointcreate stack trace for that threadrelease threads from safe point}And while rugs may attempt to cover the debris that you’ve swept under them, that debris leaves a clearly visible lump that suggests that you have a congestion problem on locks in both sun.security.provider.Sun and java.lang.Class…. What could possibly go wrong?
Interesting. I remember investigating this back in the Java 6 days and at that time 'jstack -l' caused a global safepoint before iterating over the threads, and then only resumed upon completion (implemented by VM_ThreadDump in vm_operations.cpp). It appears that in JDK 7 this was switched over to the behavior that you describe.
Either way, I'm looking at about 10 stack traces taken over a period of 3 minutes and they have 100% identical "java-level deadlock" output. So I suppose it's possible that they are live-locked on the same sets of locks in the exact same threads but seems fairly unlikely.
As for the congestion problem, I did find this JDK bug the other day: https://bugs.openjdk.java.net/browse/JDK-8133070 which aims to reduce contention, but no mention of a deadlock. We'll probably ask the customer to bump to a newer JDK with this fix and see if it magically goes away.
-Todd
Kirk Pepperdine
Oct 11, 2017, 6:48:18 AM10/11/17
to mechanica...@googlegroups.com
My vote is for live lock.. but that would be conditional on seeing all the stack traces.
— Kirk

Henri Tremblay
Oct 11, 2017, 8:07:14 AM10/11/17
to mechanica...@googlegroups.com
I will go for live lock as well. But yes, stack dumps lie. I think jstack -F might be harsher and give a different result.
But that said, you still have a deadlock. As mentioned
"New I/O worker #1810850" waiting on 0x0000000080ac88f0 is held by "New I/O worker #1810853" <-- waiting for one another
"New I/O worker #1810853" waiting on 0x00000000802ba7f8 is held by "New I/O worker #1810850" <-- waiting for one another
My question would be: Why is kudu wanting to get so much SSLContexts? Can't it reuse them? (I don't know the api well, so maybe it's normal)
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.

Alex Bagehot
Oct 11, 2017, 8:51:25 AM10/11/17
to mechanica...@googlegroups.com
On Wed, Oct 11, 2017 at 11:07 AM, Todd Lipcon <to...@lipcon.org> wrote:
On Wed, Oct 11, 2017 at 12:29 AM, Kirk Pepperdine <ki...@kodewerk.com> wrote:Not at all off topic… first, thread dumps lie like a rug… and here is why…for each thread {safe pointcreate stack trace for that threadrelease threads from safe point}And while rugs may attempt to cover the debris that you’ve swept under them, that debris leaves a clearly visible lump that suggests that you have a congestion problem on locks in both sun.security.provider.Sun and java.lang.Class…. What could possibly go wrong?Interesting. I remember investigating this back in the Java 6 days and at that time 'jstack -l' caused a global safepoint before iterating over the threads, and then only resumed upon completion (implemented by VM_ThreadDump in vm_operations.cpp). It appears that in JDK 7 this was switched over to the behavior that you describe.Either way, I'm looking at about 10 stack traces taken over a period of 3 minutes and they have 100% identical "java-level deadlock" output. So I suppose it's possible that they are live-locked on the same sets of locks in the exact same threads but seems fairly unlikely.
To consume cputime in livelock they would need to wakeup and then switch out in between the before/after thread dumps that show the blocked threads. This could be observed with perf sched wakeup/switch events (filtered on the task id of interest), or cpu samples.
A similar issue was reported here: http://mail.openjdk.java.net/pipermail/core-libs-dev/2016-February/038657.html
Thanks
Alex
As for the congestion problem, I did find this JDK bug the other day: https://bugs.openjdk.java.net/browse/JDK-8133070 which aims to reduce contention, but no mention of a deadlock. We'll probably ask the customer to bump to a newer JDK with this fix and see if it magically goes away.-Todd
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.

Jarkko Miettinen
Oct 11, 2017, 9:06:16 AM10/11/17
to mechanical-sympathy
keskiviikko 11. lokakuuta 2017 11.27.17 UTC+3 Avi Kivity kirjoitti:
If this is not off topic, what is the topic of this group?
Is it a Java support group, or a "coding in a way that exploits the way the hardware works" group?
I have to agree here with Avi. Better to have a group for "coding in a way that exploits the way the hardware works" and another group for Java support. Otherwise there will be a lot of discussion of no real relation to the topic except that people exploiting mechanical sympathy might have run into such problems.
(I would also be interested in a Java support group for the level of problems that have been posted in this group before.)
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.

Gil Tene
Oct 12, 2017, 11:48:09 AM10/12/17
to mechanical-sympathy
While jstack and thread dumps may be sampling threads outside of a global safepoint (not sure about whether they do that for their deadlock analysis), which can cause a live-lock to appear like you describe above in the set of thread dumps, I'm fairly certain that findDeadlockedThreads performs it's analysis using a global safepoint (I see deadlock detection safepoints reported in GC logs often). Todd, can you add findDeadlockedThreads from within the application and see if also reports the same deadlock? If it does, there are no thread-stack sampling races involved, as once you actually reach a deadlock, non of those thread would be moving.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-sympathy+unsub...@googlegroups.com.
Gil Tene
Oct 12, 2017, 12:09:06 PM10/12/17
to mechanica...@googlegroups.com
The "machine" we run on is not just the hardware. It's also the BIOS, the hypervisor, the kernel, the container system, the system libraries, and the various runtimes. Stuff that is "interesting" and "strange" about how the machine seems to behave is very appropriate to this group, IMO. And mysterious deadlock behaviors and related issues at the machine level (e.g. an apparent deadlock where no lock owner appears to exist, as is the case discussed here) is certainly an "interesting" machine behavior. Java for not. libposix or not, Linux or not. C#/C++/Rust or not. The fact that much of concurrency work happens to be done in Java does make Java and JVMs a more common context in which these issues are discussed, but the same can be said about Linux, even tho this is not a Linux support group.
E.g. the discussion we had a while back about Linux's futex wakeup bug (where certain kernel versions failed to wake up futex's, creating [among other things] apparent deadlocks in non-deadlocking code) was presumably appropriate for this group. I see Todd's query as no different. It is not a "help! my program has a deadlock" question. It is an observed "deadlock that isn't a deadlock" question. It may be a bug in tooling/reporting (e.g. tooling might be deducing the deadlock based on non-atomic sampling of stack state as some have suggested here), or it may be a bug in the lock mechanisms. e.g. failed wakeup at the JVM level. Either way, it would be just as interesting and relevant here as a failed wakeup or wrong lock state intrumentation at the Linux kernel level. or at the .NET CLR level, or at the golang runtime level, etc...

ben.c...@alumni.rutgers.edu
Oct 12, 2017, 12:26:11 PM10/12/17
to mechanica...@googlegroups.com, Mark Little, Peter Lawrey
Thanks Gil (as always!). Whether or not 'the software is the computer' or 'the silicon is the computer' or 'the network is the computer' ... how about this:
The COMPUTATION is the computer?
With admiration and appreciation,
Ben
On Thu, Oct 12, 2017 at 12:09 PM Gil Tene <g...@azul.com> wrote:
The "machine" we run on is not just the hardware. It's also the BIOS, the hypervisor, the kernel, the container system, the system libraries, and the various runtimes. Stuff that is "interesting" and "strange" about how the machine seems to behave is very appropriate to this group, IMO. And mysterious deadlock behaviors and related issues the machine level (e.g. an apparent deadlock where no lock owner appears to exist, as is the case discussed here) is certainly an "interesting" machine behavior. Java for not. libposix or not, Linux or not. C#/C++/Rust or not. The fact that much of concurrency work happens to be done in Java does make Java and JVMs a more common context in which these issues are discussed, but the same can be said about Linux, even tho this is not a Linux support group.E.g. the discussion we had a while back about Linux's futex wakeup bug (where certain kernel versions failed to wake up futex's, creating ()among other things) apparent deadlocks in non-deadlocking code) was presumably appropriate for this group. I see Todd's query as no different. It is not "my program has a deadlock" question. It is an observed "deadlock that isn't a deadlock" question. It may be a bug in tooling/reporting (e.g. tooling might be deducing the deadlock based on non-atomic sampling of stack state as some have suggested here), or it may be a bug in the lock mechanisms. e.g. failed wakeup at the JVM level. Either way, to would be just as interesting and relevant here as a failed wakeup or wrong lock state intrumentation at the Linux kernel level. or at the .NET CLR level, or at the golang runtime level, etc...
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.

Martin Thompson
Oct 12, 2017, 2:12:31 PM10/12/17
to mechanical-sympathy
I agree with Gil here. I often reject posts via moderation which range from things that should be in the lazy section for Stackoverflow or recruiters taking the piss. This question is from someone who has made good contributions to previous discussions and is posing a question that is trying to get to the bottom of something which is "befuddling" to someone trying to understand the mechanisms of a platform. To paraphrase Jackie Stewart who coined the mechanical sympathy phrase, to work in harmony with the machine one must understand the machine. If this was a question about the syntax of the Java language then that would be different.
Martin...
In my own experiences I've often found discussions about managed runtimes and VMs in languages other than Java, which while not directly applicable, can be informative and give insights into the thinking behind the design of the "machine" on which we run. I don't write code in Pony or Rust for a living but studying the underlying implementations gives real insights into the possible future directions for memory management which is core to the "machine" for example.
I feel it is also valid to question the appropriateness and context for discussions. It is healthy to check our assumptions. We all win when discussions are civil and present opportunities to learn.
I feel it is also valid to question the appropriateness and context for discussions. It is healthy to check our assumptions. We all win when discussions are civil and present opportunities to learn.
Martin...
Message has been deleted
Kirk Pepperdine
Oct 12, 2017, 4:12:37 PM10/12/17
to mechanica...@googlegroups.com
I think this was my original position. I was taken aback to suggest that it wasn’t interesting enough to be discussed here. Stack traces can be quite confusing but they can be key to understanding what’s going on.
Regards,
Kirk
Regards,
Kirk
Todd Lipcon
Feb 26, 2019, 7:56:31 PM2/26/19
to mechanica...@googlegroups.com
In case anyone else is running into similar issues, we're currently thinking it might be this JVM bug:
(very similar symptoms)
-Todd
--
You received this message because you are subscribed to the Google Groups "mechanical-sympathy" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mechanical-symp...@googlegroups.com.
Reply all
Reply to author
Forward
0 new messages