MathPiper Lesson 4: Parsing and the language of expression trees
16 views
Skip to first unread message

Ted Kosan
May 9, 2016, 8:30:45 PM5/9/16
to mathf...@googlegroups.com
The rest of the lessons in this “course” will be placed into MathPiper
worksheets and maybe some videos. This lesson contains a short
description of parsing and an explanation of expression trees (which
uses numerous diagrams). Even if you have not been following the
lessons up to this point, I encourage you to read through this lesson
on expression trees because they are easy to understand, and because
they are part of the foundation of mathematics and computer
programming.
Here is the link to the lesson:
http://patternmatics.org/temp_1/mathfuture/lesson4/
Joe, the explanation for how pattern matching works in MathPiper has
been moved to the next lesson.
There is no assignment for this lesson other than updating to
MathPiperIDE version .897 if you would like to experiment with the
above worksheet.
If anyone has questions, comments, or bug reports, please submit them
to the Math Future group.
Ted
worksheets and maybe some videos. This lesson contains a short
description of parsing and an explanation of expression trees (which
uses numerous diagrams). Even if you have not been following the
lessons up to this point, I encourage you to read through this lesson
on expression trees because they are easy to understand, and because
they are part of the foundation of mathematics and computer
programming.
Here is the link to the lesson:
http://patternmatics.org/temp_1/mathfuture/lesson4/
Joe, the explanation for how pattern matching works in MathPiper has
been moved to the next lesson.
There is no assignment for this lesson other than updating to
MathPiperIDE version .897 if you would like to experiment with the
above worksheet.
If anyone has questions, comments, or bug reports, please submit them
to the Math Future group.
Ted

kirby urner
May 9, 2016, 9:13:19 PM5/9/16
to mathf...@googlegroups.com
I'm looking forward to diving in to the Kosan curriculum more.
I've been on the road yet managing to follow lots of threads.
Today's infrastructure makes traveling well supported by a lot of intelligent devices, as well as people. Fun syncing Android and iPhone to dashboard of rented Sonata.
Mom, 87, is care of Delta, in route through Detroit. I'm well taken care of in Champaign Illinois. With coworker Kerry of code school heritage. Back in Portland by tomorrow.
Kirby
Ted Kosan
May 10, 2016, 8:50:17 PM5/10/16
to mathf...@googlegroups.com
Version .897 of MathPiperIDE had a bug in it that caused output folds
to overwrite non-output folds, so if you installed v.897, delete it
and install v.898.
Also, the lesson 4 worksheet had a bug in it so I replaced it. The new
version is v.02.
Ted
to overwrite non-output folds, so if you installed v.897, delete it
and install v.898.
Also, the lesson 4 worksheet had a bug in it so I replaced it. The new
version is v.02.
Ted

Joseph Austin
May 11, 2016, 11:01:16 AM5/11/16
to mathf...@googlegroups.com
On May 10, 2016, at 8:50 PM, Ted Kosan <ted....@gmail.com> wrote:Version .897 of MathPiperIDE had a bug in it that caused output folds
to overwrite non-output folds, so if you installed v.897, delete it
and install v.898.
Also, the lesson 4 worksheet had a bug in it so I replaced it. The new
version is v.02.
Ted,
I seem to have not noticed the bugs on the 897, 01 versions.
I note in the new version, there are two copies of output for 361-372.
--
Going beyond the immediate exercise,
I tried MathParse on a couple standard formulas with mixed results:
In> MathParse("ax^2+bx+c");
Result: (_a*_x^2 + _b*_x) + _c
In> MathParse("E=1/2mv^2");
Result: _E == (1 / 2*_m)*_v^2
In> MathParse("PV=nRT");
Result: _P
In> MathParse("pv=nrT");
Result: _p*_v == _n*_r
The first, a standard polynomial form, came out as expected.
The second, a physics formula for kinetic energy, is correct under your precedence with / ahead of *, or even standard left-right precedence with / * equal.
But the last two, the gas law, suggest that the system has trouble with capital letter names. This would be more of an issue in Physics than in math.
Joe Austin
Ted Kosan
May 12, 2016, 12:13:00 AM5/12/16
to mathf...@googlegroups.com
Joe wrote:
> I tried MathParse on a couple standard formulas with mixed results:
>
> In> MathParse("ax^2+bx+c");
> Result: (_a*_x^2 + _b*_x) + _c
>
> In> MathParse("E=1/2mv^2");
> Result: _E == (1 / 2*_m)*_v^2
>
> In> MathParse("PV=nRT");
> Result: _P
>
> In> MathParse("pv=nrT");
> Result: _p*_v == _n*_r
>
> The first, a standard polynomial form, came out as expected.
> The second, a physics formula for kinetic energy, is correct under your
> precedence with / ahead of *, or even standard left-right precedence with /
> * equal.
>
> But the last two, the gas law, suggest that the system has trouble with
> capital letter names. This would be more of an issue in Physics than in
> math.
This parser has an interesting story. I obtained the original version
> I tried MathParse on a couple standard formulas with mixed results:
>
> In> MathParse("ax^2+bx+c");
> Result: (_a*_x^2 + _b*_x) + _c
>
> In> MathParse("E=1/2mv^2");
> Result: _E == (1 / 2*_m)*_v^2
>
> In> MathParse("PV=nRT");
> Result: _P
>
> In> MathParse("pv=nrT");
> Result: _p*_v == _n*_r
>
> The first, a standard polynomial form, came out as expected.
> The second, a physics formula for kinetic energy, is correct under your
> precedence with / ahead of *, or even standard left-right precedence with /
> * equal.
>
> But the last two, the gas law, suggest that the system has trouble with
> capital letter names. This would be more of an issue in Physics than in
> math.
of the parser from the Khan Academy repository. Just after I obtained
it the Khan Academy developers deprecated the parser and switched to
another one that was not well suited for my needs.
Here is the section of the parser that does not recognize capital
letters as being variables:
if (c >= 65 && c <= 90) {
lexeme += String.valueOf((char)c);
return TK_COEFF;
} else if (c >= 97 && c <= 122) {
lexeme += String.valueOf((char)c);
return TK_VAR;
}
Evidently the programmers who wrote this parser considered upper case
letters to be coefficients. I modified this section of code to make
all upper and lower case letters be variables, and it enabled all of
your examples to work as desired:
/* if (c >= 65 && c <= 90) {
lexeme += String.valueOf((char)c);
return TK_COEFF;
} else */
if (c >= 65 && c <= 90 || c >= 97 && c <= 122) {
lexeme += String.valueOf((char)c);
return TK_VAR;
}
In> MathParse("ax^2+bx+c");
Result: (_a*_x^2 + _b*_x) + _c
In> MathParse("E=1/2mv^2");
Result: _E == (1/2*_m)*_v^2
In> MathParse("PV=nRT");
Result: _P*_V == (_n*_R)*_T
In> MathParse("ax^2+bx+c");
Result: (_a*_x^2 + _b*_x) + _c
In> MathParse("E=1/2mv^2");
Result: _E == (1/2*_m)*_v^2
In> MathParse("PV=nRT");
In> MathParse("pv=nrT");
Result: _p*_v == (_n*_r)*_T
TK_COEFF is not used anywhere else in the program, so removing its use
here should not break the parser. Does anyone know what the
programmers who wrote this parser may have had in mind by treating
upper case letters as coefficients?
Ted

michel paul
May 12, 2016, 11:37:10 AM5/12/16
to mathf...@googlegroups.com
If we read the expression tree top-down row by row and write it in operator prefix form (operator left-node right-node):
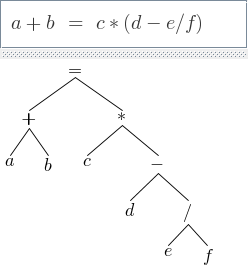
we can condense the tree to a functional one-liner: (= (+ a b) (* c (– d (/ e f))))
Ted
--
You received this message because you are subscribed to the Google Groups "MathFuture" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mathfuture+...@googlegroups.com.
To post to this group, send email to mathf...@googlegroups.com.
Visit this group at https://groups.google.com/group/mathfuture.
For more options, visit https://groups.google.com/d/optout.
===================================
"What I cannot create, I do not understand."
"What I cannot create, I do not understand."
- Richard Feynman
==================================="Computer science is the new mathematics."
- Dr. Christos Papadimitriou
===================================
===================================
kirby urner
May 12, 2016, 12:06:03 PM5/12/16
to mathf...@googlegroups.com
On Wed, May 11, 2016 at 9:13 PM, Ted Kosan <ted....@gmail.com> wrote:
TK_COEFF is not used anywhere else in the program, so removing its use
here should not break the parser. Does anyone know what the
programmers who wrote this parser may have had in mind by treating
upper case letters as coefficients?
Ted
Hi Ted --
I'm forgetting the precise definition of coefficients at the moment, are they
confined to polynomials. Any algebraic expression?
A matrix is often named with an uppercase letter and very often supply
coefficients to vector variables.
A matrix is often named with an uppercase letter and very often supply
coefficients to vector variables.
A subset of math notations insist on single letters as names, banning such
commonplace computer language cliches as energy = mass * pow(c, 2) etc.
These single letters are then given connotations, in addition to denotations,
within this or that namespace. For example lowercase theta (θ) tends to
mean "the measure of an angle" in many texts, and is used as a variable.
mean "the measure of an angle" in many texts, and is used as a variable.
e gets raised to the i θ, with e and i fixed, θ taking us around the perimeter
of a unit circle, usually shown like a clock running counter-clockwise but
of a unit circle, usually shown like a clock running counter-clockwise but
why not walk around to the back? It'll be seen to move clockwise to this
other observer (some maths don't seem to believe in any observer, or
think there's just one).
Greek phi in lowercase may be the totient function (a defined process)
or the golden mean (a fixed constant). Today's computer languages may
well allow using both upper and lowercase phi directly, whereas in the
recent passed they had more limited character sets. Greek phi in
or the golden mean (a fixed constant). Today's computer languages may
well allow using both upper and lowercase phi directly, whereas in the
recent passed they had more limited character sets. Greek phi in
uppercase tends to go with uppercase sigma, as a while or for loop
operator, with multiplication (taking a product of all the terms) it's
theme.
Executable math notations also need to formalize naming, in the sense
of binding a name to some object that may be fixed (a constant, immutable)
or changing (a variable, mutable). a = 3 is not an assertion of a pre-existing
truth so much as a binding whereby lowercase 'a' is now usable in place of
3 in future expressions. a = a + 1 looks odd to those unfamiliar with
"rebinding" i.e. using the same name with some new or next object.
The notion of "mathematics as a universal language" is more confusing
than it needs to be. "A set of languages L that share a certain family
resemblance to one another" would be more explicit and leave more
room for plurality, as in the English "maths" (in the US they tend to say
"math" in the singular, further obscuring that L is plural).
Any given L may vary in how machine-executable it is, while remaining
human-readable at the same time. I've used the symbol:
Mx <-- L --> Hx
Mx <-- L --> Hx
however the more standard convention would to make Mx an x-axis and
Hx a y-axis.
Map the Ls.
An issue there is Mx tends to be yes or no i.e. either an L is machine-
executable, or not.
Not really true though as we may judge typographically-evolved pre-
computer notations in light of how closely a CAS such as Mathematica
or MathCad or MathPiper could render them as food for their respective
evaluation engines.
Map the Ls.
An issue there is Mx tends to be yes or no i.e. either an L is machine-
executable, or not.
Not really true though as we may judge typographically-evolved pre-
computer notations in light of how closely a CAS such as Mathematica
or MathCad or MathPiper could render them as food for their respective
evaluation engines.
Another issue is "human readability" is in the eye of the beholder.
Claims to a language to being "human readable" should be with
reference to a specific readership, just as "machine readable" is
dependent on "what machine".
Kirby
Ted Kosan
May 12, 2016, 9:24:20 PM5/12/16
to mathf...@googlegroups.com
> We can condense the tree to a functional one-liner: (= (+ a b) (* c (– d (/ e f))))
In> expression := '((a+b)==(c*(d - e / f)));
Result: a + b == c*(d - e/f)
In> UnparseLisp(expression, OneLine:True)
Side Effects:
(== (+ a b) (* c (- d (/ e f))))
MathPiper can also parse strings that are in "functional" form:
In> PipeFromString("(== (+ a b) (* c (- d (/ e f))))") ParseLisp();
Result: a + b == c*(d - e/f)
Internally, MathPiper holds all of the trees it parses in lists which are in this functional form:
In> Show(ListView('(a+b+c), Resizable:False, Scale:1.7));>
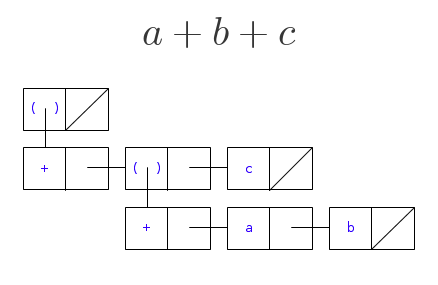
Ted
Reply all
Reply to author
Forward
0 new messages