CUDArt gc
87 views
Skip to first unread message

davidino
Nov 28, 2015, 12:19:29 PM11/28/15
to julia-users
Hi
I'm looking into using CUDArt but am struggling with a basic issue.
Following the simple vadd example,
extern "C"
{
__global__ void vadd(const int n, const double *a, const double *b, double *c)
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i<n)
{
c[i] = a[i] + b[i];
}
}
}
I wrote julia code to repeatedly add two matrices:
using CUDArt, PyPlot
CUDArt.init([0])
md=CuModule("vadd.ptx",false)
kernel=CuFunction(md,"vadd")
function vadd(A::CudaArray,B::CudaArray,C::CudaArray)
nblocks=round(Int,ceil(length(B)/1024))
launch(kernel,nblocks,1024,(length(A),A,B,C))
end
N=2000
A=CudaArray(rand(N,N))
B=CudaArray(rand(N,N))
C=CudaArray(zeros(N,N))
M=2000
tm=zeros(M)
for i in 1:M
#if i==1000 gc() end
tic()
vadd(A,B,C)
tm[i]=toc()
end
plot(tm[10:end])
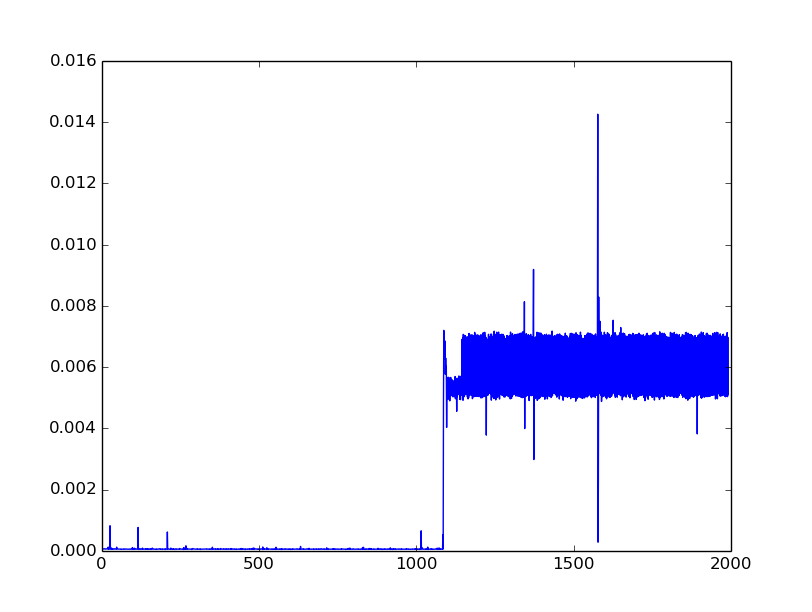
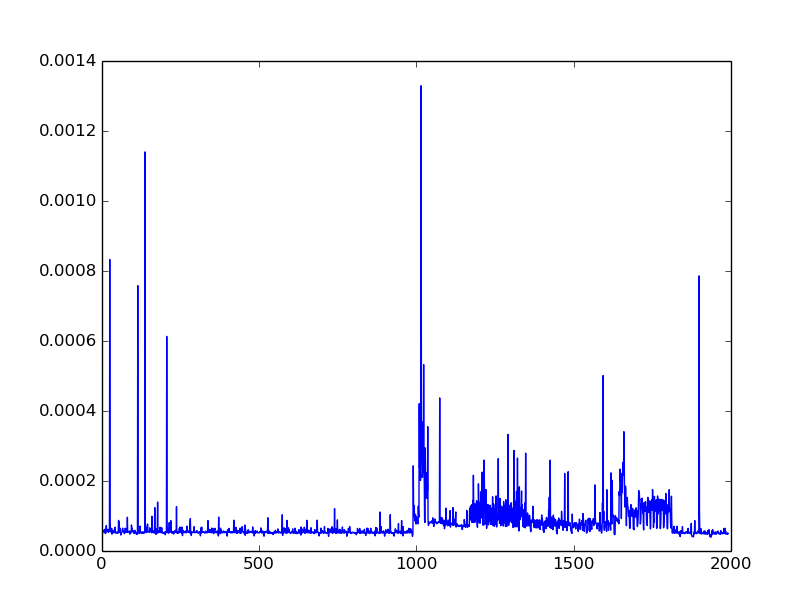
The addition of the two matrices goes super fast for about 1000 iterations, but then dramatically slows (see nogc.png). However, if I gc() after 1000 iterations (this single gc step takes a few seconds to run) then things run quickly again (see withgc.png).
Is there any way to avoid having to manually add gc()?
I'm also confused where (presumably) the memory leak could be coming from. Much of my work involves iterative algorithms, so I really need to figure this out before using this otherwise awesome tool.
I'm running this on a Jetson TK1. I've tried several different nvcc compile options and all exhibit the same behaviour.
Many thanks,
David
I'm looking into using CUDArt but am struggling with a basic issue.
Following the simple vadd example,
extern "C"
{
__global__ void vadd(const int n, const double *a, const double *b, double *c)
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i<n)
{
c[i] = a[i] + b[i];
}
}
}
I wrote julia code to repeatedly add two matrices:
using CUDArt, PyPlot
CUDArt.init([0])
md=CuModule("vadd.ptx",false)
kernel=CuFunction(md,"vadd")
function vadd(A::CudaArray,B::CudaArray,C::CudaArray)
nblocks=round(Int,ceil(length(B)/1024))
launch(kernel,nblocks,1024,(length(A),A,B,C))
end
N=2000
A=CudaArray(rand(N,N))
B=CudaArray(rand(N,N))
C=CudaArray(zeros(N,N))
M=2000
tm=zeros(M)
for i in 1:M
#if i==1000 gc() end
tic()
vadd(A,B,C)
tm[i]=toc()
end
plot(tm[10:end])
The addition of the two matrices goes super fast for about 1000 iterations, but then dramatically slows (see nogc.png). However, if I gc() after 1000 iterations (this single gc step takes a few seconds to run) then things run quickly again (see withgc.png).
Is there any way to avoid having to manually add gc()?
I'm also confused where (presumably) the memory leak could be coming from. Much of my work involves iterative algorithms, so I really need to figure this out before using this otherwise awesome tool.
I'm running this on a Jetson TK1. I've tried several different nvcc compile options and all exhibit the same behaviour.
Many thanks,
David

{kind=link}
{kind=link}
Tim Holy
Nov 28, 2015, 3:28:12 PM11/28/15
to julia...@googlegroups.com
Are you sure you're not being fooled by asynchronous operations? launch
doesn't wait for the kernel to finish before returning. Since gc is a slow
call, you're presumably just giving the GPU time to catch up on its queue,
which creates the opportunity to schedule more operations.
In other words, you might observe the same phenomenon with sleep(0.1) that
you're seeing with gc().
--Tim
doesn't wait for the kernel to finish before returning. Since gc is a slow
call, you're presumably just giving the GPU time to catch up on its queue,
which creates the opportunity to schedule more operations.
In other words, you might observe the same phenomenon with sleep(0.1) that
you're seeing with gc().
--Tim
davidino
Nov 29, 2015, 4:15:25 AM11/29/15
to julia-users
Ah, I see -- a newbie error!
Adding a CUDArt.device_synchronize() call after the loop shows that indeed it's just the GPU catching up.
Many thanks Tim (big fan of your work).
David
Adding a CUDArt.device_synchronize() call after the loop shows that indeed it's just the GPU catching up.
Many thanks Tim (big fan of your work).
David
Reply all
Reply to author
Forward
0 new messages