Gremlin Server + Spark
1,023 views
Skip to first unread message

Stephen Mallette
Oct 1, 2015, 1:55:50 PM10/1/15
to Gremlin-users, d...@tinkerpop.incubator.apache.org
I spent some time this morning to see if I could execute a Spark-based traversal remotely in Gremlin Server - and......it worked! Didn't even have to really make any code changes for it to happen either though I did make some minor adjustments to streamline some things, but all-in-all, there wasn't much to it.
Here's my step-by-step of the process. First of all, these instructions are based on the latest 3.1.0-SNAPSHOT (master branch). You need to be sure you have Hadoop 2.x running in psuedo distributed mode - in other words, be sure that you can execute a spark traversal locally from Gremlin Console (if that works, it should work for Gremlin Server).
To get started, you'll need to open two terminals - one for Gremlin Server and the other for Gremlin Console. I had to set the CLASSPATH in both:
export CLASSPATH=/hadoop-2.7.1/etc/hadoop
and in the appropriate terminal (server or console) set HADOOP_GREMLIN_LIBS:
export HADOOP_GREMLIN_LIBS=/apache-gremlin-console-3.1.0-SNAPSHOT/spark-gremlin/lib
export HADOOP_GREMLIN_LIBS=/apache-gremlin-server-3.1.0-SNAPSHOT/ext/spark-gremlin/lib
I then started up bin/gremlin.sh and installed the spark plugin:
gremlin> :install org.apache.tinkerpop spark-gremlin 3.1.0-SNAPSHOT
I restart the console as instructed and activate my plugins:
gremlin> :plugin use tinkerpop.hadoop
==>tinkerpop.hadoop activated
gremlin> :plugin use tinkerpop.spark
==>tinkerpop.spark activated
I then copy my graph data to hdfs:
gremlin> hdfs.copyFromLocal('data/tinkerpop-modern.kryo','tinkerpop-modern.kryo')
==>null
gremlin> hdfs.ls()
==>rw-r--r-- smallette supergroup 781 tinkerpop-modern.kryo
Then we switch gears to the terminal that will run Gremlin Server and "install" spark:
bin/gremlin-server.sh -i org.apache.tinkerpop spark-gremlin 3.1.0-SNAPSHOT
which will copy down appropriate dependencies the same way the Gremlin Console :install command does. Then we start gremlin server with:
bin/gremlin-server.sh conf/gremlin-server-spark.yaml
This new config file is now packaged with the Gremlin Server distribution when you build it. It's pretty well documented and should point you to how stuff works. You can see it here:
Now in the Gremlin Server terminal you should see the standard startup logging which should include some lines like this:
[INFO] GraphManager - Graph [graph] was successfully configured via [conf/hadoop-gryo.properties].
...
[INFO] GremlinExecutor - Initialized gremlin-groovy ScriptEngine with scripts/spark.groovy
...
[INFO] ServerGremlinExecutor - A GraphTraversalSource is now bound to [g] with graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]
If you see that much, you should be good to go, head back to the Gremlin Console terminal and do:
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Connected - localhost/127.0.0.1:8182
gremlin> :> g.V().count()
==>6
gremlin> :> g.V().out().out().values('name')
==>lop
==>ripple
It was good to confirm that this works as expected. This information should be especially useful to those not on the JVM who need a way to execute OLAP based traversals.
Stephen

Harsh Thakkar
Dec 6, 2017, 9:10:06 AM12/6/17
to Gremlin-users
Hi Stephen,
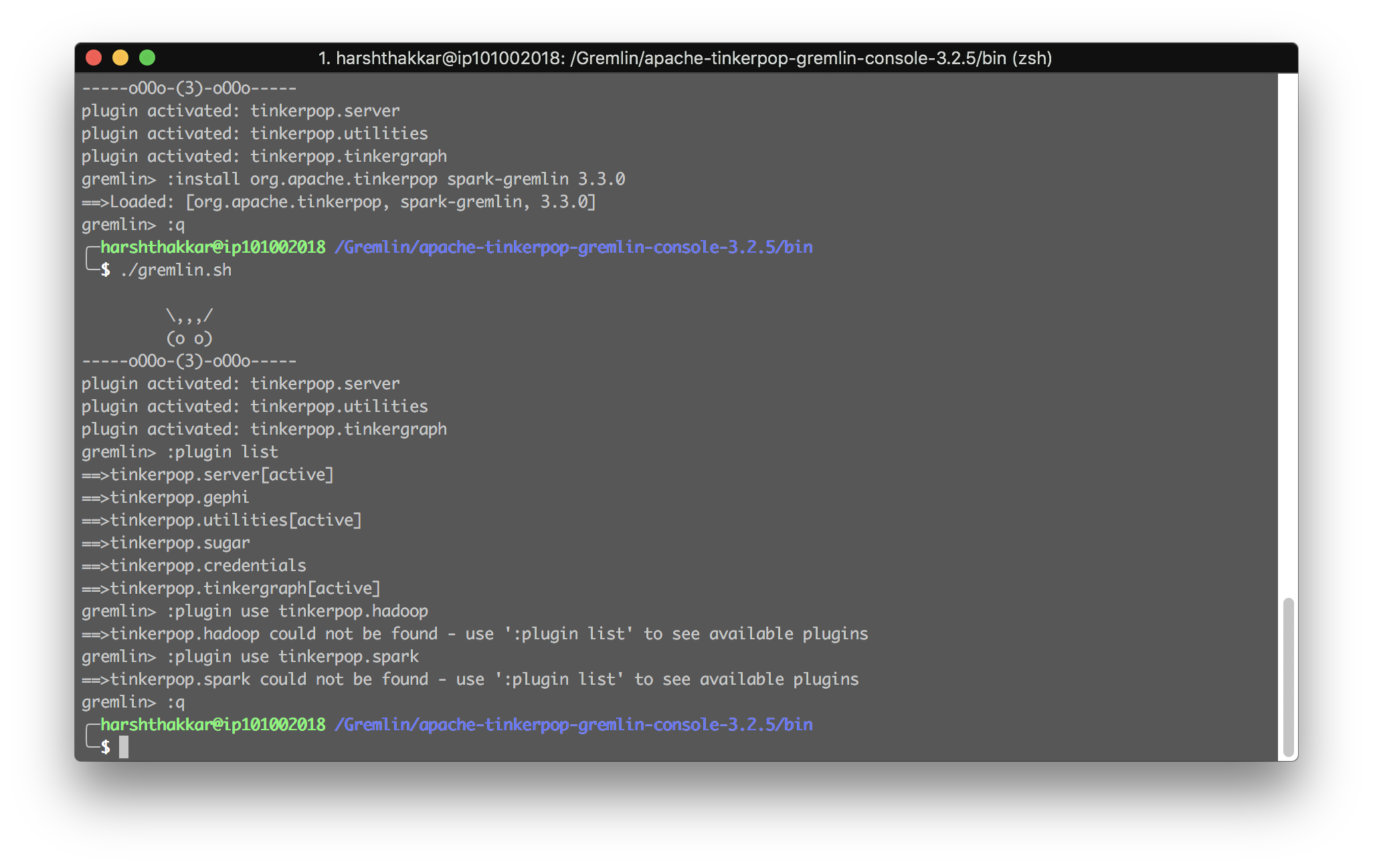
I set up the pseudo-distributed nodes in Hadoop (1 node setup) on my mac, and then basically followed your steps: exported the paths and hadoop_gremlin_libs. However, I am not able to activate the plugins. I can install the 3.3.0 Hadoop-Gremlin and spark-gremlin plugins, but they do not get listed by the :plugin list command. I am not sure why this is happening. Attaching a snapshot of my terminal.
Some help would be appreciated. Please let me know if you want me to print some other configs or details, would be happy to do so.
P.S. I am trying to test the spark-gremlin plugin for some of my work (supporting sparql querying using gremlin, then distributing them using the spark-gremlin plugin over a cluster).
Stephen Mallette
Dec 6, 2017, 9:22:46 AM12/6/17
to Gremlin-users
not sure if starting from within the bin/ directory is the problem. maybe go up a level and do bin/gremlin.sh when you execute all of those commands. after :install you should see the related jars in the /ext directory somewhere....if not, i'd find out where those are going since it's executing successfully (it seems that way at least from your screenshot).
--
You received this message because you are subscribed to the Google Groups "Gremlin-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-users+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/814b786f-2063-4749-879b-fa3724910d91%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Harsh Thakkar
Dec 6, 2017, 10:06:21 AM12/6/17
to Gremlin-users
Hi Stephen.
I did that too. The jars are in that exact place in their respective folders. However, still no luck. Same problem. The plugins are not listed.
I have attached the snapshot of my ext/ folder too.
I am using the 3.2.5 version of Gremlin, do you think this is the issue? Should I use 3.3.0 plugins with only 3.3.0 version of Gremlin console? (also am using console not server!)
Can you elaborate a bit more on the Hadoop setup? I think that should help a bit.
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-user...@googlegroups.com.
Stephen Mallette
Dec 6, 2017, 10:10:22 AM12/6/17
to Gremlin-users
> Should I use 3.3.0 plugins with only 3.3.0 version of Gremlin console?
I would not mix/match versions if possible. That is likely your problem. We changed the plugin system in a breaking way between 3.2.x and 3.3.x. Package naming for plugins changed and I bet the console just can't find the plugins as a result.
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-users+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/c8ca235f-a13a-44a3-a651-91a44954cdb9%40googlegroups.com.

Dharmen Punjani
Dec 6, 2017, 11:21:03 AM12/6/17
to Gremlin-users
Hello Stephen,
Is it possible to run "Spark-Gremlin" from Maven Java project ? If yes do you know where I can find the tutorials to do so ?
Thanks a lot in advance.
Stephen Mallette
Dec 6, 2017, 11:40:07 AM12/6/17
to Gremlin-users
The code you execute in the Console is equally executable as Java code. It's all just Gremlin. This example from the reference documentation:
http://tinkerpop.apache.org/docs/current/reference/#sparkgraphcomputer
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> g = graph.traversal().withComputer(SparkGraphComputer)
==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]
gremlin> g.V().count()
==>6
is basically just Java code:
Graph graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties');
GraphTraversalSource g = graph.traversal().withComputer(SparkGraphComputer);
long c = g.V().count().next()
Does that make sense?
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-users+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/bab943f5-96ec-4e5d-a7c8-9b2a87dab882%40googlegroups.com.
Dharmen Punjani
Dec 6, 2017, 11:56:08 AM12/6/17
to Gremlin-users
Thanks for reply,
But how to set all diff. configuration for running it from Maven Java project?
E.g, how to set the CLASSPATH , HADOOP_GREMLIN_LIBS etc.
Stephen Mallette
Dec 6, 2017, 12:14:56 PM12/6/17
to Gremlin-users
Both of those are just environment variables. You would set them for whatever environment you were running them in. Shell scripts would look just like what you do for the console:
export GREMLIN_HADOOP_LIBS=...
If you were running inside Intellij, then you could update your run configuration to include them as needed.
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-users+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/55d6ea56-d8cd-4530-92db-36273090ed35%40googlegroups.com.
Message has been deleted
Dharmen Punjani
Dec 6, 2017, 12:41:46 PM12/6/17
to Gremlin-users
Thanks a lot.

{kind=link}
{kind=link}
{kind=link}
Ashley
Dec 13, 2017, 10:50:24 AM12/13/17
to Gremlin-users
How would you do this with an actual hadoop cluster? Export classpath of the server?
Reply all
Reply to author
Forward
0 new messages