Помогите решить задачку!
206 views
Skip to first unread message

Sergio Hunter
Dec 1, 2016, 1:53:23 PM12/1/16
to Golang Russian
Здравствуйте. У меня есть база данных в которой поле "data" имеет архивные и текстовые json строки. Мой код делает декомпресс архивных данных и вместе с текстовыми данными выгружается. Теперь мне надо из json данных которые выгрузились взять определенные типы (`json:"d"` это Date, `json:"g"` это Gold,`json:"r"` это Revenue). Далее нужно чтоб когда выводились идентичные даты они объединялись и подсчитывались, другими словами выгружаются данные из БД в csv файл в котором даты дублируются, надо чтоб они сливались в одну. Для примера 2010-11-20,"r":4.99,"g":100
2010-11-20,"r":4.99,"g":100 вот так должно быть 2010-11-20,"r":9.98,"g":200
2010-11-20,"r":4.99,"g":100 вот так должно быть 2010-11-20,"r":9.98,"g":200
Вот код, но я реально запутался там где map функция, если кто может подскажите, заранее спасибо.
package main
import (
"bytes"
"compress/zlib"
"database/sql"
"encoding/json"
"fmt"
"io/ioutil"
"log"
_ "github.com/go-sql-driver/mysql"
"strconv"
"encoding/csv"
"os"
)
var (
data []byte
)
type UserStatsData struct {
Dates map[string]Info `json:"d"`
}
type Info struct {
Date string `json:"-"`
Gold int `json:"g"`
Revenue json.Number `json:"r"`
}
func main() {
db, err := sql.Open("mysql", "name:password(127.0.0.1:port)/database")
if err != nil {
panic(err.Error())
}
defer db.Close()
rows, err := db.Query(`SELECT data FROM user_stats ORDER BY created_at LIMIT 2`)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
file, err := os.Create("result.csv")
if err != nil {
fmt.Println(err)
}
defer file.Close()
userStatsData := UserStatsData{}
cont := 0
writer := csv.NewWriter(file)
for rows.Next() {
err := rows.Scan(&data)
if err != nil {
log.Fatal(err)
}
if err := json.Unmarshal(data, &userStatsData); err != nil {
r, err := zlib.NewReader(bytes.NewReader(data))
if err != nil {
log.Panicf("\nCannot read archive %v", err)
}
r.Close()
data, _ = ioutil.ReadAll(r)
}
parsed := make(map[string]interface{})
if err := json.Unmarshal(data, &parsed); err != nil {
panic(err.Error())
}
var info []Info
for _, elem := range info {
previousValue, ok := parsed[elem.Date]
if ok {
parsed[elem.Date] = previousValue + elem.Gold
} else {
parsed[elem.Date] = elem.Gold
}
}
for _, i := range info {
if cont == 0 {
var record []string
record = append(record, "Date")
record = append(record, "Gold")
record = append(record, "Revenue")
writer.Write(record)
cont++
}
var record []string
record = append(record, i.Date)
record = append(record, strconv.Itoa(i.Gold))
record = append(record, i.Revenue.String())
writer.Write(record)
cont++
}
writer.Flush()
err = writer.Error()
if err != nil {
panic(err)
}
}
}
Sergio Hunter
Dec 2, 2016, 10:28:00 AM12/2/16
to Golang Russian
Тяжелая задачка, да?

Evgeniy Solomanidin
Dec 3, 2016, 2:23:18 AM12/3/16
to Golang Russian
Не совсем понял задачу, но вот вопрос как этот цикл может работать?
var info []Info
for _, elem := range info {
Ну и пример данных бы не мешало увидеть. Что в архиве, что не в архиве.
Sergio Hunter
Dec 3, 2016, 3:44:45 AM12/3/16
to Golang Russian
В архиве JSON данные. Это уже разархивированные
{"last_login":"2015-12-03 08:21:02 -0800","t":{"gg":11000,"2":{"g":100,"r":4.99},"g":100,"r":9.98},"h":[{"r":0,"g":500,"d":"2011-01-04"},{"g":500,"r":0,"d":"2011-05-20"},{"r":0,"g":500,"d":"2011-06-13"},{"g":500,"r":0,"d":"2011-08-16"},{"r":0,"g":500,"d":"2011-10-08"},{"r":0,"g":500,"d":"2011-11-16"},{"g":500,"r":0,"d":"2011-12-02"},{"g":1000,"r":0,"d":"2011-12-12"},{"g":1000,"r":0,"d":"2012-01-11"},{"g":5000,"r":0,"d":"2012-01-20"}],"d":{"2012-01-11":{"gg":1000,"g":0,"r":0},"2011-12-02":{"gg":500,"g":0,"r":0},"2012-01-20":{"gg":5000,"g":0,"r":0},"2011-12-12":{"gg":1000,"g":0,"r":0},"2011-08-16":{"gg":500,"g":0,"r":0},"2011-10-08":{"gg":500,"r":0,"g":0},"2010-11-04":{"gg":0,"g":0,"r":4.99},"2011-05-20":{"gg":500,"g":0,"r":0},"2011-01-04":{"gg":500,"r":0,"g":0},"2010-11-17":{"gg":500,"r":0,"g":0},"2011-06-13":{"gg":500,"r":0,"g":0},"2010-12-22":{"gg":0,"2":{"g":100,"r":4.99},"g":100,"r":4.99},"2011-11-16":{"gg":500,"r":0,"g":0}},"logins":[["2011-10-05",2],["2011-10-06",2],["2011-10-10",2],["2011-10-13",1],["2011-10-14",1],["2011-10-17",1],["2011-10-18",1],["2011-10-21",6],["2011-10-22",1],["2011-10-23",3],["2011-10-25",2],["2011-10-29",1],["2011-11-01",2],["2011-11-02",2],["2011-11-06",3],["2011-11-09",5],["2011-11-10",1],["2011-11-11",1],["2011-11-12",7],["2011-11-13",1],["2011-11-15",6],["2011-11-16",2],["2011-11-18",1],["2011-11-19",1],["2011-11-20",2],["2011-11-21",4],["2011-11-23",8],["2011-11-24",1],["2011-11-27",3],["2011-11-29",3],["2011-12-01",3],["2011-12-03",4],["2011-12-04",3],["2011-12-05",2],["2011-12-06",1],["2011-12-11",2],["2011-12-12",3],["2011-12-14",3],["2011-12-16",1],["2011-12-19",3],["2011-12-21",1],["2011-12-22",2],["2011-12-24",1],["2011-12-25",1],["2011-12-27",1],["2011-12-28",1],["2011-12-29",1],["2011-12-31",1],["2012-01-01",2],["2012-01-04",1],["2012-01-06",2],["2012-01-09",1],["2012-01-11",2],["2012-01-12",4],["2012-01-13",1],["2012-01-14",3],["2012-01-15",2],["2012-01-20",4],["2012-01-22",1],["2012-01-23",1],["2012-01-24",2],["2012-01-27",2],["2012-01-30",1],["2012-02-03",1],["2012-02-06",2],["2012-02-13",1],["2012-02-16",2],["2012-02-23",1],["2012-02-27",1],["2012-03-01",1],["2012-03-06",2],["2012-03-07",1],["2012-03-08",2],["2012-03-22",1],["2012-03-23",1],["2012-03-29",1],["2012-03-30",1],["2012-04-02",1],["2012-04-03",1],["2012-04-04",2],["2012-04-05",1],["2012-04-09",2],["2012-04-10",3],["2012-04-11",3],["2012-04-14",1],["2012-04-17",1],["2012-04-19",1],["2012-04-20",3],["2012-04-22",1],["2012-04-30",3],["2012-05-01",3],["2012-05-03",1],["2012-05-07",2],["2012-05-10",1],["2012-05-15",1],["2012-05-17",3],["2012-05-21",1],["2012-05-31",3],["2012-06-04",2],["2012-06-05",7],["2012-06-06",4],["2012-06-07",6],["2012-06-08",1],["2012-06-10",3],["2012-06-11",1],["2012-06-12",1],["2012-06-13",3],["2012-06-14",1],["2012-06-15",1],["2012-06-16",1],["2012-06-19",3],["2012-06-21",1],["2012-06-22",1],["2012-06-26",1],["2012-06-27",1],["2012-06-30",1],["2012-07-06",4],["2012-07-08",1],["2012-07-09",1],["2012-07-10",3],["2012-07-12",2],["2012-07-14",1],["2012-07-25",3],["2012-07-27",1],["2012-08-03",1],["2012-08-15",1],["2012-08-26",1],["2012-08-27",3],["2012-08-28",1],["2012-09-29",2],["2012-10-16",3],["2012-10-17",2],["2012-10-18",1],["2012-10-20",1],["2012-10-23",27],["2012-10-24",2],["2012-10-25",1],["2012-10-27",1],["2012-10-28",1],["2012-10-29",2],["2012-10-30",1],["2012-11-07",5],["2012-11-08",5],["2012-11-28",1],["2012-11-30",1],["2012-12-04",2],["2012-12-05",1],["2013-02-19",1],["2013-04-25",1],["2013-05-20",1],["2013-05-27",2],["2013-06-14",1],["2013-07-04",1],["2013-10-21",1],["2013-10-30",1],["2015-12-03",1]]}
суббота, 3 декабря 2016 г., 9:23:18 UTC+2 пользователь Evgeniy Solomanidin написал:
Sergio Hunter
Dec 3, 2016, 3:46:58 AM12/3/16
to Golang Russian
И вот не архивный JSON. В БД два формата данных
{"logins":[["2011-11-06",1]],"last_login":"Sun Nov 06 16:52:45 -0800 2011","d":{"2010-11-05":{"gg":0,"r":4.99,"g":0},"2011-06-22":{"gg":0,"1":{"g":100,"r":4.99},"g":100,"r":4.99},"2011-07-16":{"gg":0,"1":{"r":9.99,"g":200},"r":9.99,"g":200},"2010-11-20":{"gg":0,"r":4.99,"g":100}},"h":[{"d":"2011-06-22","wid":"1","g":100,"r":4.99},{"d":"2011-07-16","r":9.99,"g":200,"wid":"1"}],"t":{"gg":0,"1":{"g":300,"r":14.98},"r":24.96,"g":400}}

Daniel Podolsky
Dec 3, 2016, 3:47:00 AM12/3/16
to gola...@googlegroups.com
серджио, а от нас вы чего хотите?
если помощи простой, то я не знаю, за какую ниточку хвататься. вы же
не сделали явным, в каком месте у вас проблемы.
а если вам нужно, чтобы кто-нибудь за вас вам код наваял - тогда
давайте ТЗ, что ли...
> --
> Вы получили это сообщение, поскольку подписаны на группу "Golang Russian".
> Чтобы отменить подписку на эту группу и больше не получать от нее сообщения,
> отправьте письмо на электронный адрес
> golang-ru+...@googlegroups.com.
> Чтобы настроить другие параметры, перейдите по ссылке
> https://groups.google.com/d/optout.
если помощи простой, то я не знаю, за какую ниточку хвататься. вы же
не сделали явным, в каком месте у вас проблемы.
а если вам нужно, чтобы кто-нибудь за вас вам код наваял - тогда
давайте ТЗ, что ли...
> Вы получили это сообщение, поскольку подписаны на группу "Golang Russian".
> Чтобы отменить подписку на эту группу и больше не получать от нее сообщения,
> отправьте письмо на электронный адрес
> golang-ru+...@googlegroups.com.
> Чтобы настроить другие параметры, перейдите по ссылке
> https://groups.google.com/d/optout.
Sergio Hunter
Dec 3, 2016, 3:53:28 AM12/3/16
to Golang Russian
Там где цикл var Info, оно не нужно. Вот как надо сделать
разобрать parsed на «d» потом на даты, вытягивать «g» и «r» ложить их в другие map[string]int которые надо создать перед циклом
когда цикл по базе закончится будет map[string]int в котором например gold датам
тогда надо делать цикл по ключам этого map и складываешь в csv.
Я пока вытянул "d"
date := parsed["d"].(map[string]interface{})
for k, v := range date {
switch vv := v.(type) {
case string:
fmt.Println(k, vv)
}
}
Sergio Hunter
Dec 3, 2016, 3:56:48 AM12/3/16
to Golang Russian
Нет, мне не надо чтоб кто-то сделал за меня код, мне нужна помощь всего лишь в понимании.
Sergio Hunter
Dec 3, 2016, 4:01:05 AM12/3/16
to Golang Russian
Далее я не понимаю как вытянуть "g"
Это как-то так должно быть
gold := parsed["d"][k]["g"].(map[string]interface{})
но я знаю что это неправильная запись
Evgeniy Solomanidin
Dec 3, 2016, 11:18:51 AM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 11:56:48 AM UTC+3, Sergio Hunter wrote:
Нет, мне не надо чтоб кто-то сделал за меня код, мне нужна помощь всего лишь в понимании.
Ок, с данными понятно, теперь - Вам нужно проссумировать данные по датам если они совпадают, и по каждой дате сделать запись в csv файл? Правильно я задачу понял? если так, тогда это просто. Архив и текущее данные нужно анмаршалить в разные структы типа UserStatsData, затем проходить по ним и проверять даты, и записывать в промежуточный структ или map[string]Info а уж потом в проходить по нему и писать в файл. И да, json.Number не складывается т.к это строка, лучше использовать int64 или float64 для этой цели. как пример:
var userStatsData UserStatsData var userStatsDataArchive UserStatsData if err := json.Unmarshal([]byte(dbRowData), &userStatsData); err != nil { if err != nil { log.Panicf("\nCannot read archive %v", err) } } if err := json.Unmarshal([]byte(archiveData), &userStatsDataArchive); err != nil { panic(err.Error()) } parsed := make(map[string]Info) for k, v := range userStatsDataArchive.Dates { if item, ok := parsed[k]; ok { item.Gold += v.Gold item.Revenue += v.Revenue parsed[k] = item } else { parsed[k] = v } fmt.Println("parsed archive: ", k, ": ", v) } for k, v := range userStatsData.Dates { if item, ok := parsed[k]; ok { item.Gold += v.Gold item.Revenue += v.Revenue parsed[k] = item } else { parsed[k] = v } fmt.Println("parsed: ", k, ": ", v) } var records [][]string var record []string for k, v := range parsed { record = append(record, k) record = append(record, string(v.Gold)) record = append(record, fmt.Sprintf("%.2f", v.Revenue)) writer.Write(record) } writer.Flush()Sergio Hunter
Dec 3, 2016, 1:00:45 PM12/3/16
to Golang Russian
Евгений, спасибо большое Вам за помощь. Я переделал код так как должен быть, но все равно не то что надо. Вот вывод терминала:
Но числа не подсчитываются, выделил их:
2011-12-12 { 0 0}
2011-05-20 { 0 0}
2011-01-04 { 0 0}
2011-11-16 { 0 0}
2012-01-11 { 0 0}
2012-01-20 { 0 0}
2011-08-16 { 0 0}
2011-10-08 { 0 0}
2010-11-04 { 0 4.99}
2010-11-17 { 0 0}
2011-06-13 { 0 0}
2010-12-22 { 100 4.99}
2011-12-02 { 0 0}
2011-05-20 { 0 0}
2011-01-04 { 0 0}
2011-06-22 { 100 4.99}
2012-01-20 { 0 0}
2011-08-16 { 0 0}
2011-10-08 { 0 0}
2012-01-11 { 0 0}
2011-12-12 { 0 0}
2011-11-16 { 0 0}
2010-11-05 { 0 4.99}
2011-07-16 { 200 9.99}
2010-11-20 { 100 4.99}
2011-12-02 { 0 0}
2010-11-04 { 0 4.99}
2010-11-17 { 0 0}
2011-06-13 { 0 0}
2010-12-22 { 100 4.99}
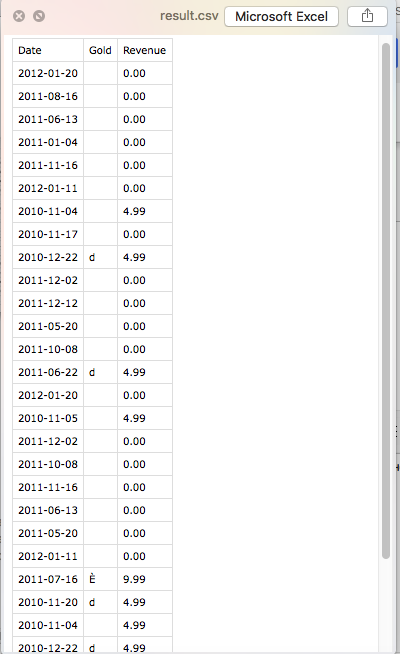
И как-то не правильно выгруженные данные в CSV (прикрепил снимок)
package main
import (
"bytes"
"compress/zlib"
"database/sql"
"encoding/json"
"fmt"
"io/ioutil"
"log"
_"github.com/go-sql-driver/mysql"
"encoding/csv"
"os"
)
var (
data []byte
)
type UserStatsData struct {
Dates map[string]Info `json:"d"`
}
type Info struct {
Date string `json:"-"`
Gold int `json:"g"`
Revenue float64 `json:"r"`
}
func main() {
db, err := sql.Open("mysql", "name:password@tcp(127.0.0.1:port)/database")
if err != nil {
panic(err.Error())
}
defer db.Close()
rows, err := db.Query(`SELECT data FROM user_stats ORDER BY created_at LIMIT 2`)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
file, err := os.Create("result.csv")
if err != nil {
fmt.Println(err)
}
defer file.Close()
userStatsData := UserStatsData{}
cont := 0
writer := csv.NewWriter(file)
for rows.Next() {
err := rows.Scan(&data)
if err != nil {
log.Fatal(err)
}
if err := json.Unmarshal(data, &userStatsData); err != nil {
r, err := zlib.NewReader(bytes.NewReader(data))
if err != nil {
log.Panicf("\nCannot read archive %v", err)
}
r.Close()
data, _ = ioutil.ReadAll(r)
}
if err := json.Unmarshal(data, &userStatsData); err != nil {
panic(err.Error())
}
parsed := make(map[string]Info)
for k, v := range userStatsData.Dates {
if item, ok := parsed[k]; ok {
item.Gold += v.Gold
item.Revenue += v.Revenue
parsed[k] = item
} else
{
parsed[k] = v
}
fmt.Println(k, v)
}
for k, v := range parsed {
if cont == 0 {
var record []string
record = append(record, "Date")
record = append(record, "Gold")
record = append(record, "Revenue")
writer.Write(record)
cont++
}
var record []string
record = append(record, k)
record = append(record, string(v.Gold))
record = append(record, fmt.Sprintf("%.2f", v.Revenue))
writer.Write
(record)
cont++
}
writer.Flush()
}
}
{kind=link}
Sergio Hunter
Dec 3, 2016, 1:10:26 PM12/3/16
to Golang Russian
И все же я думаю надо parsed разобрать на d, потом дату g, r ложить в другие map и потом делать цикл по ключам и складывать в csv. Но вот как реализовать, мне пока сложно.
Evgeniy Solomanidin
Dec 3, 2016, 1:20:13 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 9:00:45 PM UTC+3, Sergio Hunter wrote:
Евгений, спасибо большое Вам за помощь. Я переделал код так как должен быть, но все равно не то что надо. Вот вывод терминала:
я думаю все же он должен выглядеть вот так
Опять же, если я правильно понимаю задачу
Evgeniy Solomanidin
Dec 3, 2016, 1:27:44 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 9:10:26 PM UTC+3, Sergio Hunter wrote:
И все же я думаю надо parsed разобрать на d, потом дату g, r ложить в другие map и потом делать цикл по ключам и складывать в csv. Но вот как реализовать, мне пока сложно.
if err := json.Unmarshal(data, &userStatsData); err != nil { r, err := zlib.NewReader(bytes.NewReader(data)) if err != nil { log.Panicf("\nCannot read archive %v", err) } r.Close() data, _ = ioutil.ReadAll(r) }
if err := json.Unmarshal(data, &userStatsDataArchive); err != nil { panic(err.Error()) }
Вот эта часть что делает? я не пойму, там что в записи может быть блоб? если так тогда - каждый row и архив это только 1 запись? я не понимаю. Запись может быть архивной или просто записью? тогда надо все совсем не так делать
Sergio Hunter
Dec 3, 2016, 1:34:52 PM12/3/16
to Golang Russian
Все верно это BLOB архивный JSON
Sergio Hunter
Dec 3, 2016, 1:38:39 PM12/3/16
to Golang Russian
Я беру из БД BLOB данные они в перемешку архивные и просто JSON текст и это должен быть парсинг в csv. (если я правильно выражаюсь)
Sergio Hunter
Dec 3, 2016, 1:41:50 PM12/3/16
to Golang Russian
Вот этот кусок кода который Вы выделили, он декодит строку и выводит вместе с текстовой строкой
Evgeniy Solomanidin
Dec 3, 2016, 1:41:50 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 9:34:52 PM UTC+3, Sergio Hunter wrote:
Все верно это BLOB архивный JSON
Ок, значит в таблице у нас есть нормальные записи, и архивные? и мы не знаем когда какая придет? Правильно я понимаю - нужно собрать все записи в таблице - проверить у них даты, если даты совпадают - посчитать сумму полей, а потом результирующий мап записать в csv файл?
Или нужно все это делать для каждой записи в таблице?
Sergio Hunter
Dec 3, 2016, 1:44:08 PM12/3/16
to Golang Russian
Все верно! наконец-то меня поняли.
Sergio Hunter
Dec 3, 2016, 1:47:32 PM12/3/16
to Golang Russian
Да, я же делаю запрос sql с лимитом 2, а могу 10 и более поставить, и там могут быть хаотично как архивные так и текстовые JSON данные, и архив мне нужно декодить чтоб все на выходе был текст и с него брать d, g, r
Evgeniy Solomanidin
Dec 3, 2016, 1:57:25 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 9:47:32 PM UTC+3, Sergio Hunter wrote:
Да, я же делаю запрос sql с лимитом 2, а могу 10 и более поставить, и там могут быть хаотично как архивные так и текстовые JSON данные, и архив мне нужно декодить чтоб все на выходе был текст и с него брать d, g, r
Как то так должно работать
package main
import ( "bytes" "compress/zlib" "database/sql")
type UserStatsData struct { Dates map[string]Info `json:"d"`}
type Info struct { Date string `json:"-"` Gold int `json:"g"` Revenue float64 `json:"r"`}
func main() { var data []byte db, err := sql.Open("mysql", "name:password@tcp(127.0.0.1:port)/database")
if err != nil { panic(err.Error()) } defer db.Close()
rows, err := db.Query(`SELECT data FROM user_stats ORDER BY created_at LIMIT 2`) if err != nil { log.Fatal(err) } defer rows.Close()
file, err := os.Create("result.csv") if err != nil { fmt.Println(err) } defer file.Close()
writer := csv.NewWriter(file) var record []string record = append(record, "Date") record = append(record, "Gold") record = append(record, "Revenue") writer.Write(record) var userStatsDataArr []UserStatsData var userStatsDataArchiveArr []UserStatsData for rows.Next() { err := rows.Scan(&data) if err != nil { log.Fatal(err) } var userStatsData UserStatsData var userStatsDataArchive UserStatsData err = json.Unmarshal(data, &userStatsData) if err != nil { r, err := zlib.NewReader(bytes.NewReader(data)) if err != nil { log.Panicf("\nCannot read archive %v", err) } defer r.Close() data, _ = ioutil.ReadAll(r) err = json.Unmarshal(data, &userStatsDataArchive) if err != nil { panic(err.Error()) } userStatsDataArchiveArr = append(userStatsDataArchiveArr, userStatsDataArchive) } else { userStatsDataArr = append(userStatsDataArr, userStatsData) }
} parsed := make(map[string]Info) for _, arch := range userStatsDataArchiveArr { for k, v := range arch.Dates { if item, ok := parsed[k]; ok { item.Gold += v.Gold item.Revenue += v.Revenue parsed[k] = item } else { parsed[k] = v }
} } for _, user := range userStatsDataArr { for k, v := range user.Dates { if item, ok := parsed[k]; ok { item.Gold += v.Gold item.Revenue += v.Revenue parsed[k] = item } else { parsed[k] = v }
} } for k, v := range parsed { var record []string record = append(record, k) record = append(record, string(v.Gold)) record = append(record, fmt.Sprintf("%.2f", v.Revenue)) writer.Write(record) } writer.Flush()}
Sergio Hunter
Dec 3, 2016, 2:42:46 PM12/3/16
to Golang Russian
Странно предыдущий код подсчитывал одинаковые даты, но колонку revenue почему-то не выводит. Вот скрин предыдущего кода, а данный код просто выводит.
А может быть в самой JSON строке проблемы? У меня есть форматированная строка файлом
{kind=link}
Sergio Hunter
Dec 3, 2016, 2:45:34 PM12/3/16
to Golang Russian
Вернее не Revenue а Gold колонка не выводится
Evgeniy Solomanidin
Dec 3, 2016, 2:58:27 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 10:45:34 PM UTC+3, Sergio Hunter wrote:
Вернее не Revenue а Gold колонка не выводится
попробуйте заменить
record = append(record, string(v.Gold))
на
record = append(record, strconv.Itoa(v.Gold))
Sergio Hunter
Dec 3, 2016, 3:15:56 PM12/3/16
to Golang Russian
Да, точно, спасибо
Sergio Hunter
Dec 3, 2016, 3:17:05 PM12/3/16
to Golang Russian
Я ведь правильно все написал, почему оно не подсчитывает дубликаты?
package main
import (
"bytes"
"compress/zlib"
"database/sql"
"encoding/csv"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
_ "github.com/go-sql-driver/mysql"
"strconv"
)
type UserStatsData struct {
Dates map[string]Info `json:"d"`
}
type Info struct {
Date string `json:"-"`
Gold int `json:"g"`
Revenue float64 `json:"r"`
}
func main() {
var data []byte
db, err := sql.Open("mysql", "app:reACT4141@tcp(127.0.0.1:9011)/pmvalor")
if err != nil {
panic(err.Error())
}
defer db.Close()
rows, err := db.Query(`SELECT data FROM user_stats ORDER BY created_at LIMIT 2`)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
file, err := os.Create("result.csv")
if err != nil {
fmt.Println(err)
}
defer file.Close()
writer := csv.NewWriter(file)
var record []string
record = append(record, "Date")
record = append(record, "Gold")
record = append(record, "Revenue")
writer.Write(record)
writer.Flush()
var userStatsDataArr []UserStatsData
var userStatsDataArchiveArr []UserStatsData
for rows.Next() {
err := rows.Scan(&data)
if err != nil {
log.Fatal(err)
}
var userStatsData UserStatsData
var userStatsDataArchive UserStatsData
err = json.Unmarshal(data, &userStatsData)
if err != nil {
r, err := zlib.NewReader(bytes.NewReader(data))
if err != nil {
log.Panicf("\nCannot read archive %v", err)
}
record = append(record, strconv.Itoa(v.Gold))
Evgeniy Solomanidin
Dec 3, 2016, 3:22:29 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 11:17:05 PM UTC+3, Sergio Hunter wrote:
Я ведь правильно все написал, почему оно не подсчитывает дубликаты?
А они там есть? 100% есть? напечатайте все что получаете и проверьте
Sergio Hunter
Dec 3, 2016, 3:36:07 PM12/3/16
to Golang Russian
вот 2 строки json и есть даты которые повторяются
{"last_login":"2015-12-03 08:21:02 -0800","t":{"gg":11000,"2":{"g":100,"r":4.99},"g":100,"r":9.98},"h":[{"r":0,"g":500,"d":"2011-01-04"},{"g":500,"r":0,"d":"2011-05-20"},{"r":0,"g":500,"d":"2011-06-13"},{"g":500,"r":0,"d":"2011-08-16"},{"r":0,"g":500,"d":"2011-10-08"},{"r":0,"g":500,"d":"2011-11-16"},{"g":500,"r":0,"d":"2011-12-02"},{"g":1000,"r":0,"d":"2011-12-12"},{"g":1000,"r":0,"d":"2012-01-11"},{"g":5000,"r":0,"d":"2012-01-20"}],"d":{"2012-01-11":{"gg":1000,"g":0,"r":0},"2011-12-02":{"gg":500,"g":0,"r":0},"2012-01-20":{"gg":5000,"g":0,"r":0},"2011-12-12":{"gg":1000,"g":0,"r":0},"2011-08-16":{"gg":500,"g":0,"r":0},"2011-10-08":{"gg":500,"r":0,"g":0},"2010-11-04":{"gg":0,"g":0,"r":4.99},"2011-05-20":{"gg":500,"g":0,"r":0},"2011-01-04":{"gg":500,"r":0,"g":0},"2010-11-17":{"gg":500,"r":0,"g":0},"2011-06-13":{"gg":500,"r":0,"g":0},"2010-12-22":{"gg":0,"2":{"g":100,"r":4.99},"g":100,"r":4.99},"2011-11-16":{"gg":500,"r":0,"g":0}},"logins":[["2011-10-05",2],["2011-10-06",2],["2011-10-10",2],["2011-10-13",1],["2011-10-14",1],["2011-10-17",1],["2011-10-18",1],["2011-10-21",6],["2011-10-22",1],["2011-10-23",3],["2011-10-25",2],["2011-10-29",1],["2011-11-01",2],["2011-11-02",2],["2011-11-06",3],["2011-11-09",5],["2011-11-10",1],["2011-11-11",1],["2011-11-12",7],["2011-11-13",1],["2011-11-15",6],["2011-11-16",2],["2011-11-18",1],["2011-11-19",1],["2011-11-20",2],["2011-11-21",4],["2011-11-23",8],["2011-11-24",1],["2011-11-27",3],["2011-11-29",3],["2011-12-01",3],["2011-12-03",4],["2011-12-04",3],["2011-12-05",2],["2011-12-06",1],["2011-12-11",2],["2011-12-12",3],["2011-12-14",3],["2011-12-16",1],["2011-12-19",3],["2011-12-21",1],["2011-12-22",2],["2011-12-24",1],["2011-12-25",1],["2011-12-27",1],["2011-12-28",1],["2011-12-29",1],["2011-12-31",1],["2012-01-01",2],["2012-01-04",1],["2012-01-06",2],["2012-01-09",1],["2012-01-11",2],["2012-01-12",4],["2012-01-13",1],["2012-01-14",3],["2012-01-15",2],["2012-01-20",4],["2012-01-22",1],["2012-01-23",1],["2012-01-24",2],["2012-01-27",2],["2012-01-30",1],["2012-02-03",1],["2012-02-06",2],["2012-02-13",1],["2012-02-16",2],["2012-02-23",1],["2012-02-27",1],["2012-03-01",1],["2012-03-06",2],["2012-03-07",1],["2012-03-08",2],["2012-03-22",1],["2012-03-23",1],["2012-03-29",1],["2012-03-30",1],["2012-04-02",1],["2012-04-03",1],["2012-04-04",2],["2012-04-05",1],["2012-04-09",2],["2012-04-10",3],["2012-04-11",3],["2012-04-14",1],["2012-04-17",1],["2012-04-19",1],["2012-04-20",3],["2012-04-22",1],["2012-04-30",3],["2012-05-01",3],["2012-05-03",1],["2012-05-07",2],["2012-05-10",1],["2012-05-15",1],["2012-05-17",3],["2012-05-21",1],["2012-05-31",3],["2012-06-04",2],["2012-06-05",7],["2012-06-06",4],["2012-06-07",6],["2012-06-08",1],["2012-06-10",3],["2012-06-11",1],["2012-06-12",1],["2012-06-13",3],["2012-06-14",1],["2012-06-15",1],["2012-06-16",1],["2012-06-19",3],["2012-06-21",1],["2012-06-22",1],["2012-06-26",1],["2012-06-27",1],["2012-06-30",1],["2012-07-06",4],["2012-07-08",1],["2012-07-09",1],["2012-07-10",3],["2012-07-12",2],["2012-07-14",1],["2012-07-25",3],["2012-07-27",1],["2012-08-03",1],["2012-08-15",1],["2012-08-26",1],["2012-08-27",3],["2012-08-28",1],["2012-09-29",2],["2012-10-16",3],["2012-10-17",2],["2012-10-18",1],["2012-10-20",1],["2012-10-23",27],["2012-10-24",2],["2012-10-25",1],["2012-10-27",1],["2012-10-28",1],["2012-10-29",2],["2012-10-30",1],["2012-11-07",5],["2012-11-08",5],["2012-11-28",1],["2012-11-30",1],["2012-12-04",2],["2012-12-05",1],["2013-02-19",1],["2013-04-25",1],["2013-05-20",1],["2013-05-27",2],["2013-06-14",1],["2013-07-04",1],["2013-10-21",1],["2013-10-30",1],["2015-12-03",1]]}
{"logins":[["2011-11-06",1]],"last_login":"Sun Nov 06 16:52:45 -0800 2011","d":{"2010-11-05":{"gg":0,"r":4.99,"g":0},"2011-06-22":{"gg":0,"1":{"g":100,"r":4.99},"g":100,"r":4.99},"2011-07-16":{"gg":0,"1":{"r":9.99,"g":200},"r":9.99,"g":200},"2010-11-20":{"gg":0,"r":4.99,"g":100}},"h":[{"d":"2011-06-22","wid":"1","g":100,"r":4.99},{"d":"2011-07-16","r":9.99,"g":200,"wid":"1"}],"t":{"gg":0,"1":{"g":300,"r":14.98},"r":24.96,"g":400}}
и то что выводится в csv
{kind=link}
Sergio Hunter
Dec 3, 2016, 3:40:04 PM12/3/16
to Golang Russian
сортировка дат этой командой используется sort.Strings()?
Evgeniy Solomanidin
Dec 3, 2016, 3:45:58 PM12/3/16
to Golang Russian
On Saturday, December 3, 2016 at 11:36:07 PM UTC+3, Sergio Hunter wrote:
вот 2 строки json и есть даты которые повторяются
{"
{"logins":[["2011-11-06",1]],"last_login":"Sun Nov 06 16:52:45 -0800 2011","d":{"2010-11-05":{"gg":0,"r":4.99,"g":0},"2011-06-22":{"gg":0,"1":{"g":100,"r":4.99},"g":100,"r":4.99},"2011-07-16":{"gg":0,"1":{"r":9.99,"g":200},"r":9.99,"g":200},"2010-11-20":{"gg":0,"r":4.99,"g":100}},"h":[{"d":"2011-06-22","wid":"1","g":100,"r":4.99},{"d":"2011-07-16","r":9.99,"g":200,"wid":"1"}],"t":{"gg":0,"1":{"g":300,"r":14.98},"r":24.96,"g":400}}
и то что выводится в csv
У вас неверный анмаршалинг. т.к "h":[{}] вы не анмаршалите, и соответственно по ним вы не получаете данные. продумайте правильно struct и добавьте это в циклы.
Sergio Hunter
Dec 3, 2016, 4:08:00 PM12/3/16
to Golang Russian
Ну да, плохо что неверный. Евгений, а как Вы думаете, можно ли использовать вариант когда после того как сделал декомпрес данных
if err := json.Unmarshal(data, &userStatsData); err != nil {
r, err := zlib.NewReader(bytes.NewReader(data))
if err != nil {
log.Panicf("\nCannot read archive %v", err)
}
r.Close()
data, _ = ioutil.ReadAll(r)
}
я создаю переменную parsed, делаю unmarshal
parsed := make(map[string]interface{})
if err := json.Unmarshal(data, &parsed); err != nil {
panic(err.Error())
}
потом начать разбирать "d" после [даты], вытягивать "g", "r"
date := parsed["d"].(map[string]interface{})
for k, v := range date {
switch vv := v.(type) {
case string:
fmt.Println(k, vv)
}
}
потом как-то так (я не уверен что это правильно0
gold := parsed["d"][k]["g"].(map[string]interface{})
и потом это все ложить в другие map которые создаются перед циклом
когда цикл по базе закончится будет map[string]int в котором например gold датам
тогда делается цикл по ключам этого map и складывается в csv
Sergio Hunter
Dec 3, 2016, 4:10:39 PM12/3/16
to Golang Russian
Сначала получить занчение parsed[d] от него запросить [дата] а уже от него запросить [g] и [r]
Evgeniy Solomanidin
Dec 3, 2016, 4:35:41 PM12/3/16
to Golang Russian
On Sunday, December 4, 2016 at 12:10:39 AM UTC+3, Sergio Hunter wrote:
Сначала получить занчение parsed[d] от него запросить [дата] а уже от него запросить [g] и [r]
как то так
package main
import ( "bytes" "compress/zlib" "database/sql" "encoding/csv" "encoding/json" "fmt" "io/ioutil" "log" "os")
type UserStatsData struct { Dates map[string]Info `json:"d"`}
type Info struct { Date string `json:"-"` Gold int `json:"g"` Revenue float64 `json:"r"` H []Info `json:"h"`}
func main() { var data []byte db, err := sql.Open("mysql", "name:password@tcp(127.0.0.1:port)/database")
if err != nil { panic(err.Error()) } defer db.Close()
rows, err := db.Query(`SELECT data FROM user_stats ORDER BY created_at LIMIT 2`) if err != nil { log.Fatal(err) } defer rows.Close()
file, err := os.Create("result.csv") if err != nil { fmt.Println(err) } defer file.Close()
writer := csv.NewWriter(file) var record []string record = append(record, "Date") record = append(record, "Gold") record = append(record, "Revenue") writer.Write(record) var userStatsDataArr []UserStatsData for rows.Next() { err := rows.Scan(&data) if err != nil { log.Fatal(err) } var userStatsData UserStatsData
err = json.Unmarshal(data, &userStatsData) if err != nil { r, err := zlib.NewReader(bytes.NewReader(data)) if err != nil { log.Panicf("\nCannot read archive %v", err) } defer r.Close() data, _ = ioutil.ReadAll(r) err = json.Unmarshal(data, &userStatsData) if err != nil { panic(err.Error()) }
} userStatsDataArr = append(userStatsDataArr, userStatsData)
} parsed := make(map[string]Info) for _, user := range userStatsDataArr { for k, v := range user.Dates { if item, ok := parsed[k]; ok { item.Gold += v.Gold item.Revenue += v.Revenue parsed[k] = item } else { parsed[k] = v } for _, val := range v.H { if item, ok := parsed[val.Date]; ok { item.Gold += val.Gold item.Revenue += val.Revenue parsed[val.Date] = item } else { parsed[k] = valSergio Hunter
Dec 3, 2016, 5:20:09 PM12/3/16
to Golang Russian
Думаю что это оно, а как правильно отсортировать даты это sort.Strings()?
Message has been deleted
Evgeniy Solomanidin
Dec 3, 2016, 5:25:14 PM12/3/16
to Golang Russian
On Sunday, December 4, 2016 at 1:20:09 AM UTC+3, Sergio Hunter wrote:
Думаю что это оно, а как правильно отсортировать даты это sort.Strings()?
нужно знать по какому признаку их сортировать. возможно нужно реализовать sort для parsed.
Sergio Hunter
Dec 5, 2016, 1:00:29 PM12/5/16
to Golang Russian
Сортировка делается с помощью sort.Sort и методов Len, Less, и Swap?
Daniel Podolsky
Dec 5, 2016, 1:18:22 PM12/5/16
to gola...@googlegroups.com
2016-12-05 21:00 GMT+03:00 Sergio Hunter <oho...@gmail.com>:
> Сортировка делается с помощью sort.Sort и методов Len, Less, и Swap?
и специального типа.
> Сортировка делается с помощью sort.Sort и методов Len, Less, и Swap?
но сортировка массива строк делается спец методом пакета sort
Sergio Hunter
Dec 5, 2016, 1:21:43 PM12/5/16
to Golang Russian
Если Вам не трудно, не могли бы пояснить? Спасибо.
Evgeniy Solomanidin
Dec 8, 2016, 7:13:04 PM12/8/16
to Golang Russian
On Monday, December 5, 2016 at 9:21:43 PM UTC+3, Sergio Hunter wrote:
Если Вам не трудно, не могли бы пояснить? Спасибо.
Создаём тип []string для ключей parsed,реализуем там сортировку, перед записью кладем ключи туда, сортируем, итерируем по списку - по каждому значению берем из parsed нужный Info{} и записываем. Но вообще вопросы странные, если совсем ничего не знаете о Go рекомендую почитать литературу или хотя бы пройти тур.
Sergio Hunter
Dec 9, 2016, 9:29:22 AM12/9/16
to Golang Russian
Короче разобрался, спасибо огромное!
keys := []string{}
for key, _ := range parsed {
keys = append(keys, key)
}
sort.Strings(keys)
for i := range keys {
key := keys[i]
fmt.Printf(key)
fmt.Println()
}
пятница, 9 декабря 2016 г., 2:13:04 UTC+2 пользователь Evgeniy Solomanidin написал:
Sergio Hunter
Dec 9, 2016, 9:34:19 AM12/9/16
to Golang Russian
Вот только пока не разобрался как записать в csv
Evgeniy Solomanidin
Dec 9, 2016, 10:26:16 AM12/9/16
to Golang Russian
On Friday, December 9, 2016 at 5:34:19 PM UTC+3, Sergio Hunter wrote:
Вот только пока не разобрался как записать в csv
если ключи сортируются так как Вам нужно, то остается лишь заменить
for k, v := range parsed { var record []string record = append(record, k) record = append(record, strconv.Itoa(v.Gold)) record = append(record, fmt.Sprintf("%.2f", v.Revenue)) writer.Write(record)} на
for _, v := range keys{
var record []string record = append(record, v) record = append(record, strconv.Itoa(parsed[v].Gold)) record = append(record, fmt.Sprintf("%.2f", parsed[v].Revenue)) writer.Write(record)
}Sergio Hunter
Dec 9, 2016, 10:40:14 AM12/9/16
to Golang Russian
Евгений, большое спасибо за помощь. Вы Гуру программирования, хочу такого же уровня знаний достичь! Надо много работать.
Reply all
Reply to author
Forward
0 new messages