Crash in utf8 demo
65 views
Skip to first unread message


nikego
Mar 19, 2015, 5:22:32 AM3/19/15
to fltkg...@googlegroups.com
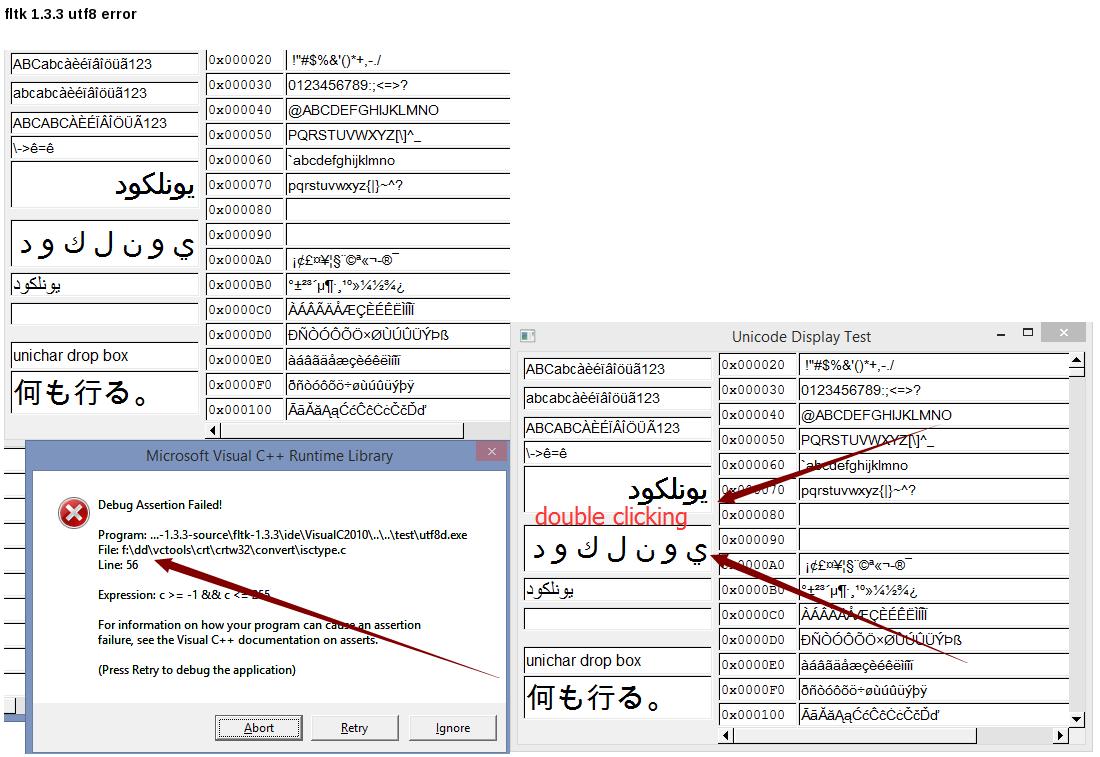
Hi, Greg. It's well known bug of fltk (debug build for Windows) occuring inside isspace() function.
_ASSERTE((unsigned)(c + 1) <= 256);
The debug assert window arises if argument is less than zero.
To be honest, it's quite easy to crash most of fltk debug applications because fltk uses UTF-8 encoding and feeds SIGNED char symbols to isspace() and other functions of the same family.
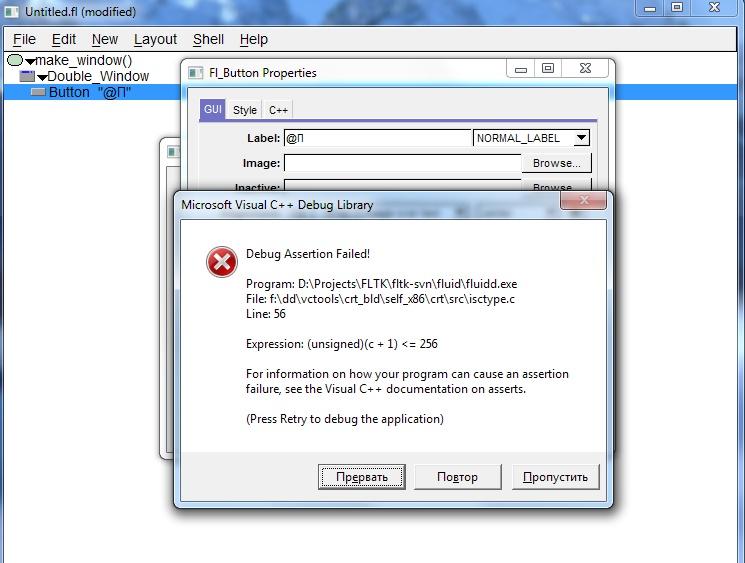
For example, see attached image with crashed Fluid - I have created button with label of two symbols - '@' and any cyrillic symbol.
_ASSERTE((unsigned)(c + 1) <= 256);
The debug assert window arises if argument is less than zero.
To be honest, it's quite easy to crash most of fltk debug applications because fltk uses UTF-8 encoding and feeds SIGNED char symbols to isspace() and other functions of the same family.
For example, see attached image with crashed Fluid - I have created button with label of two symbols - '@' and any cyrillic symbol.

MacArthur, Ian (Selex ES, UK)
Mar 19, 2015, 5:38:42 AM3/19/15
to fltkg...@googlegroups.com
> Someone sent me this on private email today..
>
> I don't have time to look into this; looks like an assertion
> is triggered when double clicking on right-to-left text
> (which I don't think FLTK supports?)
That said, I don't get this assert; but then I don't have the MS tools, I'm using mingw/msys.
Nikego reports "It's well known bug of fltk" but I have to say this is the first time I heard of it.
It only occurs in debug builds, I assume?
Nikego's analysis says:
> (debug build for Windows) occuring inside isspace() function.
>
> _ASSERTE((unsigned)(c + 1) <= 256);
>
> The debug assert window arises if argument is less than zero.
Do we need to find everywhere we call isspace et all and explicitly cast the char parameter to unsigned?
That might be a bit of a pain (and potentially confusing on platforms where a char defaults to unsigned anyway.)
> For example, see attached image with crashed Fluid -
> I have created button with label of two symbols - '@'
> and any cyrillic symbol.
Selex ES Ltd
Registered Office: Sigma House, Christopher Martin Road, Basildon, Essex SS14 3EL
A company registered in England & Wales. Company no. 02426132
********************************************************************
This email and any attachments are confidential to the intended
recipient and may also be privileged. If you are not the intended
recipient please delete it from your system and notify the sender.
You should not copy it or use it for any purpose nor disclose or
distribute its contents to any other person.
********************************************************************

{kind=link}
{kind=link}
Albrecht Schlosser
Mar 19, 2015, 7:17:47 AM3/19/15
to fltkg...@googlegroups.com
On 19.03.2015 10:38 MacArthur, Ian (Selex ES, UK) wrote:
>
>> Someone sent me this on private email today..
>>
>> I don't have time to look into this; looks like an assertion
>> is triggered when double clicking on right-to-left text
>> (which I don't think FLTK supports?)
>
> We do kind of fake-up RTL text though, in a very limited way. *Very* limited.
>
> That said, I don't get this assert; but then I don't have the MS tools, I'm using mingw/msys.
>
>
> Nikego reports "It's well known bug of fltk" but I have to say this is the first time I heard of it.
>
> It only occurs in debug builds, I assume?
Reading the MS docs, I'd say yes. See more below.
>
>> Someone sent me this on private email today..
>>
>> I don't have time to look into this; looks like an assertion
>> is triggered when double clicking on right-to-left text
>> (which I don't think FLTK supports?)
>
> We do kind of fake-up RTL text though, in a very limited way. *Very* limited.
>
> That said, I don't get this assert; but then I don't have the MS tools, I'm using mingw/msys.
>
>
> Nikego reports "It's well known bug of fltk" but I have to say this is the first time I heard of it.
>
> It only occurs in debug builds, I assume?
> Nikego's analysis says:
>
>> (debug build for Windows) occuring inside isspace() function.
>>
>> _ASSERTE((unsigned)(c + 1) <= 256);
>>
>> The debug assert window arises if argument is less than zero.
>
> Which may be true, but my reading of isspace() (which may well be flawed) was that it recognises a (potentially locale specific) set of "whitespace" characters, so the signed-ness or otherwise of the parameter really ought not matter, it either is one of the "space" values or it is not...
"These functions check whether c, which must have the value of an
unsigned char or EOF, falls into a certain character class according to
the current locale."
http://linux.die.net/man/3/isspace
Feeding arbitrary (parts of) UTF-8 characters [defined as (signed) char]
does certainly not satisfy this condition because they can be negative
and not EOF (which is most likely -1).
The man page does not mention what happens if the input is not one of
the accepted characters.
Whereas `man toupper' (which is related) says:
"If c is not an unsigned char value, or EOF, the behavior of these
functions is undefined."
> Do we need to find everywhere we call isspace et all and explicitly cast the char parameter to unsigned?
> That might be a bit of a pain (and potentially confusing on platforms where a char defaults to unsigned anyway.)
can use, and we can't use all these functions as we do now by parsing
strings byte by byte (!), because we have UTF-8 strings and one
character can be more than one byte.
Here is one example of a handle() method that retrieves one "character"
in fluid/menutype.cxx:
int Shortcut_Button::handle(int e) {
...
int v = Fl::event_text()[0];
if ( (v > 32 && v < 0x7f) || (v > 0xa0 && v <= 0xff) ) {
...
// usage of isupper() and tolower() follows
As I see this, Fl::event_text()[0] can be the first byte of a UTF-8
character and as such it can be > 127 (unsigned), but event_text() is
'char *' (see FL/Fl.H):
static const char* event_text() {return e_text;}
Question: can the 2nd part of the 'or' expression
'(v > 0xa0 && v <= 0xff)'
ever be true if 'char' is signed?
This is only one example I picked, but unfortunately there are lots of
similar issues. These are remnants of the FLTK 1.1 code base, i.e. code
that is not (yet) fully ported to UTF-8.
>> For example, see attached image with crashed Fluid -
>> I have created button with label of two symbols - '@'
>> and any cyrillic symbol.
>
> Hmm, tried this; didn’t crash. What tools etc. do you build with?
https://msdn.microsoft.com/library/y13z34da.aspx
say:
"Determines whether an integer represents a space character.
...
The behavior of isspace and _isspace_l is undefined if c is not
EOF or in the range 0 through 0xFF, inclusive. When a debug CRT
library is used and c is not one of these values, the functions
raise an assertion."
Although this is somewhat questionable I must admit that the MS behavior
is (IMHO) legitimate, because they define otherwise 'undefined' behavior.
That said, I believe that all sorts of isspace(), isupper(), toupper(),
tolower() etc. must not be in the FLTK code base anymore, since they are
all defined for "the current locale" which is not applicable for UTF-8
encoding [1]. For UTF-8 text we have for instance fl_tolower() and
fl_utf_tolower() for UCS characters and UTF-8 strings, resp..
[1] Although they may work for the ASCII _subset_ of UTF-8 and thus for
most English text.
nikego
Mar 19, 2015, 9:03:02 AM3/19/15
to fltkg...@googlegroups.com, ian.ma...@selex-es.com
Nikego reports "It's well known bug of fltk" but I have to say this is the first time I heard of it.
A few years ago there was STR with the same problem. IIRC, Albrecht fixed it in Fluid code.
It only occurs in debug builds, I assume?
Yes, it occurs only in debug builds.
> For example, see attached image with crashed Fluid -
> I have created button with label of two symbols - '@'
> and any cyrillic symbol.
Hmm, tried this; didn’t crash. What tools etc. do you build with?
VC2010.
Nikita Egorov
Albrecht Schlosser
Mar 19, 2015, 11:19:20 AM3/19/15
to fltkg...@googlegroups.com
On 19.03.2015 14:03 nikego wrote:
> Nikego reports "It's well known bug of fltk" but I have to say this
> is the first time I heard of it.
>
>
> Nikego reports "It's well known bug of fltk" but I have to say this
> is the first time I heard of it.
>
>
> A few years ago there was STR with the same problem. IIRC, Albrecht
> fixed it in Fluid code.
Yep, I found the svn log (r 9635, STR #2726). FWIW:
> fixed it in Fluid code.
------------------------------------------------------------------------
r9635 | AlbrechtS | 2012-07-14 20:31:43 +0200 (Sat, 14 Jul 2012) | 6 lines
Fix cast using both (unsigned char) and (int) to make sure that
char values > 127 are *positive* int's. (STR #2726)
--This line, and those below, will be ignored--
M fluid/Fl_Type.cxx
------------------------------------------------------------------------
> It only occurs in debug builds, I assume?
>
>
> Yes, it occurs only in debug builds.
>
>
>
>
> > For example, see attached image with crashed Fluid -
> > I have created button with label of two symbols - '@'
> > and any cyrillic symbol.
>
> Hmm, tried this; didn’t crash. What tools etc. do you build with?
>
>
> VC2010.
> > I have created button with label of two symbols - '@'
> > and any cyrillic symbol.
>
> Hmm, tried this; didn’t crash. What tools etc. do you build with?
>
>
>
> Nikita Egorov
nikego
May 12, 2015, 12:12:02 PM5/12/15
to fltkg...@googlegroups.com
> It only occurs in debug builds, I assume?
Reading the MS docs, I'd say yes. See more below.
There is a trouble: if an application was built as debug then the crash occurs independently of FLTK library (debug or release).
I had a lot of problems with it (e.g. with Fl_Text_Editor - the crashes were caused by double click on any non-latin word).
At the moment I found a workaround for it, but I'm not sure it is quite reliable. I have replaced set of the problem functions (isspace,isprint,ispunct,isalnum) to MS _ismbcspace, _ismbcprint, _ismbcpunct and iswalnum. The latter is used for UCS-4 characters.
Of course, I did it indirectly via macros like that:
#ifdef _MSC_VER
#include <mbstring.h>
#define fl_isalnum(c) iswalnum(c)
#define fl_isspace(c) _ismbcspace(c)
#define fl_isprint(c) _ismbcprint(c)
#define fl_ispunct(c) _ismbcpunct(c)
#else
#define fl_isalnum(c) isalnum(c)
#define fl_isspace(c) isspace(c)
#define fl_isprint(c) isprint(c)
#define fl_ispunct(c) ispunct(c)
#endif
// part of fl_draw.cxx - crash when label is "@"+"any non latin sym"
....
for (symptr = symbol[0];
*str && !fl_isspace(*str) && symptr < (symbol[0] + sizeof(symbol[0]) - 1);
*symptr++ = *str++);
*symptr = '\0';
if (fl_isspace(*str)) str++;
.....
It works fine for me, but I have no time (and expirience) to investigate the issue more thoroughly.
Any help appriciated.
Nikita Egorov
I had a lot of problems with it (e.g. with Fl_Text_Editor - the crashes were caused by double click on any non-latin word).
At the moment I found a workaround for it, but I'm not sure it is quite reliable. I have replaced set of the problem functions (isspace,isprint,ispunct,isalnum) to MS _ismbcspace, _ismbcprint, _ismbcpunct and iswalnum. The latter is used for UCS-4 characters.
Of course, I did it indirectly via macros like that:
#ifdef _MSC_VER
#include <mbstring.h>
#define fl_isalnum(c) iswalnum(c)
#define fl_isspace(c) _ismbcspace(c)
#define fl_isprint(c) _ismbcprint(c)
#define fl_ispunct(c) _ismbcpunct(c)
#else
#define fl_isalnum(c) isalnum(c)
#define fl_isspace(c) isspace(c)
#define fl_isprint(c) isprint(c)
#define fl_ispunct(c) ispunct(c)
#endif
// part of fl_draw.cxx - crash when label is "@"+"any non latin sym"
....
for (symptr = symbol[0];
*str && !fl_isspace(*str) && symptr < (symbol[0] + sizeof(symbol[0]) - 1);
*symptr++ = *str++);
*symptr = '\0';
if (fl_isspace(*str)) str++;
.....
It works fine for me, but I have no time (and expirience) to investigate the issue more thoroughly.
Any help appriciated.
Nikita Egorov
MacArthur, Ian (Selex ES, UK)
May 13, 2015, 7:05:41 AM5/13/15
to fltkg...@googlegroups.com
All; was an STR opened for this one? I remember there was some discussion but... My memory is not what it was; at least as far as I can remember it ever working...
>> > It only occurs in debug builds, I assume?
>> Reading the MS docs, I'd say yes. See more below.
> There is a trouble: if an application was built as debug then the crash
> occurs independently of FLTK library (debug or release).
I guess the debug DLL's get pulled in, and they will probably throw the assertion when they encounter any non-ASCII UTF8 character codes.
> occurs independently of FLTK library (debug or release).
> I had a lot of problems with it (e.g. with Fl_Text_Editor - the crashes
> were caused by double click on any non-latin word).
> At the moment I found a workaround for it, but I'm not sure it is quite
> reliable. I have replaced set of the problem functions
> (isspace,isprint,ispunct,isalnum) to MS _ismbcspace, _ismbcprint,
> _ismbcpunct and iswalnum. The latter is used for UCS-4 characters.
However, for characters from the LGC languages, I guess there's a fair chance that the UTF16 value is "the same" as the UCS4 value would be, albeit in only 16-bits.
I'd imagine this would go awry when you start to hit characters form the higher Unicode planes, where UTF16 would need pairs to hold the full UCS4 value...
I doubt iswalnum is going to be right at this point though, since we are handling UTF8 text internally I think, not UTF16 (or UCS4). Or, does someone know better? The MS API's are *challenging* at times...
Do the MS *mb* (i.e. multi-byte) functions know UTF8, or are they treating your text as if it were in some multi-byte codepage format?
nikego
May 13, 2015, 9:37:08 AM5/13/15
to fltkg...@googlegroups.com, ian.ma...@selex-es.com
Hi,
All; was an STR opened for this one? I remember there was some discussion but... My memory is not what it was; at least as far as I can remember it ever working...
I replied to Albrecht's message https://groups.google.com/d/msg/fltkgeneral/MR-I1jKCuGk/ny77V5FJDasJ
STC #2726 was only as Fluid problem, but indeed it's wider one.
I guess the debug DLL's get pulled in, and they will probably throw the assertion when they encounter any non-ASCII UTF8 character codes.
Yes.
I think iswalnum is for wide characters, which on Windows are UTF16, not UCS4.
However, for characters from the LGC languages, I guess there's a fair chance that the UTF16 value is "the same" as the UCS4 value would be, albeit in only 16-bits.
I'd imagine this would go awry when you start to hit characters form the higher Unicode planes, where UTF16 would need pairs to hold the full UCS4 value...
I doubt iswalnum is going to be right at this point though, since we are handling UTF8 text internally I think, not UTF16 (or UCS4).
No, in Fl_Text_Buffer.cxx isalnum is used for UCS4. See below code which crashes when user clicks on non-latin word in Fl_Text_Editor.
/*
Find the beginning of a word.
NOT UNICODE SAFE.
*/
int Fl_Text_Buffer::word_start(int pos) const {
// FIXME: character is ucs-4
while (pos>0 && (isalnum(char_at(pos)) || char_at(pos) == '_')) {
pos = prev_char(pos);
}
// FIXME: character is ucs-4
if (!(isalnum(char_at(pos)) || char_at(pos) == '_'))
pos = next_char(pos);
return pos;
}
/*
Find the beginning of a word.
NOT UNICODE SAFE.
*/
int Fl_Text_Buffer::word_start(int pos) const {
// FIXME: character is ucs-4
while (pos>0 && (isalnum(char_at(pos)) || char_at(pos) == '_')) {
pos = prev_char(pos);
}
// FIXME: character is ucs-4
if (!(isalnum(char_at(pos)) || char_at(pos) == '_'))
pos = next_char(pos);
return pos;
}
Do the MS *mb* (i.e. multi-byte) functions know UTF8, or are they treating your text as if it were in some multi-byte codepage format?
If I understand correctly, the *mbb* functions use the system code page. Because my CP is 1251 then the functions accept chars > 127 without crash. But how it will work with others CPs, I don't know... yet.
https://msdn.microsoft.com/en-us/library/aa298415%28v=vs.60%29.aspx
MacArthur, Ian (Selex ES, UK)
May 13, 2015, 11:42:18 AM5/13/15
to fltkg...@googlegroups.com
> > I think iswalnum is for wide characters, which on Windows are UTF16, not
> > UCS4.
> > However, for characters from the LGC languages, I guess there's a fair
> > chance that the UTF16 value is "the same" as the UCS4 value would be,
> > albeit in only 16-bits.
> > I'd imagine this would go awry when you start to hit characters form the
> > higher Unicode planes, where UTF16 would need pairs to hold the full
> > UCS4 value...
>
> > I doubt iswalnum is going to be right at this point though, since we are
> > handling UTF8 text internally I think, not UTF16 (or UCS4).
> > UCS4.
> > However, for characters from the LGC languages, I guess there's a fair
> > chance that the UTF16 value is "the same" as the UCS4 value would be,
> > albeit in only 16-bits.
> > I'd imagine this would go awry when you start to hit characters form the
> > higher Unicode planes, where UTF16 would need pairs to hold the full
> > UCS4 value...
>
> > I doubt iswalnum is going to be right at this point though, since we are
> > handling UTF8 text internally I think, not UTF16 (or UCS4).
> No, in Fl_Text_Buffer.cxx isalnum is used for UCS4. See below code which
> crashes when user clicks on non-latin word in Fl_Text_Editor.
Ugh, so it is.
> crashes when user clicks on non-latin word in Fl_Text_Editor.
Hmm, it looks like the Fl_Text_* widgets work partly in UTF8 and partly in UCS4, I did not know that.
I thought it was all UTF8.
To be honest, it might have been easier if we had made it UCS4 end to end, rather than what we have.
It is *a lot* easier to ascertain character positions in a string of UCS4 than in a string of UTF8...
Still, my point still (kinda) stands in that iswalnum on Windows will be expecting a UTF16 character, not a UCS4 one, so will fail on the supplementary language planes where UTF16 uses surrogate pairs.
On that basis, we seem to be passing UCS4 character values to a lot of the character test functions, none of which are well suited to handling UCS4 values, I suspect. (Nor are they good at UTF8 multi-byte-chars either...)
It does not look too good. No easy way out suggests itself right now...!
> > Do the MS *mb* (i.e. multi-byte) functions know UTF8, or are they
> > treating your text as if it were in some multi-byte codepage format?
> If I understand correctly, the *mbb* functions use the system code page.
> Because my CP is 1251 then the functions accept chars > 127 without
> crash. But how it will work with others CPs, I don't know... yet.
OK.
> Because my CP is 1251 then the functions accept chars > 127 without
> crash. But how it will work with others CPs, I don't know... yet.
You seem to have used the *mbc* functions rather than the *mbb* ones though.
What is the difference?
nikego
May 20, 2015, 4:37:57 AM5/20/15
to fltkg...@googlegroups.com, ian.ma...@selex-es.com
Hi, Ian
To be honest, it might have been easier if we had made it UCS4 end to end, rather than what we have.
It is *a lot* easier to ascertain character positions in a string of UCS4 than in a string of UTF8...
I think next position is not a very big problem, but what to do with the functions "is*"? Windows has no function to test ucs4.
Still, my point still (kinda) stands in that iswalnum on Windows will be expecting a UTF16 character, not a UCS4 one, so will fail on the supplementary language planes where UTF16 uses surrogate pairs.
iswalnum() won't fail because type of its argument is unsigned short. So we can have only collision when low word of usc4 will be less than 256.
So from the Windows view point the best way is to convert utf8 to utf16 and use isw****().
Nikita Egorov
Reply all
Reply to author
Forward
0 new messages