FBP: What is the Use Case

Ged Byrne

Paul Tarvydas
> Hi all,
>
> The question has been raised several times in this forum recently:
> What is the Use Case?
>
> I'd like to share what I believe the Use Case to be. It opens both
> editions of Paul's Flow Based Programming book:
> http://www.jpaulmorrison.com/fbp/intro.shtml
>
> "Imagine that you have a large and complex application running in your
> shop, and you discover that you need what looks like fairly complex
> changes made to it in a hurry. You consult your programmers and they
> tell you that the changes will probably take several months, but they
> will take a look. A meeting is called of all the people involved - not
> just programmers and analysts, but users and operations personnel as
> well. The essential logic of the program is put up on the wall, and
> the program designers walk through the program structure with the
> group. During the ensuing discussion, they realize that two new
> modules have to be written and some other ones have to change places.
> Total time to make the changes - a week!"
>
this is actually achieved needs to be clarified:
1. FBP works because it solves the "coupling" issue[1]. Components have
input API's AND output API's, or in different words, components cannot
"name" their peers[2].
1a. Example of Decoupled: send(myOutputPinX, value);
1aa. (Both, FBP and bmFBP do it this way).
1ab. The "kernel" or the "parent" determines "where" the value on
myOutputPinX gets delivered.
1b. Example of Coupled: send(ComponentB, pinY, value); or Call
ComponentB(value);
1bb. In the coupled case, the "caller" component determines where the
value gets delivered. i.e. it names ComponentB explicitly.
1c. When Management says "change the design", it is a trivial matter to
rewire decoupled components. You simply shuffle the components and
change the wiring.
1cc. When Management says "change the design", it is very hard to do in
a coupled system. You can't simply shuffle the components and "change
the wiring". The component-to-component wiring is hard-coded inside of
every component. Every component needs to be altered.
1d. The fundamental benefit of FBP is "send-to-output-port()". The
component places a value onto its output port, but does *not* know where
that value will be delivered. I.E. the receiver's name is not
hard-wired into the sender's code. The value is delivered by the parent
/ the kernel according to a wiring list, which is not owned, nor
manipulated, nor seen by the sender nor the receiver.
1e. "Asynchronousity" is a property of a "component". The component
must be written in such a way that it cannot know who is calling it, nor
who it calls. A component written that way is asynchronous. The
scheduler, then, decides how to deliver IPs, messages, events and in
what order. As long as the order is not built into the component, the
component is asynchronous.
2. Bounded queues are just an implementation detail. Bounded queues
provide decoupling, but so do unbounded queues (aka bounded queues of
length infinity) and bounded queues of length 1 (aka "variables").
3. Processes provide decoupling, but so does code that is written
without processes, if it is written to eschew coupling. It is possible
to write send-to-output-port() without using a process albeit, using a
"scheduler" to deliver IPs asynchronously.
4. Anything that uses CALL/RETURN between components has implicit
coupling and is not what FBP is about.
5. Event-driven and reactiveness is NOT the issue. Event-driven,
reactive components can certainly be decoupled and can have the same
wonderfullness of FBP.
6. NoFlo is mistakenly called "event driven" / "reactive". It is my
understanding that NoFlo is only reactive around the edges[3]. NoFlo
gets (asynchronous) events from node.js, but doesn't use node.js (nor
fibers, etc.) to implement the internal components. If my understanding
is correct, then non-node.js components in NoFlo are *synchronous*
(CALL/RETURN) and do not conform to the FBP notion of decoupling.
7. The idea that fine-grained components are too focused on control-flow
to result in an understandable design is provably false. I have
literally lived this use-case - using a truly reactive variant of FBP -
and documented it in a paper[4]. Two weeks for two people to change
roughly 10 man-years of work, consisting of some 300 hierarchical
components.
8. Stop thinking "flat" and think "hierarchical". Nested FBP diagrams
reduce the cognitive load at every level.
9. Try writing a mouse driver. Try writing a network protocol stack
(esp. using OSI 7-layer design). Try writing a GUI. Try writing an
operating system. Solutions for these problems can easily be expressed
using FBP-ish diagrams composed with decoupled components. You will,
though, find yourself thinking a bit more reactively when solving these
classes of problems.
10. My personal, general objective: can we make it so cheap that we can
use FBP for every line of code?
pt
[1] Chapter 1 of Faison's book discusses this issue quite well
http://www.amazon.com/Event-Based-Programming-Taking-Events-Limit/dp/1590596439/ref=sr_1_4?ie=UTF8&qid=1423255910&sr=8-4&keywords=faison#reader_1590596439
[2] Original CSP and Actors had this problem.
[3] Please correct me if I'm mis-stating. The NoFlo people are welcome
to respond to Ged's challenge, specifically, about NoFlo.
[4] http://dl.acm.org/citation.cfm?id=1266935 section 4.5.1.

Paul Morrison
Very interesting summary, Paul!
Minor quibble - point 2: IMO we could not have built our systems using unbounded queues. a) there is no guarantee that data will ever be processed, and b) such systems could potentially use infinite resources!
Regards,
The other Paul
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-programming+unsub...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Kenneth Kan
9. Try writing a mouse driver. Try writing a network protocol stack
(esp. using OSI 7-layer design). Try writing a GUI. Try writing an
operating system. Solutions for these problems can easily be expressed
using FBP-ish diagrams composed with decoupled components. You will,
though, find yourself thinking a bit more reactively when solving these
classes of problems.
10. My personal, general objective: can we make it so cheap that we can
use FBP for every line of code?
Ged Byrne
I'm glad you agree with the use case. I'm hoping we can all find a single point of agreement.
I'm entirely neutral about how the use case is achieved.
I am interested in time stretched, long lived processes for SMEs. The type of thing the big companies do with BPM and an army of specialists but boiled down to its essence so that it's accessible to small companies with limited resources.
I suspect that your context is different. Different problems + different resource = different solution.
I believe, however, that this use case is universal. Building a system from reusable components that is accessible to a wide range of stakeholders and responsive to change with reasonable effort.
Regards,
Ged
Ged Byrne
Don't forget the cost of comprehension.
Code complexity is like page loading time. Just as every second loses potential visitors extra complexity loses readers.
The milestones of complexity are sequences, trees and graphs.
Humans find sequences the easiest to comprehend and navigate. In a recipe book you'll find a lists of instructions. I've never seen a recipe book with boxes and arrows.
When we introduce variation to the list things grow more complicated. Most recipes books get away with a few GOTOs but for software they soon becomes harmful.
So we move to trees. The code becomes structured by adding selection and iteration to the sequences. We've these control structures a single tree can describe many sequences. With trees we can describe any sequence that can be described by a context-free grammar.
Most people can grasp trees. They are fairly accessible, but not as accessible as a nice simple sequences. That's why we have shopping lists and not shopping trees.
But context-free grammars are not enough. Then we must start using a graph. A single graph can describe many trees but they are difficult to comprehend for the majority of people.
We can describe anything with graphs, but that does not mean that we should. Not of we want a wide range of people to understand.
If we are to create descriptions that are accessible to people then we should use lists whenever possible, trees where necessary and graphs as little as possible.
The power of classic FBP isn't just that it presents the whole system as a single graph. The true power comes from the fact that those graphs then decompose into to trees and lists.
The reader can navigate the graph, producing a simple sequence. The rule about having IPs in just one place and having an explicit splitter helps us stick to this. IPs progress cleanly like a drink through a straw. They don't spread out like spilt milk and cause worry.
The reader can be confident that IPs navigate the same way that they read. When the reader encounters a splitter it becomes clear to them that they have encountered a branch and their line has become a tree.
The reader can also look at clear, simple code that describes trees through sequence, selection and iteration. Again they can walk the code to build multiple sequences. The programmer is spared the need to use recursion to describe graphs and so they are not forced to leave the casual reader behind.
Better than that the reader is spared the need to read the code because it implements a context-free grammar. V -> w, so the relationship between input and output can be succinctly described in the form of a contract. Given this input we can expect that output.
FBP doesn't tie out hands here like Functional programming. It helps us keep to these guidelines until it threatens the comprehension of what are system is doing. If these rules start to make our descriptions cumbersome we are free to break them. FBP does not enforce the laws, it just makes following them easy. It makes doing the right thing the path of least resistance.
That's what good design is all about.
Regards,
Ged
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
Paul Morrison
Hi Ged,
Your last paragraph really rang a bell for me! I think I realized this years ago - even before FBP: forbid as little as possible, but make good practice easier and/or cheaper!
This is like Nate Edwards' method of getting hardware designers to use components - he told them they were free to build their own components but then they had to carry the cost of testing!
Thanks for an insightful article, Ged!
Regards,
Paul

co...@ccil.org
> FBP doesn't tie our hands here like Functional programming.
An FBP graph is a functional program, but the separation between
components means that any non-functional parts are encapsulated
where they can do no harm. This is the reverse of Haskell, where
the imperative parts are at the top level and invoke the functional
parts as needed.
--
John Cowan http://www.ccil.org/~cowan co...@ccil.org
"Hacking is the true football." --F.W. Campbell (1863) in response to a
successful attempt to ban shin-kicking from soccer. Today, it's biting.
Kenneth Kan
An FBP graph is a functional program, but the separation between
components means that any non-functional parts are encapsulated
where they can do no harm. This is the reverse of Haskell, where
the imperative parts are at the top level and invoke the functional
parts as needed.
Paul Tarvydas
Very interesting summary, Paul!
Minor quibble - point 2: IMO we could not have built our systems using unbounded queues. a) there is no guarantee that data will ever be processed, and b) such systems could potentially use infinite resources!
Minor quibble with your minor quibble. I think that that means they cancel out and produce an unquibble.
You *could not* have built your systems using unbounded queues and the very same system design.
You *could* have built the system using unbounded queues if you had added one more line - a throttle. An explicit back-pressure line. Or, more likely, a "send next record" line.
I often work with protocols - it is important to me to show back-pressure explicitly on the diagram. You don't like to show back-pressure explicitly. I think it's a matter of taste... (or problem domain).
pt
Regards,
The other Paul
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.
Paul Morrison
On Mar 16, 2015 6:35 PM, "Paul Tarvydas" <paulta...@gmail.com> wrote:
>
> On 15-03-15 05:21 PM, Paul Morrison wrote:
>>
>> Very interesting summary, Paul!
>>
>> Minor quibble - point 2: IMO we could not have built our systems using unbounded queues. a) there is no guarantee that data will ever be processed, and b) such systems could potentially use infinite resources!
>
>
> Hi Paul,
>
> Minor quibble with your minor quibble. I think that that means they cancel out and produce an unquibble.
>
> You *could not* have built your systems using unbounded queues and the very same system design.
>
> You *could* have built the system using unbounded queues if you had added one more line - a throttle. An explicit back-pressure line. Or, more likely, a "send next record" line.
Sorry, don't understand! Do you mean line in a diagram? If so, I want back pressure on every line, so why should I mark it? Of course, its easy to implement in cFBP. If it's expensive in your system, I can sort of see why you might want to use it sparingly , but I think that makes the mental model more complex...
What is a "send next record" line?
>
> I often work with protocols - it is important to me to show back-pressure explicitly on the diagram. You don't like to show back-pressure explicitly. I think it's a matter of taste... (or problem domain).
>
Do you have some concrete examples?
Regards,
Paul
Paul Tarvydas
>
>
> Sorry, don't understand! Do you mean line in a diagram?
>
> If so, I want back pressure on every line, so why should I mark it?
>
In my problem domain (true reactive), there are lots of "control signals".
1. These control signals are important pieces of the architecture and I
expect to draw them explicitly, so that other engineers can see what my
intention is for the architecture.
2. I know something concrete about the control signals. They *never*
happen frequently enough to need back-pressure. So, putting
back-pressure on them is a waste.
> ... , but I think that makes the mental model more complex...
>
I don't think so :-). In fact, I know it doesn't make it more complex
:-). It *might* be a different way of thinking (EE), so there might be
some learning curve associated to switching between the two models.
> What is a "send next record" line?
>
This is what implicitly happens in cFBP when the bounded queue is full
and a very short time-slice is used. Every time the reader pulls a
record out of the queue (freeing one slot in the queue), the writer is
woken up (put on the kernel's active queue) and implicitly "asked" to
put one more record into the queue. If the time-slice is very coarse,
then the reader might drain the queue down some more, before the writer
gets a chance to run, but, the writer is put into the ACTIVE state after
the very first slot is freed up.
> >
> > I often work with protocols - it is important to me to show
> back-pressure explicitly on the diagram. You don't like to show
> back-pressure explicitly. I think it's a matter of taste... (or
> problem domain).
> >
>
> Do you have some concrete examples?
>
Think of a mouse driver written in FBP (that happens to be the kind of
thing I program with FBP).
As a user swipes the mouse, it produces a rapid sequence of mouse-move
events. Let's say that the mouse produced 50 events. Your bounded queue
is set to 25. What happened to the other 25 mouse-move events? The
most important event is the last one - the final position of the mouse.
Where did that one go?
pt
Ged Byrne
Your explicit control signals sound interesting. What do they look like? How do they work?
Thanks,
Ged
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-programming+unsub...@googlegroups.com.
Paul Tarvydas
> Paul,
>
> Your explicit control signals sound interesting. What do they look
> like? How do they work?
>
> Thanks,
for a demo I did in 2009. At the 7-second-ish mark, I dive into a
component (text-buttons) which is composed of a bunch of instances of
push-button-control. If you stop it at the 9 second mark, you will see
a component at the very top called eliding-button-control. When
eliding-button-control gets a trigger on its "toggle" input, it changes
between two states. If it is in the already-elided state, it changes to
expand and sends a control IP (containing the message 'elide or 'expand)
out of its "elide" pin - this travels to every push-button below it and
arrives on their "hide" pins. The buttons all react to this message and
either make themselves visible or invisible. And v.v.
At the 18 second mark, there are two components view-controller and
graphics-fb (FactBase - triple store).
When the view-controller wants to know which objects the mouse is over,
it shoots a trigger out of its "get-hits" pin. The graphic-fb does a
bounding rectangle calculation and shoots back a list objects.
https://www.youtube.com/watch?v=8vZ8Pi32oMo
Does this answer your question(s)?
pt
Paul Morrison
On Mar 17, 2015 11:31 AM, "Paul Tarvydas" <paulta...@gmail.com> wrote:
> Think of a mouse driver written in FBP (that happens to be the kind of thing I program with FBP).
>
> As a user swipes the mouse, it produces a rapid sequence of mouse-move events. Let's say that the mouse produced 50 events. Your bounded queue is set to 25. What happened to the other 25 mouse-move events? The most important event is the last one - the final position of the mouse. Where did that one go?
>
> pt
Ah! I implemented this recently as a connection attribute on the cFBP implementations - I called it "dropOldest". I'm sure I posted this on the Group! :-) I guess for my purposes the default goes the other way, but I get your point.
Regards,
TOP (The Other Paul)
Paul Tarvydas
>
> TOP (The Other Paul)
>
I *thought* I was The Other. You are The One. Oops, still doesn't
differentiate :-).
pt

John Cowan
> Ah! I implemented this recently as a connection attribute on the cFBP
> implementations - I called it "dropOldest".
that reads mouse events directly from the mouse (not as IPs) and keeps
just the latest event. When it receives a packet from its input port
(whose content is unimportant), it sends the saved event to its output port.
As we all know, civil libertarians are not the friskiest group around --
comes from forever being on the qui vive for the sound of jack-booted
fascism coming down the pike. --Molly Ivins
Paul Morrison
I didn't see your previous post - you're right, that would work. Actually these two solutions are clearly push and pull, respectively!
I just thought dropOldest would be generally useful, and it looks pretty in the diagram (I use a zigzag line)!
Paul Morrison
> --
We could take turns!
Regards,
One of the Pauls :-)
Rolf Lampa
"I am interested in time stretched, long lived processes for SMEs."
I am extremely interested in learning/knowing how well suited FBP is for building Business Enterprise Systems (I once designed a huge monolith system which still is very much in use as a commercial software, object oriented/ORM).
But I must admit that I have difficulties in grasping how and "from which angle" to approach anything alike using FBP.
I really much appreciate this whole thread, and I think I understand most of the stated REASONS for using FBP. But HOW to go about using a "process" oriented approach to handle data which is mostly consists of (stateful) object structures with complex inter-dependencies (in a relational database) is a big change. No technical details I've seen so far regarding FBP seems to point me at where and how to start, although I DO have a Use Case (a very very very very huge ERP system which I'd like to make more scalable).
So if anyone could give some pointers in a similar form as the excellent post about the Use Case, but instead focusing on how to get started with, lets say something that's in the core of any ERP system, like
* an organization module (with main classes Organization & Department and Persons/Contacts, and
* a "geographic" domain with main classes Country, PostOffice, City, and
* how these kind of structures best are stored (regarding the fact that these kind of objects are linked to / referred to from almost every other part of any complex business system) and
* what approach and benefits one would gain from using FBP to serve the rest of the system with whatever these "problem domains" (Organization & Geographic domains) usually provides.
Notice for example that also Business Events often needs to be (geographically) "located" as to be able to determine which time zone to relate to (that is, have references to addresses, and it's spatial context like PO and Country and/or customized Regional Zones etc), which also relates to currency, and which currency rate was current at that very point in time, in that location, etc.
Not to forget what language(s) are likely to be useful in event-related user interaction and documents. And so on.
I chose as an example some of the most (non dynamic) "stale" types of data because if someone can tell me how to deal with such data (most common in ERP systems) in a meaningful way with FBP, then the approach and the usefulness of handling "any other kind of data" would be both obvious and implied. :)
Things of interest is like preferred data storage for what is (today) essentially a class based system and whether FBP is suitable for serving from such a persistence solution. The ORM solution currently used has many benefits, but it has limitations in terms of performance (number of business transactions/events) and overall scalability. In order to compute massive amounts of business events (bookings, planning etc) only a distributed system would really scale, but that's not an easy thing to achieve with "tight" ORM solution (and memory tends to be filled with object structures). Document databases comes to mind, but I have no experience of those.
This is the kind of questions that, if well answered, could really open up for FBP as enterprise business systems is where the money is.
It may or may not have significance, but one thing that is special with the current (monolithic) system i built is it's (object) granularity (and numerous "smart" relations) which is of immense value for analysis and reports. There's simply "no question that can't be answered" about any aspect of the operational business. And much of the logic is actually comprised by the very structure in which data is organized (I call it imp-logic, that is, implied logic, one only have to sum things up, at the desired "level of granularity"). If this last passage sounds too spooky, just disregard it and try give general pointers for how to approach any "traditional ERP system" out there.
I have read your book Paul ("TOP" :) ) and it really is an inspiration, but it didn't seem to address the higher level of "conceptual patterns" and general approaches I'm looking for here.
Best regards,
// Rolf Lampa
Ged Byrne
As far as the static structures go then you can carry on using the same approach you have followed using OO/ORM.
My experience with ERP is that there is a lot of duplication and associated complexity.
For example, you usually have a fundamental concept of a LINE.
Let's say I raise an Order. That Order has multiple lines. Imagine it's an online bookstore and I order a copy of Paul's FBP book.
First I add the book to my cart. A CART-LINE is created.
I go to checkout and an ORDER is created. That ORDER has an ORDER-LINE for my FBP book. The CART-LINE is destroyed, and possibly a SKU-LINE as well.
Then as the order multiple lines are created and destroyed for billing and provisioning and reporting and a whole load of other purposes.
Those lines are all distinct and separate entities. They may contain "reference" fields, but these are weak. No referential integrity is enforced.
If I want to follow the FBP book as it moves through the system, being replicated from one system to the next, I will struggle.
If I say "This line on this order, where is the delivery note for it" the task is usually non trivial involving complex joins and an understanding of the complex system interactions.
With a FBP approach we have a single IP for the book entity. This IP does not contain all of the data for ordering, provisioning or charging but it does provide a single, distinct artefact that uniquely identifies this instance of the FBP book in our system. It is what Lean thinkers would call a kanban:
http://leankit.com/kanban/what-is-kanban/
The flow graph will show the possible journeys that the book instance will take from procurement to delivery.
There can be only one IP for the book because there is only one book.
On the far right of the flow-graph we have a stock component. Our FBP book sits in here. Perhaps there is a sub-graph with components that relate to the different physical warehouses. It's all about maintaining the relationships with real world and making them visible.
When we place the book in our cart the IP moves from the STOCK component to the CART component. Perhaps a placeholder remains so that those querying stock can see where it has gone.
There are two ports out of cart: RETURN-TO-STOCK and PROCEED-TO-CHECKOUT.
When we go to the checkout our IP is sent to the out port and queued to proceed to the CHECKOUT. This will probably be load balanced to several processors for a quick response time. The load balancing is described in a sub graph.
CHECKOUT is a sub graph describing the possible routes such as:
ENTER-PAYMENT-DETAILS -> REQUEST-PAYMENT -> CUSTOMER-CONFIRMS -> COMPLETE-PAYMENT
That is one route. Another route might be LOGIN -> CUSTOMER-CONFIRMS -> CONTINUE-SHOPPING
The user interface is reactive so the changes in state on the server are quickly propagated to the client. When the IP arrives at CUSTOMER-CONFIRMS the client interface will reflect this by displaying the confirmation page. This will look rather like Spring-Webflow only using a flow graph instead of a state machine:
The flow of screens is driven by the flow graph and not the UI. Ideally you would want to be able to define your flow graph and the shape of the IP and automatically generate the interface from that, similar to ApAche Isis: http://isis.apache.org/
The shape of our IP is based on a Behciour tree. As the IP progresses through the graph it's state changes and the behaviour tree describes this. The fields and actions change as we move from state to state. Just as in games the UI knows how to respond to these changes and translate the behaviour tree into a meaningful UI: http://www.gamasutra.com/blogs/ChrisSimpson/20140717/221339/Behavior_trees_for_AI_How_they_work.php
How to prepare you BAs for this brave new world? Get them reading Jackson and Demarco:
* http://en.m.wikipedia.org/wiki/Jackson_system_development
* http://en.m.wikipedia.org/wiki/Structured_analysis
For your developers the flow graph will be used like an ESB. I have a post mapping FBP to the EIPs here (my first post in the thread):
https://groups.google.com/forum/m/#!topic/flow-based-programming/II1v7m_eWv8
As you can see I am drawing together a lot of disparate threads here. I haven't mentioned BPMN bit I'm sure you can see the similarity.
The power of FBP is nothing new. What it provides is a single, simple framework that brings all these threads together.
FBP takes all these specialised areas speaking differing languages into a unified whole with a common tongue: The language of Flow.
That's is how the use case is satisfied. Now they can all get together around the same diagram and work together to solve the real, essential problem without getting lost in the accidental complexity.
I hope you find this useful. I'd love to see somebody use these ideas. My day job doesn't give me the opportunity to do so.
Regards,
Ged
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-progra...@googlegroups.com.

John Nilsson
Paul Tarvydas
which angle" to approach anything alike using FBP.
did have a peek at the DDS sample
http://dddsample.sourceforge.net/patterns-reference.html
It's basically an OO set of data structures and, I guess, a few patterns
that govern how to interrelate the data (e.g. like MVC).
I gave up on OO because, while it is good for organizing hierarchical
data (graphics is the only example that comes to mind), OO completely
obfuscates control flow.
FBP shows control flow. "Collate" is an assembly-line - a pattern that
describes the left-to-right flow of data and shows, on a diagram, what
operations will take place.
DDDS, I *think*, would simply be a collection of such assembly-line
patterns, with a GUI box at the far left. The GUI causes a chunk of
data to be routed into a pattern, e.g. change-route, and the data would
flow through the assembly-line, then it would placed back into the
"database".
Shhh, don't tell Paul M I said this, it is *possible* (not recommended)
using one's own implementation of FBP to send pointers-to-objects as
IP's. In this case, the FBP components would be essentially scripts -
they receive an object, push a couple of buttons on the object and send
it along down the line. So, it is *possible* to mix the two paradigms
(OO and FBP).
Now, I will comment on how to store data, and you(s) will likely find
this to be controversial :-)...
The fatal flaw in OO, structured programming, strongly typed
programming, etc. is that it causes one to design the strongly-connected
data structure(s) too early in the design process.
If you've ever worked in a C shop, you saw the symptoms of this problem
- after two years of development, management adds a requirement and the
shop threatens to mutiny or quotes ridiculous time-frames for a
seemingly simple change.
I have found (in 30+ years) but one data structuring technique that does
not exhibit this problem, and now I use it almost exclusively. I call it
a factbase. XML calls it a triple-store (but then someone bent the spec
to include a 4th field, sigh).
Express everything as a triple. Relation(Subject, Object). A very
restricted form of Prolog. Write Prolog-like queries against the
factbase and put the query scripts into FBP boxes.
For example, two years down the road, DDDS needs to add a new kind of
routine leg (SpaceX) which requires a new kind of relationship to be
stored in the factbase. No problem, add it, none of the previous stuff
breaks - because none of the previous stuff has any hard-coded knowledge
of the data structure, everything is a triple and all collections and
operations on the data is expressed as logic queries. The old logic
queries "skip over" the new relation, since they don't even know about it.
If you google for pharmaceutical / XML / healthcare / research /
genetics / etc. you will find that really, really big data is being
stored in this (scalable) manner.
E.G. Franz is attacking this market niche
http://franz.com/agraph/allegrograph/ .
pt
Rolf Lampa
Wow! You answered more questions than I had asked. Now we are approaching the heart of the matter (of FBP).
My short summary: As any business system consists of, let's say, 50% data structures and 50% Behavior, FBP is directly suitable, but (perhaps) not limited to taking care of Behavior. I happen to know - as soon as I read your post - that FBP is useful for replacing/handling behavior in ANY business system.
----
Let me share with you some more thoughts invoked by Ge's post, although much less significant than my short summary above:
As a matter fact, when I read your link about AI & "Behavior trees" I realized that I actually had designed everything that "Behavior Trees" is meant to handle, but, I didn't use that term, and I designed my solution "on top" of the classical OOP approach (with states stored exclusively as values in object properties).
But when I realized (at the end of the design process) that behavior should be, not only the "processor" (singularis), but the very "fabric and path-ways" (or "flow-chart"), including the "processors" of a Behavior Machine (which is the term I used to describe what I also called the "Meta System" of the ERP system I built), at that point in time I didn't have the time to separate the Behavior Machine into a "freestanding" flow-chart of its own, instead it's embedded into the system, although separately "executable". Worth to note is that the whole "Behavior Tree" (my "Meta System" or "Behavior Machine") could be defined, executed and tested in run-time without ever having to take down the running system. Which sounds risky (and it is) but have been proven useful in some cases (for example for fixing broken data structures by creating "repair processes", again, in run-time, then fixing what was broken, and at last, deleting the "fix tools" which was a sub-net of states where scripts where triggered to execute in the transitions).
Again, thank you very much for your post Ged.
I don't understand how I didn't see what I now see, but you hit right at it. Every Business System Designer out there needs to be aware of this essential fact - The BEHAVIOR part (at least) of any Business System is to be designed using FBP. Exactly that sentence is the magic, although not "silver" bullet in communicating what FBP is good for to designers of Business Systems. At least to me that short summary explains more than everything else I have read about FBP for about two years by now. Remark.
Now remains only to elaborate on more aspects of Enterprise Business Systems.
What wasn't really answered, and I think that it's very important to have pointers, is to try identify what KIND of (persistent) storage is best/easiest utilized by FBP for collecting and examining data in a way that is more easily DISTRIBUTED.
As I mentioned, I designed an extremely complex data structure (and for good reasons) and by implication an FBP approach for sweeping over and assigning and detaching objects in that incredibly complex - but also extremely efficient (for the purpose) structure - would be... like "swearing in the decoupling church". But perhaps I simply must think in terms of "bigger" components which hides such complexity. For a very small and very limited example of why data structures may benefit from more TECHNICAL complexity, see this article which I wrote some years ago:
http://bionics.it/posts/dynamic-navigation-for-higher-performance/
// Rolf Lampa
Paul Morrison
I really like Ged's kanban image... I think we did something like that with our screen manager component (about 30 years ago) described in http://www.jpaulmorrison.com/fbp/scrmgr.shtml - do a find on BLSB. Here the same substreams were used in both an interactive and a batch mode.
The other neat thing about IPs is that different components can process or ignore different parts of the IP. I used that, among other examples, to alternate between lists and the items being listed...
In http://www.jpaulmorrison.com/fbp/online.shtml I talk about not implementing the screen flow as a network - I much prefer table-driven...
Another point about FBP is that it lets apps grow organically... - this lets you put in the frills (editing, formatting, etc.) later, rather than early on in development.
It seems to me that ORMs could be encapsulated as components. Our JavaFBP brokerage app used SQL - and we stored a lot of data there as strings, not numeric values. For instance, 30.45 Canadian $ was stored as "CAD30.45" - this didn't even need an ORM - we just had a Money class with appropriate constructors and toString() methods. Still I could see building more complex ORMs as subnets - or even building specialized database structures - whichever makes sense.
BTW Did you know the Java Date and the SQL Date are different...? Go figure! And we converted all dates to UTC.
I'd like to mention MCBSIM again - this component accessed a simple database. Since it had an input port and an output port, it could be used in both "stream" and "subroutine" style. See p.341 of the 2nd edition...
On Monday, April 13, 2015 at 12:45:33 PM UTC-4, Paul Tarvydas wrote:
Shhh, don't tell Paul M I said this, it is *possible* (not recommended)
using one's own implementation of FBP to send pointers-to-objects as
IP's. In this case, the FBP components would be essentially scripts -
they receive an object, push a couple of buttons on the object and send
it along down the line. So, it is *possible* to mix the two paradigms
(OO and FBP).
I heard that! :-) However, Paul T., how is this different from the FBP "tree" structure" - http://www.jpaulmorrison.com/fbp/tree.shtml . Your description sounds very accurate! :-)
I'm sure lots of comments will be posted to this topic - but maybe the best way to learn will be to actually build an app. Sounds like fun!
Regards,
Paul M.
Rolf Lampa
Shhh, don't tell Paul M I said this, it is *possible* (not recommended)
using one's own implementation of FBP to send pointers-to-objects as
IP's. In this case, the FBP components would be essentially scripts -
they receive an object, push a couple of buttons on the object and send
it along down the line. So, it is *possible* to mix the two paradigms
(OO and FBP).
As I mentioned, my "Behavior Machine" (BM) is essentially a whole "mind" (or, a "global machine") controlling all behavior in the system, a mind which determines which pathway to proceed (although the processing that could have been executed by the "state" was traditional OOP procedures).
In order to let that monster BM control the behavior I did just that which you mentioned, namely handing over the objects to the Behavior Machine as pointers (to the object) and so the behavior took place (transitions triggered constrained by OCL rules).
What bugs me in hindsight though, is that I had to stop the design at the level of having the Behavior Machine only inserting the resulting state as a string value into the dedicated string property of each object (called, well, "CurrentStates: String") in the following form "[inprocess][waiting][printed]" etc.
The string indicates that entirely different groups of states ("state cycles", or "behavior sequences" if lending terminology from behavior trees) can be started and applied to any object. But in any case, a global "mind-map" or "flow-chart" defines and executes all the rules of what was allowed and not, and when.
OOP and State
The locally stored "value" representing a state is an annoying limitation once one have "seen the light" regarding behavior as a pathway and a flow-chart. State should instead be represented with a REFERENCE to a component (or, "state"). Which is also what I actually implemented (while still keeping the state field since the reference approach requires some tricky additional design before being fully generic). From the state's perspective, there's a "list of objects" currently being in the particular state, like so:
[State A]-1------*-[Object]
Notice the fact that using a reference (link) which is (should be) navigable in both direction isn't a trivial thing in most traditional OOP contexts, but the conceptual demands for a behavior machine is even worse: You often need several links for sub-states ("Leafs"), and sometimes an object uses several different "state cycles" (term from regular state machines).
A reasonable approach then seems to be to store a LIST of REFERENCES in each object, instead of the hard coded links which "technically speaking" maps to persistent relations in ORM databases. A canditate solution would be to store "triples" (of ref:ids) as strings in the object(s).
Triples stored in a string field may sound as something close to storing only the state's name (which was my first approach) but it isn't. Using a state name (in string format) is a "natural key" which may cause conflicts in a big systems (where states in different contexts can have the same name) while a reference can reference a state's "unnatural" id, preferably a GUID, and so It'd never get misinterpreted.
Perhaps all this is a good match for document databases? Any experts on NOSQL out there could give further guidance. I'm very interested in finding a reasonable good persistence solution for a mix of OOP--FBP as described so far in this thread, a DISTRIBUTABLE persistence solution supporting realtime high performance computations.
// Rolf Lampa
Ged Byrne
Obviously these are my own ideas, and not the only approach to applying FBP. My post is just to show how the flow perspective can be applied.
Te behaviour trees in particular are my way to modernise Jackson's Structure Diagrams:
https://kartika124.files.wordpress.com/2009/02/jsp.pdf
I'll post more when I've had chance to read through everything.
Regards,
Ged
--
Ged Byrne
Ged Byrne

Sam Watkins
> Express everything as a triple. Relation(Subject, Object). A very
> restricted form of Prolog. Write Prolog-like queries against the
> factbase and put the query scripts into FBP boxes.
serve to filter them or transform them to infer new facts?
Ged Byrne
Ports are a specific fact type. Inserting a fact of that type is the same as sending to a specific port.
Since we are dealing with long lived processes the queuing logic isn't the usual FIFO. IPs will remain in a queue until they are ready to be processed, such as a certain date I condition being reached.
Also, it doesn't make senses to rub processes on separate threads if they are only going to actually run once a month or possibly never. Processes are started by rule firings.
I'm calling it Plip Plop Programming rather than Flow Based since it involves a few drops now and then and not a constant flow.
Regards,
Ged
John Nilsson
BR,
Ged Byrne
My inspiration for the system I'm designing, which I'm calling Plip Plop Programming rather than Flow Based because it is designed for SMEs with low volumes and a trickle of events over time, comes from this passage from the 1997 book "Building Process Implementation - Building Workflow Systems" by Michael Jackson and Graham Twaddle:
John Nilsson
Ged Byrne
Glad to hear you found it useful.
John Nilsson
Would you do something similar here? I.e record the events of as the IPs are sent and recieved? I.e how to get views for "what is the status of my request?" and "What is the typical ratio of approvals for July?"
BR
John
Ged Byrne
Write SQL for any of these queries and take a look at the execution plan. There you will see the flow graph generate to construct the data set.
http://en.m.wikipedia.org/wiki/Query_plan
If your using NoSQL then you'll be constructing the flow graph for yourself.
Obviously these graphs execute in a different timeframe to the long lived processes I've been talking about.
Regards,
Ged
John Nilsson
Paul Morrison
On Tuesday, April 14, 2015 at 8:52:09 AM UTC-4, Ged Byrne wrote:
FBP takes a different approach, as described in Paul's chapter on control IPs and Checkpointing:
Just wanted to point out that the Checkpointing chapter just described a way FBP can be used to do checkpointing - FBP doesn't mandate any particular approach.
In the 2nd edition of my book there is some discussion of "optimistic" checkpointing (p. 194), and Ohua (same page, just above), both strategies which get around some of these problems in the case of large volume systems.
Regards,
Paul M.
Paul Morrison
Oddly enough, Nate Edwards came up with a similar design many years ago, which he called the "accountant's view", pointing out that a database is just a snapshot of the data at a particular point in time. The event list should be write-once, read-many! Of course in those days we didn't think it would perform very well!
Ged Byrne
That sounds like it could work.
FBP doesn't tell you how to build the system, it tells you how to see it.
Once you can see the system, you can see what works and what doesn't.
Once you see the flow, What is right or wrong thing becomes clear. You follow your senses, not a set of prescribed rules.
Regards,
Ged
Paul Tarvydas
Let's leave 'em guessing :-)
pt
Paul Tarvydas
> Paul Morrison scripsit:
>
>> Ah! I implemented this recently as a connection attribute on the cFBP
>> implementations - I called it "dropOldest".
> As I pointed out, this can be implemented in standard FBP with a component
> that reads mouse events directly from the mouse (not as IPs) and keeps
> just the latest event. When it receives a packet from its input port
> (whose content is unimportant), it sends the saved event to its output port.
>
I didn't see this, either (but I have an excuse :-).
This sounds interesting, but I'm pretty sure that I'm missing something.
When you say "read mouse events directly", what do you mean?
Windows pushes mouse events at us via the main loop. Hardware pushes
mouse events at us via interrupts.
Is your model different from these, or am I just not understanding your
description?
Thanks
pt
Paul Tarvydas
:-).
It depends on the problem.
When I write a compiler, I think in terms of "passes" (scanner, parser,
semantic check, allocator, emitter).
In such a case, the factbase is a single IP. A pass adds new facts to
the factbase, then sends it down the line for further processing /
embellishment.
In this example https://github.com/guitarvydas/vsh I built a simple FBP
diagram compiler in itself. I used lisp hash tables to implement the
factbase and I used simple loops instead of a unifier.
And, in other cases, I've created a factbase inside of every component,
then fired facts around as IP's. In some ways this was "better"
(completely distributed and concurrent), in others it was "worse"
(components could choose to send facts selectively to different
components, causing inconsistencies in the distributed factbases and
potentially disrupting one of the key advantages of factbases ("all the
data is in the factbase, skip the stuff that isn't interesting")).
I guess that what I just said is - I'm still thinking about these
issues... :-).
pt
Paul Morrison
Not quite sure what your question is... this seems to go back to a conversation within this topic from last June. I was just saying that I had added a "dropOldest" connection attribute to JavaFBP and DrawFBP, in which a send to it doesn't suspend, but drops the "oldest" IP in the connection. I thought it might be useful in situations where you can afford to drop IPs without processing them, such as events from a mouse drag function.
pt
--
You received this message because you are subscribed to the Google Groups "Flow Based Programming" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flow-based-programming+unsub...@googlegroups.com.
John Cowan
> When you say "read mouse events directly", what do you mean?
You can make it periodically reading a temperature sensor if you like:
the idea is the same. All but the most recent value is discarded,
and that value will be sent to the output port whenever an arbitrary
packet is read from the input port, rather than queuing them all up to
be sent to the output port regardless of age.
--
John Cowan http://www.ccil.org/~cowan co...@ccil.org
I now introduce Professor Smullyan, who will prove to you that either
he doesn't exist or you don't exist, but you won't know which.
--Melvin Fitting
Paul Morrison
I decided to try to draw your application below, and there turned out to be some quirks. I am attaching it below, with some explanation. I am actually not sure how much FBP simplifies the logic as a lot of it is pretty synchronous! However, I would like to throw this open - there may well be other valid FBP solutions to this problem.
On Tuesday, April 14, 2015 at 8:52:09 AM UTC-4, Ged Byrne wrote:
What about a practical example. Here's one from Plan B software: http://blogs.planbsoftware.co.nz/?p=247"Imagine the following scenario for a leave approval system.* An employee applies for leave.* The request for leave must be approved by the HR manager* The request for leave must be approved by the employees line Manager.* If both the HR manager and the line manager approve the request it can then be authorized.* Both the HR manager and the line manager will make their decisions independently of each other."For this I would build a simple flow graph that would behave as follows:First a REQUEST_LEAVE component that receives a request IP. For every IP received two new IPs are created for HR and Line Manager approval. The original IP is sent to the COLLATE_REQUEST_APPROVAL. The new IPs are sent to the HR_APPROVE_LEAVE and LINE_MANAGER_APPROVE_LEAVE.These two components allow HR and the Line Manager to approve or reject the leave request.Their choice is sent to COLLATE_REQUEST_APPROVAL.COLLATE_REQUEST_APPROVAL receives from LEAVE_REQUEST, HR_APPROVE_LEAVE, LINE_MANAGER_APPROVE_LEAVE and a TIMER.When COLLATE_REQUEST_APPROVAL receives a request IP it creates an entry for it and calculates an escalation date for it based on configuration.When it receieves one of the approvals it updates the request IP and checks to see if it has both HR and Line Manager approvals yet.When both have been received it sends the request IP to either APPROVE_REQUEST or REJECT_REQUEST based on the Approval content.When it receives an IP from TIMER it sends any request IP that has passed it's escalation date to ESCALATE_REQUEST.

The first thing I came up with is that COLLATE_REQUEST_APPROVALS is essentially a database manager. As I said in the book in connection with MCBSIM (2nd ed., p. 341), a send/receive call is essentially the same as a "call", except that it can be "opened up" if desired, in which case the input comes from one process, and the output goes to another.
btw I feel COLLATE may be a bit of a misnomer as Collate is usually used to describe a merging process involving 2 or more streams of IPs sorted on the same key. In this case I might suggest something like CORRELATE.
Now, in this diagram, the inputs to COLLATE_REQUEST_APPROVALS come from different sources. Since an FBP process can't wait on the first arrival at any input port, we bring all the inputs into one input port and tag them somehow to indicate what source they come from - so that responses can be sent to the appropriate destination. We handle the timer "tick" IPs the same way, as described in 2ed. p. 192.. So COLLATE_REQUEST_APPROVALS has 1 input port, multiple output ports.
The diagram is getting a bit complex - but most of the functions here IMHO are synchronous, so you need two 1-way connections for a lot of the linkages.
Why didn't we add two-way connections to FBP? a) we would like our users to think as asynchronously as possible, b) such connections don't take advantage of the built-in buffering, and c) frankly, in the area where FBP was used most heavily, we didn't need them!
Why didn't we add "wait on any input port"? because it turned out to have all sorts of weird wrinkles when we tried to implement it, and it just wasn't necessary!
Now, you will notice that all accesses to the database are sequential. Clearly this avoids database deadlock, but it might impact performance, depending on machine speed, transaction volume, etc. So how can we avoid this? One tried and true technique is to multiplex the Database Manager - that makes the diagram even more complex -and you may get clashes because multiple processes are accessing the same database, but there are ways of managing this (this is a known technology, totally independent of FBP). You can also use caches - again more complex diagram, but this takes advantage of what is sometimes called the 80/20 rule (20% of the people I know give me 80% of the trouble!).
I have shown the "Person" at both ends of the diagram - depending on which departments or humans are involved, and what interaction software they are using, you might want to close this loop.
OK so here's a preliminary picture - everyone (esp. Ged as I have probably played havoc with his nice design!) feel free to throw brickbats!
Best regards,
Paul
John Nilsson
Ged Byrne
It's late here, so I'll write up in full in the morning.
The main point is that your graph here is dealing with the user interaction and database management.
For Plip Plop the approach is different. The graph describes the long lived transaction only. It doesn't describe the user interactions.
The UI and persistence concerns are taken care of by the framework, as seen in Apache Isis.
Regards,
Ged
Ged Byrne
Paul Morrison
On Wednesday, April 15, 2015 at 4:41:04 PM UTC-4, John Nilsson wrote:
Why the arrows back to the approvals?
I was assuming that HR and Line Manager would be interested in knowing the decisions of the other players...
Regarding reading from the queues, do they have to block on an empty queue?
IMO this is fundamental - if a "station" or machine has nothing to work on its waits until some data arrives to be worked on. Otherwise what should it be working on?
I started thinking to day that FBP and Kanban has a few things in common (any experience from some synergy there?). In this view the bounded queues would be equivalent to the columns of a kanban board. The typical flow is FIFO, but it's not a strict requirement. And there is an order to which queues are scanned for things to pull, but you don't block on an empty queue, instead you look for another queue to pull from to keep things moving (e.g. swarming).
No, as I have said before, we tried that (one of the more celebrated FBP "failures"), and couldn't get it to work consistently. In fact, we couldn't get the rules for suspension to make sense, and you don't want to do polling! Why not route the different work items into a single input port?
So with that view in mind, instead of multiplexing IPs to a single port, how about just allowing the component to pull from any (connected) queue, how and when it pleases? (How would you f.ex. implement work stealing in an FBP network?)
Not sure about work stealing, but in real life I always find that one queue, multiple servers works best.
Regarding state: If we keep with the physical metaphor of kanban, and sending notes around kanban boards. The collate component would be the guy with the stapler, keeping pending requests, and approval notices on his desk while processing them. In one sense it makes sense to see this desk as the database, but the state is kept _on_ the notices, so I'm thinking that the better pattern would be for some Active Record implementation to get orthogonal persistence. The IP is not only the information of the requests, it's also the handle used to update this information, and persist it. Thus the database isn't connected to the component, it's connected to the IP and follows it around the network.
We may be saying the same thing... FBP supports the idea of IP trees, corresponding your idea of stapling IPs together. This allows the "IP tree" to be shipped around the network as a single object. This can then be converted into a substream, or the reverse, as desired. If you want to visualize this structure as a database, you're welcome! A more conventional approach IMO would be to convert a database record and all its attachments into a tree at read time and back again at write time, as you need to cache or persist it. However you may be right that it's probably not necessary!
Hope this makes sense! :-)
Regards,
Paul
Paul Morrison
Not sure about work stealing, but in real life I always find that one queue, multiple servers works best.

Tom Young
Tom
Young
47 MITCHELL ST.
STAMFORD, CT 06902
When
bad men combine, the good must associate; ...
-Edmund
Burke 'Thoughts on the cause of the present discontents' , 1770
Not sure about work stealing, but in real life I always find that one queue, multiple servers works best.I should have said: one queue, feeding a load balancer, feeding multiple instances of the server... In one case we reduced the elapsed time of a run from 2 hours to 20 minutes!
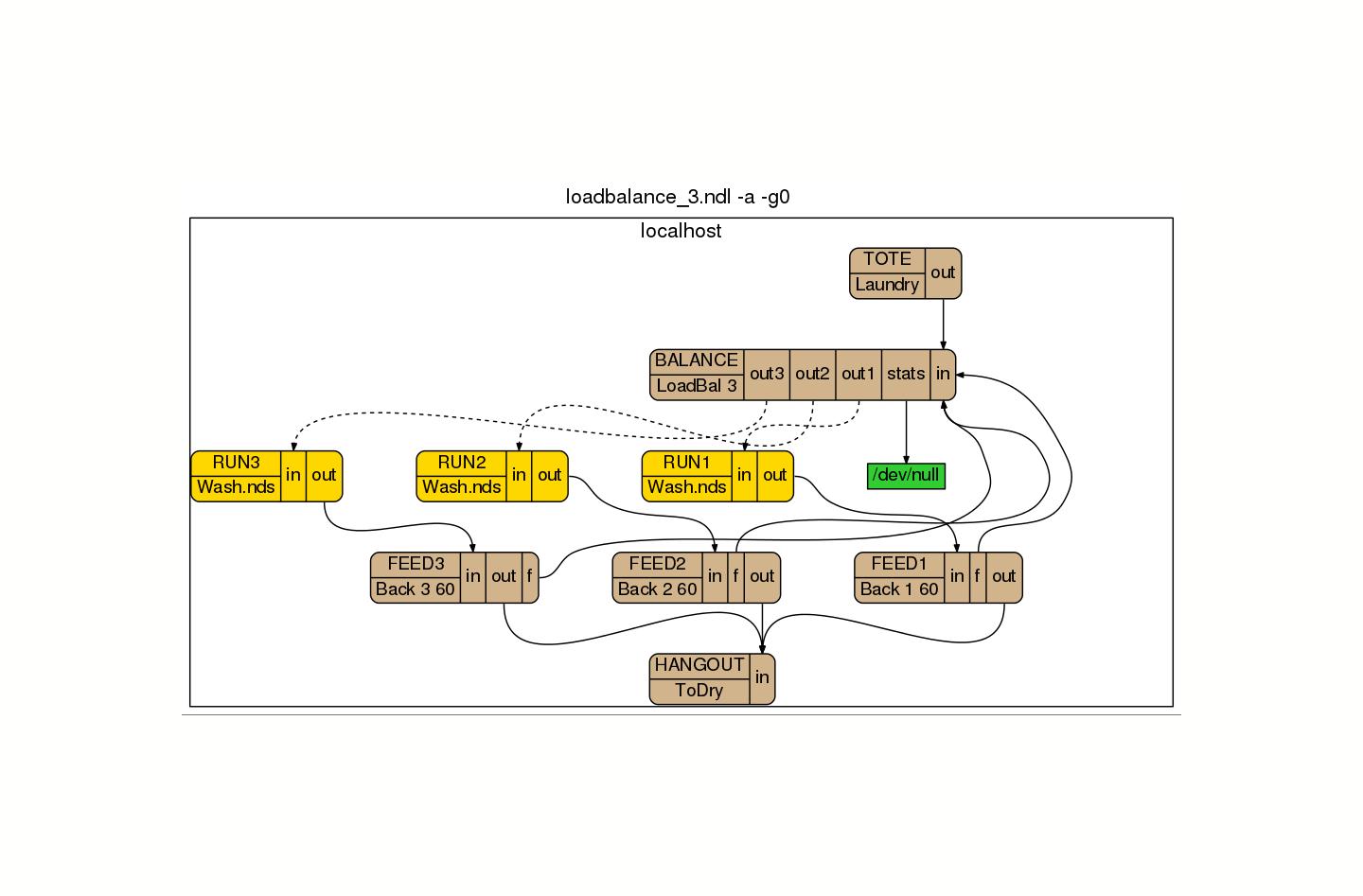{kind=link}
Paul Morrison
Pretty much the way I did it, except for a minor glitch - I think I admitted to this "crime" earlier, and Matt Lai very properly rapped me on the knuckles. You may have meant to show an array port, but array ports in FBP allow me to multiplex the RUNx component as much as I like. The load balancer's crime is that it peeks at the connections attached to the output port, and seeing which has the smallest backlog - it then sends the next incoming IP to that array port element. So there is one specialized service call, but, apart from that, the output connections are perfectly normal, and I don't need to feed back from the RUNx components back to the load balancer... And I don't use a different notation, unless you were just trying to attract the reader's attention!