Required/Inflection features and variants

Alexandre Arkhipov
Hello FLEx support and FLEx list,
I'm struggling with a project I've got from colleagues which makes use of inflection features, and the default parser.
(The project can be downloaded from here: https://yadi.sk/d/nG_rF6Vl3Jftpf (there's a tiny flag icon in the bottom-right to switch languages if it is not English, and the download link in top-right corner).)
1) I've got an affix, ēn "3.pl" which has a Required feature [ten:npst] (present-future tense). I created a verb stem testverb and am using Parser > Try a word on the word testverbēn. It doesn't parse when I mark the stem with Inflectional feature [ten:pst] (past tense) and parses ok when I mark it with [tns:npst], both of which are as expected. But the word also parses fine when no tense feature is present on the stem. Why?
2) There is also a homonymous clitic =en which is always allowed
by the parser; do I understand it correctly that there's no way to
impose any feature restrictions on clitics?
3) The colleagues originally set up a system of Variant types to
distinguish between what is actually stem names (allomorphs of the
stem which are conditioned grammatically, e.g. by tense
categories). The reason they didn't use Stem Names is that
Irregularly inflected forms under Variant types allow to append
the category names to the glosses, which Stem Names don't. Now,
for every Variant type (like Present, Perfect, Past etc.) they
introduced the corresponding tense feature values.
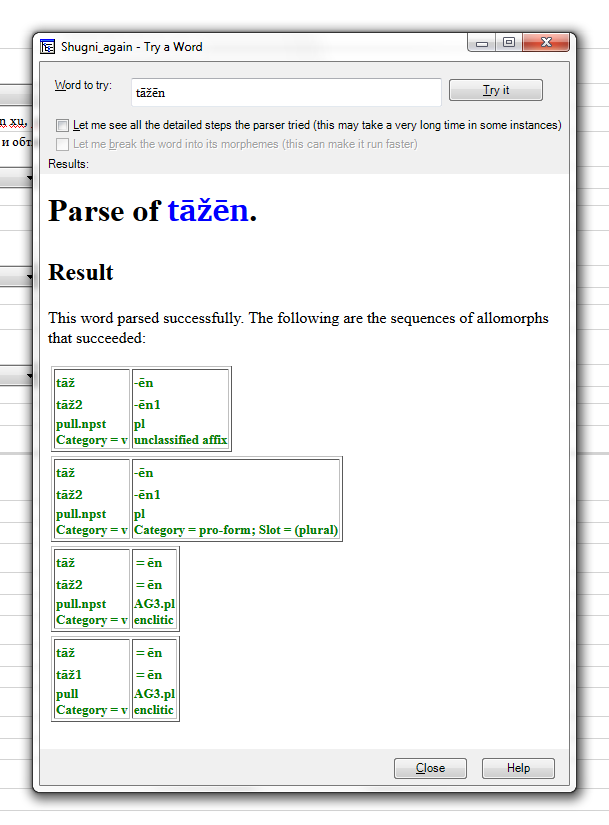
E.g., take the verb tāž(1) "pull". While the main entry
has no tense features, it has a homonymous Present variant tāž(2)
[ten:npst], a Perfect variant tīžǰ [ten:prf] and some
others. Again, tīžǰēn doesn't parse (except as
stem+clitic), while tāžēn parses twice: as the
Present variant (which is fine) and as the main entry (which I
thought isn't).
But the most strange thing happens if I specify the main entry tāž(1)
as having the feature [ten:pst] which should prevent tāžēn
to parse with tāž(1). Now neither tāž(1) nor tāž(2)
give correct parses, but instead there appear two spurious parses
of tāž(2), i.e. Present variant, with another homonymous ēn,
a nominal and pronominal plural marker -- which should (and is)
normally prevented by category matching. (See screenshot below).
tāž2-en
pull.npst-3.pl
tīžǰ=en
pull.prf=AG3.pl
and forbid the reverse (or at least the second of them):
*tāž2=en
pull.npst=AG3.pl
*tīžǰ-en
pull.prf-3.pl
?
Many thanks,
Alexandre

Andy Black
On number 2): you are correct that clitics cannot be constrained by inflection features.
Thanks for providing the data. I've been looking at it and would appreciate a full paradigm for the tāž(1) "pull" verb. Would that be possible?
I'm also wondering what the conditions are for when a word has one of the enclitics. In particular, I'm not understanding why the ēn in tīžǰēn needs to be analyzed as an enclitic instead of being analyzed as the suffix ēn "3.pl" since the enclitic and the suffix are homophonous and appear to have the same meaning.
Thanks,
--Andy
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
You can join this group by going to http://groups.google.com/group/flex-list.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+...@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/59ea6436-bfe3-bbf9-fc79-490c92376e11%40mail.ru.
For more options, visit https://groups.google.com/d/optout.
Alexandre Arkhipov
Dear Andy,
I'll ask them for a full paradigm. So far I just know the stems
that are linked to it as variants.
The tricky moment with clitics is that past tense forms take
agreement clitics which can appear on any other word, while
nonpast tense forms take agreement suffixes.
Maybe the simplest thing would be to always treat ēn on a
verb as a suffix, and only on other words as a clitic?
Best,
Alexandre
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/d2f3dfe9-e44d-30d9-8774-f90b84289da9%40sil.org.

maxwell
but I'll comment on a couple:
On 2017-05-30 15:02, 'Alexandre Arkhipov' via FLEx list wrote:
> 1) I've got an affix, *ēn* "3.pl" which has a Required feature
> *testverbēn*. It doesn't parse when I mark the stem with Inflectional
> [tns:npst], both of which are as expected. But the word also parses
> fine when no tense feature is present on the stem. Why?
Crab parser, I'm not sure about the default parser) checks for
DISagreement in feature values; rather than requiring that a stem bear
the features that an affix carries. That's intentional. Suppose a
language has inflectional affixes marking both singular and plural. You
want those affixes to all be able to attach to a stem; you wouldn't want
to have to list in your dictionary two identical stems, one bearing a
singular number feature to which the singular affix would attach, and
one bearing a plural number feature, to which the plural affix would
attach.
Of course there are situations where the stems to which the singular and
plural affix attach are different stems. In that case, which is usually
limited to a subset of the nouns in some language, you would use stem
names; more below on that. Alternatively, if the conditioning is
one-to-one grammatical, you could assign number features to each stem,
which would prevent the disagreeing affix from attaching. (There's also
the situation where the plural of a noun is simply irregular, like
'geese'--and that needs to be handled by a different mechanism, lest the
plural affix attach to the irregular word, like *geeses.)
Similar comments apply to other parts of speech.
> 3) The colleagues originally set up a system of Variant types to
> distinguish between what is actually stem names (allomorphs of the
> stem which are conditioned grammatically, e.g. by tense categories).
> The reason they didn't use Stem Names is that Irregularly inflected
> forms under Variant types allow to append the category names to the
> glosses, which Stem Names don't.
that way, e.g. you wouldn't normally gloss 'wives' as "wife.PL-PL".
Second, stem names need to allow for the situation where a named stem
does _not_ have any consistent grammatical meaning, i.e. where there is
NOT one-to-one grammatical conditioning. For example, in Spanish some
verbs have a so-called "hard" stem (ending in /ng/, rather than /n/)
that appears in two grammatical contexts: the first person present
indicative (tengo "I have"), and all persons of the present subjunctive
(tenga "I/you/he/she have (subjunctive)", tengamos "we have
(subjunctive)", etc.). There is no grammatical feature that is common
to all these forms, hence there can be no grammatical gloss for the
"hard" stem. (You could gloss it "hard", but that wouldn't tell you
anything besides the fact that there was a stem-final /g/, which you can
already see.)
BTW, these irregular stems often (not always) arise from phonological
processes--e.g. in the Spanish case, the /g/ of the hard stems appears
where the following vowel is non-front ('o' or 'a'), and it's missing
otherwise. Some linguists would call this a historical process that is
not active in the modern language (there are plenty of instances of /n/
before non-front vowels in Spanish), which is well modeled by the stem
names allomorph mechanism; other linguists would say that it is an
active process, with a lexically conditioned phonological rule (or a
rule conditioned by an exception feature). The latter analysis can be
modeled as well.
For those interested in the theory, there's a large literature on stem
names, also called stem spaces, or stem regions; see also morphomes (not
morphemes).
Mike Maxwell
University of Maryland
Alexandre Arkhipov
Dear Mike,
Thanks a lot for the comments.
Re 1): Ok, good to know that it's intentional. But I thought that was a difference between Inflection and Required features (Infl checking for disagreement vs. Req. literally requiring the specified feature to be present). What is the difference then?
Re 3):
>>Again, this is intentional. First, I think it's uncommon to gloss words
that way, e.g. you wouldn't normally gloss 'wives' as "wife.PL-PL".
It is not uncommon for all languages/families, e.g. it is quite common in our local tradition of glossing Caucasian languages. While looking a bit awkward in wives, it can be quite helpful when the stem alternation is the only marker of tense, taking further inflectional markers, possibly shared between tenses (e.g. pull.PRS-2SG vs. pull.PST-2SG).
>>Second, stem names need to allow for the situation where a named stem
does _not_ have any consistent grammatical meaning, i.e. where there is
NOT one-to-one grammatical conditioning.
Sure, but it would work equally fine with the same solution which is implemented for variants: just leave those "Append to gloss" field blank.
Best,
Alexandre
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
You can join this group by going to http://groups.google.com/group/flex-list.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+...@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/c51924081d109998ed13329f876e434b%40umiacs.umd.edu.
Andy Black
Dear Andy,
I'll ask them for a full paradigm. So far I just know the stems that are linked to it as variants.
The tricky moment with clitics is that past tense forms take agreement clitics which can appear on any other word, while nonpast tense forms take agreement suffixes.
Maybe the simplest thing would be to always treat ēn on a verb as a suffix, and only on other words as a clitic?
When showing just suffixes and enclitics (and sorting by glosses), it looks like the form of the person/number suffixes and the form of the agreement enclitics is the same with two exceptions:
So, then, it sounds like for the verbal suffixes, one gets
pst-at for 2sg past but npst-i for non-past (What
about perfect and past perfect? Do these also take the -i
form?) and
pst-i for 3sg past but npst-t for non-past (What
about perfect and past perfect? Do these also take the -t
form?)
If so, for the 2.sg suffix, you would create an allomorph for the
more restricted one (maybe the past form if the non-past form is
also used for perfect and past perfect). You also would set its
Required Features to be pst. The lexeme form would be the other
form and it would not have any Required Features. You see, this
is what Required Features are for: to distinguish between two
forms of the same morpheme.
You'd do something similar for 3.sg.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/b1617128-04af-50b0-e566-67ce3995ff61%40mail.ru.

Jeff Shrum
In a case like “wives” I think I would allomorphs for both the stem and the suffix for English. In a Nilo-Saharan languages where there were several classes of nouns that the stem changed in the plural and were not do to phonological processes, I used variants, irregular plural. In FLEx you can create tags for other irregular forms that make sense for the language being analyzed. Using irregular variants is often a good way to go when using the default parser.
Jeff Shrum
SIL International
Language Technology Consultant
Dallas, TX
USA
From: 'Alexandre Arkhipov' via FLEx list [mailto:flex...@googlegroups.com]
Sent: Wednesday, May 31, 2017 11:02 AM
To: flex...@googlegroups.com
Cc: flex_errors <flex_...@sil.org>
Subject: Re[2]: [FLEx] Required/Inflection features and variants
Dear Mike,
Thanks a lot for the comments.
Re 1): Ok, good to know that it's intentional. But I thought that was a difference between Inflection and Required features (Infl checking for disagreement vs. Req. literally requiring the specified feature to be present). What is the difference then?
Re 3):
>>Again, this is intentional. First, I think it's uncommon to gloss words
that way, e.g. you wouldn't normally gloss 'wives' as "wife.PL-PL".
It is not uncommon for all languages/families, e.g. it is quite common in our local tradition of glossing Caucasian languages. While looking a bit awkward in wives, it can be quite helpful when the stem alternation is the only marker of tense, taking further inflectional markers, possibly shared between tenses (e.g. pull.PRS-2SG vs. pull.PST-2SG).
>>Second, stem names need to allow for the situation where a named stem
does _not_ have any consistent grammatical meaning, i.e. where there is
NOT one-to-one grammatical conditioning.
Sure, but it would work equally fine with the same solution which is implemented for variants: just leave those "Append to gloss" field blank.
Best,
Alexandre
среда, 31 мая 2017г., 16:55 +02:00 от maxwell max...@umiacs.umd.edu:
Andy will be able to answer most of your questions better than I can,
but I'll comment on a couple:
On 2017-05-30 15:02, 'Alexandre Arkhipov' via FLEx list wrote:
> 1) I've got an affix, *ēn* "3.pl" which has a Required feature
> [ten:npst] (present-future tense). I created a verb stem
> *testverb***and am using Parser > Try a word on the word
> *testverbēn*. It doesn't parse when I mark the stem with Inflectional
> feature [ten:pst] (past tense) and parses ok when I mark it with
> [tns:npst], both of which are as expected. But the word also parses
> fine when no tense feature is present on the stem. Why?
The morphology model that underlies the parsers (at least the Hermit
Crab parser, I'm not sure about the default parser) checks for
DISagreement in feature values; rather than requiring that a stem bear
the features that an affix carries. That's intentional. Suppose a
language has inflectional affixes marking both singular and plural. You
want those affixes to all be able to attach to a stem; you wouldn't want
to have to list in your dictionary two identical stems, one bearing a
singular number feature to which the singular affix would attach, and
one bearing a plural number feature, to which the plural affix would
attach.
Of course there are situations where the stems to which the singular and
plural affix attach are different stems. In that case, which is usually
limited to a subset of the nouns in some language, you would use stem
names; more below on that. Alternatively, if the conditioning is
one-to-one grammatical, you could assign number features to each stem,
which would prevent the disagreeing affix from attaching. (There's also
the situation where the plural of a noun is simply irregular, like
'geese'--and that needs to be handled by a different mechanism, lest the
plural affix attach to the irregular word, like *geeses.)
Similar comments apply to other parts of speech.
> 3) The colleagues originally set up a system of Variant types to
> distinguish between what is actually stem names (allomorphs of the
> stem which are conditioned grammatically, e.g. by tense categories).
> The reason they didn't use Stem Names is that Irregularly inflected
> forms under Variant types allow to append the category names to the
> glosses, which Stem Names don't.
Again, this is intentional. First, I think it's uncommon to gloss words
that way, e.g. you wouldn't normally gloss 'wives' as "wife.PL-PL".
Second, stem names need to allow for the situation where a named stem
does _not_ have any consistent grammatical meaning, i.e. where there is
NOT one-to-one grammatical conditioning. For example, in Spanish some
verbs have a so-called "hard" stem (ending in /ng/, rather than /n/)
that appears in two grammatical contexts: the first person present
indicative (tengo "I have"), and all persons of the present subjunctive
(tenga "I/you/he/she have (subjunctive)", tengamos "we have
(subjunctive)", etc.). There is no grammatical feature that is common
to all these forms, hence there can be no grammatical gloss for the
"hard" stem. (You could gloss it "hard", but that wouldn't tell you
anything besides the fact that there was a stem-final /g/, which you can
already see.)
BTW, these irregular stems often (not always) arise from phonological
processes--e.g. in the Spanish case, the /g/ of the hard stems appears
where the following vowel is non-front ('o' or 'a'), and it's missing
otherwise. Some linguists would call this a historical process that is
not active in the modern language (there are plenty of instances of /n/
before non-front vowels in Spanish), which is well modeled by the stem
names allomorph mechanism; other linguists would say that it is an
active process, with a lexically conditioned phonological rule (or a
rule conditioned by an exception feature). The latter analysis can be
modeled as well.
For those interested in the theory, there's a large literature on stem
names, also called stem spaces, or stem regions; see also morphomes (not
morphemes).
Mike Maxwell
University of Maryland
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
You can join this group by going to http://groups.google.com/group/flex-list.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+...@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/c51924081d109998ed13329f876e434b%40umiacs.umd.edu.
For more options, visit https://groups.google.com/d/optout.
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
You can join this group by going to http://groups.google.com/group/flex-list.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+...@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/1496246538.431576142%40f65.i.mail.ru.
Alexandre Arkhipov
Dear Andy,
Thanks a lot, and here's the paradigm:
https://docs.google.com/document/d/1AbQCKYnSPnzRh3rnaY1Mqx-KbMVHlEaSLBTugCPT48I/edit
Indeed, there are the two -i markers that you noticed, and also
two -at markers, one of them a past tense used on perfect stems,
and the other a 2sg clitic.
The split is rather between present-future (nonpast) and all the
other stems. So the npst will probably be a better choice as the
more restricted one.
Best,
Sasha
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/f4169b80-dbfe-491d-05cd-98fe89951deb%40sil.org.
Andy Black
Dear Andy,
Thanks a lot, and here's the paradigm:
https://docs.google.com/document/d/1AbQCKYnSPnzRh3rnaY1Mqx-KbMVHlEaSLBTugCPT48I/edit
Would it be possible to get a paradigm where all forms are fully spelled out? Something like
pull.npst
tāžum 1sg
tāži 2sg
tōžd 3sg
tāžām 1pl
tāžēt 2pl
tāžēn 3pl
pull.pst
tīždum 1sg
tīždat 2sg
tīždi 3sg (if it were intransitive, it would just be tīžd???)
tīždām 1pl
tīždēt 2pl
tīždēn 3pl
pull.prf
tīžǰum 1sg
tīžǰat 2sg
tīžǰi 3sg (if it were intransitive, it would just be tīžǰ???)
tīžǰām 1pl
tīžǰēt 2pl
tīžǰēn 3pl
pull.pprf
???
Overt, surface forms for the infinitive, prf.ptcp, adj.ptcp, fut.ptcp, and 'doer'.
Also, do all verbs have an additional d in the pst and an additional ǰ in the perf or just the 'pull' verb?
Thamks,
--Andy
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/b2420eb8-6de3-1163-237f-e0f2fcefec11%40mail.ru.
Alexandre Arkhipov
Dear Andy,
A completed paradigm is under the same link:
https://docs.google.com/document/d/1AbQCKYnSPnzRh3rnaY1Mqx-KbMVHlEaSLBTugCPT48I/edit
Best,
Sasha
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/c473cb9a-a91b-e21d-b0a8-8b4a958504e7%40sil.org.
Andy Black
Dear Andy,
A completed paradigm is under the same link:
https://docs.google.com/document/d/1AbQCKYnSPnzRh3rnaY1Mqx-KbMVHlEaSLBTugCPT48I/edit
Take a look at what is in the following back-up file. You may want to restore it using a new project name so it doesn't change what you have and so you can explore the approach it takes. See https://drive.google.com/file/d/0BxzG868ube1cSXJjNFptZFFPblU/view?usp=sharing.
This approach uses tense verb slots and stem names (probably very much what Mike Maxwell was thinking). There are no variants (but if you need them for a dictionary, you certainly can add them; I'd suggest you decide on a fully inflected form to use as a citation form of it). For those subject suffixes which have different shapes depending on the tense, it uses allomorphs and required features.
The infinitive and participles use affix templates which require further derivation. These, too, use a tense slot.
I hope you find this helpful.
--Andy
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/dee33328-6253-49e1-cd4f-98bd3c2a0147%40mail.ru.
Alexandre Arkhipov
Dear Andy,
Thank you very very much! I'll share it with colleagues right
away and also will keep for my own future reference.
Best,
Sasha
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/afa78ffd-39f5-bd90-d248-4b5e08644eaf%40sil.org.
maxwell
> Re 1): Ok, good to know that it's intentional. But I thought that was
> a difference between Inflection and Required features (Infl checking
> for disagreement vs. Req. literally requiring the specified feature to
> be present). What is the difference then?
> [Me:]
> words
> that way, e.g. you wouldn't normally gloss 'wives' as "wife.PL-PL".
> It is not uncommon for all languages/families, e.g. it is quite common
> in our local tradition of glossing Caucasian languages. While looking
> a bit awkward in wives, it can be quite helpful when the stem
> alternation is the only marker of tense, taking further inflectional
> markers, possibly shared between tenses (e.g. pull.PRS-2SG vs.
> pull.PST-2SG).
between Inflectional features. The only situation where this comes up
(where agreement within a word matters) is multiple exponence, i.e.
where there are two (or more) morphemes in a single word marked for the
same inflectional feature.
Required features is, as you say, used for a different purpose: to
require a feature to already be present when an affix attaches.
Normally this is a different feature, i.e. there's no reason to use the
Required Features to check feature agreement, since that will already be
checked by the inflectional features. The Required Features would come
up when one the allowed values of one feature are dependent on a
different feature. For example, in Spanish [Mood subjunctive] requires
[Tense present] or [Tense preterite], it's incompatible with [Tense
future].
As for wife.PL-PL, vs. Caucasian languages, I don't know any of those
languages, so it's quite possible there's a situation where you'd want
s.t. like that. But I was specifically referring to the situation where
the *same* feature (value) was glossed on both the stem and the suffix
([Number plural] in this example). The examples you give of
pull.PRS-2SG and pull.PST-2SG are different features on stem and suffix,
are found in lots of languages, and are as you say completely legitimate
to gloss that way. (The Leipzig Glossing Rules don't specifically
address the situation of 'wives', although their rules for "Inherent
categories" and "Bipartite elements" address related questions.)
maxwell
APOLOGIES, I just realized I was responding to an email that's almost
exactly a year old... rather than one that just came out today :-).
Mike Maxwell
Alexandre Arkhipov
Mike,
But still thanks a lot! :)
Best,
Sasha
--
Отправлено из Mail.Ru для Android
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
You can join this group by going to http://groups.google.com/group/flex-list.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+...@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/fe880bbed0889e34a4fcafe1d27e07b9%40umiacs.umd.edu.