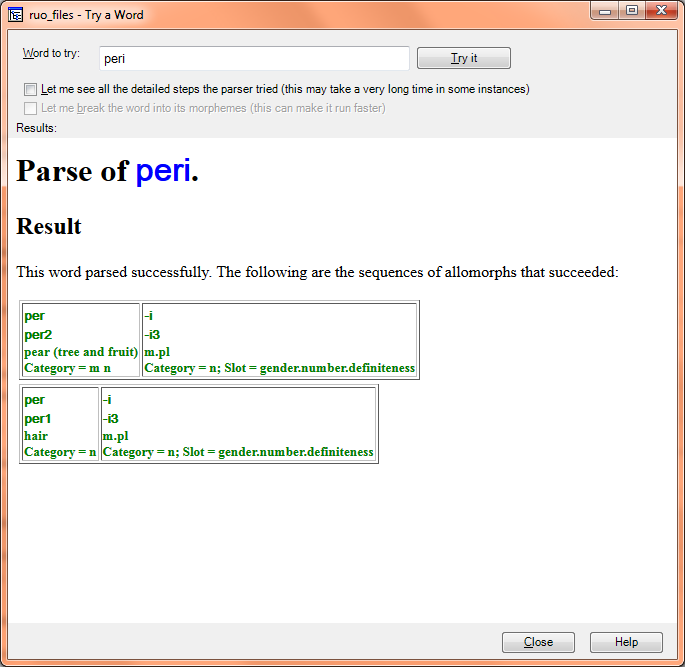
Are there 2 different parsing engines?

Zach Wellstood

Kevin Warfel
Hi Zach,
There are two different parsers, yes, but that is not the source of what you are experiencing. You can choose the parser you want to use by going to Parser, Choose Parser.
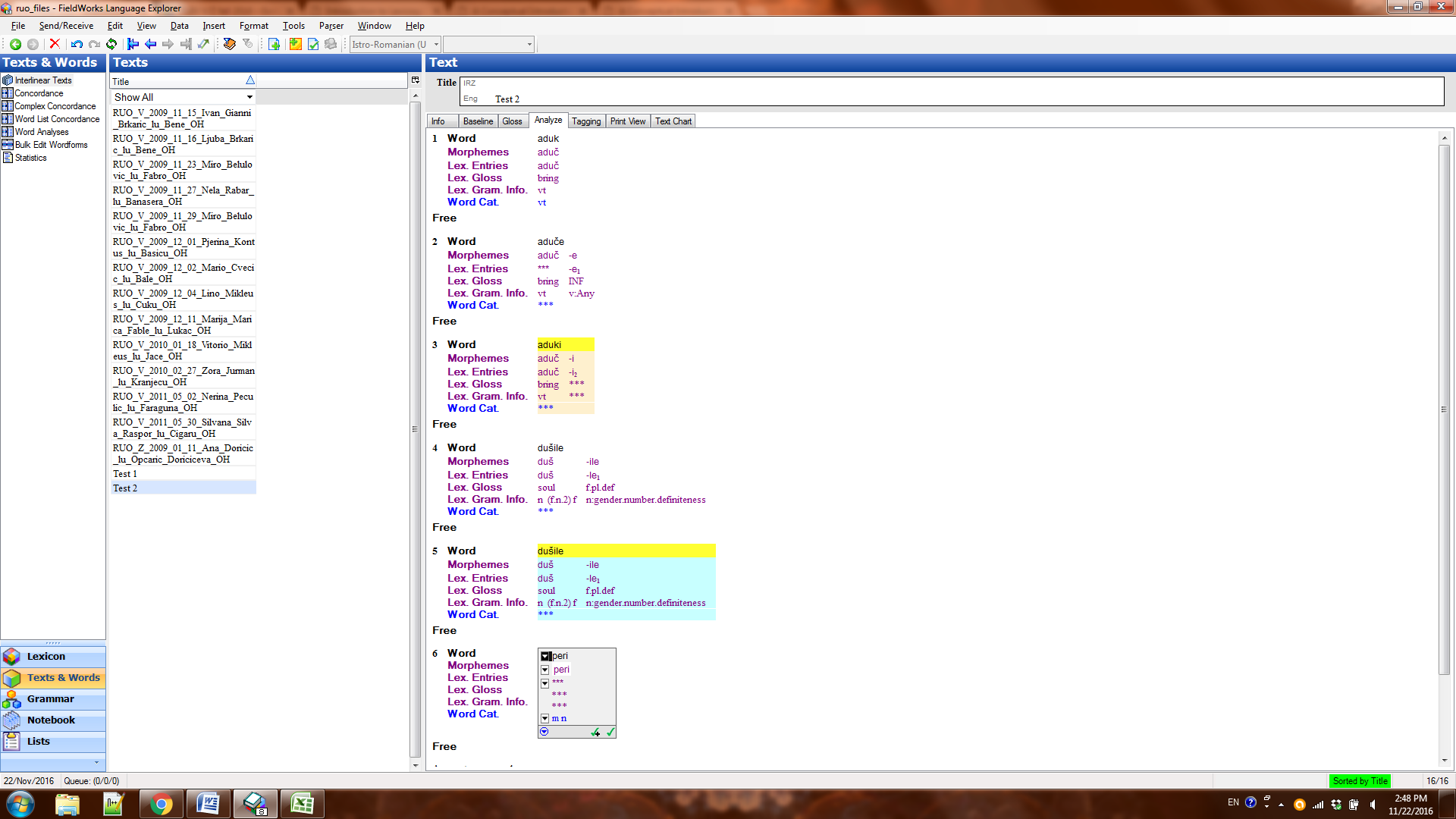
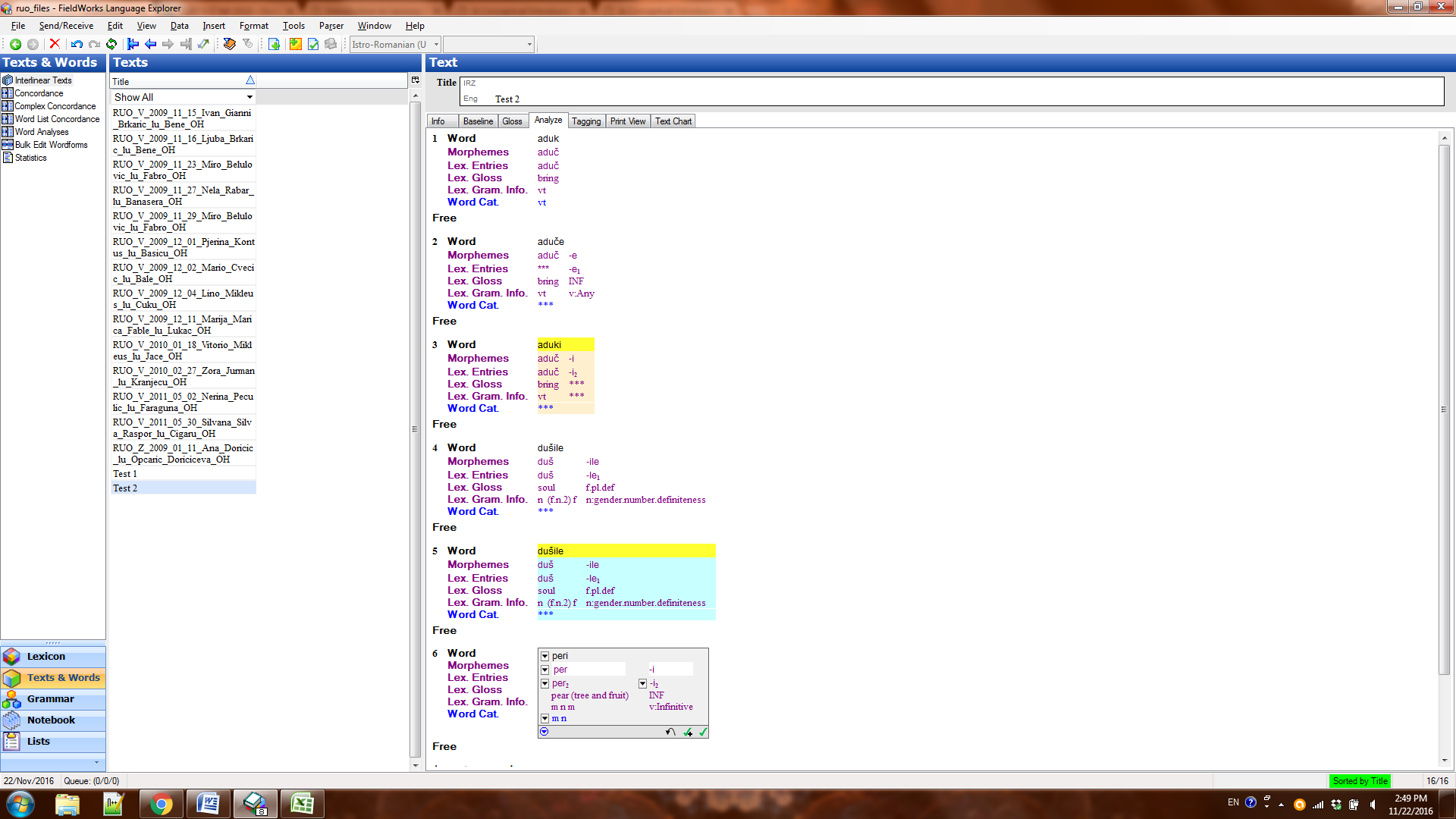
What you’re seeing happening in the data in the Analyze tab is a result of FLEx giving you information from the lexicon, without any parser smarts applied to it. It will only show you entire morphemes that match your word, or if you break it up manually, it will give you all matches to those pieces, without any application of logic as to what can or cannot co-occur with what else.
To get the parser to operate on the word in the Analyze tab, highlight the word and then go to Parser, Parse Current Word or to Parser, Parse Words in Text (if you want to do all the words in the whole text—which could take a while if parsing is complex in your language). I think Parser, Parse Current Word will give you the same results as in Try A Word, but it will add information to the data in Word Analyses, which the use of Try A Word does not.
Others who know more about this area of FLEx can correct me if I’ve misrepresented anything.
Blessings,
Kevin
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+...@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/CAMvzDNJ-a4-DnobwVGGPobjU_FQf6kTd04Pj-DFbFV2MrRMgMw%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
Zach Wellstood

To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+unsubscribe@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/CAMvzDNJ-a4-DnobwVGGPobjU_FQf6kTd04Pj-DFbFV2MrRMgMw%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You are subscribed to the publicly accessible group "FLEx list".
Only members can post but anyone can view messages on the website.
To change your status, please write to flex_d...@sil.org.
---
You received this message because you are subscribed to the Google Groups "FLEx list" group.
To unsubscribe from this group and stop receiving emails from it, send an email to flex-list+unsubscribe@googlegroups.com.
To post to this group, send email to flex...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/flex-list/9505df3ef51002fb0420534cc631a610%40mail.gmail.com.