Let's kick this up a notch! (video/images wanted)
71 views
Skip to first unread message

Jon Watte
Apr 27, 2017, 9:52:03 PM4/27/17
to diyrovers
Robogames is over! I placed third out of twelve in Mech Warfare with Onyx X :-)
To do that, I need as much pictures, video footage, and ideally, on-board video footage from rovers driving. Especially from the Sparkfun competition. Especially from last year. But anything is welcome!
I know some of you have posted good video before, but trawling through the archives, it's hard to find where those links / media are.
I'll collect whatever links and files you can send me, and I'll put them all in a single place where we call all reference them. (I have approximately unlimited web hosting capabilities if needed, too.)
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Now, if you could also kindly paint an overlay each frame of each video with a clear semantic segmentation of "hay bale," "spectator," "other car," "drivable ground" "non-drivable ground," "ramp" and so forth, that'd be super helpful. :-)
(No, I don't /actually/ expect you to do this; that's going to be the major effort I'll have to undertake. If you share video, I will share results!)
(No, I don't /actually/ expect you to do this; that's going to be the major effort I'll have to undertake. If you share video, I will share results!)
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson

Ted Meyers
Apr 30, 2017, 2:51:58 PM4/30/17
to diyrovers
Good luck Jon. I expect that most any video still around is on youtube already. I tend not to put any on-board camera on the bot during the race, because it is just one more thing to go wrong.
Sounds like you are going to try a machine learning algorithm? I've decided to try a CV solution, but not ML; ML is just too hard to train, given the limited time on the track, and difficult in reproducing/simulating a track for testing. Not that CV couldn't benefit from realistic track testing, but I figure that I can do more to control the algorithm, if hand-coded.
I do believe that some sort of obstacle avoidance will be very important this year, if one can believe the little info that SF has put out; we should know a lot more tomorrow(?) I think that the most difficult obstacles may still be other vehicles and people on the track. And both of those have the added difficulty in that they are moving!
Congrats on the success in Robogames! Did you compete in the Robomagellan this year? Did they hold the event this year?
Ted
Jon Watte
Apr 30, 2017, 3:49:06 PM4/30/17
to diyrovers
Yes, I'm looking into some machine learning based vision.
If that doesn't pan out, I already have some "color blobs" type manual code used for Magellan last year (where I failed because of mechanical issues, like climbing a chainlink fence...)
I did not do Magellan this year, because I really wanted to do Mech Warfare, and with no work on any of the bots in January, I had to pick one or the other.
Now that the Onyx 'mech is in reasonable shape, it's possible I'll do both next year. Meanwhile, I'm lookin at AVC as a possible next destination, which means kicking Money Pit into gear again.
But really, it's just an excuse to play with toys :-)
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
--
You received this message because you are subscribed to the Google Groups "diyrovers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to diyrovers+unsubscribe@googlegroups.com.
To post to this group, send email to diyr...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/diyrovers/bad8ee4c-d0d2-418d-ae97-91210886fc31%40googlegroups.com.
Jon Watte
May 1, 2017, 1:03:40 AM5/1/17
to diyrovers
So, here's my workflow so far:
1) process the video files with scripts that rip out
a) every keyframe
b) a frame every two seconds
into PNG files.
2) open it all up in Photoshop and label it with "go," "no go," "ignore" and "interest"
(I'm using "interest" for other rovers, and for the hoop/ramp)
This is going to be a LOT of work...
I started out labeling about 20 things (spectators, curbs, fence, buildings, trees, ...) but I don't really need those.
I just need to know where to drive, and when bad or interesting things are close.
It took a couple of false starts to settle on this workflow, but now I'm getting reasonably efficient -- perahaps 10 labeled frames per hour.
Examples:
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
On Sun, Apr 30, 2017 at 11:51 AM, Ted Meyers <ted.m...@gmail.com> wrote:
--
Jon Watte
May 3, 2017, 12:50:51 AM5/3/17
to diyrovers
So far, I've annotated 46 pictures. I figure if I do 20 per evening, I'll eventually get through them, without dying from boredom.
Where's an un-paid intern when you need one? ;-)
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Ted Meyers
May 3, 2017, 1:27:39 PM5/3/17
to diyr...@googlegroups.com
You need to use the Amazon "Mechanical Turk". Where you pay random people (mostly in India I think) a few cents to manually process digital data.
To view this discussion on the web visit https://groups.google.com/d/msgid/diyrovers/CAJgyHGOxhqDZ73OE6OU5Xv-2wPyQUSSERrzA9zRVDu3N01G3qw%40mail.gmail.com.
Jon Watte
May 3, 2017, 3:41:39 PM5/3/17
to diyrovers
You need to use the Amazon "Mechanical Turk". Where you pay random people (mostly in India I think) a few cents to manually process digital data.
I have considered Turking, but the problem is that random people probably aren't great at figuring out "where could a rover drive" versus "where could it not drive."
Not to mention that most Turks don't have Photoshop, and I know of no other good tool for annotating images with class colors, using magnetic slelection and so forth.
I bet if I did this for a living, the investment in easy-to-use web-based tools to go Turk for classification would totally be worth it, though!
(And if I were Google, I'd just turn it into a CAPTCHA and get it solved for free :-)
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
To view this discussion on the web visit https://groups.google.com/d/msgid/diyrovers/CADnZWKMXsaPzsmT7%2Bq9if6qGG_K14YBD0uKP6dvfRwUgoiwOJw%40mail.gmail.com.
Jon Watte
May 7, 2017, 3:05:41 AM5/7/17
to diyrovers
Some interesting news on my project to apply machine vision to the subject of autonomous rover racing.
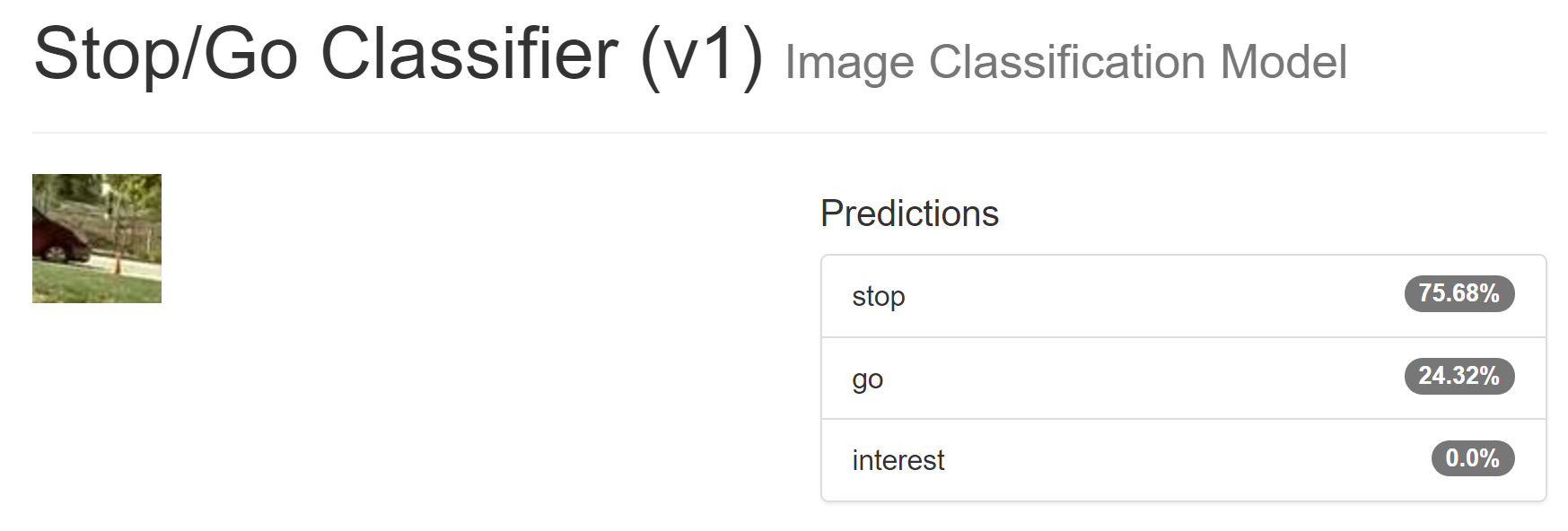
I've been renting GPU processing power on the GPU processing power spot market (yes, there is such a thing) and training neural networks.
I've used some of the videos that jesse helpfully provided from onboard his rovers during AVC 2015/2016, painstakingly painting red/green "stop/go" areas in each frame across some selected snippets.
Then, I've cut little sub-sections of each frame out randomly, where the center spot is either "stop" or "go," and formulated and trained a Deep Learning Fully Convolutional network on those pictures. (I had about 500 pictures when I was done)
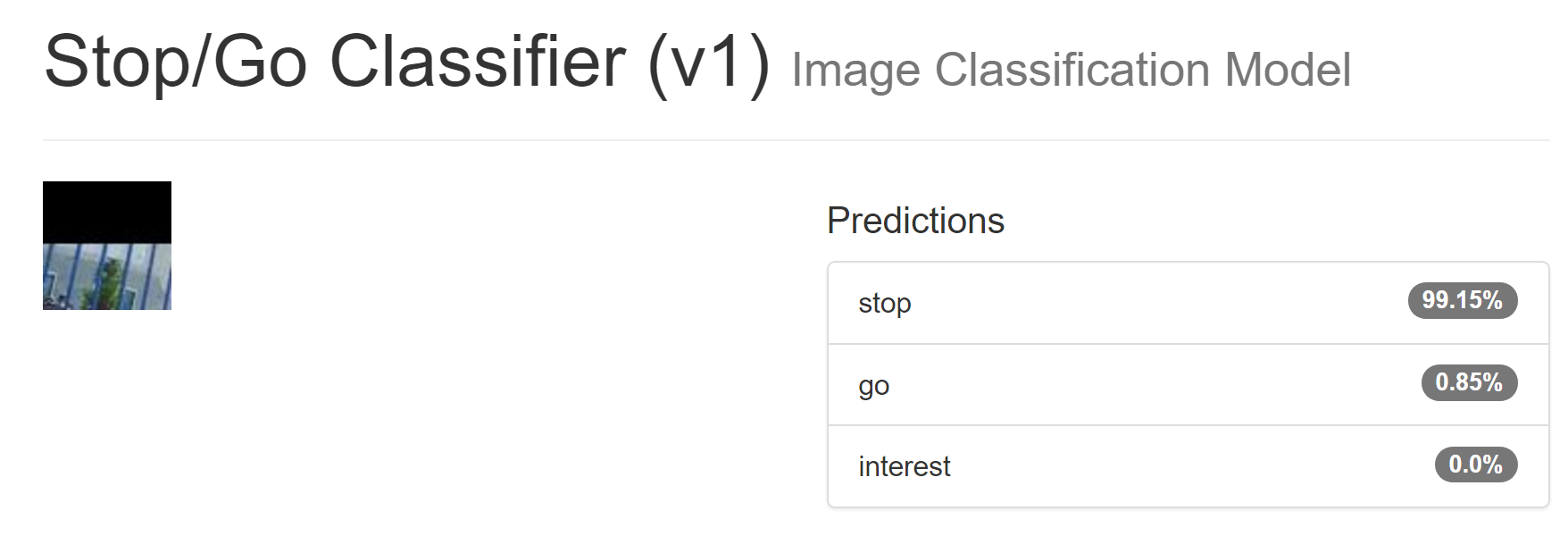
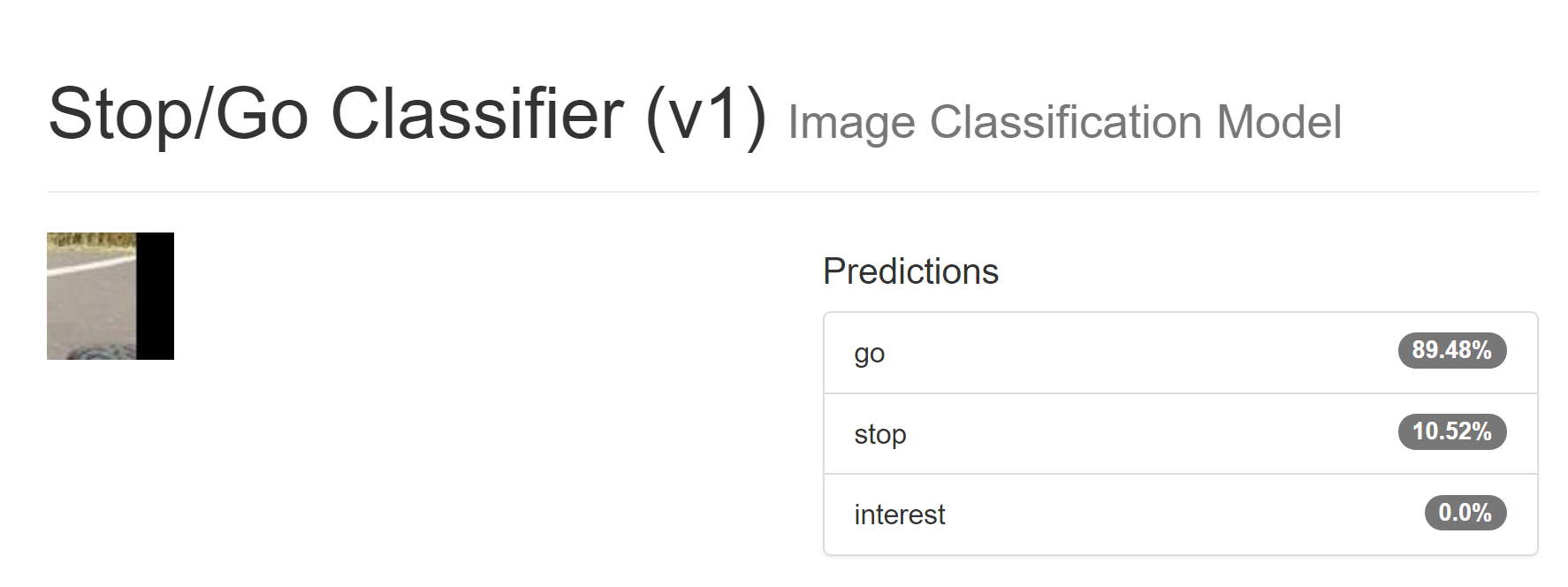
Here are random examples of "stop" and "go" from this training set:
The randomly-selected "stop" is probably cropped from the top of some picture, and the blue lines is likely a fence.
The randomly-selected "go" is probably cropped from the right of a picture, and we can see the track and a bit of a wheel in it.
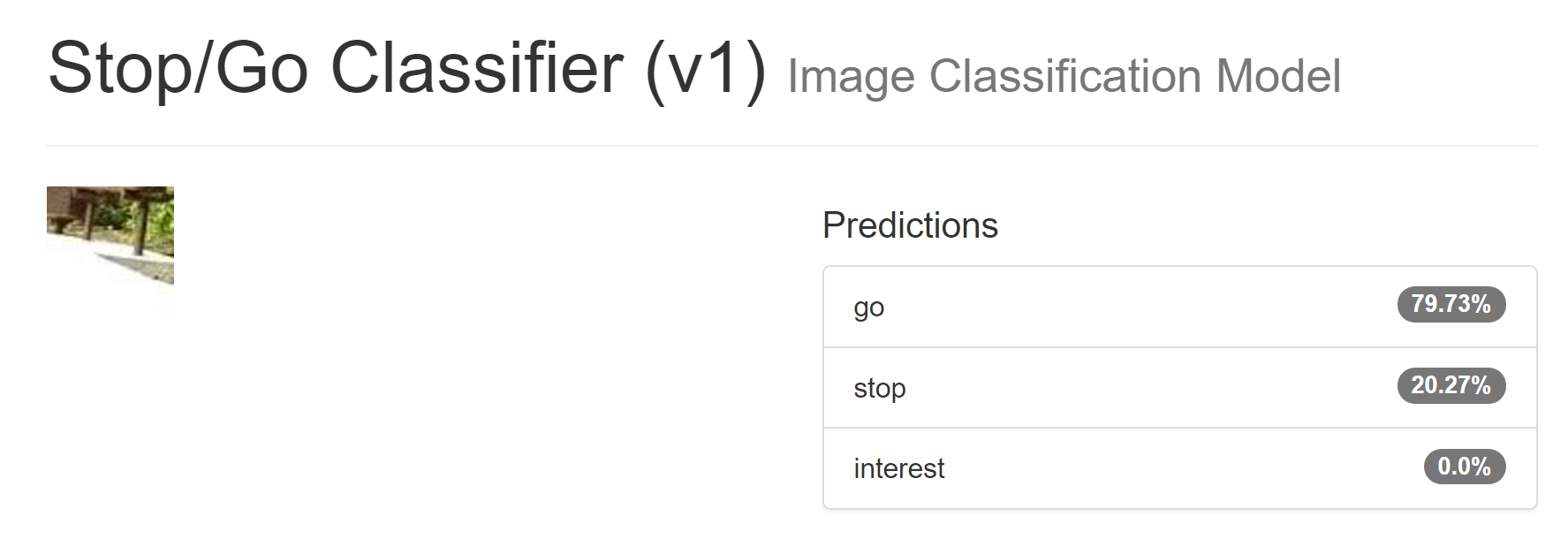
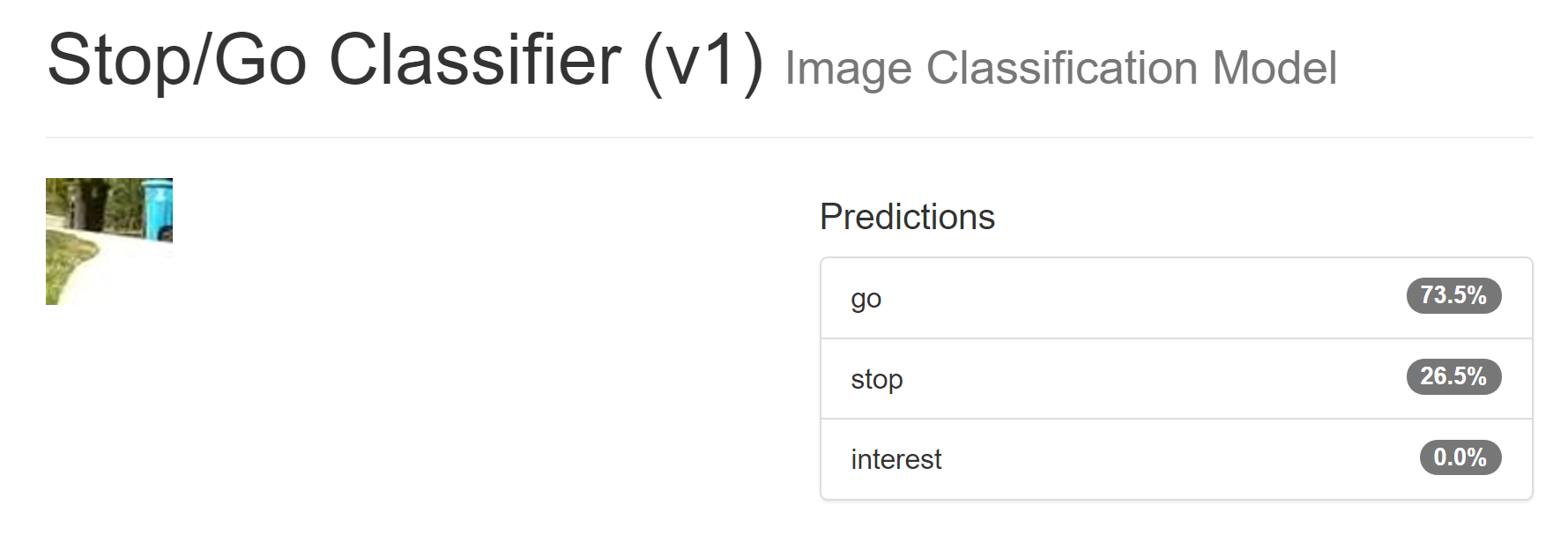
Then I took some footage from Money Pit 3 in 2015, when I was just driving around a local park. What's interesting is that this park has brighter pavement than the AVC track, and it also faces a road where cars are parked, which is different form haybales on the side.
I picked three random pictures, two "go" ones and a "stop" one (note: the model classifies the CENTER of the image, not the near field of the image.) Here are the results, on totally brand new images the models' never seen before, taken with different cameras, etc:
It should go on those paths, but should probably stop for those cars.
This feels amaaaaaziiing!
(...until such time that I find out something like that it actually thought anything with white along the bottom is OK, and anything with green along the bottom is not OK, at which point I'm sad and need to apply the Knobbly Stick of Network Enlightenment to it)
The next step is to turn these 64x64 snippets into a wider convolutional network that classifies pixels in a full video frame -- this is known as semantic segmentation. The cool thing is that I can basically take the model that I have, and run it across sections of the video frame, sliding it over a little bit each time, and then color the center of the image window with whatever stop/go the model tells me it should be.
Then I should have a "map" of what's okay or not in front of the camera out to the horizon.
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Jon Watte
May 7, 2017, 7:46:36 PM5/7/17
to diyrovers
This particular image (of a haybale, right at the right edge of a frame) is somehow not getting solved as "please don't ram the haybales."
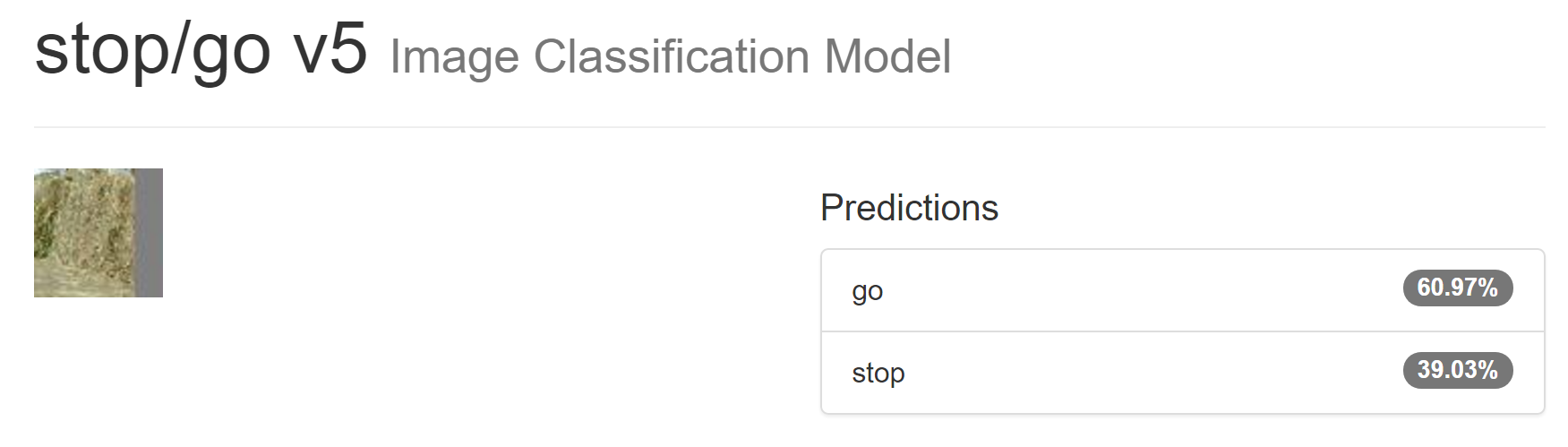
My theory is that it's too close to grass, which is a totally fine driving surface (I'm adding images from Robomagellan to the training set)
Also, I'm wondering whether I should use narrower, taller strips. A 32 wide 128 tall would be the same size (and thus same processing cost) but would give more information about whatever happens to be overhainging the area of interest.
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Jon Watte
May 8, 2017, 1:58:55 AM5/8/17
to diyrovers
The answer is: Yes! With 32 wide 128 tall strips randomly taken from a set of 320x240 video image, I can make a > 97% accurate stop/go decision about the "lower center" of that image.
And the "go" that should be "stop" are clearly ambiguous, such that there's actually some room to move forward; hopefully the next image (closer to the obstacle) would then say "stop" at some point.
I'm going to keep labeling images (this is the most tedious and time-consuming part of the job) and build an even bigger data set, see if I can get > 99%.
It's using about 4.5 million learned parameters, but the Jetson TX2 has 8 GB of RAM and can process over a trillion floats per second, so that's actually not a big deal in this day and age. I love living in the future!
(By comparison, the high-performing image classification competition networks use at least 10x as many parameters. So I'm not shooting mosquitoes with a cannon; perhaps with a .50 cal though :-)
It looks like there will be GPU power left over for "object detection" separate from the segmentation, so I can hopefully add code to detect things like "start marker" and "ramp" and "hoop" and "pedestrian" and "barrels" -- if I can only get enough reference images in time ...
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Ted Meyers
May 8, 2017, 11:31:37 AM5/8/17
to diyr...@googlegroups.com
Wow, sounds like you are making some progress. I have to ask though, how is this any different than just using color as a classifier -- mostly asphalt gray == GO, otherwise STOP. That seems to be the obvious takeaway from the examples given so far.
To view this discussion on the web visit https://groups.google.com/d/msgid/diyrovers/CAJgyHGMKuWKdLX%2BgiaXng5XSxWUhpcY%3Dp%3D2%2BGt7E400_SUfq1Q%40mail.gmail.com.
Jon Watte
May 8, 2017, 2:10:34 PM5/8/17
to diyrovers
how is this any different than just using color as a classifier -- mostly asphalt gray == GO, otherwise STOP
Good question!
I'm doing this for both AVC and Robomagellan.
Some walls are gray, but vertical. I also like drawing on lawns (horizontal grass) but stop for haybales (vertical grass) and bushes.
I also want to drive on dirt, and mulch, and hay on the track (as opposed to hay that's bunched up!)
I'll write up more of a progress report with some more example input images and labels tonight.
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
To view this discussion on the web visit https://groups.google.com/d/msgid/diyrovers/CADnZWKOS%2BvsCfC0WVfFZqjtc0pRAj_jgRLR5LyZXSooVXu9E3A%40mail.gmail.com.
Jon Watte
May 9, 2017, 12:25:24 PM5/9/17
to diyrovers
I promised a better explanation of why machine learning might be better than color blob detection.
It ended up as a blog post:
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Jon Watte
May 14, 2017, 5:11:43 PM5/14/17
to diyrovers
Did I post this? I probably didn't post this.

Both the hoop and the ramp are "interesting."
I find those pretty hard to separate because the ramp is kind-of flattish on the ground in a grayish blue, and the hoop is darkish green against a bright background, thus tends towards black.
Anyway, thinking about what went wrong with Money Pit last Robogames, the one mechanical problem was that the AX-12A servos used for steering were overloaded in the thick grass.
I can either add stronger servos ( http://support.robotis.com/en/product/actuator/dynamixel_x/xm_series/xm430-w350.htm at 4.3 kgcm ) or I can do software fixes by trying to wiggle the wheels back/forward when turning, or I can add a third pair of wheels in the center, and balance the springs to give them more of the load than the front/back wheel pairs.
Those wheels don't need to turn, either; they might not even need to be driven (but doing so will be helpful, especially if I also get encoders from that third pair just like the first two.)
Am I up for machining even more suspension parts? Perhaps. We'll see. The XM430 servo price point is a pretty big incentive to find another solution :-)
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
Ted Meyers
May 14, 2017, 11:18:45 PM5/14/17
to diyrovers
Well, that is going to be an interesting mess with the hoop and the ramp in view at the same time -- yeah, just drive straight through the hoop pipe and to the ramp -- oops. I might just decide to avoid them both. Consistency is worth a lot in this event.
I also noticed that the green (go) area is surrounded by red (stop). Hmm...
For your servo needs, Servo City carries some beefed up servos; I imagine the trick will be getting something that is strong enough and also fits.

wholder
May 15, 2017, 1:32:01 PM5/15/17
to diyrovers
I met a guy at a San Diego robotics meet up that had an interesting approach to using a neural network to drive his car. He used the Unity game engine to generate a video of an endless road with random tuns and other features and then captured the video frames and computed steering angle to a file. He then used Amazon's compute cloud to train the net using just the images and steering angle. After this, he transferred the trained network into his 1/10th scale car where it runs on a Raspberry Pi and a Pi Camera. I think he used an Adafruit servo board to drive the steering servo. He took his car up to a recent autonomous car competition somewhere in the Bay Area (don't remember the name of the competition.) I saw video of his car running on the track there and it was quite impressive.
I don't know much about neural nets, but I had always imagined that some type of preprocessing step was needed on the images, but he just trained the net with raw, RBG images. He did have to scale down the video resolution quite a bit (I think it was something like QVGA, perhaps QQVGA) to make it run on the Pi, though, I queried him quite a bit on his approach and, in general, he seemed to suggest that he thinks it works best if the training images are more abstract than real, as he doesn't want the network keying in on superfluous details. In fact, the training images he showed me were quite different from what I imagine the car would see on the track where he ran it.
I'll see if I can convince him to perhaps join the group here and explain his approach in more detail, as I think his approach is quite interesting. I believe he's interested in trying his approach on a full size car and is looking to team up with other individuals. At least, that's what he said at the time we spoke.
Wayne
Jon Watte
May 15, 2017, 2:37:31 PM5/15/17
to diyrovers
For your servo needs, Servo City carries some beefed up servos; I imagine the trick will be getting something that is strong enough and also fits.
I like the Robotis servos much more than the Servo City servos. Robotis servos are all-digital, UART based communication (with feedback) with a multi-drop bus, and so on. The XM430-W430-T is a quite strong servo for the size (not much bigger than the AX-12A, 43 kgcm) and I do have some spare MX-64-T servos (which are bigger, but go to 64 kgcm) from my walker.
But, with the grippy tires I have, I think a servo of any strength is going to potentially get stuck -- or start tearing the 1/8" aluminum brackets up, or ripping the rubber from the tires ...
I think I'll go with slippier tires (which also lead to more precise encoder-based odometry) as well as three axles; a center axle that doesn't turn but is still driven and has encoders, and tune the suspension to put 50% of the weight on that axle.
I had always imagined that some type of preprocessing step was needed on the images, but he just trained the net with raw, RBG images.
Well, you need to "label" the data, which means that you have to provide the training system a "goal" to strive towards. The "goal" might be two simple outputs: "left/center/right" and "drive/brake" or it might be something more advanced (like labeling areas with "pedestrian," "open space," "curb" and so forth.)
When using synthetic data, the benefit is that the labeling is "free" -- you generated the image, you know what the desired output is!
The SYNTHIA dataset does this for cityscape scenes (streets/houses/pedestrians.)
The draw-back of this method is that the modeled/textured geometry used for synthetic images tend to be very repetitive, and thus the networks tend to pick up on details of the synthetic environment that aren't there in the real world, and thus end up not working well when provided real data. However, starting out with a synthetic data set can help in the first half of training the network -- establishing the overall major structural connections for detecting edges, aggregating features, and so forth.
Meanwhile, some friendly Germans have made a dataset with REAL data of the same kind:
Luckily, I only drive where there are lawns/paths/pedestrians, and there are fences and hay bales to keep accidents from causing any lasting damage, so I don't need to go to that level :-)
Obligatory rover picture; here's what it looks like right now: (after taking it out of the closet where it's been for a year)

I'm definitely going to have to clean up that cable mess in the center, if nothing else ...
Sincerely,
jw
Sincerely,
Jon Watte
--
"I find that the harder I work, the more luck I seem to have." -- Thomas Jefferson
--
You received this message because you are subscribed to the Google Groups "diyrovers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to diyrovers+unsubscribe@googlegroups.com.
To post to this group, send email to diyr...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/diyrovers/d3ab32e2-bd06-4eb8-bef9-0e8940de59c2%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages