Any use for RNA secondary structure prediction? (slash help getting started?)
32 views
Skip to first unread message

Michael Flynn
Aug 10, 2015, 5:37:16 PM8/10/15
to DIYbio
Hi all,
I recently wrote my undergraduate thesis on RNA secondary structure prediction algorithms. In the process I've become intimately familiar with the algorithms and code bases behind Unafold and RNAstructure, which I have been told comprise 90% of the market share of RNA structure prediction software. My thesis is located here, if you are interested.
However, I was a physics and computer science student, and I have minimal (no) training in biology. This meant that most of the time while I was writing my thesis I was in great want of background knowledge and motivation. I was often asked why my research was important, but I could never give a strong answer. When I asked my advisor for motivations behind our work, he did not answer to my satisfaction. So I thought, what better way to learn than DIYbio?
So are there ways I could help this community? What would be the best path for me to get started, in a way that my background would be the most relevant?
Mike
![Mega [Andreas Stuermer]'s profile photo](http://lh3.googleusercontent.com/a-/ALV-UjUNVm1hB8tAcAAFPeCKG7sAAOMXtiGvFTd7NEBaHFgxRcdy1Lnb=s40-c)
Mega [Andreas Stuermer]
Aug 10, 2015, 6:58:14 PM8/10/15
to DIYbio
Probably there are tons of things that are important for RNA folding.
-The 5'UTR of CDS determine translation initiation efficiency (heavy secondary structures may keep the ribosomes from binding)
- crispr: maybe you can engineer the scaffold (change certain bases that are non essential, to keep homologous recombination from occuring in multiplex constructs)
-crispr2: maybe it is possible to express the guide (19-20 bp that tells where to cut in the genome) and the scaffold (80 bp, that binds to cas9 enzyme) seperately and then join them by some weird RNA mechanism. It is a pain in the *** to express 10 guides, because you would need the scaffold 10 times. Costing synthesis (especially repeats are difficult and $$$)
-The 5'UTR of CDS determine translation initiation efficiency (heavy secondary structures may keep the ribosomes from binding)
- crispr: maybe you can engineer the scaffold (change certain bases that are non essential, to keep homologous recombination from occuring in multiplex constructs)
-crispr2: maybe it is possible to express the guide (19-20 bp that tells where to cut in the genome) and the scaffold (80 bp, that binds to cas9 enzyme) seperately and then join them by some weird RNA mechanism. It is a pain in the *** to express 10 guides, because you would need the scaffold 10 times. Costing synthesis (especially repeats are difficult and $$$)

Koeng
Aug 11, 2015, 12:31:31 AM8/11/15
to DIYbio
It's important for gene expression. For example, if I wanted to get precise gene expression, I would have to filter through a library of RBSs ( https://www.denovodna.com/software/ ). A more recent example was structure analysis they used to tether the 2 subunits of the e coli ribosome together, coupling RBS initiation and the peptidyl transferase centre for *true orthogonal proteins* ( http://www.ncbi.nlm.nih.gov/pubmed/26222032 ). I have also used it when I need to fuse an active RNA to a protein coding sequence and I don't want structural interference. I use it both very often at an academic lab and at a DIYbio lab.
(and Mega couldn't you hypothetically just do this with an HSV ribozyme and the normal CRISPR repeats? )
Anyway, I would say the most useful thing for me would be an open source RBS calculator and secondary structure prediction program I could just run on my computer. (I'm not so enthusiastic about all these web server things). These have probably been done (first one has if I ever get around to getting it to work) but that's what would be most helpful for me.
-Koeng
(and Mega couldn't you hypothetically just do this with an HSV ribozyme and the normal CRISPR repeats? )
Mega [Andreas Stuermer]
Aug 11, 2015, 7:42:54 AM8/11/15
to DIYbio
Yeah, but the problem is that multiple repeats are difficult to synthesize for synthesis companies, and some won't even try. Or make it much more expensive.
On Monday, August 10, 2015 at 11:37:16 PM UTC+2, Michael Flynn wrote:
Koeng
Aug 11, 2015, 10:09:50 AM8/11/15
to DIYbio
I suppose you could try the ligase cycling reaction with synthesized oligos then do a PCR off of it. Since Taq ligase can't add nucleotides, literal positioning could accomplish directionality. (have one overlap 20 with the sgRNA, one overlap 25, etc, and design the sgRNA to also have this)
I've also looked into goldengate assembly, it can do this pretty darn well.
-Koeng

Josiah Zayner
Aug 11, 2015, 12:20:49 PM8/11/15
to DIYbio
Interesting thesis topic. I still can't wrap my head around the use of a partition function vs just "pure" free energy calculations. Especially because of non-local base pairing leading to an ridonculously incalculable number of possible states but I guess the goal is to try and predict more canonical secondary structures? And probably I just haven't spent enough time reading on the topic. Previous to this though I never knew that mfold(unafold) used a partition function calculation.
The question you ask is difficult to answer, why is RNA secondary structure prediction important? RNA secondary structure prediction is important because it provides a tool for Scientists to use, to better understand how biology works. Science can't have exact answers in some(most?) cases. Think about using SHAPE for RNA secondary structure determination it only gives someone info on what bases are "flexible" or "unpaired"(the reason these are in quotes is because those definitions can vary). The only ways to really determine a "macrostate" conformation in RNA secondary structure is through things like NMR or X-ray crystallography and even those are just a local energy minimum based on context. So programs like unafold are used widely by RNA biochemists and biologist to understand how and why RNA works the way it does. The more we understand how things work the better we can predict why things are doing what they are doing and the better we can do cool things with Science. Helping with unafold doesn't necessarily contribute anything directly to our knowledge of the universe but it helps others contribute.
As for what you should do, the field of Molecular Dynamics simulations lends itself to someone with knowledge of physics and computer science. Molecular Dynamics around protein function and dynamics is a field that is being extensively and successfully explored. If you run a windows box I would suggest looking up tutorials on NAMD and proteins, if you use linux I would suggest looking up tutorials on GROMACS and proteins. Simulations can also be run with the 3D structures of RNA but the energy functions aren't quite optimized and so I would generally stick to proteins.
If you have any questions feel free to send them my way.
Josiah Zayner
The question you ask is difficult to answer, why is RNA secondary structure prediction important? RNA secondary structure prediction is important because it provides a tool for Scientists to use, to better understand how biology works. Science can't have exact answers in some(most?) cases. Think about using SHAPE for RNA secondary structure determination it only gives someone info on what bases are "flexible" or "unpaired"(the reason these are in quotes is because those definitions can vary). The only ways to really determine a "macrostate" conformation in RNA secondary structure is through things like NMR or X-ray crystallography and even those are just a local energy minimum based on context. So programs like unafold are used widely by RNA biochemists and biologist to understand how and why RNA works the way it does. The more we understand how things work the better we can predict why things are doing what they are doing and the better we can do cool things with Science. Helping with unafold doesn't necessarily contribute anything directly to our knowledge of the universe but it helps others contribute.
As for what you should do, the field of Molecular Dynamics simulations lends itself to someone with knowledge of physics and computer science. Molecular Dynamics around protein function and dynamics is a field that is being extensively and successfully explored. If you run a windows box I would suggest looking up tutorials on NAMD and proteins, if you use linux I would suggest looking up tutorials on GROMACS and proteins. Simulations can also be run with the 3D structures of RNA but the energy functions aren't quite optimized and so I would generally stick to proteins.
If you have any questions feel free to send them my way.
Josiah Zayner
On Monday, August 10, 2015 at 2:37:16 PM UTC-7, Michael Flynn wrote:
Michael Flynn
Aug 11, 2015, 4:32:08 PM8/11/15
to DIYbio
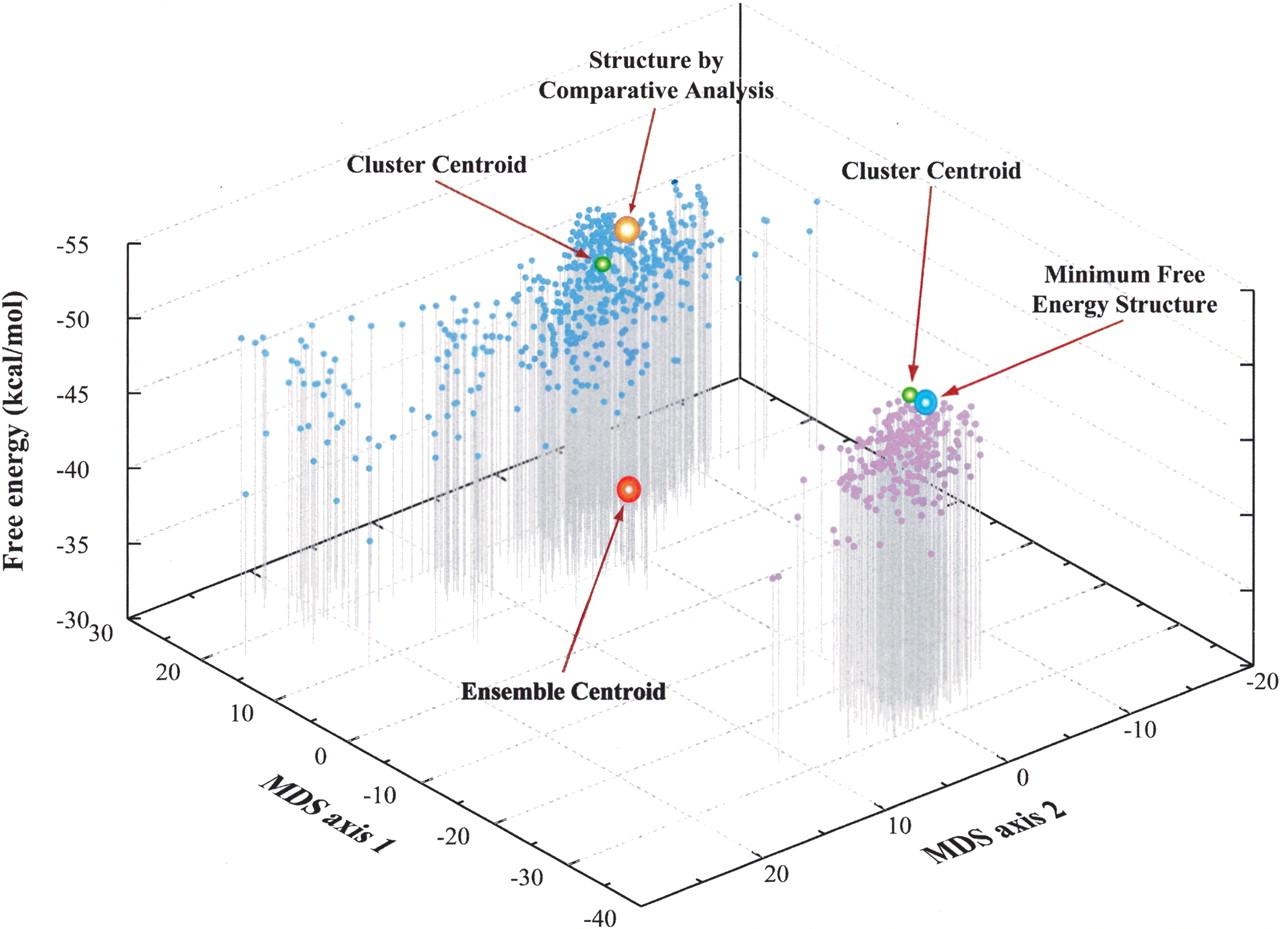
There are actually very good reasons to use the partition function over the minimum free energy, at least for strands of length N > 100. If you look at the Boltzmann distribution P(s) = e^{-E(s)}/Z, the probability of being in any given state goes like 1.1*10^{-N/59} (see attached pMFE2.pdf). For many of these strands, there exist multiple stable macrostates, the most stable of which may not contain the MFE state because they get their entropic weight from multiplicity of states near them, rather than having the lowest energies (see attached ensemble-centroid.jpg). Predicting structure by sampling from the boltzmann distribution and clustering structures has been shown to be more accurate than just the MFE calculation. Check out Ding and Lawrence (2005) http://www.ncbi.nlm.nih.gov/pubmed/16043502. There are also many other reasons not to trust MFE computations, mostly because the energy model of RNA has tons of error and uncertainty which the MFE is *really* sensitive to, while partition function probabilities are a little more robust. I wrote about this extensively in my thesis. You are correct though, it is a difficult computation because there are many states, specifically O(1.8^n), but there exist dynamic programming algorithms that compute it in O(N^3).
I was thinking more of basic DIY projects that I could do and maybe extend with RNA structure prediction, or other molecular dynamics tools. I recently read about BioBricks, thought I might be able to help design some standardized parts, but I would have a hard time extending something I haven't touched yet. I want to get my hands dirty, and through that figure out something I could use my computational knowledge for. I am just completely in the dark with how to get started experimentally.
Does this book look good: http://www.amazon.com/Synthetic-Biology-Manual-Josefine-Liljeruhm/dp/9814579548/ref=sr_1_4?ie=UTF8&qid=1439325077&sr=8-4&keywords=biobuilder ?
Mike
{kind=link}
Josiah Zayner
Aug 11, 2015, 4:38:51 PM8/11/15
to diy...@googlegroups.com
Thanks for the info.
Here is a new book that just came out. I have not read it but maybe you should check it out.
http://www.amazon.com/BioBuilder-Natalie-Kuldell/dp/1491904291
Here is a new book that just came out. I have not read it but maybe you should check it out.
http://www.amazon.com/BioBuilder-Natalie-Kuldell/dp/1491904291
--
-- You received this message because you are subscribed to the Google Groups DIYbio group. To post to this group, send email to diy...@googlegroups.com. To unsubscribe from this group, send email to diybio+un...@googlegroups.com. For more options, visit this group at https://groups.google.com/d/forum/diybio?hl=en
Learn more at www.diybio.org
---
You received this message because you are subscribed to a topic in the Google Groups "DIYbio" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/diybio/dyCR2e5ZvSI/unsubscribe.
To unsubscribe from this group and all its topics, send an email to diybio+un...@googlegroups.com.
To post to this group, send email to diy...@googlegroups.com.
Visit this group at http://groups.google.com/group/diybio.
To view this discussion on the web visit https://groups.google.com/d/msgid/diybio/9a43c14d-0600-4d0f-a80a-4754ac2f5463%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages