Cannot write to volume: No space left on device
288 views
Skip to first unread message

Jan Gatzke
Sep 28, 2018, 3:25:32 PM9/28/18
to dedupfilesystem-sdfs-user-discuss
Randomly my SDFS volume stops working. I can read all data but cannot write anything. Error is "No space left on device". After remounting writing data to the volume works just fine.
sdfscli --volume-info
Files : 15
Volume Capacity : 1 TB
Volume Current Logical Size : 231.54 GB
Volume Max Percentage Full : Unlimited
Volume Duplicate Data Written : 80.65 GB
Unique Blocks Stored: 537.66 GB
Unique Blocks Stored after Compression : 243.76 GB
Cluster Block Copies : 2
Volume Virtual Dedup Rate (Unique Blocks Stored/Current Size) : -132.21%
Volume Actual Storage Savings (Compressed Unique Blocks Stored/Current Size) : -5.28%
Compression Rate: 54.66%
df -h
sdfs:/etc/sdfs/pool0-volume-cfg.xml:6442 1.1T 244G 781G 24% /daten/backup_dedup
Installed version of SDFS is 3.7.6.0
I cannot get the dse info
sdfscli --dse-info
java.io.IOException: java.net.SocketTimeoutException: Read timed out
at org.opendedup.sdfs.mgmt.cli.MgmtServerConnection.getResponse(MgmtServerConnection.java:179)
at org.opendedup.sdfs.mgmt.cli.ProcessDSEInfo.runCmd(ProcessDSEInfo.java:18)
at org.opendedup.sdfs.mgmt.cli.SDFSCmdline.parseCmdLine(SDFSCmdline.java:79)
at org.opendedup.sdfs.mgmt.cli.SDFSCmdline.main(SDFSCmdline.java:678)
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:170)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at sun.security.ssl.InputRecord.readFully(InputRecord.java:465)
at sun.security.ssl.InputRecord.read(InputRecord.java:503)
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:973)
at sun.security.ssl.SSLSocketImpl.readDataRecord(SSLSocketImpl.java:930)
at sun.security.ssl.AppInputStream.read(AppInputStream.java:105)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
at java.io.BufferedInputStream.read(BufferedInputStream.java:265)
at org.apache.commons.httpclient.HttpParser.readRawLine(HttpParser.java:78)
at org.apache.commons.httpclient.HttpParser.readLine(HttpParser.java:106)
at org.apache.commons.httpclient.HttpConnection.readLine(HttpConnection.java:1116)
at org.apache.commons.httpclient.MultiThreadedHttpConnectionManager$HttpConnectionAdapter.readLine(MultiThreadedHttpConnectionManager.java:1413)
at org.apache.commons.httpclient.HttpMethodBase.readStatusLine(HttpMethodBase.java:1973)
at org.apache.commons.httpclient.HttpMethodBase.readResponse(HttpMethodBase.java:1735)
at org.apache.commons.httpclient.HttpMethodBase.execute(HttpMethodBase.java:1098)
at org.apache.commons.httpclient.HttpMethodDirector.executeWithRetry(HttpMethodDirector.java:398)
at org.apache.commons.httpclient.HttpMethodDirector.executeMethod(HttpMethodDirector.java:171)
at org.apache.commons.httpclient.HttpClient.executeMethod(HttpClient.java:397)
at org.apache.commons.httpclient.HttpClient.executeMethod(HttpClient.java:323)
at org.opendedup.sdfs.mgmt.cli.MgmtServerConnection.getResponse(MgmtServerConnection.java:163)
... 3 more
However, I am sure the storage is fine.

Sam Silverberg
Sep 29, 2018, 6:48:56 PM9/29/18
to dedupfilesystem-...@googlegroups.com
Try unmounting the volume and editing the config in /etc/sdfs with a larger allocation-size. I could also be that the underlying block filesystem is full.
Sam
--
You received this message because you are subscribed to the Google Groups "dedupfilesystem-sdfs-user-discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dedupfilesystem-sdfs-u...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Ty Moses
Jan 28, 2019, 3:03:02 PM1/28/19
to dedupfilesystem-sdfs-user-discuss
Sam-
I have experienced similar issues. Why does the chunkstore keep growing even when I haven’t put any additional data in the files folder?
I am trying to store my backups in the volume which replicates to Backblaze B2 and awaits deduplication.
I can see data going into Backblaze immediately following the start of a backup job but then the job either hangs
or it fails with errors. It seems that the volume or chunkstore isn’t stable, causing my backups to fail. More specifically it seems to be having trouble synchronizing the “files” folder in the volume.
I would just like to have a clear understanding of the process that sdfs goes through, in order, when data is dropped into the volume.
Any info would be helpful
Thanks
I have experienced similar issues. Why does the chunkstore keep growing even when I haven’t put any additional data in the files folder?
I am trying to store my backups in the volume which replicates to Backblaze B2 and awaits deduplication.
I can see data going into Backblaze immediately following the start of a backup job but then the job either hangs
or it fails with errors. It seems that the volume or chunkstore isn’t stable, causing my backups to fail. More specifically it seems to be having trouble synchronizing the “files” folder in the volume.
I would just like to have a clear understanding of the process that sdfs goes through, in order, when data is dropped into the volume.
Any info would be helpful
Thanks

Rinat Camal
Jan 29, 2019, 4:32:34 AM1/29/19
to dedupfilesystem-sdfs-user-discuss
I have similar issue.
Today I found out the reason.
SDFS is not removing chunks from underlying filesystem after you delete file from SDFS. Those chunks just marked "deleted" but not removed from FS, the chunk, the *.cmap *.map *.md files of that chunk are still in place.
Today I found out the reason.
SDFS is not removing chunks from underlying filesystem after you delete file from SDFS. Those chunks just marked "deleted" but not removed from FS, the chunk, the *.cmap *.map *.md files of that chunk are still in place.
Rinat Camal
Jan 29, 2019, 6:24:24 AM1/29/19
to dedupfilesystem-sdfs-user-discuss
Also I've opened RocksDB today directly
there is this strange values, that I cannot open or delete.
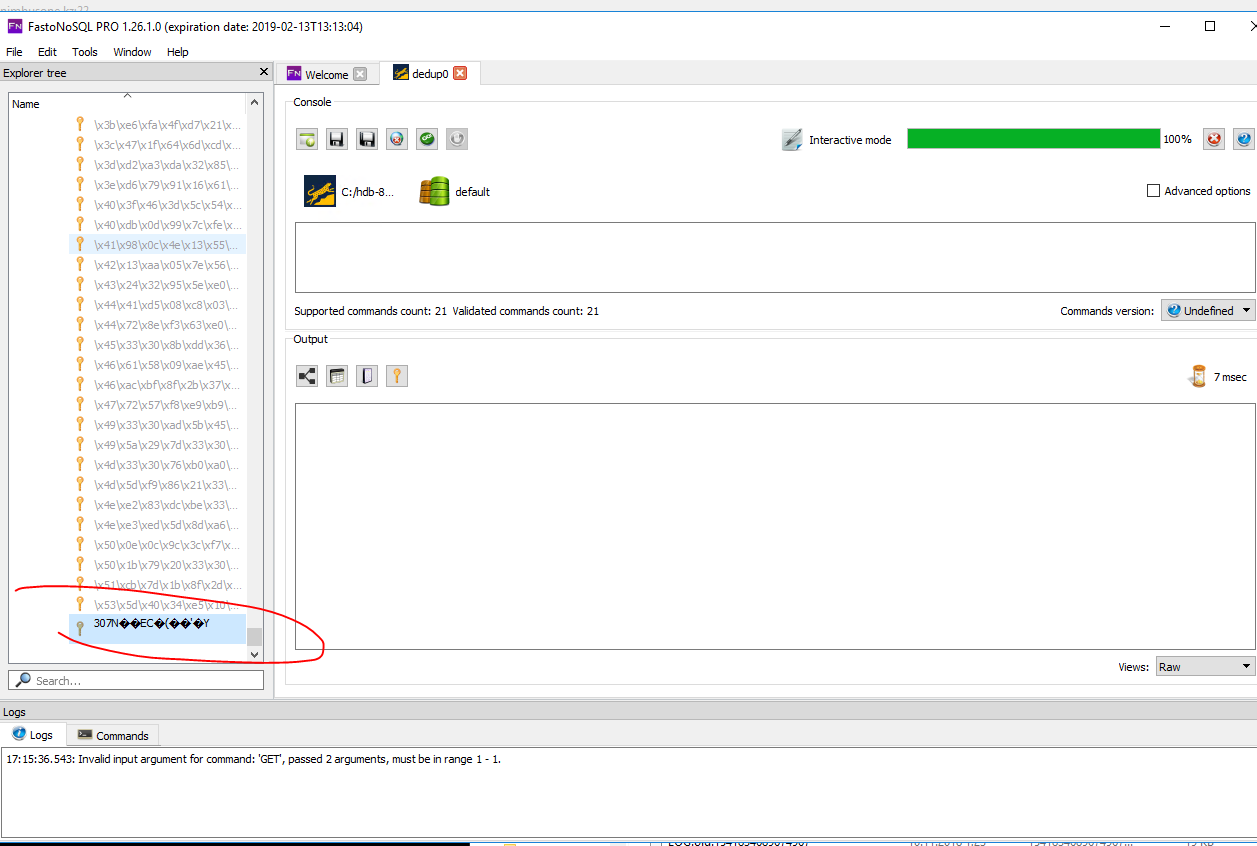
there is this strange values, that I cannot open or delete.
Sam Silverberg
Jan 29, 2019, 12:01:35 PM1/29/19
to dedupfilesystem-...@googlegroups.com
Hi all - Data gets removed on a scheduled basis. This data will be removed as a batch process. Use sdfscli —clean store to remove data
--
Rinat Camal
Jan 29, 2019, 12:52:55 PM1/29/19
to dedupfilesystem-sdfs-user-discuss
hello again!
I maybe wrong but I think this is broken database issue.
you see, I removed everything from this server to check if it will free space. This server was dedicated to test OpenDedup. The volume is Empty now.
SDFS started to free space and then stopped.
I can send you database if you want to but I think OpenDedup stuck on that damaged records. There is several of them in folder 0 and folder 1
Some of this damaged record cannot be removed!!!
I maybe wrong but I think this is broken database issue.
you see, I removed everything from this server to check if it will free space. This server was dedicated to test OpenDedup. The volume is Empty now.
SDFS started to free space and then stopped.
I can send you database if you want to but I think OpenDedup stuck on that damaged records. There is several of them in folder 0 and folder 1
Some of this damaged record cannot be removed!!!
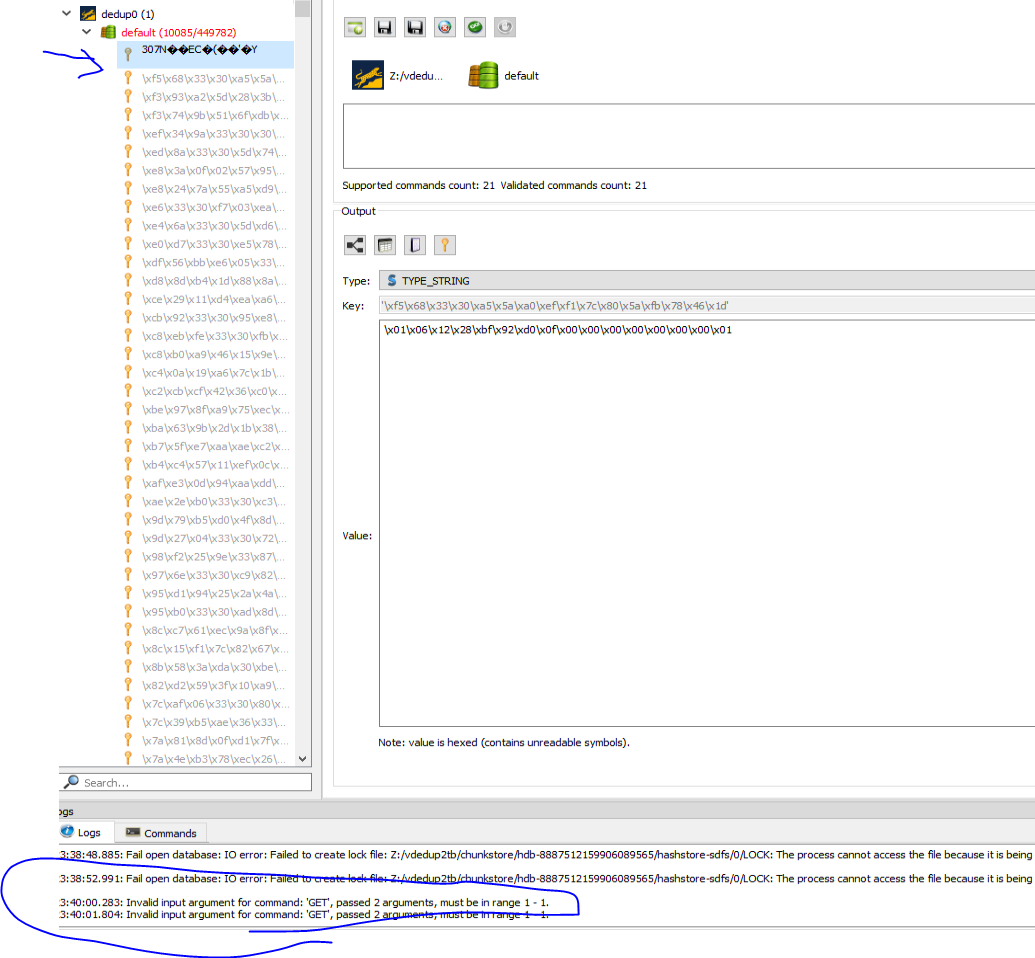
these commands start then they end successfully
sdfscli --port=6443 --cleanstore
sdfscli --port=6443 --cleanstore
sdfscli --port=6443 --compactcleanstore
also command lsb finishes with no errors, but I think it does not check the keys themself
ldb checkconsistency --db=/media/xfs/sdfs/vdedup2tb/chunkstore/hdb-8887512159906089565/hashstore-sdfs/0/
Do you know any what I can check database key-values for integrity?
also command lsb finishes with no errors, but I think it does not check the keys themself
ldb checkconsistency --db=/media/xfs/sdfs/vdedup2tb/chunkstore/hdb-8887512159906089565/hashstore-sdfs/0/
Do you know any what I can check database key-values for integrity?
Rinat Camal
Jan 29, 2019, 1:55:18 PM1/29/19
to dedupfilesystem-sdfs-user-discuss
Also can you explain what is that means?
[sdfs] [org.opendedup.sdfs.filestore.gc.PFullGC] [114] [Thread-56] - Current DSE Percentage Full is [6.68141161782119E-4] will run GC when [0.10066814116178212]
[sdfs] [org.opendedup.sdfs.filestore.gc.PFullGC] [114] [Thread-56] - Current DSE Percentage Full is [6.68141161782119E-4] will run GC when [0.10066814116178212]

David K
Jan 29, 2019, 2:16:28 PM1/29/19
to dedupfilesystem-sdfs-user-discuss
DSE = Deduplication Storage Engine, Percent full represents how much data is stored in your local cache. Multiply the number by 10 to the exponent -4 in this case.
GC is Garbage Collection.
Your next run will be when when the DSE grows by 10% or, at the next scheduled run (search the /var/log/<poolname>-volume-cfg.xml.log file for the phrase "Garbage Collection"
Rinat Camal
Jan 30, 2019, 12:44:16 AM1/30/19
to dedupfilesystem-sdfs-user-discuss
ok, here is my questions
1. "how much data is stored in your local cache". this is local-volume not a cluster, what local cache?
2. "next scheduled run" it runs every hour, nothing is removed.sdfscli --port=6443 --get-gc-schedule
Cron Schedule is : 0 1 * ? * *
+-------------------------------+
| Next 5 Runs |
+-------------------------------+
| Wed Jan 30 12:01:00 ALMT 2019 |
| Wed Jan 30 13:01:00 ALMT 2019 |
| Wed Jan 30 14:01:00 ALMT 2019 |
| Wed Jan 30 15:01:00 ALMT 2019 |
| Wed Jan 30 16:01:00 ALMT 2019 |
+-------------------------------+
3. It does not show me DSE info - only error
sdfscli --port=6443 --dse-info
java.io.IOException: java.net.SocketTimeoutException: Read timed out
at org.opendedup.sdfs.mgmt.cli.MgmtServerConnection.getResponse(MgmtServerConnection.java:179)
at org.opendedup.sdfs.mgmt.cli.ProcessDSEInfo.runCmd(ProcessDSEInfo.java:18)
at org.opendedup.sdfs.mgmt.cli.SDFSCmdline.parseCmdLine(SDFSCmdline.java:79)
at org.opendedup.sdfs.mgmt.cli.SDFSCmdline.main(SDFSCmdline.java:678)
Caused by: java.net.SocketTimeoutException: Read timed out
Rinat Camal
Jan 31, 2019, 1:31:33 AM1/31/19
to dedupfilesystem-sdfs-user-discuss
Hello!
so, do you have any suggestion for me to try?
volume is still Empty but chunkstore is more than 900 GB.
I think this problem appears the moment Java crashes for any reason(in my case SAP HANA backups test), so I need to check integrity of record in RocksDB somehow after fall
I think this problem appears the moment Java crashes for any reason(in my case SAP HANA backups test), so I need to check integrity of record in RocksDB somehow after fall
Rinat Camal
Jan 31, 2019, 7:02:14 AM1/31/19
to dedupfilesystem-sdfs-user-discuss
I have finally was able to recevin info from command
root@alm-dedup:~# sdfscli --port=6443 --dse-info
DSE Max Size : 4 TB
DSE Current Size : 0 B
DSE Compressed Size : 0 B
DSE Percent Full : 0.0%
DSE Page Size : 32768
DSE Blocks Available for Reuse : 0
Total DSE Blocks : 3596523
Average DSE Block Size : 0
DSE Current Cache Size : 1.44 TB
DSE Max Cache Size : 10 GB
Trottled Read Speed : 0 B/s
Trottled Write Speed : 0 B/s
Encryption Key : QZJ5IafYiJGnvaTSi2Vl-FghGANZs4ku0gwpPcAUeGDgR+y3MRRe25V4h5_rETlS
Encryption IV : 1e0f582836cfcaa20c886055f4d4f625
Cache is not being freed! How can i FORCE it to start cleaning????
root@alm-dedup:~# sdfscli --port=6443 --dse-info
DSE Max Size : 4 TB
DSE Current Size : 0 B
DSE Compressed Size : 0 B
DSE Percent Full : 0.0%
DSE Page Size : 32768
DSE Blocks Available for Reuse : 0
Total DSE Blocks : 3596523
Average DSE Block Size : 0
DSE Current Cache Size : 1.44 TB
DSE Max Cache Size : 10 GB
Trottled Read Speed : 0 B/s
Trottled Write Speed : 0 B/s
Encryption Key : QZJ5IafYiJGnvaTSi2Vl-FghGANZs4ku0gwpPcAUeGDgR+y3MRRe25V4h5_rETlS
Encryption IV : 1e0f582836cfcaa20c886055f4d4f625
Cache is not being freed! How can i FORCE it to start cleaning????
Rinat Camal
Feb 19, 2019, 4:22:57 AM2/19/19
to dedupfilesystem-sdfs-user-discuss
I found relationship between this 2 problems
"Cannot write to volume: No space left on device" and "max open file limit is always hited " https://github.com/opendedup/sdfs/issues/70
block-size
If you backup lots of small files less than 1KB size as I have to do. I have 18 folder with more than 65000 files in one backup.
increasing max-variable-segment-size and block-size="1 GB" will result in "Too many open files" cause those Blocks will be opened by SDFS until the end of backup.
The solution that currently works for me. Backup on normal FS (ext4 in may case). pack all 18 folders into tar files and then move big files on SDFS volume
"Cannot write to volume: No space left on device" and "max open file limit is always hited " https://github.com/opendedup/sdfs/issues/70
block-size
If you backup lots of small files less than 1KB size as I have to do. I have 18 folder with more than 65000 files in one backup.
increasing max-variable-segment-size and block-size="1 GB" will result in "Too many open files" cause those Blocks will be opened by SDFS until the end of backup.
BUT decreasing to block-size="10 MB" will result in sdfscli --dse-info error. The cause of this error will also cause Garbage Collection to fail.
Rinat Camal
Mar 11, 2019, 2:31:24 AM3/11/19
to dedupfilesystem-sdfs-user-discuss
I think I found it. The way to force Garbage Collection to start
the start of clearing is affected by this parameter
capacity="120 GB"
Who have this problem can try to do this
1) sdfscli --dse-info. You need to get results from this command
2) umount sdfs volume
3) reduce "capacity=" to be at least twice "DSE Current Size"
so "DSE Percent Full " will be more than 10%
4) mount volume
5) after successfull mounting unmount and mount it again.
6) next scheduled GC clean up will be removing hashes
the start of clearing is affected by this parameter
capacity="120 GB"
Who have this problem can try to do this
1) sdfscli --dse-info. You need to get results from this command
2) umount sdfs volume
3) reduce "capacity=" to be at least twice "DSE Current Size"
so "DSE Percent Full " will be more than 10%
4) mount volume
5) after successfull mounting unmount and mount it again.
6) next scheduled GC clean up will be removing hashes
Reply all
Reply to author
Forward
0 new messages