Cythonize memleak
59 views
Skip to first unread message

Volker Braun
Apr 22, 2015, 9:35:01 PM4/22/15
to cython...@googlegroups.com
Cythonizing multiple files all runs in a single Python process, and apparently has a memory leak. This is bad for projects with large numbers of extension modules. Is there a particular reason why the Python process is not restarted to guard against memory leaks? Should I open a bug?
In the picture below you see a log for buliding the Sage library (sage -ba) with a single thread. The first 2/3 is cythonizing 411 modules, the last third is compiling (mostly ccache). The memory usage for Cython keeps going up as the files are processed:
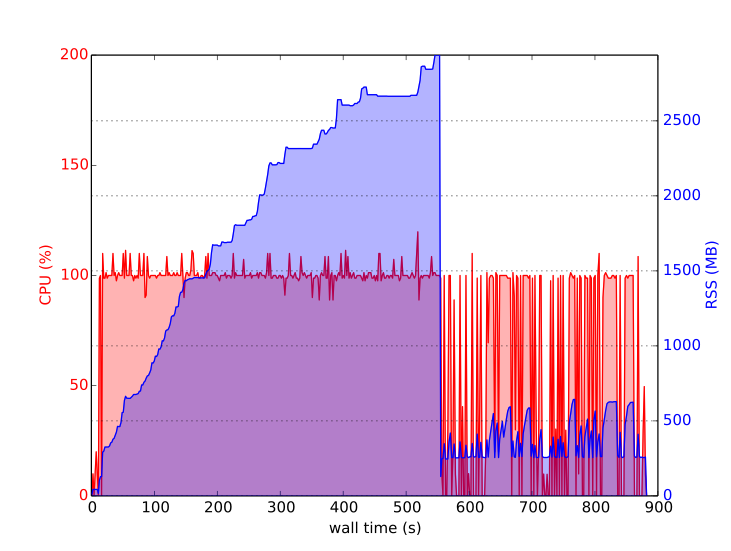
We recently noticed that we can't build Sage with 2GB of physical ram any more due to this, see https://groups.google.com/d/topic/sage-devel/8MYGxWQBEzs/discussion

Robert Bradshaw
Apr 22, 2015, 11:46:43 PM4/22/15
to cython...@googlegroups.com
The memory use goes up because it caches the parse of .pxd files (which otherwise must be re-parsed over and over, which gets expensive). However, this does seem excessive. Do you have any kind of heap dump towards the end?
--
---
You received this message because you are subscribed to the Google Groups "cython-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to cython-users...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Jeroen Demeyer
Apr 23, 2015, 10:21:58 AM4/23/15
to cython...@googlegroups.com
On 2015-04-23 05:46, Robert Bradshaw wrote:
> The memory use goes up because it caches the parse of .pxd files (which
> otherwise must be re-parsed over and over, which gets expensive).
> However, this does seem excessive. Do you have any kind of heap dump
> towards the end?
After removing the cache from cached_method, cached_function and
> The memory use goes up because it caches the parse of .pxd files (which
> otherwise must be re-parsed over and over, which gets expensive).
> However, this does seem excessive. Do you have any kind of heap dump
> towards the end?
load_cached, the problem persists.
guppy/heapy dump after Cythonizing one module:
Cythonizing sage/algebras/letterplace/free_algebra_element_letterplace.pyx
Partition of a set of 74143 objects. Total size = 16750128 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 4104 6 4494528 27 4494528 27 dict of
Cython.Compiler.Symtab.Entry
1 9613 13 1773840 11 6268368 37
Cython.Compiler.StringEncoding.EncodedString
2 20977 28 1667656 10 7936024 47 list
3 3142 4 1582480 9 9518504 57 dict (no owner)
4 5696 8 1398416 8 10916920 65 unicode
5 1264 2 1324672 8 12241592 73 dict of
Cython.Compiler.PyrexTypes.CFuncType
6 2419 3 677320 4 12918912 77 dict of
Cython.Compiler.PyrexTypes.CFuncTypeArg
7 6881 9 585096 3 13504008 81 tuple
8 1487 2 416360 2 13920368 83 dict of
Cython.Compiler.PyrexTypes.CPtrType
9 3861 5 384352 2 14304720 85 str
Jeroen Demeyer
Apr 24, 2015, 1:56:01 AM4/24/15
to cython...@googlegroups.com
I was wondering: is the Python garbage collector mathematically perfect
or does it use heuristics? Could it be that a very complicated reference
graph confuses the garbage collector?
or does it use heuristics? Could it be that a very complicated reference
graph confuses the garbage collector?
Robert Bradshaw
Apr 24, 2015, 2:16:26 AM4/24/15
to cython...@googlegroups.com
the fact that Cython avoids re-parsing (say) integer.pxd for every
instance of "cimport sage.rings.integer." The fact that it's mostly
Symtab.Entry supports this. (I also wonder how many
StringEncoding.EncodedStrings are unique, or if interning could reduce
this 11%). Still, 2G seems excessive for what probably amounts to only
a couple of MB of source (pxd) files, or even all pxd and pyx put
together.
Jeroen Demeyer
Apr 24, 2015, 4:28:37 AM4/24/15
to cython...@googlegroups.com
On 2015-04-24 08:15, Robert Bradshaw wrote:
> On Thu, Apr 23, 2015 at 10:55 PM, Jeroen Demeyer <jdem...@cage.ugent.be> wrote:
>> I was wondering: is the Python garbage collector mathematically perfect or
>> does it use heuristics? Could it be that a very complicated reference graph
>> confuses the garbage collector?
>
> Doubtful. This isn't a "cache" in the sense of cached_method, but in
> the fact that Cython avoids re-parsing (say) integer.pxd for every
> instance of "cimport sage.rings.integer."
Where in the Cython sources is this mechanism?
> On Thu, Apr 23, 2015 at 10:55 PM, Jeroen Demeyer <jdem...@cage.ugent.be> wrote:
>> I was wondering: is the Python garbage collector mathematically perfect or
>> does it use heuristics? Could it be that a very complicated reference graph
>> confuses the garbage collector?
>
> Doubtful. This isn't a "cache" in the sense of cached_method, but in
> the fact that Cython avoids re-parsing (say) integer.pxd for every
> instance of "cimport sage.rings.integer."

Stefan Behnel
Apr 24, 2015, 6:07:27 AM4/24/15
to cython...@googlegroups.com
Robert Bradshaw schrieb am 24.04.2015 um 08:15:
> I also wonder how many
> StringEncoding.EncodedStrings are unique, or if interning could reduce
> this 11%
This is Py2.x though (I guess). The situation is much better in Py3.3+, as
> I also wonder how many
> StringEncoding.EncodedStrings are unique, or if interning could reduce
> this 11%
most of these (Unicode) strings are ascii-only.
That being said, letting the parser intern identifier names sounds like a
good idea.
https://github.com/cython/cython/commit/0f9a60d99fc6b818217b7a28ac402215bf1cb87b
A quick test with lxml gave me 48600 interning lookups in the parser for
only 3900 distinct (and now interned) names.
> Still, 2G seems excessive for what probably amounts to only
> a couple of MB of source (pxd) files, or even all pxd and pyx put
> together.
give more insights.
Stefan
Stefan Behnel
Apr 24, 2015, 6:10:22 AM4/24/15
to cython...@googlegroups.com
Stefan
Jeroen Demeyer
Apr 24, 2015, 6:44:29 AM4/24/15
to cython...@googlegroups.com
I did some memory profiling using pympler.asizeof and it seems that the
following modules keep growing:
Cython.Compiler.PyrexTypes
Cython.Compiler.CythonScope
following modules keep growing:
Cython.Compiler.PyrexTypes
Cython.Compiler.CythonScope
Jeroen Demeyer
Apr 24, 2015, 11:35:50 AM4/24/15
to cython...@googlegroups.com
More precisely, the leak is in
Cython.Compiler.PyrexTypes.c_tuple_types
Cython.Compiler.PyrexTypes.c_tuple_types
Stefan Behnel
Apr 24, 2015, 11:58:33 AM4/24/15
to cython...@googlegroups.com
Jeroen Demeyer schrieb am 24.04.2015 um 17:35:
> More precisely, the leak is in
>
> Cython.Compiler.PyrexTypes.c_tuple_types
Thanks for investigating. This should fix it:
> More precisely, the leak is in
>
> Cython.Compiler.PyrexTypes.c_tuple_types
https://github.com/cython/cython/commit/bb4d9c2de71b7c7e1e02d9dfeae53f4547fa9d7d
Stefan
Jeroen Demeyer
Apr 24, 2015, 2:35:36 PM4/24/15
to cython...@googlegroups.com
with 600MB of memory.
Robert Bradshaw
Apr 24, 2015, 2:47:28 PM4/24/15
to cython...@googlegroups.com
Volker Braun
Apr 24, 2015, 6:47:43 PM4/24/15
to cython...@googlegroups.com
Thanks for the quick fix! Picture proof with the patch:

Jeroen Demeyer
Apr 25, 2015, 4:44:13 AM4/25/15
to cython...@googlegroups.com
On 2015-04-23 05:46, Robert Bradshaw wrote:
> it caches the parse of .pxd files (which
> otherwise must be re-parsed over and over, which gets expensive).
Are you sure this happens? Maybe this is an idea which was never
> otherwise must be re-parsed over and over, which gets expensive).
actually implemented? I have looked carefully in the code and couldn't
find anything like this.
Robert Bradshaw
Apr 25, 2015, 4:57:48 AM4/25/15
to cython...@googlegroups.com
Stefan Behnel
Apr 25, 2015, 5:42:30 AM4/25/15
to cython...@googlegroups.com
Robert Bradshaw schrieb am 25.04.2015 um 10:57:
context of the main .pyx file, not even a safe one.
Stefan
> On Sat, Apr 25, 2015 at 1:44 AM, Jeroen Demeyer wrote:
>> On 2015-04-23 05:46, Robert Bradshaw wrote:
>>>
>>> it caches the parse of .pxd files (which
>>> otherwise must be re-parsed over and over, which gets expensive).
>>
>> Are you sure this happens? Maybe this is an idea which was never actually
>> implemented? I have looked carefully in the code and couldn't find anything
>> like this.
>
> It may very well be an unimplemented optimization.
And given that pxd files are currently being parsed and interpreted in the
>> On 2015-04-23 05:46, Robert Bradshaw wrote:
>>>
>>> it caches the parse of .pxd files (which
>>> otherwise must be re-parsed over and over, which gets expensive).
>>
>> Are you sure this happens? Maybe this is an idea which was never actually
>> implemented? I have looked carefully in the code and couldn't find anything
>> like this.
>
> It may very well be an unimplemented optimization.
context of the main .pyx file, not even a safe one.
Stefan
Robert Bradshaw
Apr 25, 2015, 5:45:41 AM4/25/15
to cython...@googlegroups.com
is independent of the context (or only inspects a few bits, like cpp
or not).
- Robert
Reply all
Reply to author
Forward
0 new messages