DDD/CQRS Vs Clean Architecture

Mohammed AMHEND
Uncle Bob,
What are the main differences and similarities between the clean architecture approach that you presented in the 7th episode and a DDD/CQRS architecture.
Cheers

Uncle Bob
- The Hexagonal architecture by Steve Freeman and Nat Pryce.
- The DDD architecture, by Eric Evans
- The DCI architecture by James Coplien and Trygve Reenskaug
- The Clean Architecture by me, based on Ivar Jacobson's BCE architecture.
The separations emphasized by DDD/CQRS are:
- Domain Model
- Commands
- Queries.
- Models (Domain objects)
- Interactions (Use cases)
- Contexts
- UI
- Mid-tier
- Domain
- UI
- Database
- Use Cases
- Domain
- DCI uses inheritance and traits
- Clean uses Dependency Inversion (polymorphism and interfaces)
- Hexagonal also uses Depencency Inversion, but with an emphasis on mocks.
- DDD/CQRS is less technically specific, though an example can be found in the TimeAndMoney example by Evans.
- application specific functions
- application independent functions
- input/output mechanisms
- storage mechanisms
- external interfaces
- frameworks.
Or to say this more succinctly, each evolves into a plugin model.
Mohammed AMHEND
I hope you'll decide someday to write a Clean Architecture book, that gathers all this stuff and gives much more detail about your Clean Architecture
Uncle Bob

Andreas Schaefer
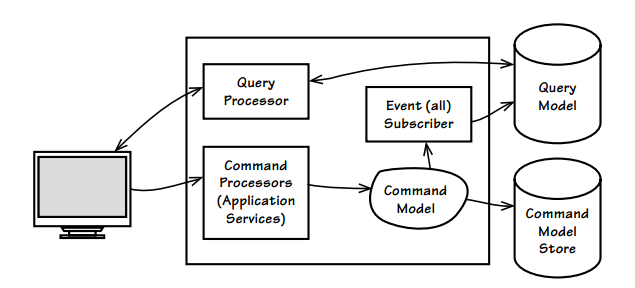
e.g. according to greg young you could simplify your read scenarios by having a "thin remote facade" (web server or web api I assume) that accesses data storage more or less directly, bypassing whole parts of the domain model (boundaries, entities, interactors, maybe even repository implementations!?), which essentially makes the domain model only being used in write contexts .. and potentially splitting apart n more scalable, dedicated read context databases that could store data in a read-optimized 1st normal form (opposed to the 3rd normal form of the write context database) .. assuming we're having relational databases (but surely this can be optimized for other db formats as well).
greg states that as we're practically dealing with relaxed consistency in read scenarios anyway, we can as well go this step further and having seperate read databases that get updated and normalized by event handlers when write events occur.
could this still be seen as clean?
I assume we'd need more corase grained tests for the read contexts, but I'd be fine with that.
what do you all think? UncleBob, I'd love to hear your thoughts on this as well.
regards
Andreas

Bennie Copeland

Sara ezati
Best,