Unable to append a new message to a topic in Camus.Getting "null record" error
37 views
Skip to first unread message

Ashish Dutt
Jul 20, 2015, 5:45:43 AM7/20/15
to camu...@googlegroups.com
Hello all,
I am using Camus to insert messages into Kafka which then I will upload to HDFS. I'm using CDH5.4 with parcels and JSON file format for data
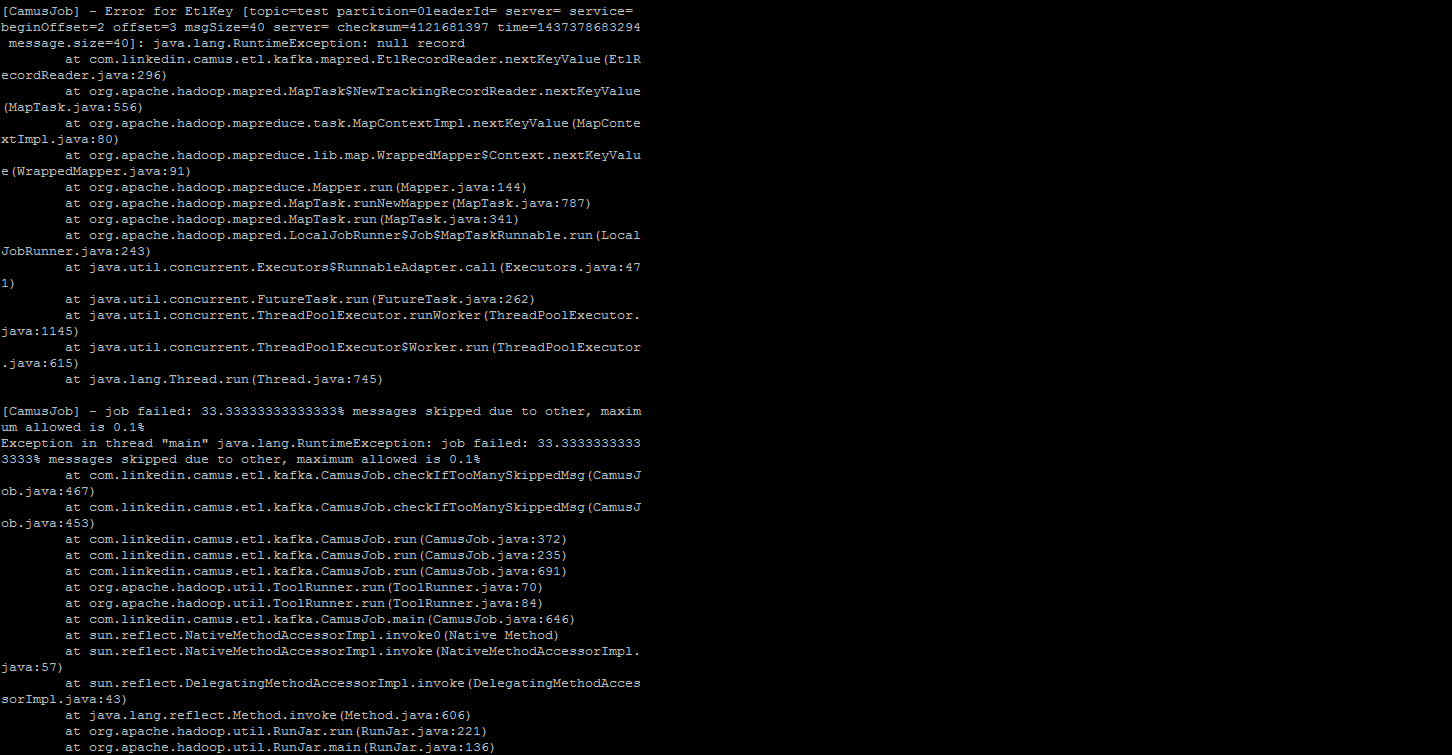
I am able to create a new topic and insert messages into it at one go but if I try to insert a new message or append a new message into the topic it fails giving me an error code: Java.lang.RunTimeException: Null record.
The camus.properties file is as follows
# Needed Camus properties, more cleanup to come
#
# Almost all properties have decent default properties. When in doubt, comment out the property.
#
# The job name.
camus.job.name=Camus Job
fs.defaultFS=hdfs://BDA01:8020
etl.record.writer.provider.class=com.linkedin.camus.etl.kafka.common.StringRecordWriterProvider
#etl.record.writer.provider.class=com.linkedin.camus.etl.kafka.common.AvroRecordWriterProvider
# final top-level data output directory, sub-directory will be dynamically created for each topic pulled
etl.destination.path=/user/kafka/
# HDFS location where you want to keep execution files, i.e. offsets, error logs, and count files
etl.execution.base.path=/user/kafka/exec
# where completed Camus job output directories are kept, usually a sub-dir in the base.path
etl.execution.history.path=/user/kafka/camus/exec/history
# Concrete implementation of the Encoder class to use (used by Kafka Audit, and thus optional for now)
#camus.message.encoder.class=com.linkedin.camus.etl.kafka.coders.DummyKafkaMessageEncoder
# Concrete implementation of the Decoder class to use.
# Out of the box options are:
# com.linkedin.camus.etl.kafka.coders.JsonStringMessageDecoder - Reads JSON events, and tries to extract timestamp.
# com.linkedin.camus.etl.kafka.coders.KafkaAvroMessageDecoder - Reads Avro events using a schema from a configured schema repository.
# com.linkedin.camus.etl.kafka.coders.LatestSchemaKafkaAvroMessageDecoder - Same, but converts event to latest schema for current topic.
camus.message.decoder.class=com.linkedin.camus.etl.kafka.coders.JsonStringMessageDecoder
#camus.message.decoder.class=com.linkedin.camus.etl.kafka.coders.LatestSchemaKafkaAvroMessageDecoder
# Decoder class can also be set on a per topic basis.
#camus.message.decoder.class.<topic-name>=com.your.custom.MessageDecoder
# Used by avro-based Decoders (KafkaAvroMessageDecoder and LatestSchemaKafkaAvroMessageDecoder) to use as their schema registry.
# Out of the box options are:
# com.linkedin.camus.schemaregistry.FileSchemaRegistry
# com.linkedin.camus.schemaregistry.MemorySchemaRegistry
# com.linkedin.camus.schemaregistry.AvroRestSchemaRegistry
# com.linkedin.camus.example.schemaregistry.DummySchemaRegistry
kafka.message.coder.schema.registry.class=com.linkedin.camus.example.schemaregistry.DummySchemaRegistry
# Used by JsonStringMessageDecoder when extracting the timestamp
# Choose the field that holds the time stamp (default "timestamp")
camus.message.timestamp.field=time
# What format is the timestamp in? Out of the box options are:
# "unix" or "unix_seconds": The value will be read as a long containing the seconds since epoc
# "unix_milliseconds": The value will be read as a long containing the milliseconds since epoc
# "ISO-8601": Timestamps will be fed directly into org.joda.time.DateTime constructor, which reads ISO-8601
# All other values will be fed into the java.text.SimpleDateFormat constructor, which will be used to parse the timestamps
# Default is "[dd/MMM/yyyy:HH:mm:ss Z]"
#camus.message.timestamp.format=yyyy-MM-dd_HH:mm:ss
camus.message.timestamp.format=ISO-8601
# Used by the committer to arrange .avro files into a partitioned scheme. This will be the default partitioner for all
# topic that do not have a partitioner specified.
# Out of the box options are (for all options see the source for configuration options):
# com.linkedin.camus.etl.kafka.partitioner.HourlyPartitioner, groups files in hourly directories
# com.linkedin.camus.etl.kafka.partitioner.DailyPartitioner, groups files in daily directories
# com.linkedin.camus.etl.kafka.partitioner.TimeBasedPartitioner, groups files in very configurable directories
# com.linkedin.camus.etl.kafka.partitioner.DefaultPartitioner, like HourlyPartitioner but less configurable
# com.linkedin.camus.etl.kafka.partitioner.TopicGroupingPartitioner
#etl.partitioner.class=com.linkedin.camus.etl.kafka.partitioner.HourlyPartitioner
# Partitioners can also be set on a per-topic basis. (Note though that configuration is currently not per-topic.)
#etl.partitioner.class.<topic-name>=com.your.custom.CustomPartitioner
# all files in this dir will be added to the distributed cache and placed on the classpath for hadoop tasks
# hdfs.default.classpath.dir=
# max hadoop tasks to use, each task can pull multiple topic partitions
mapred.map.tasks=30
# max historical time that will be pulled from each partition based on event timestamp
kafka.max.pull.hrs=1
# events with a timestamp older than this will be discarded.
kafka.max.historical.days=3
# Max minutes for each mapper to pull messages (-1 means no limit)
kafka.max.pull.minutes.per.task=-1
# if whitelist has values, only whitelisted topic are pulled. Nothing on the blacklist is pulled
#kafka.blacklist.topics=
kafka.whitelist.topics=test
log4j.configuration=true
# Name of the client as seen by kafka
kafka.client.name=camus
# The Kafka brokers to connect to, format: kafka.brokers=host1:port,host2:port,host3:port
kafka.brokers=BDA01:9092,BDA02:9092, BDA03:9092, BDA04:9092
# Fetch request parameters:
#kafka.fetch.buffer.size=
#kafka.fetch.request.correlationid=
#kafka.fetch.request.max.wait=
#kafka.fetch.request.min.bytes=
#kafka.timeout.value=
#Stops the mapper from getting inundated with Decoder exceptions for the same topic
#Default value is set to 10
max.decoder.exceptions.to.print=5
#Controls the submitting of counts to Kafka
#Default value set to true
post.tracking.counts.to.kafka=true
#monitoring.event.class=class.that.generates.record.to.submit.counts.to.kafka
# everything below this point can be ignored for the time being, will provide more documentation down the road
##########################
#kafka.monitor.tier=
#etl.counts.path=
kafka.monitor.time.granularity=10
#etl.hourly=hourly
#etdal.ily=daily
# Should we ignore events that cannot be decoded (exception thrown by MessageDecoder)?
# `false` will fail the job, `true` will silently drop the event.
etl.ignore.schema.errors=true
# configure output compression for deflate or snappy. Defaults to deflate
mapred.output.compress=false
#etl.output.codec=deflate
#etl.deflate.level=6
#etl.output.codec=snappy
etl.default.timezone=America/Los_Angeles
etl.output.file.time.partition.mins=60
etl.keep.count.files=false
etl.execution.history.max.of.quota=.8
# Configures a customer reporter which extends BaseReporter to send etl data
#etl.reporter.class
mapred.map.max.attempts=1
kafka.client.buffer.size=20971520
kafka.client.so.timeout=60000
#zookeeper.session.timeout=
#zookeeper.connection.timeout=
When I execute this command to append a new message to the topic I get this error in attached screenshot
hadoop jar /opt/camus/camus-example/target/camus-example-0.1.0-SNAPSHOT-shaded.jar com.linkedin.camus.etl.kafka.CamusJob -P /opt/camus/camus.properties
Please can anyone point me to the solution to how to fix it.
Thank you,
Ashish

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rodolfo Mijangos
Jul 20, 2015, 1:56:37 PM7/20/15
to camu...@googlegroups.com
Hello, try changing
camus.message.timestamp.field=time
to
camus.message.timestamp.field=timestamp
in your camus.properties
Ashish Dutt
Jul 21, 2015, 3:55:30 AM7/21/15
to Rodolfo Mijangos, camu...@googlegroups.com
Many thanks Rodolfo, that did the trick. So now the conf.properties file reads as following
However, now when I try to insert a new message to a topic using the command
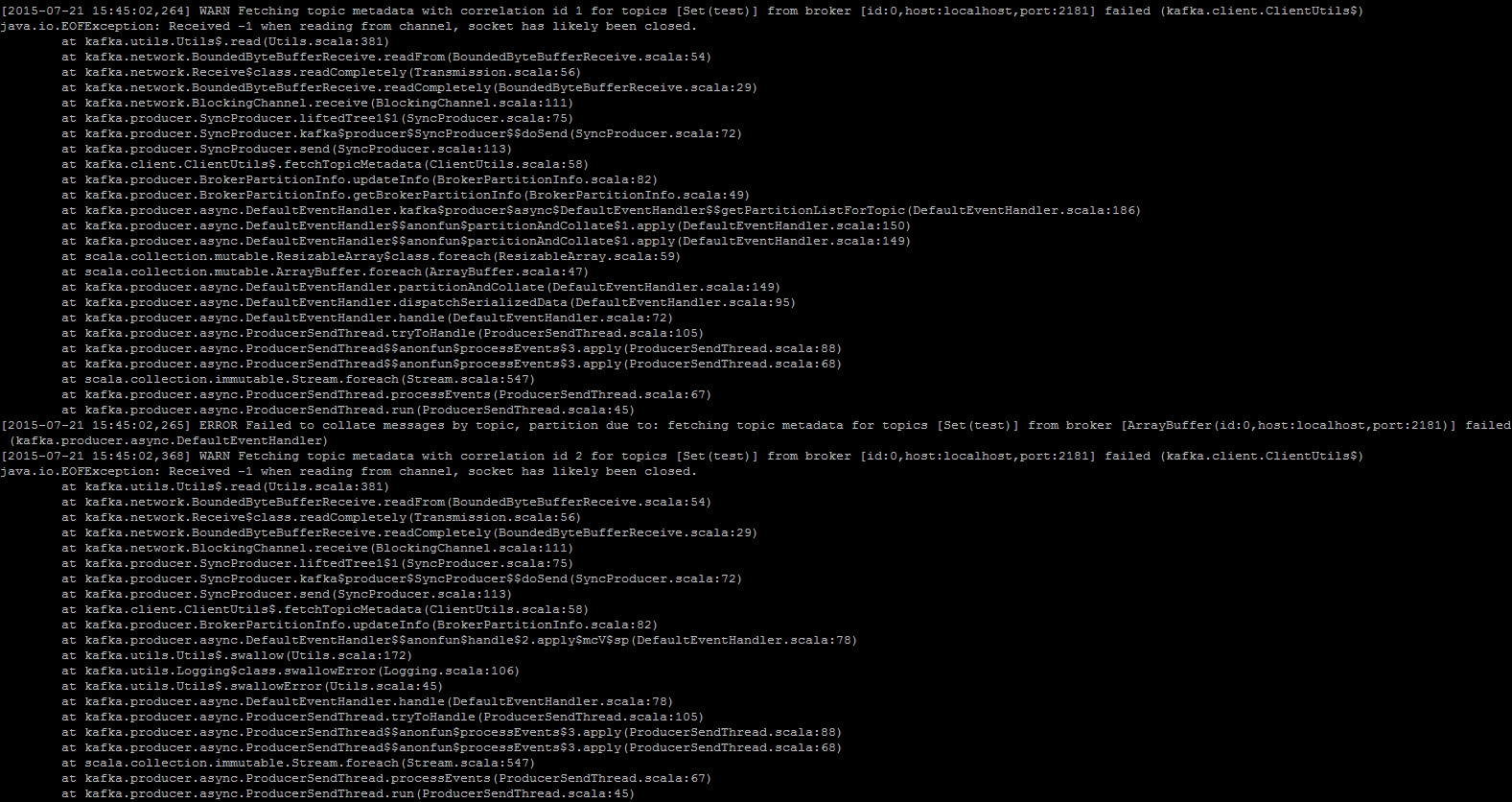
/opt/cloudera/parcels/KAFKA/bin/kafka-console-producer --broker-list localhost:2181 --topic test
I type a message like 'Testing message:80'
I get the following error message
"received -1 when reading from channel. Socket has likely been closed"
Attached are the screenshots for the same
Sincerely,
Ashish Dutt
--
You received this message because you are subscribed to a topic in the Google Groups "Camus - Kafka ETL for Hadoop" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/camus_etl/hJFLtaC_P8Q/unsubscribe.
To unsubscribe from this group and all its topics, send an email to camus_etl+...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
{kind=link}
{kind=link}
Reply all
Reply to author
Forward
0 new messages