Test labels for regression caffe, float not allowed?
1,655 views
Skip to first unread message

Devendra Mandan
Aug 2, 2015, 1:01:54 PM8/2/15
to Caffe Users
Hi,
I am doing regression using caffe, and my test.txt ans train.txt files are like this:
/home/foo/caffe/data/finetune/flickr/3860781056.jpg 2.0
/home/foo/caffe/data/finetune/flickr/4559004485.jpg 3.6
/home/foo/caffe/data/finetune/flickr/3208038920.jpg 3.2
/home/foo/caffe/data/finetune/flickr/6170430622.jpg 4.0
/home/foo/caffe/data/finetune/flickr/7508671542.jpg 2.7272
My problem is it seems caffe does not allow float labels like 2.0, when I use float labels while reading , for example the test.txt file caffe only
recognizes "a total of 1 images", which is wrong.
But when I for example change the 2.0 to 2 in the file and the following lines same, caffe now gives "a total of 2 images" implying that the float labels are responsible for the problem.
Can anyone help me here, to solve this problem, I definitely need to use float labels for regression, so does anyone know about a work around or solution for this? Thanks in advance.
I am doing regression using caffe, and my test.txt ans train.txt files are like this:
/home/foo/caffe/data/finetune/flickr/3860781056.jpg 2.0
/home/foo/caffe/data/finetune/flickr/4559004485.jpg 3.6
/home/foo/caffe/data/finetune/flickr/3208038920.jpg 3.2
/home/foo/caffe/data/finetune/flickr/6170430622.jpg 4.0
/home/foo/caffe/data/finetune/flickr/7508671542.jpg 2.7272
My problem is it seems caffe does not allow float labels like 2.0, when I use float labels while reading , for example the test.txt file caffe only
recognizes "a total of 1 images", which is wrong.
But when I for example change the 2.0 to 2 in the file and the following lines same, caffe now gives "a total of 2 images" implying that the float labels are responsible for the problem.
Can anyone help me here, to solve this problem, I definitely need to use float labels for regression, so does anyone know about a work around or solution for this? Thanks in advance.
Devendra Mandan
Aug 2, 2015, 1:06:44 PM8/2/15
to Caffe Users
Any help would be greatly appreciated.

Terry Chen
Aug 2, 2015, 2:19:01 PM8/2/15
to Caffe Users
I don;t know how to use float label, an alternative way to train the net is to use L2 loss to do regression task.
Devendra Mandan
Aug 2, 2015, 2:24:38 PM8/2/15
to Caffe Users
Thanks a lot for the reply, but i wish to use float labels. Thanks again :)

Axel Angel
Aug 2, 2015, 2:35:58 PM8/2/15
to Caffe Users
The problem comes from the DataImage layer which only accepts integer. You can probably patch into the code or implement your own layer for parsing. Most people switch to HDF5 to do regression. There are lots of posts on the subject, give it a try.
Devendra Mandan
Aug 2, 2015, 3:11:17 PM8/2/15
to Caffe Users
Can you please explain, how can i patch it into the code, I am sort of a noob :)

rorschachhb
Aug 3, 2015, 4:35:09 AM8/3/15
to Caffe Users
My suggestion is to use 2 data layers, you can write your images and labels in different lmdb files and create your .prototxt file like this:
在 2015年8月3日星期一 UTC+8上午3:11:17,Devendra Mandan写道:
layer {
name: "data1"
type: "Data"
top: "data"
data_param {
source: "examples/you_example/train_1_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "data2"
type: "Data"
top: "label"
data_param {
source: "examples/your_example/train_2_lmdb"
batch_size: 100
backend: LMDB
}
}
in train_2_lmdb your labels are treated as data, so they don't have to be integer.
在 2015年8月3日星期一 UTC+8上午3:11:17,Devendra Mandan写道:

npit
Aug 3, 2015, 4:45:45 AM8/3/15
to Caffe Users
Don't LMDB data have to be 8-bit unsigned integer though?
rorschachhb
Aug 3, 2015, 5:09:50 AM8/3/15
to Caffe Users
According to https://github.com/BVLC/caffe/issues/2116, you can put any type of float data in leveldb or lmdb.
I just did a little experiment by converting my image data from int to float, turned out that the net converged perfectly.
在 2015年8月3日星期一 UTC+8下午4:45:45,npit写道:
在 2015年8月3日星期一 UTC+8下午4:45:45,npit写道:
npit
Aug 3, 2015, 5:40:32 AM8/3/15
to Caffe Users
Thanks for the info.

Nanne van Noord
Aug 3, 2015, 8:31:21 AM8/3/15
to Caffe Users
I found that the data field of the datum object only stores integers, while it does accept floats it only stores the integer part. You can however store floats in the datum.float_data field.
I wrote an inelegant script ( https://gist.github.com/Nanne/6f50ca5dcab3b2c565e5 ) that takes a TXT file with <filename> <vector of floats>'s and stores the vectors as datums with float_data in an db with the filenames as key (identical to convert_imageset). This doesn't store the imagedata, but as you mentioned it can serve as the second lmdb with just the labels.
Axel Angel
Aug 3, 2015, 1:44:11 PM8/3/15
to Caffe Users
If you want reliability I would follow what was said above. If you want to adventure yourself a bit, I made a very simple PR that allows to use floating point for the label (WIP):
Devendra Mandan
Aug 8, 2015, 2:52:58 PM8/8/15
to Caffe Users
Hi Axel, just wanted to ask, can I use the 2 commits you made, would they be enough and correct or would I have to do something more. (I am feeling a bit adventurous, dare I say.)
Axel Angel
Aug 9, 2015, 4:37:13 AM8/9/15
to Caffe Users
There is only one commit actually. But yes, it should suffice to do regression with one "float" label. You need to make sure you're using a suitable loss function like the Euclidian Loss and revert my patch if you need to use again "int" label with Softmax. Test and tell us how it goes, the loss should decreases and converges.
Devendra Mandan
Aug 9, 2015, 5:22:06 AM8/9/15
to Caffe Users
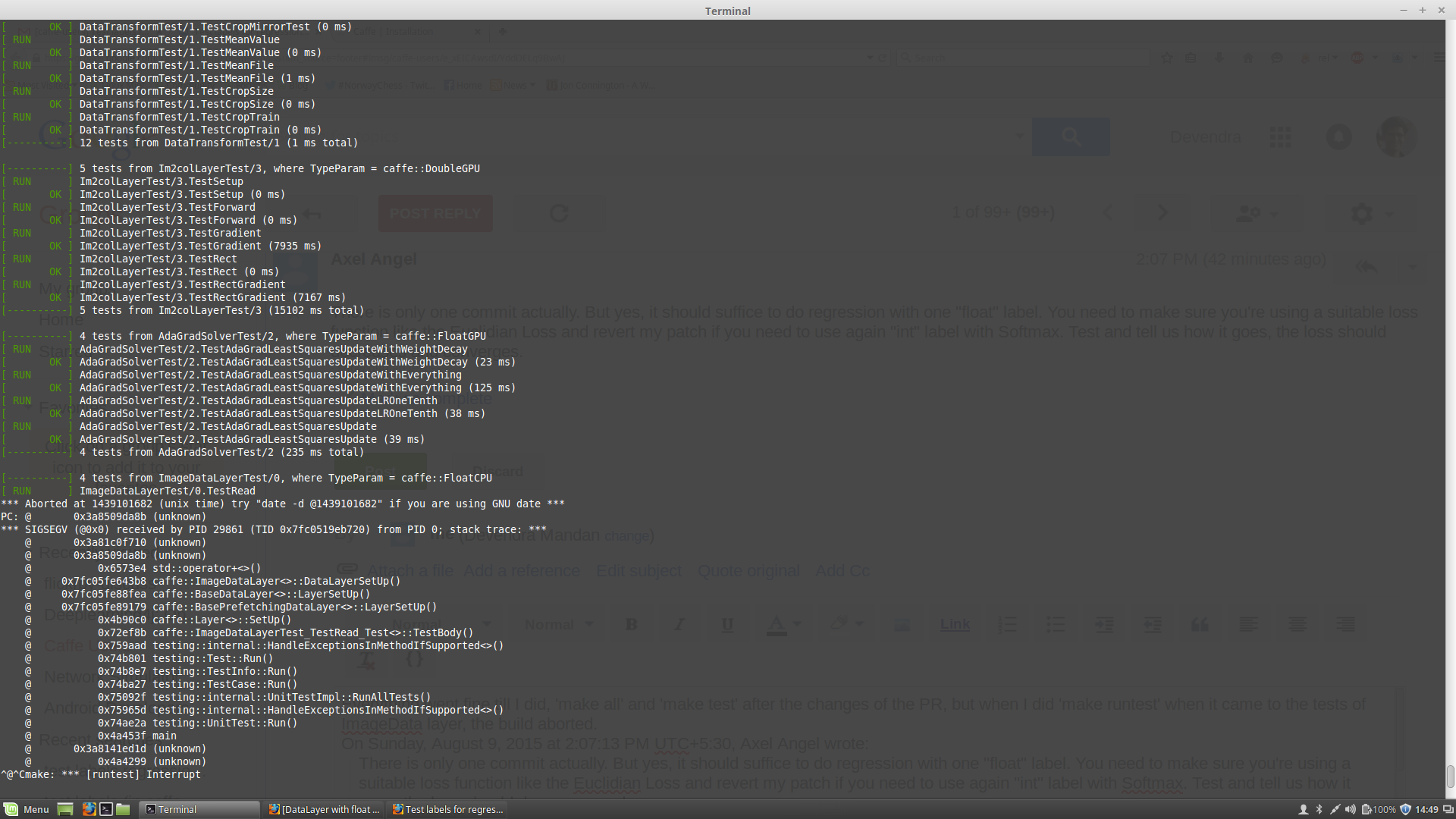
Everything went fine till I did, 'make all' and 'make test' after the changes of the PR, but when I did 'make runtest' when it came to the tests of ImageData layer, the build aborted as shown in the screenshot.
Axel Angel
Aug 9, 2015, 7:57:59 AM8/9/15
to Caffe Users
Well, tests won't pass as described in my pull request. It breaks the Softmax layers but you won't use it.
Message has been deleted
Devendra Mandan
Aug 29, 2015, 5:20:49 PM8/29/15
to Caffe Users
Hi everyone, sorry for being late, but I was facing some problems. The net did converge. Thanks Axel for the PR. If you can please look at the
continuation in a separate topic
Ehsan
Sep 4, 2015, 6:16:26 PM9/4/15
to Caffe Users
Hello all,
I am also trying use caffe for regression. I want to use rorschachhb's suggestion of using two 2 data layers. I used Nanne's C++ code (https://gist.github.com/Nanne/6f50ca5dcab3b2c565e5) to create a label lmdb file which went through (thanks Nanne). The usage is "convert_vector [FLAGS] LISTFILE DB_NAME". I left [FLAGS] blank and the list file is a txt file where each line is like:
folder/image_filename 0.54
My question is how to generate the data lmdb? Should I use "convert_imageset" to generate the data lmdb? I tried to do so with an input text file where each line was just the file names with no label but "convert_imageset" reported "A total of 0 images" and did not put any data in the data lmdb file. Can I use a dummy label for each image file without screwing things up and use "convert_imageset"? Please help.
Best,
Ehsan

Ihsan Ullah
Sep 6, 2015, 8:29:49 AM9/6/15
to Caffe Users
You guys can use hdf5 files. That is a good solution for regression case.

{kind=link}
林可昀
Apr 13, 2016, 5:33:54 AM4/13/16
to Caffe Users
Hi all,
If you want to use ImageDataLayer with "floating value" label input, you may
modify this line: https://github.com/BVLC/caffe/blob/master/src/caffe/layers/image_data_layer.cpp#L41
from int label; to double lable;
and modify this line: https://github.com/BVLC/caffe/blob/master/include/caffe/layers/image_data_layer.hpp#L40
from vector<std::pair<std::string, int> > lines_; to vector<std::pair<std::string, double> > lines_;
enjoy!
Kevin
Devendra Mandan於 2015年8月3日星期一 UTC+8上午1時01分54秒寫道:
If you want to use ImageDataLayer with "floating value" label input, you may
modify this line: https://github.com/BVLC/caffe/blob/master/src/caffe/layers/image_data_layer.cpp#L41
from int label; to double lable;
and modify this line: https://github.com/BVLC/caffe/blob/master/include/caffe/layers/image_data_layer.hpp#L40
from vector<std::pair<std::string, int> > lines_; to vector<std::pair<std::string, double> > lines_;
enjoy!
Kevin
Devendra Mandan於 2015年8月3日星期一 UTC+8上午1時01分54秒寫道:
Reply all
Reply to author
Forward
0 new messages