Interaction between BatchGraph, graph.commit/shutdown, and JVM heap.
197 views
Skip to first unread message

Verdi March
Aug 20, 2014, 7:34:14 AM8/20/14
to aureliu...@googlegroups.com
Hi,
In my experiments with Titan 0.4.4 with the BerkeleyDB backend, I found that loading many nodes take large JVM heap (there're cases I needed 16GB only to load 2.4M nodes with two node properties).
After many rounds of experiments, I finally found that I need to combine two patterns: BatchGraph and reopen graph connection (I'll explain what I mean by reopen). While I'm happy that this combination works, I don't understand why.
To demonstrate, I devise a simple test to add 2M nodes, committing every 400k nodes (so there're 5 commits). The pseudocode is as follows:
/** START pseudocode **/same as (2) but don't wrap in BatchGraph.
open graph
for (i in 1..2000000) {
v = graph.addVertex(i); v.setProperty('keyA', i); v.setProperty('element_type', 'node');
if (i % 400000 == 0) {
commit;
System.gc(); //purposely
}
}
/** END pseudocode **/
Based on the above pseudocode, I have four test variations:
(1) reopen + batch: use BatchGraph, but replace commit with [shutdown graph, open & wrap in BatchGraph].
(2) commit + batch: the pseudocode, but by using BatchGraph
(3) commit-nobatch: same as (1) but don't wrap with BatchGraph
(4) reopen-nobatch: same as (2) but don't wrap in BatchGraph.
The following test results show that (1) is the best approach. In these tests, the JVM heap is configured as -Xms256m -Xmx512m (note: purposely kept small). For each approach, I show the time for each 400k commits (hence, there're five timings for each approach).
(1) reopen + batch: 20s, 17s, 17s, 17s, 17s
(2) commit + batch: 15s, 12s, 28s, 59s, 101s
(3) reopen-nobatch: 25s, 21s, "Could not commit transaction due to exception during persistence"
(4) commit-nobatch: 19s, "Could not commit transaction due to exception during persistence"
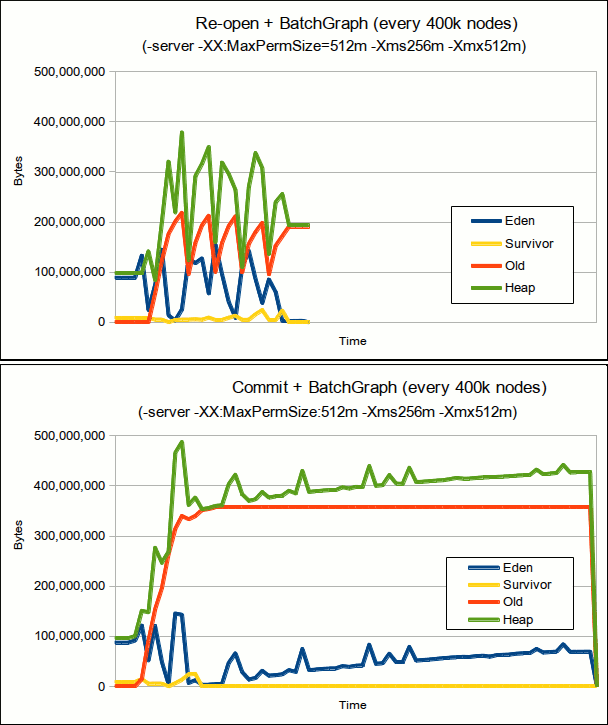
With approach (1), the time per "commit" are almost stable which indicates good usage of JVM heap. Looking at the heap usage using JConsole, I clearly identify five cycles in the heap chart. In each cycle, the heap consumption steadily increases then decreases after the "commit".
With approach (2), the time/commit increases and CPU utilization spikes. These are symptoms of full heaps and overhead of garbage collection. JConsole further confirms suspicions, that JVM heap consumption steadily increases approaching the limit.
The remaining approaches, (3) & (4), throw transaction exceptions (even with storage.cache-percentage=80), and JConsole shows JVM heap consumption steadily increases similar to the pattern in (1).
Those tests bring me to my questions. First, what's the difference between commit through BatchGraph vs commit without BatchGraph? And secondly, why does "commit" by reopen (especially combined with BatchGraph) free up JVM heap afterwards?
Regards,
Verdi
Verdi March
Aug 21, 2014, 10:56:39 PM8/21/14
to aureliu...@googlegroups.com
Hi,
Still the same situation with Titan-0.5.0. The graph still needs to be closed & reopen now-and-then, to prevent memory-leak.
This time I attach the Gremlin scripts (for Titan-0.5.0), and also the memory comparison between reopen+batchgraph vs commit+batchgraph. Perhaps somebody may want to replicate the tests.
Another observation is a performance regression:
- [titan-0.4.4] reopen+batch: 20s, 17s, 17s, 17s, 17s
- [titan-0.5.0] reopen+batch: 35s, 35s, 34s, 34s, 35s
Regards,
Verdi

{kind=link}
Stephen Mallette
Aug 22, 2014, 7:06:33 AM8/22/14
to aureliu...@googlegroups.com
> First, what's the difference between commit through BatchGraph vs commit without BatchGraph?
I'm not clear if you are doing it or not, but you should only call commit() at the end of all your loading if using BatchGraph. BatchGraph is commiting for you at the interval you define and calling commit explicitly can get things messed up (unless you are calling it to mark your loading as complete). That said, I can't explain what's going on between your BatchGraph approach and non-BatchGraph approach - you mentioned transaction exception gets thrown - do you have the stack trace?
And secondly, why does "commit" by reopen (especially combined with BatchGraph) free up JVM heap afterwards?
To enhance performance when loading edges, BatchGraph maintains an in-memory cache of vertices and identifiers. When you commit/rewrap with BatchGraph you are killing that cache (which would be bad if you were going to later load edges). You should probably read the BatchGraph wiki page in its entirety for more details: https://github.com/tinkerpop/blueprints/wiki/Batch-Implementation
To view this discussion on the web visit https://groups.google.com/d/msgid/aureliusgraphs/9513c172-aff9-4dec-8dc9-d1d282a30e95%40googlegroups.com.--
You received this message because you are subscribed to the Google Groups "Aurelius" group.
To unsubscribe from this group and stop receiving emails from it, send an email to aureliusgraph...@googlegroups.com.
Verdi March
Aug 25, 2014, 2:20:06 AM8/25/14
to aureliu...@googlegroups.com
Hi Stephen,
I understand the intention of BatchGraph, and that's why I was (pleasantly) surprised that it actually reduces the heap pressure.
Regarding your point that my test cases destroy the cache, actually that's intentional for demonstration purposes. In addition, explicit commits (or reopen) will coincide with BatchGraph's internal commits because BatchGraph's batch size is 1000, so the explicit commit or reopen (every 400k nodes) will occur immediately after the 400th BatchGraph's internal commit.
As for the exception trace that occurs when not wrapping with BatchGraph:
13:55:56 ERROR com.thinkaurelius.titan.graphdb.database.StandardTitanGraph - Could not commit transaction [2] due to exception
java.lang.OutOfMemoryError: Java heap space
at java.nio.HeapByteBuffer.<init>(HeapByteBuffer.java:57)
at java.nio.ByteBuffer.allocate(ByteBuffer.java:331)
at com.thinkaurelius.titan.diskstorage.util.WriteByteBuffer.<init>(WriteByteBuffer.java:28)
at com.thinkaurelius.titan.graphdb.database.serialize.StandardSerializer$StandardDataOutput.<init>(StandardSerializer.java:96)
at com.thinkaurelius.titan.graphdb.database.serialize.StandardSerializer$StandardDataOutput.<init>(StandardSerializer.java:93)
at com.thinkaurelius.titan.graphdb.database.serialize.StandardSerializer.getDataOutput(StandardSerializer.java:90)
at com.thinkaurelius.titan.graphdb.database.IndexSerializer.getIndexKey(IndexSerializer.java:693)
at com.thinkaurelius.titan.graphdb.database.IndexSerializer.getIndexKey(IndexSerializer.java:689)
at com.thinkaurelius.titan.graphdb.database.IndexSerializer.getIndexUpdates(IndexSerializer.java:297)
at com.thinkaurelius.titan.graphdb.database.StandardTitanGraph.prepareCommit(StandardTitanGraph.java:447)
at com.thinkaurelius.titan.graphdb.database.StandardTitanGraph.commit(StandardTitanGraph.java:609)
at com.thinkaurelius.titan.graphdb.transaction.StandardTitanTx.commit(StandardTitanTx.java:1228)
at com.thinkaurelius.titan.graphdb.blueprints.TitanBlueprintsGraph.commit(TitanBlueprintsGraph.java:57)
at com.tinkerpop.blueprints.TransactionalGraph$commit.call(Unknown Source)
at org.codehaus.groovy.runtime.callsite.CallSiteArray.defaultCall(CallSiteArray.java:42)
at org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:108)
at org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:112)
at Script1.run(Script1.groovy:28)
at com.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.eval(GremlinGroovyScriptEngine.java:219)
at com.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.eval(GremlinGroovyScriptEngine.java:90)
at com.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.eval(GremlinGroovyScriptEngine.java:85)
at javax.script.AbstractScriptEngine.eval(AbstractScriptEngine.java:212)
at com.thinkaurelius.titan.hadoop.tinkerpop.gremlin.ScriptExecutor.evaluate(ScriptExecutor.java:35)
at com.thinkaurelius.titan.hadoop.tinkerpop.gremlin.ScriptExecutor.main(ScriptExecutor.java:20)
com.thinkaurelius.titan.core.TitanException: Could not commit transaction due to exception during persistence
at com.thinkaurelius.titan.graphdb.transaction.StandardTitanTx.commit(StandardTitanTx.java:1239)
at com.thinkaurelius.titan.graphdb.blueprints.TitanBlueprintsGraph.commit(TitanBlueprintsGraph.java:57)
at com.tinkerpop.blueprints.TransactionalGraph$commit.call(Unknown Source)
at org.codehaus.groovy.runtime.callsite.CallSiteArray.defaultCall(CallSiteArray.java:42)
at org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:108)
at org.codehaus.groovy.runtime.callsite.AbstractCallSite.call(AbstractCallSite.java:112)
at Script1.run(Script1.groovy:28)
at com.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.eval(GremlinGroovyScriptEngine.java:219)
at com.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.eval(GremlinGroovyScriptEngine.java:90)
at com.tinkerpop.gremlin.groovy.jsr223.GremlinGroovyScriptEngine.eval(GremlinGroovyScriptEngine.java:85)
at javax.script.AbstractScriptEngine.eval(AbstractScriptEngine.java:212)
at com.thinkaurelius.titan.hadoop.tinkerpop.gremlin.ScriptExecutor.evaluate(ScriptExecutor.java:35)
at com.thinkaurelius.titan.hadoop.tinkerpop.gremlin.ScriptExecutor.main(ScriptExecutor.java:20)
Caused by: com.thinkaurelius.titan.core.TitanException: Unexpected exception
at com.thinkaurelius.titan.graphdb.database.StandardTitanGraph.commit(StandardTitanGraph.java:694)
at com.thinkaurelius.titan.graphdb.transaction.StandardTitanTx.commit(StandardTitanTx.java:1228)
... 12 more
Caused by: java.lang.OutOfMemoryError: Java heap space
at java.nio.HeapByteBuffer.<init>(HeapByteBuffer.java:57)
at java.nio.ByteBuffer.allocate(ByteBuffer.java:331)
at com.thinkaurelius.titan.diskstorage.util.WriteByteBuffer.<init>(WriteByteBuffer.java:28)
at com.thinkaurelius.titan.graphdb.database.serialize.StandardSerializer$StandardDataOutput.<init>(StandardSerializer.java:96)
at com.thinkaurelius.titan.graphdb.database.serialize.StandardSerializer$StandardDataOutput.<init>(StandardSerializer.java:93)
at com.thinkaurelius.titan.graphdb.database.serialize.StandardSerializer.getDataOutput(StandardSerializer.java:90)
at com.thinkaurelius.titan.graphdb.database.IndexSerializer.getIndexKey(IndexSerializer.java:693)
at com.thinkaurelius.titan.graphdb.database.IndexSerializer.getIndexKey(IndexSerializer.java:689)
at com.thinkaurelius.titan.graphdb.database.IndexSerializer.getIndexUpdates(IndexSerializer.java:297)
at com.thinkaurelius.titan.graphdb.database.StandardTitanGraph.prepareCommit(StandardTitanGraph.java:447)
at com.thinkaurelius.titan.graphdb.database.StandardTitanGraph.commit(StandardTitanGraph.java:609)
... 13 more
javax.script.ScriptException: com.thinkaurelius.titan.core.TitanException: Could not commit transaction due to exception during persistence
^C
Regards,
Verdi
Verdi March
Aug 25, 2014, 2:56:27 AM8/25/14
to aureliu...@googlegroups.com
Is it possible that the reopen works better instead of commit, is because it allows BatchGraph's cache of id mappings to be garbage collected?
My hypothesis is that even though BatchGraph commits every BATCH_SIZE, but the mapping of external-to-internal id are always kept until the graph is closed. Hence, the reason why g.commit() doesn't free up more memory, while g.shutdown() does.
Regards,
Verdi
Verdi March
Aug 25, 2014, 4:31:10 AM8/25/14
to aureliu...@googlegroups.com
Hi,
Sorry to keep adding, but after a little bit more work, indeed it seems that the BatchGraph's id map is what steadily increases memory usage.
To demonstrate, I just re-wrap the base graph in a new batch graph every now and then. The old batch graph will be garbage collected (together with its id map), which then frees up memory.
I further took a glance BatchGraph's cache, and found that the id hash map is indeed always kept in memory.
I was wondering, if this is really the case, could it be possible the batchgraph wiki to mention about the memory implication of id map, especially when adding so many nodes or edges.
Regards,
Verdi
Stephen Mallette
Aug 25, 2014, 8:52:54 AM8/25/14
to aureliu...@googlegroups.com
It seem you understand it clearly now, though I would add that the cache is pretty efficient despite it being kept in memory. It only keeps vertex references during a "batch" after which they are converted to their identifiers. That said, that if you choose to generate a "large" graph with BatchGraph, you need to configure your loader with sufficient memory to cover that. The wiki already states:
"BatchGraph maintains a mapping from the external vertex ids, in our example the first two entries in the String array describing the edge, to the internal vertex ids assigned by the wrapped graph database. Since this mapping is maintained in memory, it is potentially much faster than the database index."
If you think it should say something more please let me know and we can consider adjusting the wiki.
To view this discussion on the web visit https://groups.google.com/d/msgid/aureliusgraphs/bea32f84-cf71-47a9-abdf-cf931d01cea9%40googlegroups.com.
Message has been deleted
Verdi March
Aug 26, 2014, 6:06:54 AM8/26/14
to aureliu...@googlegroups.com
Hi Stephen,
Regards,
perhaps it could be something along the line that BatchGraph's memory requirement is still linear to the number of elements added (regardless of batch size), because BatchGraph never expire id map entries (unlike the cached vertices/edges). The id map can be released only when shutdown(), or when the BatchGraph object is eligible for garbage collection. Thus, while batching reduces the transactional memory size, but BatchGraph now shifts the memory requirement to the id map. In fact, the asymptotic memory requirement is similar to the issue BatchGraph tries to address in the first place which is "loading all these edges in a single transaction is likely to exhaust main memory". I understand id compression and so on helps reducing memory usage, but growth is still linear to the number of elements added.
Some 2cents more: is it possible to make the id map to be like a typical cache when NOT loading from scratch? In other words, for BatchGraph to implement expiration mechanisms for id map entries? When not loading from scratch, BatchGraph is allowed to hit the base graph anyway to ensure no id collision. Therefore, BatchGraph can re-load expired id from the graph database. My apology in advance if this is more suitable for tinkerpop/blueprint discussions.
Regards,
Verdi
Stephen Mallette
Aug 26, 2014, 6:18:56 AM8/26/14
to aureliu...@googlegroups.com
Yes - this is probably a discussion more suited to gremlin-users, but that's ok. I suppose there could be features to BatchGraph that allowed for an expiring cache with lookups to hit the database to renew cached elements/ids that expired. It just wasn't implemented that way. In my own use of BatchGraph, I've found it to comfortably load well into the tens of millions of elements quite nicely and I've been more than happy to give it tons of Xmx to do it. For my purposes speed has generally outweighed the need to be efficient with memory usage. Once my data load grows larger than what i'm will to accept I'll switch to Faunus/titan-hadoop (or possibly a custom loader written in groovy).
I don't think we will change BatchGraph for TinkerPop 2.x, but perhaps an expiring cache might be something for TinkerPop3. I'm not sure it's worth it though, given the loading patterns that we typically adhere to that I described above.
On Tue, Aug 26, 2014 at 6:06 AM, Verdi March <verdi...@gmail.com> wrote:
Hi Stephen,
perhaps it could be something along the line that BatchGraph's memory requirement is still linear to the number of elements added (regardless of batch size), because BatchGraph never expire id map entries (unlike the cached vertices/edges). The id map can be released only when shutdown(), or when the BatchGraph object is eligible for garbage collection. Thus, while batching reduces the transactional memory size, but BatchGraph now shifts the memory requirement to the id map. In fact, the asymptotic memory requirement is similar to the issue BatchGraph tries to address in the first place which is "loading all these edges in a single transaction is likely to exhaust main memory". I understand id compression and so on helps reducing memory usage, but growth is still linear to the number of elements added.
Some 2cents more: is it to implement id map to be like a typical cache when NOT loading from scratch? In other words, for BatchGraph to implement expiration mechanisms for id map entries? When not loading from scratch, BatchGraph is allowed to hit the base graph anyway to ensure no id collision. Therefore, BatchGraph can re-load expired id from the graph database. My apology in advance if this is more suitable for tinkerpop/blueprint discussions.
Regards,Verdi
To view this discussion on the web visit https://groups.google.com/d/msgid/aureliusgraphs/c396a0a8-d7ea-48ca-9af6-7e3f337e1066%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages