Alluxio copyFromLocal fails
151 views
Skip to first unread message

Krishnaprasad
Jun 22, 2016, 8:44:20 AM6/22/16
to Alluxio Users
Hai,
I'm trying to run a MR job on alluxio. My Environment set up follows,
4 node hadoop cluster (version 2.6.4)
5 node alluxio set up (1 master 5 workers, version 1.2.0 build)
Please find below Summary from web console,
Each hdfs node has 5.12 GB MEM capacity for alluxio worker and one extra node with 10GB memory for alluxio worker. Total 30.49GB memory available in the cluster.
I'm trying to load a 25GB file from local machine to alluxio in master machine (worker memory 5.12 GB) using the following command,
alluxio fs copyFromLocal testData.csv /wordcount
The command fails to load the data to alluxio by saying the following error,
Failed to cache: Unable to request space from worker
Is it trying to load the data to the local worker alone.? What I expect was it will distribute the data in the 30GB memory cluster like what hdfs does.
If it loads only to the local worker memory, then is there a way to load a large sized file (larger than local worker memory) to alluxio memory ?
I was planned to run a MR job on the 25GB file after loading it into alluxio. Is it possible ?
Also How can I set the eviction policy, like evict if memory exceeds 80% ?
Please help ?
Thanks,
Krishnaprasad.
I'm trying to run a MR job on alluxio. My Environment set up follows,
4 node hadoop cluster (version 2.6.4)
5 node alluxio set up (1 master 5 workers, version 1.2.0 build)
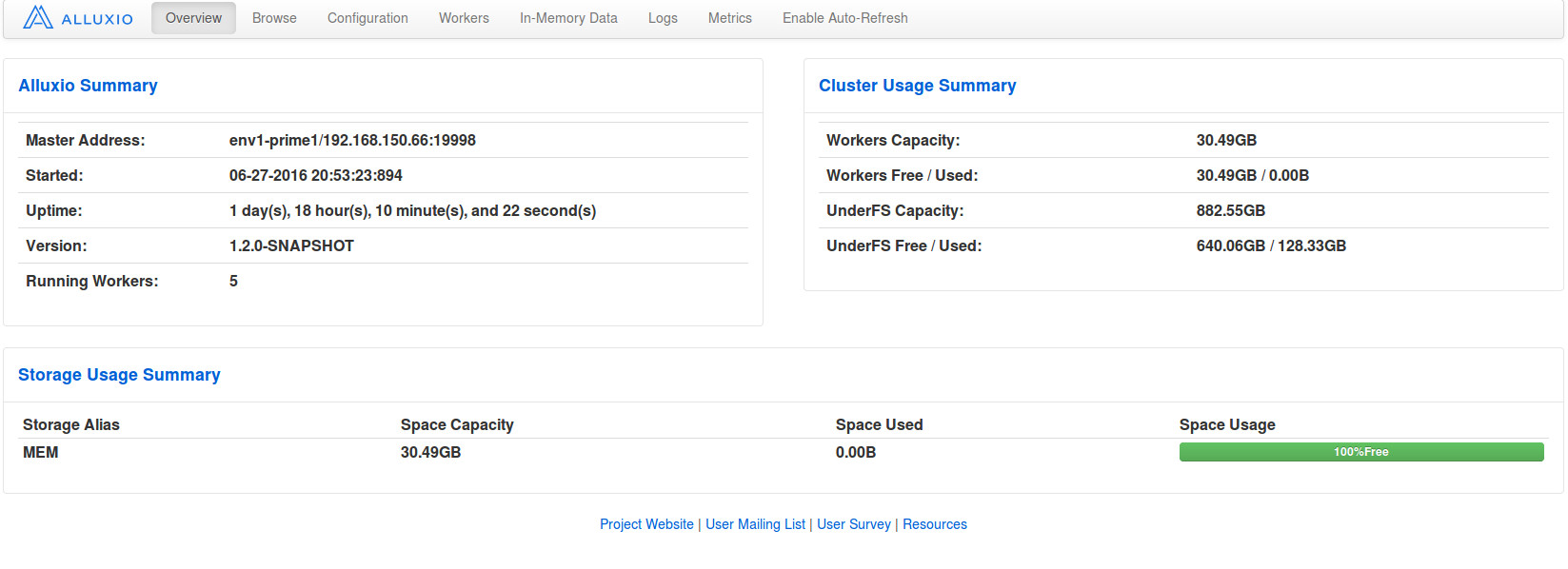
Please find below Summary from web console,
| Master Address: | env1-prime1/192.168.150.66:19998 |
|---|---|
| Started: | 06-22-2016 15:24:14:717 |
| Uptime: | 0 day(s), 2 hour(s), 23 minute(s), and 0 second(s) |
| Version: | 1.2.0-SNAPSHOT |
| Running Workers: | 5 |
| Workers Capacity: | 30.49GB |
|---|---|
| Workers Free / Used: | 30.49GB / 0.00B |
| UnderFS Capacity: | 882.55GB |
| UnderFS Free / Used: | 691.89GB / 126.28GB |
| Storage Alias | Space Capacity | Space Used | Space Usage |
|---|---|---|---|
| MEM | 30.49GB | 0.00B |
100%Free
|
Each hdfs node has 5.12 GB MEM capacity for alluxio worker and one extra node with 10GB memory for alluxio worker. Total 30.49GB memory available in the cluster.
I'm trying to load a 25GB file from local machine to alluxio in master machine (worker memory 5.12 GB) using the following command,
alluxio fs copyFromLocal testData.csv /wordcount
The command fails to load the data to alluxio by saying the following error,
Failed to cache: Unable to request space from worker
Is it trying to load the data to the local worker alone.? What I expect was it will distribute the data in the 30GB memory cluster like what hdfs does.
If it loads only to the local worker memory, then is there a way to load a large sized file (larger than local worker memory) to alluxio memory ?
I was planned to run a MR job on the 25GB file after loading it into alluxio. Is it possible ?
Also How can I set the eviction policy, like evict if memory exceeds 80% ?
Please help ?
Thanks,
Krishnaprasad.
Yupeng Fu
Jun 22, 2016, 3:05:36 PM6/22/16
to Krishnaprasad, Alluxio Users
Hi Krishnaprasad,
By default, Alluxio uses the location policy that always tries to store the block into the local worker. And when the local worker is full, it first tries to evict the blocks on the same node.
To workaround this limitation, you can try to change the location policy to RoundRobinPolicy (http://www.alluxio.org/documentation/v1.0.0/en/File-System-API.html#location-policy).
Hope this helps.
Cheers,
--
You received this message because you are subscribed to the Google Groups "Alluxio Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to alluxio-user...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Krishnaprasad A S
Jun 23, 2016, 5:46:50 AM6/23/16
to Yupeng Fu, Alluxio Users
Hi Yupeng,
Thanks for the reply.
If it try to store in the same worker memory, then why it's not evicting data when memory becomes full, other than throwing error?
Also how can I set the location property to round robin in the cluster, ? Or is it possible only through the API ?Thanks for the reply.
If it try to store in the same worker memory, then why it's not evicting data when memory becomes full, other than throwing error?
I can see the configuration from the web console of my cluster,
alluxio.user.file.write.location.policy.class alluxio.client.file.policy.LocalFirstPolicy
alluxio.user.file.write.location.policy.class alluxio.client.file.policy.LocalFirstPolicy
Thanks in advance.
--
Krishnaprasad A S
Lead Engineer
Flytxt
Skype: krishnaprasadas
M: +91 8907209454 | O: +91 471.3082753 | F: +91 471.2700202
www.flytxt.com | Visit our blog | Follow us | Connect on LinkedIn
Lead Engineer
Flytxt
Skype: krishnaprasadas
M: +91 8907209454 | O: +91 471.3082753 | F: +91 471.2700202
www.flytxt.com | Visit our blog | Follow us | Connect on LinkedIn
Yupeng Fu
Jun 23, 2016, 1:49:50 PM6/23/16
to Krishnaprasad A S, Alluxio Users
Hi Krishnaprasad,
No block is evicted because the file has not been fully written yet, and therefore the blocks are locked and cannot be committed.
To set the config, you follow the instructions at http://www.alluxio.org/documentation/v1.0.0/en/Configuration-Settings.html
Hope this helps,
Krishnaprasad A S
Jun 27, 2016, 1:11:10 PM6/27/16
to Yupeng Fu, Alluxio Users
Thanks for your help,
I changed the location policy to round robin and the file copied successfully.16/06/27 21:36:10 INFO mapreduce.Job: Task Id : attempt_1466750827272_0007_m_000002_0, Status : FAILED
Error: java.io.IOException: Block 67108865 is not available in Alluxio
Yupeng Fu
Jun 27, 2016, 8:30:39 PM6/27/16
to Krishnaprasad A S, Alluxio Users
Can you check the Web UI to see if the file is fully loaded into Alluxio? Also, could you paste the logs in Alluxio?
Thanks,
Krishnaprasad A S
Jun 29, 2016, 6:17:41 AM6/29/16
to Yupeng Fu, Alluxio Users
Hi Yupeng Fu,
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Yupeng Fu
Jun 29, 2016, 5:48:35 PM6/29/16
to Krishnaprasad A S, Alluxio Users
Hi,
Based on your screenshots and the logs, I think what possibly happened was the MR job generated some temp data and put that into Alluxio, which evicted the blocks in memory. To verify this hypothesis, you can persist the file or lock the blocks, and rerun the job.
Hope this helps,
Krishnaprasad A S
Jun 30, 2016, 9:48:58 AM6/30/16
to Yupeng Fu, Alluxio Users
I rerun the job after persisting the file. It ran for 100% map and failed on 84% reduce.
Error16/06/30 18:50:42 INFO mapreduce.Job: Task Id : attempt_1467284290167_0002_r_000000_2, Status : FAILED
Error: java.io.IOException: Failed to cache: Unable to request space from worker
at alluxio.client.file.FileOutStream.handleCacheWriteException(FileOutStream.java:337)
at alluxio.client.file.FileOutStream.write(FileOutStream.java:293)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:58)
at java.io.DataOutputStream.write(DataOutputStream.java:107)
at org.apache.hadoop.mapreduce.lib.output.TextOutputFormat$LineRecordWriter.writeObject(TextOutputFormat.java:83)
at org.apache.hadoop.mapreduce.lib.output.TextOutputFormat$LineRecordWriter.write(TextOutputFormat.java:98)
at org.apache.hadoop.mapred.ReduceTask$NewTrackingRecordWriter.write(ReduceTask.java:558)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89)
at org.apache.hadoop.mapreduce.lib.reduce.WrappedReducer$Context.write(WrappedReducer.java:105)
at com.flytxt.bigdata.mr.WordCount$IntSumReducer.reduce(WordCount.java:101)
at com.flytxt.bigdata.mr.WordCount$IntSumReducer.reduce(WordCount.java:90)
at org.apache.hadoop.mapreduce.Reducer.run(Reducer.java:171)
at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:627)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:389)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.io.IOException: Unable to request space from worker
at alluxio.client.block.LocalBlockOutStream.requestSpace(LocalBlockOutStream.java:137)
at alluxio.client.block.LocalBlockOutStream.flush(LocalBlockOutStream.java:114)
at alluxio.client.block.BufferedBlockOutStream.write(BufferedBlockOutStream.java:104)
at alluxio.client.file.FileOutStream.write(FileOutStream.java:284)
... 17 more
Yupeng Fu
Jun 30, 2016, 3:46:57 PM6/30/16
to Krishnaprasad A S, Alluxio Users
Yes, that sounds like an issue of not enough memory. The performance depends heavily on the job logic. That's because Alluxio tries to load data into memory, so if the worker's memory is not sufficient for the reduce logic, the job may trigger multiple data eviction and reloading in alluxio.
Also, if data is stored in HDFS but not in Alluxio, then the first run of the query will bring it into Alluxio, that's why you may not observe perf improvement.
Krishnaprasad A S
Jul 1, 2016, 8:52:00 AM7/1/16
to Yupeng Fu, Alluxio Users
This time I reduced Alluxio memory to 3GB per node, for allocating rest of the memory to MR. But this time also I got an error,
16/07/01 13:27:31 INFO mapreduce.Job: Task Id : attempt_1467358214615_0001_r_000000_0, Status : FAILED
-----
-----
16/07/01 13:27:00 INFO mapreduce.Job: map 100% reduce 76%
16/07/01 13:27:24 INFO mapreduce.Job: map 100% reduce 77%
Error: java.io.IOException: alluxio.exception.BlockInfoException: Cannot complete a file without all the blocks committed
at alluxio.client.file.FileOutStream.close(FileOutStream.java:222)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
at org.apache.hadoop.mapreduce.lib.output.TextOutputFormat$LineRecordWriter.close(TextOutputFormat.java:111)
at org.apache.hadoop.mapred.ReduceTask$NewTrackingRecordWriter.close(ReduceTask.java:550)
at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:629)
16/07/01 13:27:31 INFO mapreduce.Job: Task Id : attempt_1467358214615_0001_r_000000_0, Status : FAILED
-----
-----
16/07/01 13:27:00 INFO mapreduce.Job: map 100% reduce 76%
16/07/01 13:27:24 INFO mapreduce.Job: map 100% reduce 77%
Error: java.io.IOException: alluxio.exception.BlockInfoException: Cannot complete a file without all the blocks committed
at alluxio.client.file.FileOutStream.close(FileOutStream.java:222)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
at org.apache.hadoop.mapreduce.lib.output.TextOutputFormat$LineRecordWriter.close(TextOutputFormat.java:111)
at org.apache.hadoop.mapred.ReduceTask$NewTrackingRecordWriter.close(ReduceTask.java:550)
at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:629)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:389)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: alluxio.exception.BlockInfoException: Cannot complete a file without all the blocks committed
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at alluxio.exception.AlluxioException.fromThrift(AlluxioException.java:99)
at alluxio.AbstractClient.retryRPC(AbstractClient.java:329)
at alluxio.client.file.FileSystemMasterClient.completeFile(FileSystemMasterClient.java:130)
at alluxio.client.file.FileOutStream.close(FileOutStream.java:220)
... 11 more
What may be the issue? Also what is the meaning of the error "Cannot complete a file without all the blocks committed".at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at alluxio.exception.AlluxioException.fromThrift(AlluxioException.java:99)
at alluxio.AbstractClient.retryRPC(AbstractClient.java:329)
at alluxio.client.file.FileSystemMasterClient.completeFile(FileSystemMasterClient.java:130)
at alluxio.client.file.FileOutStream.close(FileOutStream.java:220)
... 11 more
Yupeng Fu
Jul 8, 2016, 2:13:23 AM7/8/16
to Krishnaprasad A S, Alluxio Users
Hi Krishnaprasad,
Alluxio commits a file after it commits all the blocks of the file on all the workers. So I suspect what might have happened is some blocks/workers were lost. It will be helpful if you can provide the logs from workers and master.
Thanks,
Reply all
Reply to author
Forward
0 new messages