Great job with IMAP interface
203 views
Skip to first unread message

Louis LaBrunda
Mar 27, 2021, 10:43:14 AM3/27/21
to VAST Community Forum
Hi All,
I have an old program that reads the email headers from various email accounts and displays them in two lists, those that it thinks I want to delete and those that I want to keep. The program was written a long time ago with Totally Objects Socket Set.
Socket Set only does POP3, so I decided to upgrade the program to IMAP. I really like the Instantiations IMAP interface.
With POP3, once an email is deleted, it is gone. With IMAP it is flagged as deleted but remains until it is expunged, so it can be recovered. I like this because every once in a while I would accidently delete emails before having read them into my email client. With IMAP I can delete them and undelete them before they are gone for good. There is one problem with that. My email client (Forte Agent, which is old but I like it) reads via POP3 and sees and reads the "deleted" email.
IMAP to the rescue. With IMAP I can move emails to another mailbox. IMAP really doesn't have a move command but it does have a copy command. Instantiations made this easy with their #move:to: method that does a copy and then deletes (flags and expunges) the email from the original mailbox. It saved me the trouble of writing it.
If I mess up, I can recover emails from the archive mailbox. At the end of the day, when I'm sure I have read all the emails I'm interested in, I delete them for good from the archive mailbox.
Thanks guys, for a nice job.
Lou

Seth Berman
Mar 27, 2021, 11:16:37 AM3/27/21
to VAST Community Forum
Thanks Lou,
I'll admit, SMTP was a lot more enjoyable to write than IMAP.
The volume of RFCs to get a handle on for IMAP was considerable because we ended up supporting a lot of extensions.
But it was interesting to do things like IMAP IDLE support.
Many thanks
- Seth
Louis LaBrunda
Mar 28, 2021, 12:08:43 PM3/28/21
to VAST Community Forum
Hi Seth,
I have a question. Some of the email have subjects that look like this:
'=?utf-8?Q?33=20Items=20on=20Sale=20at=20up=20to=2040%=20off=21?='
and from>personalName that look like this:
'=?utf-8?Q?MPJA.com=20=2D=20Email=20Specials?='
They look like html encodes string? Any idea what I need to do to convert them to cleaner looking text?
Lou
Seth Berman
Mar 28, 2021, 3:20:02 PM3/28/21
to VAST Community Forum
Hi Lou,
The grammar is defined lower in the doc, but from your example we can see a "Quoted-Printable" encoding (since the encoding is a Q).
There are probably lots of articles on how specifically to handle these, but this is from RFC 1342: Representation of Non-ASCII Text in Internet Message Headers
The grammar is defined lower in the doc, but from your example we can see a "Quoted-Printable" encoding (since the encoding is a Q).
You will want to refer to the grammar for encoded-text which leads you to see that =20 is a <space> and =21 is an <exclamation mark> in UTF-8
Therefore, the substitution would look like:
encoded-word = "=" "?" charset "?" encoding "?" encoded-text "?" "=" ---->
= "=" "?" utf-8 "?" Q "?" 20Items=20on=20Sale=20at=20up=20to=2040%=20off=21 "?" "=" ---->
= "=" "?" utf-8 "?" Q "?" Items on Sale at up to 40% off! "?" "=" ---->
...
- Seth

Joachim Tuchel
Mar 29, 2021, 2:09:46 AM3/29/21
to VAST Community Forum
Lou,
as Seth said, this is a very common encoding. My research pointed me towars RFC2047, but I must admit that I have my troubles seeing the forest among all those trees when it comes to RFCs.
For the part between "=?UTF-8?Q?" and "?=" you can use my QuotedPrintableCoder from VASTGoodies. I also have an unfinished version of an RFC2047 code in my private repository for the surrounding part which also uses the Base64Encoder for cases in which the encoding is B instead of Q. I didn't find the time to do the encoding part yet, however. Shouldn't be too much work, but I had other things to do and so I moved on before it was finished ... I'll contact you in private about this.
Joachim
Seth Berman
Mar 29, 2021, 9:21:33 AM3/29/21
to VAST Community Forum
Hi Joachim,
I could be looking at a more dated version...I didn't think to follow the RFC update trail.
Basically at the top of the rfcs...such as RFC 1342, you can see "Obsoleted by: 1522"
Then if you visit RFC 1522, you can see the same basic grammar in "2. Syntax of Encoded-Words"
But, we see that this was obsoleted by a whole host of documents...one of them being RFC 2047 which contains that grammar in "2. Syntax of encoded-words".
Then if you visit RFC 1522, you can see the same basic grammar in "2. Syntax of Encoded-Words"
But, we see that this was obsoleted by a whole host of documents...one of them being RFC 2047 which contains that grammar in "2. Syntax of encoded-words".
It basically looks the same, but I would certainly use the newest one.
- Seth
Joachim Tuchel
Mar 30, 2021, 3:06:00 AM3/30/21
to VAST Community Forum
Hi Seth,
I think I remember reading a comment of yours about the fun of reading RFCs... Imagine you are not a native speaker and try again ;-)
I don't think the QuotedPrintable stuff has changed much over time. The problem with its documentation to me seems to be the fact that it is described in multiple RFCs and I think I even saw some tiny differences between them. I initially implemented the QuotedPrintableCoder to read .VCS and .ics files, not knowing that it's used in many more contexts.
The bigger problem to me was that it is embedded in other encodings like the one described in 2047. And going through RFCs increasingly gives you the feeling no matter what you implement, there will be ever more RFCs putting this one detail into more and more contexts. It feels like rolling a rock up an endless chain of hills... you always fear whatever you implemented so far, it's not good enough for more purposes than the one or two you use it in...
So I do have a starting point of an RFC2047 coder (it does decoding, but no encoding yet, because I didn't need it yet), but it is far from complete, so I haven't published it yet.... I sent it to Lou to see whether it does work for his purposes as well and who knows, maybe he will do a bit more testing and maybe even add some functionality.
AFAIK, Pharo 9 (maybe it was even Pharo 8, don't remember) ships with an RFC2047 code based on / inherited from my my QuotedPrintableCoder, so looking into "backporting" this stuff to VAST is an even better option...
Joachim
Louis LaBrunda
Apr 2, 2021, 4:40:28 PM4/2/21
to VAST Community Forum
Hi Seth,
Joachim and everyone,
Just for fun I wrote a RFC2047 decoder. I had an idea for a way of converting this stuff that I decided to play with. Years ago, when I did conversions like this (I don't remember what was being converted, that's how long ago it was) I used a thing called "state diagrams". State Diagrams are a way of drawing the steps (states) a machine goes through to perform a process based upon inputs. They are kinda like a flow chart. I think they were used to design things like vending machines before integrated circuits were cheep and readily available. I never used them for machines myself but borrowed the idea for conversions. They are drawn with circles that represent the current state and lines that show input and what state the machine goes to next. States can loop back to themselves.
My hope was that since when in a state, the next character is being looked at and then the state changes, the code for each state would be small and simple. That should make the code for each state easy to change if the spec of the data being decoded changes. I made each major state a method.
The decoder can decode multiple encodings (with different code pages) in one string. That requires recursive calling of methods. That could be a problem because the methods don't return in a normal way. That could lead to the stack going very deep. I throw an event and catch it to end things.
The encoded string for an given encoding can't contain another encoding. I'm not sure if this is allowed. If it is, I will have to think about how to do that.
Since I still can't get this stupid google groups to upload a file, you can download a file out of the class here:
All comments are welcome.
Lou
Louis LaBrunda
Apr 3, 2021, 2:20:48 PM4/3/21
to VAST Community Forum
After sleeping on my machine state approach to decoding RFC2047 data I decided that I learned a lot but that simple loops could accomplish the conversion without throwing/catching events and the depth wasn't going to be a problem. So I have rewritten the code in that mode. I will post the code later.
New question. This is a string I got as the subject of an email:
'=?UTF-8?Q?should?= =?UTF-8?Q?_=F0=9D=91=BA=F0=9D=92=95=F0=9D=92=82=F0=9D=92=84=F0=9D=92=86=F0=9D=92=9A?= =?UTF-8?Q?_=F0=9D=91=A8=F0=9D=92=83=F0=9D=92=93=F0=9D=92=82=F0=9D=92=8E=F0=9D=92=94?= =?UTF-8?Q?_run_for_Governor=3F?='
There are four encoded sections all claiming to to be code page UTF-8. After conversion I get:
'should ???????????? ???????????? run for Governor?'
I converted the two middle sections to this: ' 𠑺𠒕𠒂𠒄𠒆𠒚' and ' 𠑨𠒃𠒓𠒂𠒎𠒔'
I'm sure that is correct. The current code page seems to be 819. I assume that is correct?
Anyone have any idea what's up? Is UTF-8 wrong? Is 819 wrong?
Based on the body of the email I think the two strings should convert to "Stacey Abrams", maybe with some funny formatting like italics.
Lou
Louis LaBrunda
Apr 5, 2021, 10:04:00 AM4/5/21
to VAST Community Forum
Hi,
Here is another subject that doesn't convert:
'=?UTF-8?Q?=F0=9D=90=8C=F0=9D=90=9A=F0=9D=90=AB=F0=9D=90=AD=F0=9D=90=A2=F0=9D=90=A7?= =?UTF-8?Q?_=F0=9D=90=8B=F0=9D=90=AE=F0=9D=90=AD=F0=9D=90=A1=F0=9D=90=9E=F0=9D=90=AB?= =?UTF-8?Q?_=F0=9D=90=8A=F0=9D=90=A2=F0=9D=90=A7=F0=9D=90=A0?= =?UTF-8?Q?_=F0=9D=90=89=F0=9D=90=AB.?= =?UTF-8?Q?_=F0=9D=90=8B=F0=9D=90=9E=F0=9D=90=A0=F0=9D=90=9A=F0=9D=90=9C=F0=9D=90=B2?= =?UTF-8?Q?_=F0=9D=90=92=F0=9D=90=AE=F0=9D=90=AB=F0=9D=90=AF=F0=9D=90=9E=F0=9D=90=B2?='
Could the Q encoded values be wrong? They are all above 128 in value. I have tried all the char sets beside UTF-8 and that doesn't help. Any ideas?
Lou
P.S. You can download my latest KscRFC2047Decoder.st.
Message has been deleted
Seth Berman
Apr 5, 2021, 11:08:20 AM4/5/21
to VAST Community Forum
Hi Lou,
Your latest subject contains UTF-8 bold characters. That's why they all are prefixed with =F0=9D.
It says: 𝐌𝐚𝐫𝐭𝐢𝐧 𝐋𝐮𝐭𝐡𝐞𝐫 𝐊𝐢𝐧𝐠 𝐉𝐫. 𝐋𝐞𝐠𝐚𝐜𝐲 𝐒𝐮𝐫𝐯𝐞𝐲
It says: 𝐌𝐚𝐫𝐭𝐢𝐧 𝐋𝐮𝐭𝐡𝐞𝐫 𝐊𝐢𝐧𝐠 𝐉𝐫. 𝐋𝐞𝐠𝐚𝐜𝐲 𝐒𝐮𝐫𝐯𝐞𝐲
For example, you can see the 𝐌 is f0 9d 90 8c (MATHEMATICAL BOLD CAPITAL M)
I found this site which may help you to decode so you know what you are aiming for: https://dogmamix.com/MimeHeadersDecoder/
I found this site which may help you to decode so you know what you are aiming for: https://dogmamix.com/MimeHeadersDecoder/
-Seth
Louis LaBrunda
Apr 5, 2021, 11:35:59 AM4/5/21
to VAST Community Forum
Thanks Seth, I'm sure that will be a big help.
Lou
Louis LaBrunda
Apr 5, 2021, 11:55:48 AM4/5/21
to VAST Community Forum
Seth, have I gotten into an area that VA Smalltalk doesn't support yet? Is this a Unicode code page problem? Might I hack a solution by subtracting out the "bold" part to bring things down to a regular letter?
Lou
Seth Berman
Apr 5, 2021, 12:31:01 PM4/5/21
to VAST Community Forum
Hi Lou,
"have I gotten into an area that VA Smalltalk doesn't support yet?"
Not necessarily, it all depends on what you want to do with it.
If you want to show it in an editor, save it in source code, or otherwise interpret it...then probably so.
If you want to simply pass it through to somewhere else...then not at all.
If you want to simply pass it through to somewhere else...then not at all.
I think your issue is that you need to parse those bytes as UTF-8. So you need a UTF-8 parser (I would think).
Those hex values sit in a Smalltalk 'String' container but that isn't really relevant. So you don't need to do code page conversion.
Those hex values sit in a Smalltalk 'String' container but that isn't really relevant. So you don't need to do code page conversion.
Some ideas are:
1. Parse the UTF-8 hex values into a ByteArray. (Maybe as simple as removing the '=' stuff in-between and pushing those hex converted integer values to a ByteArray).
2. Assuming you want to turn it into a Smalltalk String and accept some losslessness, then do code page conversion on that ByteArray from UTF-8 -> current code page.
3. If you want to just pass it through to somewhere else, then just leave it as a ByteArray and pass that ByteArray on to something else.
1. Parse the UTF-8 hex values into a ByteArray. (Maybe as simple as removing the '=' stuff in-between and pushing those hex converted integer values to a ByteArray).
2. Assuming you want to turn it into a Smalltalk String and accept some losslessness, then do code page conversion on that ByteArray from UTF-8 -> current code page.
3. If you want to just pass it through to somewhere else, then just leave it as a ByteArray and pass that ByteArray on to something else.
- Seth
Louis LaBrunda
Apr 5, 2021, 1:23:27 PM4/5/21
to VAST Community Forum
Hi Seth,
Thanks.
On Monday, April 5, 2021 at 12:31:01 PM UTC-4 Seth Berman wrote:
Some ideas are:
1. Parse the UTF-8 hex values into a ByteArray. (Maybe as simple as removing the '=' stuff in-between and pushing those hex converted integer values to a ByteArray).
2. Assuming you want to turn it into a Smalltalk String and accept some losslessness, then do code page conversion on that ByteArray from UTF-8 -> current code page.
This is what I'm doing (I think). I put the converted hex into a String and not a ByteArray and use convertFromCodePage: 'UTF-8', to convert it to the current code page. The result is mostly "?" marks.
The current code page is 819.
Lou
Seth Berman
Apr 5, 2021, 1:45:06 PM4/5/21
to VAST Community Forum
Hi Lou,
I guess this goes back to what you ultimately want to do with the UTF-8 bytes?
In other words...why must you convert to the current code page? (which btw, I don't think you can do since 819 doesn't have an equivalent for those special letters).
In other words...why must you convert to the current code page? (which btw, I don't think you can do since 819 doesn't have an equivalent for those special letters).
If what you have is a valid set of UTF-8 bytes sitting in a ByteArray...what would you like to do next?
- Seth
Louis LaBrunda
Apr 5, 2021, 1:53:40 PM4/5/21
to VAST Community Forum
Hey Seth,
For my need (I'm not sure about Joachim) I would just like the string to be readable. So, I don't need the bolding (or whatever), I just need to see what it says.
Because the UTF-8 stuff like "MATHEMATICAL BOLD CAPITAL M" is defined as U+1D40C I have been trying to subtract out the the U part but that doesn't seem to get me where I want to be.
Lou
Seth Berman
Apr 5, 2021, 2:01:50 PM4/5/21
to VAST Community Forum
Hi Lou,
But those UTF-8 encoded code points are just numbers assigned by a group of people. It doesn't know that its technically a decorated ASCII M. So you would need to have some program that new how to perform that conversion to some code page which is certainly not something that VAST does.
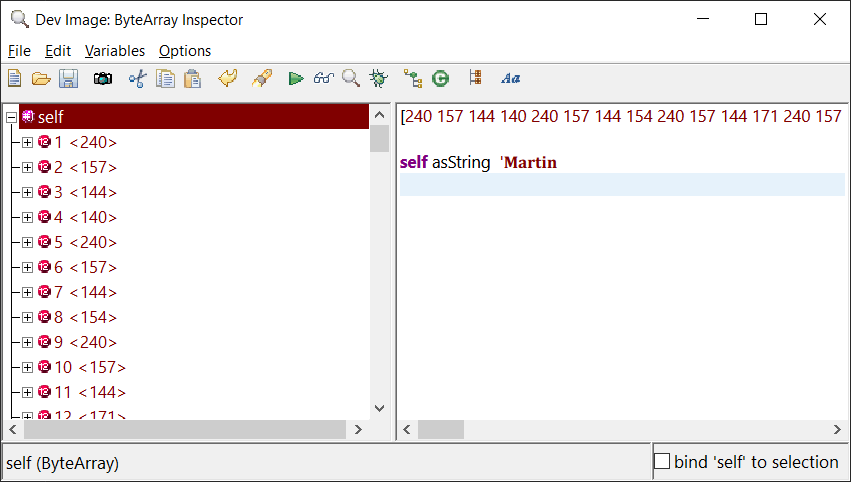
"I would just like the string to be readable"
- It just depends where you want to read it.
If you dump those bytes to a file and open them in something like Notepad++ in UTF-8 mode...then it will be readable.
If you set the code page of the smalltalk scintilla editor to 65001, then it will be readable (see below)
If you dump those bytes to a file and open them in something like Notepad++ in UTF-8 mode...then it will be readable.
If you set the code page of the smalltalk scintilla editor to 65001, then it will be readable (see below)
But those UTF-8 encoded code points are just numbers assigned by a group of people. It doesn't know that its technically a decorated ASCII M. So you would need to have some program that new how to perform that conversion to some code page which is certainly not something that VAST does.
Louis LaBrunda
Apr 5, 2021, 2:26:31 PM4/5/21
to VAST Community Forum
Hi Seth,
If you dump those bytes to a file and open them in something like Notepad++ in UTF-8 mode...then it will be readable.
The program I need this for displays the subject as a column in a container is a window. Joachim might be okay with sending the data to a file.
If you set the code page of the smalltalk scintilla editor to 65001, then it will be readable (see below)
How did you do that? Can I call scintilla to give me a converted string?
How about my idea (maybe crazy idea) to subtract something from each chunk (3 or 4 bytes) to bring it down to a range we can work with?
But those UTF-8 encoded code points are just numbers assigned by a group of people. It doesn't know that its technically a decorated ASCII M. So you would need to have some program that new how to perform that conversion to some code page which is certainly not something that VAST does.
This was my guess, I am just trying to hack my way around it for my limited case until you guys do the real conversion.
Lou
Seth Berman
Apr 5, 2021, 2:43:44 PM4/5/21
to VAST Community Forum
Hi Lou,
To put the editor in UTF-8 mode, you get an instance and apply:
And I didn't convert anything...it just goes into a mode where it interprets the bytes in that byte array correctly.
CwScintillaEditor>>setCodePage: 65001
"How about my idea (maybe crazy idea) to subtract something from each chunk (3 or 4 bytes) to bring it down to a range we can work with?"
That's not going to work. Except *mostly* for the first 128 chars, UTF-8 encoded bytes are not relatable to code pages. Again, its just a value
assigned by a group of folks, so you can't really do anything mathematical to it to accomplish much with regards to conversion.
The first 4 bytes in your example is the UTF-8 encoded value for Mathmatical Bold Capital M (https://www.compart.com/en/unicode/U+1D40C)
It's UTF-8 value is different than its UTF-16 value which is different from its Unicode Scalar value. And they don't relate...its just a value.
It's UTF-8 value is different than its UTF-16 value which is different from its Unicode Scalar value. And they don't relate...its just a value.
"I am just trying to hack my way around it for my limited case until you guys do the real conversion."
- We won't be doing any conversion. As a first step, what we are doing is offering a UnicodeString container that could ingest those UTF-8 encoded bytes and do interesting things with them and showing them in our editor which we will switch to UTF-8 mode. This means a UnicodeString will need to convert itself to UTF-8 when it hands Scintilla bytes to display.
Next steps would be upgrading our CFS APIs to use them, followed by switching our APIS on Windows from narrow to wide APIs. At that point, UTF-8 would still require conversion to UTF-16 if you are going to be showing them in table cells that are Windows widgets. But the new Unicode support library gives you a first class container and plenty of easy APIs to make that feasible.
- Seth
Joachim Tuchel
Apr 6, 2021, 6:02:31 AM4/6/21
to VAST Community Forum
Hi Lou, Seth,
I've been offline for a bit over easter. So I'm late to the discussion....
As you know, I also implemented a rather sketchy RFC2047 converter and had used it for a few months already. It has some limitiations and of course has nothing to offer for emojis, bold characters and whatnot. I freely admit I never cared about these edge cases, because my main purpose of using IMAP is to receive attachments and put them on some batch for processing. Most of the encoded headers are irrelevant for my use case.
I was sure my encoder is not even close to being half-baked, so I kept it for myself for the time being. I would revisit it once I encounter a use case that requires more. It is a lot of work to "just" write some tool that implements the plethora of RFCs that you discover once you lift a corner of one of them....
I am glad you shared your experiences here and that Seth chimed in with his knowledge on the topic. UTF-x and Unicode are cans of worms, white areas on the map of a mortal application developer, the valley where many young and brave knights rode into but never came back... So there may be lots of beautiful princesses there or just an army of Dragons, nobody knows ;-)
Why am I glad? Because I know I am not alone and - even better - that Instantiations is going to send their princes into UTF-x valley for us ;-)
Joachim
As a side note: my clumsy decoder returns this: '???????????? _???????????? _???????? _????. _???????????? _????????????' ;-)
Louis LaBrunda
Apr 7, 2021, 6:19:34 PM4/7/21
to VAST Community Forum
Hi Everyone,
I have been able to squeeze the bold... section of UTF-8 (those four byte sections that start with F0) down to displayable characters. I'm still working on the three and two byte sections, those that start with E0 and C0. This code is a hack but I think it does what I need in my program. I'm not sure if it will help Joachim but he and anyone who wants should feel free to us it or any part of it.
LouLouis LaBrunda
Apr 11, 2021, 7:19:44 PM4/11/21
to VAST Community Forum
Hi Everyone,
I spoke a little too soon when I said I had been able to squeeze the bold... section of UTF-8 (those four byte sections that start with F0) down to displayable characters. I thought I had been able to do some math on the value and map it to some ascii character that would look close. It turns out that works a little but not as consistently as I hoped. I had to go to the use of a table and that seems to cover almost everything I'm interested in. I'm was able to work out the math for the three and two byte sections, those that start with E0 and C0. I consider all of the code to be a hack but I think it does what I need in my program. I'm not sure if it will help Joachim but he and anyone who wants should feel free to us it or any part of it.
Louis LaBrunda
Apr 12, 2021, 10:32:22 AM4/12/21
to VAST Community Forum
Hi All,
Today I got an email with this subject:
'=?UTF-8?B?SGVhcnRmZWx0IGdpZnRzIGZvciBNb3RoZXLigJlzIERheSDwn5Kd?='
my conversion yields:
'Heartfelt gifts for Mother’s Day 💠'
an online converter yealds:
Heartfelt gifts for Mother’s Day 💝
I don't really need this for my program but I curious.
Lou
Seth Berman
Apr 12, 2021, 11:04:49 AM4/12/21
to VAST Community Forum
Hi Lou,
This is kinda what I've been saying. This is UTF-8 encoded bytes. You need a UTF-8 decoder to properly decode those bytes.
UTF-8 is an encoding scheme for Unicode code points. The code page you are using (or any code page) can only represent a very small portion of what the Unicode code space captures. And certainly, emoji are not included in that unless someone in recent times has been creating strange code pages I'm not familiar with.
Using the "Code Page Converter", you can properly convert most of that...but its not going to know how to convert a 💝 to a codepage byte...because there likely is no such mapping in any useful codepage.
Conversion from Unicode to code page is a lossy conversion. One can't possibly represent all forms of a 'character' from the valid set of Unicode code points in just a byte.
This is why I was asking earlier about what you plan to do with these incoming bytes.
If you need to just pass them on to someone else...then keep them in UTF-8 in a ByteArray (no conversion), and then just pass them on.
You could technically keep them in a String class, since it basically is a ByteArray...but I would advise against trying to assume (String at: <index>) is always going to return something useful.
If you need to work with them in Smalltalk as a set of Characters...then we arrive at the inevitable conclusion that VAST is not yet Unicode-aware.
This whole discussion was the basis of my recent post showing what we are doing for VAST 2022
https://groups.google.com/g/va-smalltalk/c/-w7FVdc1gFM/m/gvngUys3CAAJ
This whole discussion was the basis of my recent post showing what we are doing for VAST 2022
https://groups.google.com/g/va-smalltalk/c/-w7FVdc1gFM/m/gvngUys3CAAJ
- Seth
Louis LaBrunda
Apr 12, 2021, 1:24:39 PM4/12/21
to VAST Community Forum
Hi Seth,
Thanks for the reply. I understand everything you said. What I'm curious about is how does a code page or anything know that an F0 (which is a valid ASCII upper end character) is the start of a UTF-8 or Unicode four byte thingy?
Lou
Seth Berman
Apr 12, 2021, 1:40:32 PM4/12/21
to VAST Community Forum
Hi Lou,
Codepages don't know anything about UTF-8. UTF-8 was designed so that the first 128 'characters' of UTF-8 match ASCII, so it may seem as if they are related.
The subject lines you are providing specify 'UTF-8'...and therefore you need to treat it as such.
If all chars in the subject are between 0-127, then you can just treat it as ascii. Otherwise, you will need to attempt lossy code page conversion which may (or may not) be able to map the UTF-8 encoded codepoints to a byte in your current code page.
If you are curious about the UTF-8 encoding, you can just checkout Wikipedia or something that will describe how the upper bits help determine how many UTF-8 bytes are required to read a decoded unicode code point.
- Seth
Louis LaBrunda
Apr 12, 2021, 3:23:02 PM4/12/21
to VAST Community Forum
Hi Seth,
I see my misunderstanding. It is 0-127 of ASCII and UTF-8 that are the same. Above 127 that requires the 2, 3 or 4 byte encodings. So, if a character is between 0 and 127, ASCII is good. Above 127 one needs to map to ASCII if one wants something that looks close (which is what I have been doing for the "Q" encoded stuff). I didn't realize the "B" encoded stuff needed the extra step. Thanks.
Lou
Louis LaBrunda
Apr 17, 2021, 11:27:42 AM4/17/21
to VAST Community Forum
Hi Guys,
I now know far more about UTF-8 than I ever wanted to. I apologize for asking a lot of questions because I really didn't want to read too much of those UTF-8 and RFC2047 docs.
I have split my KscRFC2047Decoder.st in two and now have it and KscUtf8ToAscii.st. KscUtf8ToAscii is a class that maps over 2000 UTF-8 values to single byte ASCII values that look a lot like the UTF-8 images but without fancy stuff like bold etc. This allows me to see the intended meaning (of email subjects and such) without the indication that the UTF-8 couldn't map to ASCII, like a box or something.
To my mind, this is what a UTF-8 to ASCII code page converter should do. I know that is asking a lot but it would be nice.
Lou

Mariano Martinez Peck
Apr 19, 2021, 7:54:24 AM4/19/21
to VA Smalltalk
On Sat, Apr 17, 2021 at 12:27 PM Louis LaBrunda <L...@keystone-software.com> wrote:
Hi Guys,I now know far more about UTF-8 than I ever wanted to. I apologize for asking a lot of questions because I really didn't want to read too much of those UTF-8 and RFC2047 docs.I have split my KscRFC2047Decoder.st in two and now have it and KscUtf8ToAscii.st. KscUtf8ToAscii is a class that maps over 2000 UTF-8 values to single byte ASCII values that look a lot like the UTF-8 images but without fancy stuff like bold etc. This allows me to see the intended meaning (of email subjects and such) without the indication that the UTF-8 couldn't map to ASCII, like a box or something.To my mind, this is what a UTF-8 to ASCII code page converter should do. I know that is asking a lot but it would be nice.
It does, but up to a certain extent. This is called "Transliterate". iconv() provides a //TRANSLIT option and Windows offers a flag in the conversion API too. We have recently reified that (as well as other options) into a class EsCodePageConversionPolicy. See senders of #isTransliterateMode. Even more, we put the transliterate mode even the default one. So...again, the code page converter tries to transliterate, but up to certain extent. And from VAST point of view, we are doing up to that extent too.
Best,
| |||||||||||||||||
Reply all
Reply to author
Forward
0 new messages