ECAP 2 Update...
215 views
Skip to first unread message

Seth Berman
Jun 4, 2019, 4:21:23 PM6/4/19
to VA Smalltalk
Hello All,
The next version of the Early Customer Access Program (ECAP) preview release is coming soon.
We're running about 2 weeks behind because we want to reach production quality for the new Just-In-Time Compiler that will come with it.
We've reached the performance goals, but we also want to preview it when there are no remaining issues that we are aware of.
The purpose of ECAP is to help us find the issues we are not aware of. Almost there!
- Seth

Louis LaBrunda
Jun 5, 2019, 8:28:57 AM6/5/19
to VA Smalltalk
Hi Seth,
When you get some time, please explain just what the/a Just-In-Time Compiler does and when it does it. I thought that when one saves a method, it gets compiled. That process doesn't seem to need a Just-In-Time Compiler. What is created is what in my day called "P code", now I think it is called "byte code". So, what is getting Just-In-Time Compiled and when?
Lou
Seth Berman
Jun 5, 2019, 9:24:34 AM6/5/19
to VA Smalltalk
Hi Lou,
Good question...I'll give the quick answer and then give some insight into what we have put together.
JIT in this context typically means "compiled to native machine code at runtime". So it generates the instructions of the native machine...not the instructions of the Smalltalk virtual machine.
Our interpreter is incredibly fast...faster than any interpreter you could code in C/C++ by about 25-30%. This is because we essentially wrote a Smalltalk specific compiler front-end on top of LLVM's backend machine code generator. So our Smalltalk Interpreter is at the same level as a C/C++ compiler, not a program written on top of a C/C++ compiler which has certain runtime rules that must be respected and you have less control over how register allocation works.
That being said, even a simple JIT should be able to outperform an interpreter because, at the very least, you can remove expensive Bytecode->Machine code fetch/transfer of control costs. It's actually very expensive to load the next bytecode from a compiled method, lookup where the native code is that implements that bytecode, and then transition to it. You're basically emulating in software what is done normally in hardware as the machine executes one instruction and then the next.
Our new JIT is a 1st tier JIT...one that is specifically designed to remove the aforementioned bytecode dispatch overhead, dramatically speed up Smalltalk method sends, and generate the machine code very very quickly. It's not technically an in-memory compiler at all. It's more of a linker and optimizer. We generate the native code templates at compile time, and dump it to disk as a binary object file (esvm40.bin). This will ship with the product and you will see it in the new ECAP.
Our "JIT" will inspect the bytecodes of a method and wire together its native template counterparts, copy it to an executable portion of memory, "fill in the blanks" of the templates with real memory addresses and offsets, and then we perform a series of optimizations on the native machine code now that we can see it in the context of the entire method. We also support super-ops, so as we recognize patterns of bytecodes, and few bytecodes then may be replaced with one optimized native template. So we end up with nicely optimized machine code that was really quick to generate. And we don't need a full in-memory compiler, so we can keep size down.
We also implemented polymorphic inline caches so we could reduce Smalltalk method sends (another expensive area in Interpretation mode) to just a few native instructions. Since Smalltalk is all about sending messages...this is obviously a great thing.
We are already looking at a 2nd tier JIT that will use an in-memory compiler and compile hot sections of code (i.e. Hotspot). We already have the counters in place so the data collection is there for us to put together what paths are hot (we already do it for hot methods). We'll also be able to do this in separate threads so the main execution doesn't need to stop and wait for the in-memory compiler to put some code together.
The really nice part is that this JIT we have put together is portable across platforms, thats been the nice advantage of using the LLVM code generator throughout our vm technology stack.
Hope this helps
- Seth
Louis LaBrunda
Jun 5, 2019, 11:11:27 AM6/5/19
to VA Smalltalk
Hi Seth,
WOW! Sounds great! Much of what you describe is what I was guessing you were doing. Where I got confused is I thought modern machines/OSs didn't allow programs to write/change executable memory, as a security measure. But I guess there is a way around that.
Lou
Seth Berman
Jun 5, 2019, 11:19:55 AM6/5/19
to VA Smalltalk
Hi Lou,
Yes, even though our virtual machine is compiled with DEP (Data Execution Prevention), we can still dynamically allocate code memory with the necessary permissions.
- Seth

Richard Sargent
Jun 5, 2019, 7:06:50 PM6/5/19
to VA Smalltalk
On Wednesday, June 5, 2019 at 6:24:34 AM UTC-7, Seth Berman wrote:
Hi Lou,Good question...I'll give the quick answer and then give some insight into what we have put together.JIT in this context typically means "compiled to native machine code at runtime". So it generates the instructions of the native machine...not the instructions of the Smalltalk virtual machine.Our interpreter is incredibly fast...faster than any interpreter you could code in C/C++ by about 25-30%. This is because we essentially wrote a Smalltalk specific compiler front-end on top of LLVM's backend machine code generator. So our Smalltalk Interpreter is at the same level as a C/C++ compiler, not a program written on top of a C/C++ compiler which has certain runtime rules that must be respected and you have less control over how register allocation works.That being said, even a simple JIT should be able to outperform an interpreter because, at the very least, you can remove expensive Bytecode->Machine code fetch/transfer of control costs. It's actually very expensive to load the next bytecode from a compiled method, lookup where the native code is that implements that bytecode, and then transition to it. You're basically emulating in software what is done normally in hardware as the machine executes one instruction and then the next.Our new JIT is a 1st tier JIT...one that is specifically designed to remove the aforementioned bytecode dispatch overhead, dramatically speed up Smalltalk method sends, and generate the machine code very very quickly. It's not technically an in-memory compiler at all. It's more of a linker and optimizer. We generate the native code templates at compile time, and dump it to disk as a binary object file (esvm40.bin). This will ship with the product and you will see it in the new ECAP.Our "JIT" will inspect the bytecodes of a method and wire together its native template counterparts, copy it to an executable portion of memory, "fill in the blanks" of the templates with real memory addresses and offsets, and then we perform a series of optimizations on the native machine code now that we can see it in the context of the entire method. We also support super-ops, so as we recognize patterns of bytecodes, and few bytecodes then may be replaced with one optimized native template. So we end up with nicely optimized machine code that was really quick to generate. And we don't need a full in-memory compiler, so we can keep size down.We also implemented polymorphic inline caches so we could reduce Smalltalk method sends (another expensive area in Interpretation mode) to just a few native instructions. Since Smalltalk is all about sending messages...this is obviously a great thing.We are already looking at a 2nd tier JIT that will use an in-memory compiler and compile hot sections of code (i.e. Hotspot). We already have the counters in place so the data collection is there for us to put together what paths are hot (we already do it for hot methods). We'll also be able to do this in separate threads so the main execution doesn't need to stop and wait for the in-memory compiler to put some code together.The really nice part is that this JIT we have put together is portable across platforms, thats been the nice advantage of using the LLVM code generator throughout our vm technology stack.Hope this helps
Wow! This sounds really nice. Are you ready to mention the approximate performance gain you've been seeing so far? Inquiring minds want to know!
Seth Berman
Jun 5, 2019, 7:54:10 PM6/5/19
to VA Smalltalk
Hi Richard,
- Seth
We will talk more about it at ESUG, and of course you can try for yourself with the next ECAP.
We have our own benchmarks we'll show, but we have real world numbers from a customer who partnered with us to help make this happen.
Those numbers are highly favorable and show that it clearly outperforms IBM's virtual machine for 32-bit. Obviously we don't have a 64-bit comparison against IBM because that never existed.
If you're using 9.x, it should provide a considerable speed boost, probably in the 2x range for computationally intensive work. If you are just doing UI work and sockets...you may not notice.
That's why I don't like talking benchmarks too much even though I know it has to be done...seems like smoke and mirrors whenever I hear people talk about it.
Like when you hear marketing verbiage such as "up to 20x faster". Yes, it may be 20x faster in some obscure corner case that you'll never execute in the real world...the rest of the time it will be 1.000000001x faster.
For now I'll say...its faster...if you do computational workloads...you'll definitely notice the difference.
- Seth
Louis LaBrunda
Jun 7, 2019, 10:00:19 AM6/7/19
to VA Smalltalk
Hi Seth,
I know you don't want to make any claims as to performance but I'm going to press you a little because I would like some ammunition for bragging rights. How would you say a 64 bit VA Smalltalk program compares with say a Java or C++ or NodeJS or Ruby program?
A little history, I don't claim to remember it perfectly but this is my recollection:
Smalltalk has long suffered from a reputation of being slow. The first Smalltalk (Xerox) was very close to 100% objects, everything was an object. I think Strings were arrays of Character objects not characters or bytes. This made doing things with strings very slow. This is forgivable because because Smalltalk was meant to be an experiment about ease of programming and not production speed.
The guys at Sun decided they would "fix" things by having "real" data types that weren't objects along with objects. That lead to the mess that is Java. The smart solution was to "box" (I think that is the right term) things. For Strings that meant keeping them in memory as bytes and only when a Character was needed, would a Character object be created/used. There are of course more examples.
I would love to counter the perception that Smalltalk is slow, with some evidence, even if it isn't backed up with perfect benchmarks.
Lou

Julian Ford
Jun 7, 2019, 12:26:08 PM6/7/19
to VA Smalltalk
Hi, Louis.
Those benchmarks would be very interesting, even if (as you said) they are not scientifically sustainable.
We have all heard about those complaints from early days, and love the chance to show what Smalltalk
(and especially VAST) can do today!!!
One other metric I frequently tell people about is the DEVELOPMENT benchmarking.
How developing an application in Smalltalk can be significantly faster, as well as much more
maintainable and robust than in Java and C++.
Ok...I realize that this is getting off the original topic, so I'll stop there.
I just LOVE to talk about the development benefits AS WELL as the runtime benchmarking...
Julian
Seth Berman
Jun 7, 2019, 11:36:58 PM6/7/19
to VA Smalltalk
Hi All,
"How would you say a 64 bit VA Smalltalk program compares with say a Java or C++ or NodeJS or Ruby program?"
- I wouldn't without extensive benchmarking of all of these and then understanding what each benchmark is trying to show and understanding how each language implements it down to the metal. This is even hard to show between smalltalk dialects. Some benchmarks might be hitting places where one dialect implements the hotspot as a quick primitive while the other is pure smalltalk.
- As someone once said "Give me a benchmark and tell me how fast you want it to run"...I think it was Lars Bak in a V8 javascript engine interview.
It's not a dodge, I just simply don't feel confident enough to provide a satisfactory answer that I know reliably represents the truth.
"VM Performance" is a complex thing to define. You can't provide a code snippet and say your vm is fast or slow.
You can't look at a tinyBenchmarks run and say it's fast or slow.
We have about 20 to 25 benchmarks we routinely look at to get a feel for it...so I understand how it improves over time against itself (and IBM because same spec) and thats been the real value of benchmarks for us.
I'll try to think of something semi-meaningful that at least partially satisfies my cynical view of benchmarks and the reporting of it.
But it would be quite an effort for me to do this beyond just a few benchmarks which would show just specific slices of what could be thought of as "VM Performance"....and I would qualify it as so.
- Seth
Louis LaBrunda
Jun 8, 2019, 9:17:32 AM6/8/19
to VA Smalltalk
Hi Seth,
I agree with everything you have said here.
That said, are there any benchmarks that others use, say one for Java, another for C##, C# and Ruby etc., that you could run when you have nothing better to do, (he says with a big grin) that we could point to and say, see VA Smalltalk does just as well and without any tuning?
Lou
Seth Berman
Jun 8, 2019, 9:30:46 AM6/8/19
to VA Smalltalk
Hi Lou,
Well that was kind of my point. I’m sure there is a reasonable benchmark. All we’ll be showing is how the machinery involved in that benchmark compares to others.
Kind of like a car where we’re comparing lbs of boost in turbo-chargers. At the end of the day, “my turbo-charger is bigger than your turbo-charger” is interesting and a great claim we can all be proud of. But if the turbo-charger is mated with a in-line 2 cylinder on a vehicle weighing 5000lbs...then it becomes less interesting. Not saying we’re a 2-cylinder tank but it’s important to set expectations about what we’re going to be excited about when we have a fantastic showing.
But like I said, I’ll take a look.
Well that was kind of my point. I’m sure there is a reasonable benchmark. All we’ll be showing is how the machinery involved in that benchmark compares to others.
Kind of like a car where we’re comparing lbs of boost in turbo-chargers. At the end of the day, “my turbo-charger is bigger than your turbo-charger” is interesting and a great claim we can all be proud of. But if the turbo-charger is mated with a in-line 2 cylinder on a vehicle weighing 5000lbs...then it becomes less interesting. Not saying we’re a 2-cylinder tank but it’s important to set expectations about what we’re going to be excited about when we have a fantastic showing.
But like I said, I’ll take a look.
Seth Berman
Jun 9, 2019, 11:11:38 PM6/9/19
to VA Smalltalk
Hi All,
Ok, for what its worth I ported the sudoku solver from the following location below (see attached) and then ran what is in the repo for Java, C#, Ruby, Python and Go.
The port I did is mostly from Julia (sudoku_v1.jl) because that also uses 1-based indexing.
https://github.com/attractivechaos/plb
https://github.com/attractivechaos/plb
The results are pretty much what I expected (except I had no idea where Go would end up). I guess I figured java and C# would be more ahead than they ended up being, so I was
triple checking if I was doing anything wrong. Still not sure, both were built in release mode and if I did miss anything, I don't know what it is. No big surprise for Python and Ruby.
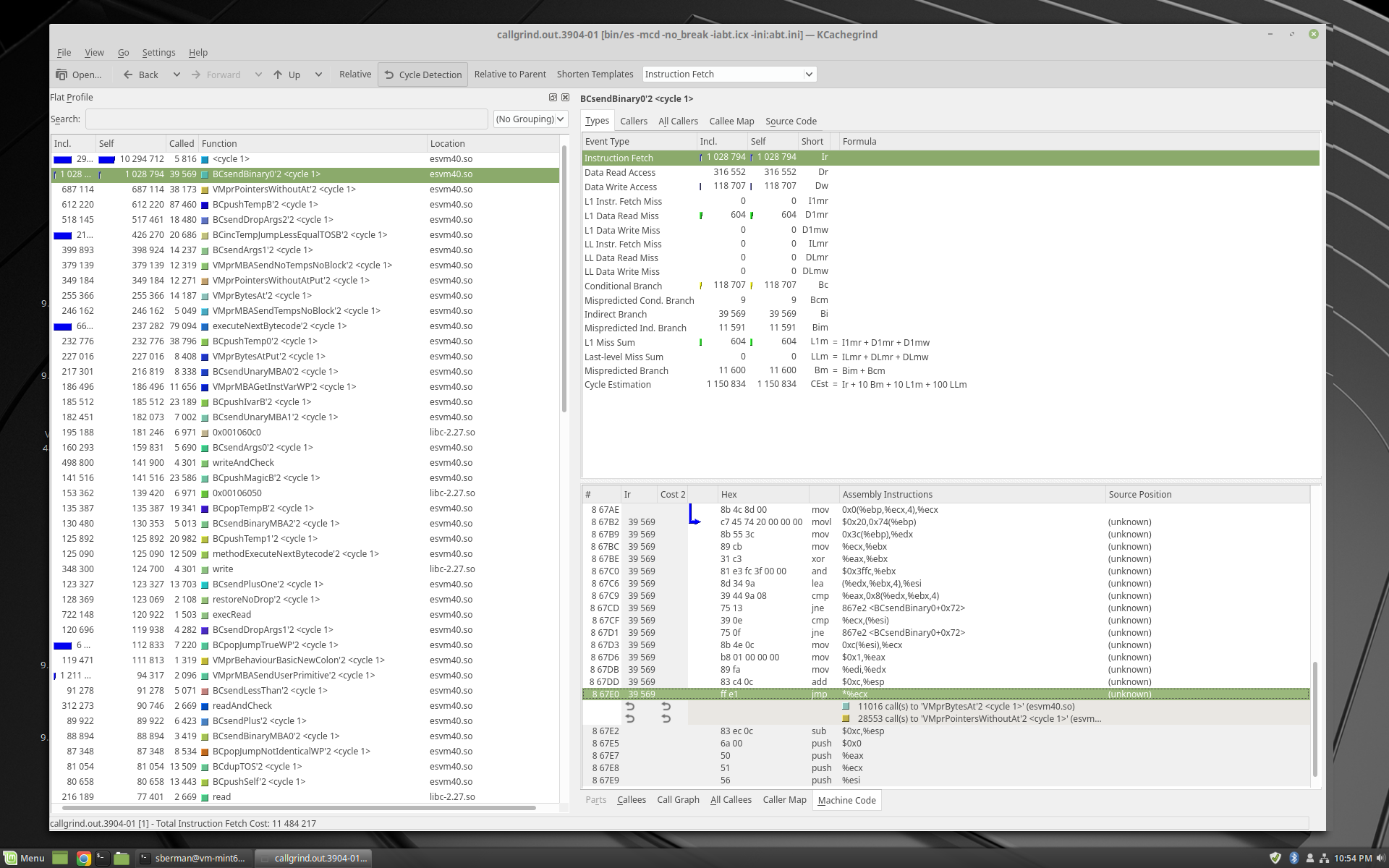
I've attached a picture of the cachegrind profile of a partial sudoku run just so I could get a sense of what kind of work we are doing...thought the source code pretty much explained it.
Looking at the solver code , the areas of the vm we should be thinking about are:
- Iteration (i.e. 1 to: 374 do: [:i ...) and efficiency of compare/branch bytecodes like BCincTempJumpLessEqualTOSB
- Iteration (i.e. 1 to: 374 do: [:i ...) and efficiency of compare/branch bytecodes like BCincTempJumpLessEqualTOSB
- At and AtPuts for byte, word and pointer collections (i.e. ByteArray, String, SudokuWordArray, Array)
- Basic push/pop temps and ivar (which is pretty much always the case).
- Primitive send machinery
What this isn't so good at showing is normal message send machinery...most of the work happens in a few methods and with bytecodes and primitive sends.
Results:
Machine - Intel(R) Core(TM) i7-4910MQ CPU @ 2.90GHz / 32 GB RAM / Windows 10 64-bit
Java - jdk 11.0.1 x64 - 63ms
C# - Visual Studio 2017 x64 - @67ms (lots of variance..between 40 and 140ms...didn't bother to see why)
Go - go1.12.5 windows/amd64 - 404ms
Ruby - cruby 2.1.5p273 x64 - 713ms
Python - cpython 3.6.2 x64 - 758ms
VAST 9.x 32-bit (JIT) - 128ms
VAST 9.x 64-bit (JIT) - 156ms
VAST 9.x 32-bit (Interpreter) - 250ms
VAST 9.x 64-bit (Interpreter) - 266ms
- Seth
Seth Berman
Jun 10, 2019, 11:33:58 AM6/10/19
to VA Smalltalk
Hi All,
I was looking more into Go lang and the more I looked, the more I felt that result couldn't be right.
Looking further, I had been including startup costs into that for Go...which was not fair.
So I went back and made sure all scripts had milliseconds time wrapped around just the code and not do command line timer.
So I went back and made sure all scripts had milliseconds time wrapped around just the code and not do command line timer.
I need to profile the version in C, but Go is looking more like it should I think.
Python dropped around 50ms in startup costs.
I updated Ruby and run again...it did pretty horrible. I was looking at wrong value in Measure-Command on powershell.
Just to be sure, I'm going to include the Go, Ruby, Python scripts in case anyone wants to check along with me.
I was trying to do these benchmarks with my kids watching Shrek 2 in the background...clearly a mistake.
Next I'm going to review java and C# one more time...and I'll try to do C so we get a good optimal baseline
Java - jdk 11.0.1 x64 - 63ms
C# - Visual Studio 2017 x64 - @67ms (lots of variance..between 40 and 140ms...didn't bother to see why)
Go - go1.12.5 windows/amd64 - 15m
Ruby - cruby 2.1.5p273 x64 - 2437ms
Python - cpython 3.6.2 x64 - 703ms
VAST 9.x 32-bit (JIT) - 128ms
VAST 9.x 64-bit (JIT) - 156ms
VAST 9.x 32-bit (Interpreter) - 250ms
VAST 9.x 64-bit (Interpreter) - 266ms
Louis LaBrunda
Jun 10, 2019, 3:16:24 PM6/10/19
to VA Smalltalk
Hi Seth,
Thanks for doing this. LOL about the kids watching Shrek 2.
A lot of people think that Python, which is becoming more and more popular, is compiled to machine code and therefor should be fast, it's not and it isn't.
A lot of people use Ruby on Rails for web work but if you have a choice for new work I don't see it beating Seaside on Smalltalk. My oldest son's company uses Ruby on Rails. From time to time he tells me about changes being made to Ruby to make it look more like Smalltalk. I think most Smalltalk derivatives have left things out (like blocks of code being objects or some data types not being objects) only to learn later, Smalltalk had it right.
A lot of people use Ruby on Rails for web work but if you have a choice for new work I don't see it beating Seaside on Smalltalk. My oldest son's company uses Ruby on Rails. From time to time he tells me about changes being made to Ruby to make it look more like Smalltalk. I think most Smalltalk derivatives have left things out (like blocks of code being objects or some data types not being objects) only to learn later, Smalltalk had it right.
Java and C# look impressive but is development as easy in them as it is in Smalltalk?
Lou
Seth Berman
Jun 10, 2019, 4:52:27 PM6/10/19
to VA Smalltalk
Hi Lou,
No problem...fun exercise.
I think the canonical version of python that everyone uses (CPython) is not that fast...its kind of a slow C interpreter.
However, there are other folks that make faster versions of python...but there are other trade-offs if you choose them over CPython.
I just installed and tried PyPy which is python with a JIT compiler and this was the result:
Python - PyPy 7.1.1-beta0 with MSC v.1910 32 bit - 172ms (vs 703ms for CPython).
This is clearly a big improvement, though still not as fast as VAST 9.x JIT 32-bit.
Perhaps we should have created a really slow interpreter so we also could claim 3x, 4x and beyond for our 1st tier JIT:)
I use Visual Studio's for vm development but I really don't do a lot of C# development. So other than familiarity with the .NET clr and C# syntax and semantics...I can't say I understand the "feel" of development for it.
Java I understand better since I spent a lot of time developing with it. It's not like I felt unproductive with java, but certainly not as productive as I am with a live system like Smalltalk.
- Seth

Vizio Costar
Jun 11, 2019, 4:21:34 AM6/11/19
to VA Smalltalk
> Java and C# look impressive but is development as easy in them as it is in Smalltalk?
The answer is 'no' for Java. I don't want to start an ancient history discussions, so, I'll limit my comments.
IBM kept stats on their projects and ST had the highest productivity, Lotus Notes #2, Java/Eclipse #3, and the compiled languages, like C, were at the bottom. Java/Eclipse was about half as productive as ST.
... but there is more to it then that such as CM, Envy vs Maven, etc. Maven is quite a shock when coming from the Envy world. Maven is an XML file where one specifies, amongst other things, what version of what software package to use. Here is an updated tut on it should you decide to give yourself a headache,

Simon Franz
Jun 14, 2019, 3:34:16 PM6/14/19
to VA Smalltalk
These are really good improvements!
Did you also run your code in VA 8.6.3 or 9.1 and measured the time? Would it be interesting to see that in comparison to other programming languages as well to 9.2 with the coming changes with the JIT-Compiler.
- Simon
Seth Berman
Jun 14, 2019, 4:12:53 PM6/14/19
to VA Smalltalk
Greetings Simon,
Yes, for this particular benchmark and what was involved (iteration, at/atPut prims, optimized integer arith) I suspected 2x for 9.1 and about 1x for 8.6.3. And it turned out to be pretty much exactly that.
Had it involved any appreciable amount of float calculations or certain optimized iteration statements (that I didn't see), the IBM vm would have lost by a landslide...not even close.
And sometimes its statement by statement (I give an example at the end).
I wish I could do 8.6.3 on 64-bit...but of course that's not possible so I'm stuck with a 32-bit only comparison.
Had it involved any appreciable amount of float calculations or certain optimized iteration statements (that I didn't see), the IBM vm would have lost by a landslide...not even close.
And sometimes its statement by statement (I give an example at the end).
I wish I could do 8.6.3 on 64-bit...but of course that's not possible so I'm stuck with a 32-bit only comparison.
Some interesting notes:
- IBM vm was 32-bit only, had 1st tier JIT (typically means non-optimizing compiler and designed to generate the native code quickly)
- IBM vm was i386 optimized and lacked some of the necessary optimizations for deeper pipeline processors that came in 486 and later.
- IBM vm was 32-bit only, had 1st tier JIT (typically means non-optimizing compiler and designed to generate the native code quickly)
- IBM vm was i386 optimized and lacked some of the necessary optimizations for deeper pipeline processors that came in 486 and later.
- IBM vm code generator is all in ENVY/Smalltalk. It is essentially unrestricted and has no runtime rules, it can jump wherever it wants and even use ESP stack pointer as a general purpose register (something we can't do in llvm) Doesn't much matter for 64-bit, but does for 32-bit x86 where you barley have any registers to work with.
- LLVM vm is 32-bit and 64-bit, and now has a similar 1st tier JIT with more optimizations applied
- LLVM vm is optimized for modern processors and generates far superior code
- LLVM vm can not use the ESP register like IBM vm, so for some small sections of code it might not be possible to beat IBM (because x86 is so register starved). But usually, the LLVM code gen quality makes up for this.
- LLVM vm code generator is in C++, and we use C++ Classes and C++ Lambdas to recreate the majority of the ENVY/Smalltalk description of the model. Not quite as nice, but we can map one to the other easily enough.
- LLVM vm is coded using a pure SSA style. This caused issues so we created additional infrastructure to allow us to code SSA without so many mistakes.
- LLVM vm uses a function-oriented design pattern. Bytecodes, Primitives, Return Points...everything is a function. Each function uses a special calling convention we created and is the only patch to LLVM base code. This calling convention helps us create guaranteed tail-call optimized functions and pin registers with calling convention argument specification (arguments like pc, sp, bp...). This is also how we tell LLVM to perform jmp assembly statements instead of call statements as it transitions from bytecode to bytecode in the interpreter.
- LLVM vm 1st tier JIT is generated by doing a second pass on the Interpreter (during compile time) which generates the native templates for all bytecodes, return points, prims... So we reuse the same code as the Interpreter for the most part to build the JIT, but the template versions of a bytecode will look slightly different than what the Interpreter will run.
As I mentioned, for a given benchmark you really have to almost inspect it statement by statement. For example, try this in <= 8.6.3 and 9.1. 8.6.3 should win but it doesn't...and this is because there is just some bad code generation in the IBM vm and some really good code generation in LLVM. There are lots of examples like these...which is why I like to see this run on larger applications and hear feedback. So I look forward to ECAP2 feedback.
"Try in 8.6.3 and 9.1...8.6.3 should win...but won't (or didn't on my machine)"
| t |
t := Time millisecondsToRun: [
100 timesRepeat: [| total |
total := 0.
1 to: 1000000 do: [:each | total := total + each]]
].
t := Time millisecondsToRun: [
100 timesRepeat: [| total |
total := 0.
1 to: 1000000 do: [:each | total := total + each]]
].
Seth Berman
Jun 14, 2019, 4:13:49 PM6/14/19
to VA Smalltalk
Hi All,
I suspect on Monday.
Good weekend to all
- Seth
Seth Berman
Jun 14, 2019, 4:21:23 PM6/14/19
to VA Smalltalk
Hello Simon,
I just saw your statement "Would it be interesting to see that in comparison to other programming languages as well to 9.2 with the coming changes with the JIT-Compiler."
Did you see the benchmarks I did later in this thread? Or did you mean something else?
- Seth
On Friday, June 14, 2019 at 3:34:16 PM UTC-4, Simon Franz wrote:
Simon Franz
Jun 15, 2019, 4:35:47 PM6/15/19
to VA Smalltalk
Hi Seth,
I wasn't sure if the noted performance of 9.x (interpreter) is the same speed as in VA 8.6.3 (surely on 32 bit). Is there also an speed increase from VA 8.6.x to VA 9.x which might be visible in a benchmark?
VAST 9.x 32-bit (Interpreter) - 250ms
VAST 9.x 64-bit (Interpreter) - 266ms
I've seen the benchmarks and i'm really exited about the new JIT-Compire :-)
- Simon

{kind=link}
Wayne Johnston
Jun 17, 2019, 10:35:51 AM6/17/19
to VA Smalltalk
Very much looking forward to trying this 9.2.
Is there a hint of what the contents of the migration guide will be for this release?
Thought I'd look at the web site - it has been down at least a couple hours.
Seth Berman
Jun 17, 2019, 11:21:19 AM6/17/19
to VA Smalltalk
Hi Simon,
The basic bytecode processing engine and message send speed of 9.x 32-bit (interpreter) is not as fast as that of 8.6.3 32-bit (JIT).
That will change with 9.2 32-bit (JIT) which will make both of these as fast.
Numeric operations and primitives code is much faster in 9.x 32-bit (interpreter) than in 8.6.3 32-bit (JIT).
9.2 32-bit (JIT) makes this even faster
Memory management (allocation / GC) is faster in 9.x in general.
9.2 32-bit (JIT) allocation will be faster, GC algorithms will be the same as 9.x
Linux abt script always disabled jit (-mcd) because of some issue with the IBM JIT in a development environment. (see abt script at the bottom)
In 9.2, we remove that conditional....JIT is always enabled in all contexts on all platforms.
At ESUG and FAST conferences this year, Alexander Mitin (our Lead VM engineer) will be presenting all the work that has been done over the last
8 months that has led to the 9.2 JIT and some benchmarks.
Seth Berman
Jun 17, 2019, 11:25:48 AM6/17/19
to VA Smalltalk
Hi Wayne,
Site should be back up.
No, we don't have migration guides updated for ECAP previews.
But, I actually can't think of many off the top of my head.
The JIT vm, believe it or not, is pretty much just copy/replace esvm40.dll (vm) and esvm40.bin (native templates) into existing VA install.
I think I copied them before into some old 7.0 installs and that worked (but not tested).
I think I copied them before into some old 7.0 installs and that worked (but not tested).
Obviously, you should be making a backup of anything that you replace:) Just saying...
- Seth
Simon Franz
Jun 17, 2019, 3:47:39 PM6/17/19
to VA Smalltalk
Thanks, Seth, this is exactly the info I wanted to know. I am very curious about the news of 9.2.
Reply all
Reply to author
Forward
0 new messages