Wikipedia, Text Slicer Edition & Pandoc
616 views
Skip to first unread message

Steven Schneider
Feb 21, 2018, 9:18:27 AM2/21/18
to TiddlyWiki
Hi folks,
I wanted to open / revive a conversation about using TiddlyWiki to add functionality to other types of documents, in this case, Wikipedia pages. In the DesignWriteStudio class, we are currently working on importing wikipedia tables through google sheets, as well as "tiddlywiki-fying" wikipedia pages by excising and tagging paragraphs, but that will only get us so far.
I'm interested in being able to take a wikipedia page like the timeline of Russia interference in the 2016 United States elections and create tagged tiddlers for each of the, say, 100+ individuals and 100+ events.
To that end: I was wondering if anyone has experimented with or mastered the art of ingesting Wikipedia pages (perhaps using text slicer edition or perhaps using pandoc as an intermediary) into TiddlyWiki?
Along those lines: has there been any movement to create a Tiddlywiki import/export for pandoc, or to write a custom pandoc filter for wikitext? Pandoc currently supports "Markdown (including CommonMark and GitHub-flavored Markdown), reStructuredText, AsciiDoc, Emacs Org-Mode, Emacs Muse, Textile, txt2tags, MediaWiki markup, DokuWiki markup, TikiWiki markup, TWiki markup, Vimwiki markup, and ZimWiki markup," but not tiddlywiki/wikitext.
Thanks!
//steve.

@TiddlyTweeter
Feb 21, 2018, 9:41:02 AM2/21/18
to TiddlyWiki
Steve
IMO here you are talking about a specificity of import. Text slicer alone is unlikely to be able to do that as its a generic tool for effective slice on normal universally repeated elements.
But a specific Wikipedia page de-reconstructor needs pay attention to its specific layout. I think it would need to be A bespoke solution.
Pandoc is one route. Probably over complex(?). Another route is to use Regular Expressions within TW.
BJs FLEXITY plugin I have been crapping on about for months. It is excellent. It provides a new Content Type that allows you to run raw JavaScript regex over a Tiddler before the main parser kicks in. Its a possible solution within TW for this issue. It takes a while to grasp how it works. And to get the best from it you'd need understand basic regex syntax.
Anyway here it is: http://flexibility.tiddlyspot.com/
Best wishes
Josiah
IMO here you are talking about a specificity of import. Text slicer alone is unlikely to be able to do that as its a generic tool for effective slice on normal universally repeated elements.
But a specific Wikipedia page de-reconstructor needs pay attention to its specific layout. I think it would need to be A bespoke solution.
Pandoc is one route. Probably over complex(?). Another route is to use Regular Expressions within TW.
BJs FLEXITY plugin I have been crapping on about for months. It is excellent. It provides a new Content Type that allows you to run raw JavaScript regex over a Tiddler before the main parser kicks in. Its a possible solution within TW for this issue. It takes a while to grasp how it works. And to get the best from it you'd need understand basic regex syntax.
Anyway here it is: http://flexibility.tiddlyspot.com/
Best wishes
Josiah
@TiddlyTweeter
Feb 21, 2018, 9:52:55 AM2/21/18
to TiddlyWiki
Steve
Footnotes to last.
1 - You could use Text-Slicer or TiddlyClip for the first step. Then finesse with Flexity?
2 - I believe BJ is working on a new version of TiddlyClip that will include greater scope as a customised "screen-scraper". I don't know the details.
Best wishes
Josiah
Footnotes to last.
1 - You could use Text-Slicer or TiddlyClip for the first step. Then finesse with Flexity?
2 - I believe BJ is working on a new version of TiddlyClip that will include greater scope as a customised "screen-scraper". I don't know the details.
Best wishes
Josiah

BurningTreeC
Feb 21, 2018, 10:27:21 AM2/21/18
to TiddlyWiki
Hi Steve,
I recently took a look at the pandoc github repository to see what's needed to maybe include tiddlywiki syntax
I didn't have that much time to get into it...
I think in a collaborative effort we could gather informations at one place that help make it clear a) if it's possible and if then b) how it can be done
We could then, if possible, see if we can make a pull request there to include tiddlywiki syntax
I think that would be a great thing, like https://www.youtube.com/watch?v=R3O--B-3R3E that great
I recently took a look at the pandoc github repository to see what's needed to maybe include tiddlywiki syntax
I didn't have that much time to get into it...
I think in a collaborative effort we could gather informations at one place that help make it clear a) if it's possible and if then b) how it can be done
We could then, if possible, see if we can make a pull request there to include tiddlywiki syntax
I think that would be a great thing, like https://www.youtube.com/watch?v=R3O--B-3R3E that great

TonyM
Feb 21, 2018, 1:50:18 PM2/21/18
to TiddlyWiki
As much as I like tiddlywiki to be self sufficent, including its wikitext rules in a utility makes sence because it enables conversion between many different formats.
Tony
Tony

Mark S.
Feb 22, 2018, 11:17:25 PM2/22/18
to TiddlyWiki
It kind of looks like you would need to take an existing pandoc writer (maybe markdown) and rewrite it as a new TiddlyWiki module. But ... it's all written in Haskell. It would be quite a time investment to get up to speed with Haskell (unless of course you already know it) enough to make the changes. And of course you would then have to compile your own pandoc, which would probably be easiest on Linux.
Another approach would be to use "filters". Filters change the AST (pandoc's internal markup language). The filters are middlemen -- they don't create output. It looks like you might be able to use this to turn elements into text-based elements and then output as text. I asked in the pandoc forum and at least one respondent thought this might work -- with effort. Oh yeah, and in that crazy logic of open source code, the built-in filter language is not Haskell, but Lua. But at least you wouldn't have to compile the resulting code.
And after all that, how many people would use it? Five?
-- Mark
Another approach would be to use "filters". Filters change the AST (pandoc's internal markup language). The filters are middlemen -- they don't create output. It looks like you might be able to use this to turn elements into text-based elements and then output as text. I asked in the pandoc forum and at least one respondent thought this might work -- with effort. Oh yeah, and in that crazy logic of open source code, the built-in filter language is not Haskell, but Lua. But at least you wouldn't have to compile the resulting code.
And after all that, how many people would use it? Five?
-- Mark
BurningTreeC
Feb 23, 2018, 1:50:10 AM2/23/18
to TiddlyWiki
I'm on Linux, now the next 10 minutes I'm doing https://wiki.haskell.org/Learn_Haskell_in_10_minutes
Then for those five org-mode users it'll be time :D
No, seriously, I think also if there won't be many users, having it on the list could still be good in terms of "showing that there's also tw"
Then for those five org-mode users it'll be time :D
No, seriously, I think also if there won't be many users, having it on the list could still be good in terms of "showing that there's also tw"
Mark S.
Feb 23, 2018, 9:15:43 AM2/23/18
to TiddlyWiki
Ok, so we'll see you back in, um, 20 minutes?
I used org-mode for awhile. But it was too easy to accidentally bleed one entry into another, and there are were (are?) no good Android apps.
For publicity, what's needed is to discover that some prominent politician or celebrity uses TW.
-- Mark
I used org-mode for awhile. But it was too easy to accidentally bleed one entry into another, and there are were (are?) no good Android apps.
For publicity, what's needed is to discover that some prominent politician or celebrity uses TW.
-- Mark
BurningTreeC
Feb 23, 2018, 9:51:07 AM2/23/18
to TiddlyWiki
Ok, so we'll see you back in, um, 20 minutes?
uhm...
I used org-mode for awhile. But it was too easy to accidentally bleed one entry into another, and there are were (are?) no good Android apps.
For publicity, what's needed is to discover that some prominent politician or celebrity uses TW.
@TiddlyTweeter
Feb 23, 2018, 11:35:13 AM2/23/18
to TiddlyWiki
Steve, Mark.S, TonyM, BTC & all.
Returning to the theme. I'm sure Pandoc to TW would be a great plus to ease migration to TW. In terms of conversion TWC & TW5 variants would be awesome. TWC is still live and significant.
My concern about it is NOT Pandoc to TW, its TW to Pandoc. BOTH ways conversion is important for Pandoc.
I'm not fully convinced its workable. TW differs from most Pandoc formats in having a dynamism that is significant to looks and function in a way most Pandoc formats don't have. Pandoc is largely pretty static document formats.
TW can modify its own form so I'm kinda AS interested in what Pandoc can do with TW to get it into other formats as I am the other way round. I'm not yet convinced that it might not be a disappointing experience TW -> Other.
I guess it would be some kinda gateway to greater uptake to TW. But I do think its a bit more complicated than it might look on first take. That's in addition to the Haskell hassle.
Best wishes
Josiah
Returning to the theme. I'm sure Pandoc to TW would be a great plus to ease migration to TW. In terms of conversion TWC & TW5 variants would be awesome. TWC is still live and significant.
My concern about it is NOT Pandoc to TW, its TW to Pandoc. BOTH ways conversion is important for Pandoc.
I'm not fully convinced its workable. TW differs from most Pandoc formats in having a dynamism that is significant to looks and function in a way most Pandoc formats don't have. Pandoc is largely pretty static document formats.
TW can modify its own form so I'm kinda AS interested in what Pandoc can do with TW to get it into other formats as I am the other way round. I'm not yet convinced that it might not be a disappointing experience TW -> Other.
I guess it would be some kinda gateway to greater uptake to TW. But I do think its a bit more complicated than it might look on first take. That's in addition to the Haskell hassle.
Best wishes
Josiah
Mark S.
Feb 23, 2018, 11:54:53 AM2/23/18
to tiddl...@googlegroups.com
This just in from John MacFarlane, the author of Pandoc:
-- Mark
Your best bet is to make a custom lua writer.
pandoc --print-default-data-file sample.lua
will give you a sample lua writer that basically
imitates pandoc's HTML writer. You can modify that
as you see fit. See the manual for instructions
on using lua writers.
-- Mark
Mark S.
Feb 23, 2018, 12:00:43 PM2/23/18
to TiddlyWiki
Baby steps. The original post was about converting Wikipedia (HTML) into TW format.
For my own use, I have a html2tw regex-based javascript macro that I use inside BJ's web clipper. This works really well with my target sites (though there's always a little clean-up and conversion from remote to local image files). Unfortunately it only works on Wikipedia paragraphs -- for some reason when it sees the main headers it ignores subsequent text. This is the problem with regex-based approaches -- there's always some subtle thing that sends everything off the rails.
-- Mark
For my own use, I have a html2tw regex-based javascript macro that I use inside BJ's web clipper. This works really well with my target sites (though there's always a little clean-up and conversion from remote to local image files). Unfortunately it only works on Wikipedia paragraphs -- for some reason when it sees the main headers it ignores subsequent text. This is the problem with regex-based approaches -- there's always some subtle thing that sends everything off the rails.
-- Mark
@TiddlyTweeter
Feb 23, 2018, 12:24:56 PM2/23/18
to TiddlyWiki
Ciao Mark S.
Totally agree about regex, though I love it, its difficult to use 100% reliably the more generalised the input case is. "Debugging" regex can be seriously difficult. Its easier for "construction-up" as you can have a CLEAR starting point than "strip-drown" of formats that may have one-off complexities that in regex lead to unexpected results.
Right, the original post is about Wikipedia but it HAS to enfold conversion to TW, or something compatible. So TW general conversion does arise, I think, as a, if not THE, central issue.
Best wishes
Josiah
Totally agree about regex, though I love it, its difficult to use 100% reliably the more generalised the input case is. "Debugging" regex can be seriously difficult. Its easier for "construction-up" as you can have a CLEAR starting point than "strip-drown" of formats that may have one-off complexities that in regex lead to unexpected results.
Right, the original post is about Wikipedia but it HAS to enfold conversion to TW, or something compatible. So TW general conversion does arise, I think, as a, if not THE, central issue.
Best wishes
Josiah
Steven Schneider
Feb 23, 2018, 2:15:19 PM2/23/18
to TiddlyWiki
This is quite an interesting conversation, tho not exactly sure where we go with it. I'll look into regexp, though that is a bit complex (both for me, and for my students). I'll update here as I make progress...//steve.
Mark S.
Feb 24, 2018, 12:11:22 AM2/24/18
to TiddlyWiki
The lua filter approach might be made to work. But there's a lot of problems matching HTML from Wikipedia and TW5 markup.
For one thing, WikiPedia (WP) uses anchors and id's to move around the page. You can't use this approach in TW5. So the table of contents becomes effectively static text.
WP likes to nest a lot of <span> tags, and currently I don't see a way to emulate that with the @@ syntax in TW5 markup. The @@ markup also doesn't seem to let you specify more than one class at a time (if someone knows the magic syntax to do otherwise that would be great).
Another question would be, do images link to image on WP's remote home site, or to local files (which you would have to download separately).
-- Mark
For one thing, WikiPedia (WP) uses anchors and id's to move around the page. You can't use this approach in TW5. So the table of contents becomes effectively static text.
WP likes to nest a lot of <span> tags, and currently I don't see a way to emulate that with the @@ syntax in TW5 markup. The @@ markup also doesn't seem to let you specify more than one class at a time (if someone knows the magic syntax to do otherwise that would be great).
Another question would be, do images link to image on WP's remote home site, or to local files (which you would have to download separately).
-- Mark
BurningTreeC
Feb 24, 2018, 8:31:16 AM2/24/18
to TiddlyWiki
Hi Steven,
originally you've also mentioned the text-slicer plugin and I'd anyway like to figure it out and make it's interactions clearer
I was also thinking about creating something on top of it, but before that I'd have to figure out what all the things are one can do with it,
which input it handles and what we can do with its output
As I understand, it splits html to small chunks that are reusable afterwards, so they're all single tiddlers
The Pandoc could be a translator from other formats to html, and the text-slicer the final converter to tiddlers
If this is how it works then we could focus on creating some UI and workflows on top of it for various input types,
That would be a great knowledgebase I think
Simon
originally you've also mentioned the text-slicer plugin and I'd anyway like to figure it out and make it's interactions clearer
I was also thinking about creating something on top of it, but before that I'd have to figure out what all the things are one can do with it,
which input it handles and what we can do with its output
As I understand, it splits html to small chunks that are reusable afterwards, so they're all single tiddlers
The Pandoc could be a translator from other formats to html, and the text-slicer the final converter to tiddlers
If this is how it works then we could focus on creating some UI and workflows on top of it for various input types,
That would be a great knowledgebase I think
Simon

Alex Hough
Feb 28, 2018, 3:04:00 AM2/28/18
to TiddlyWiki
Hi Steve,
I've been experimenting with text slicer and Sublime text editor.
Basically I am learning to use Sublime to help prepare cut and pasted text for text-slicer.
Using multiply cursers, adding spaces at the end of paragraph so that the text slicer makes sense of the spaces
Alex
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+unsubscribe@googlegroups.com.
To post to this group, send email to tiddl...@googlegroups.com.
Visit this group at https://groups.google.com/group/tiddlywiki.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/4b848644-a67e-4cef-8809-862f25680ca0%40googlegroups.com.
Mark S.
Mar 2, 2018, 9:05:52 PM3/2/18
to TiddlyWiki
Here's where I'm at with using lua filters inside of Pandoc. The script is attached. It can be invoked by:
pandoc -f html -t TW5.lua myfile.html -o myfile.tid
or
env basename="/mylocaldir/" pandoc -f html -t TW5.lua myfile.html -o myfile.tid
... if you want to specify a basename file to be appended to links -- not that it does much good with Wikipedia links since they seem to use some internal linking mechanism.
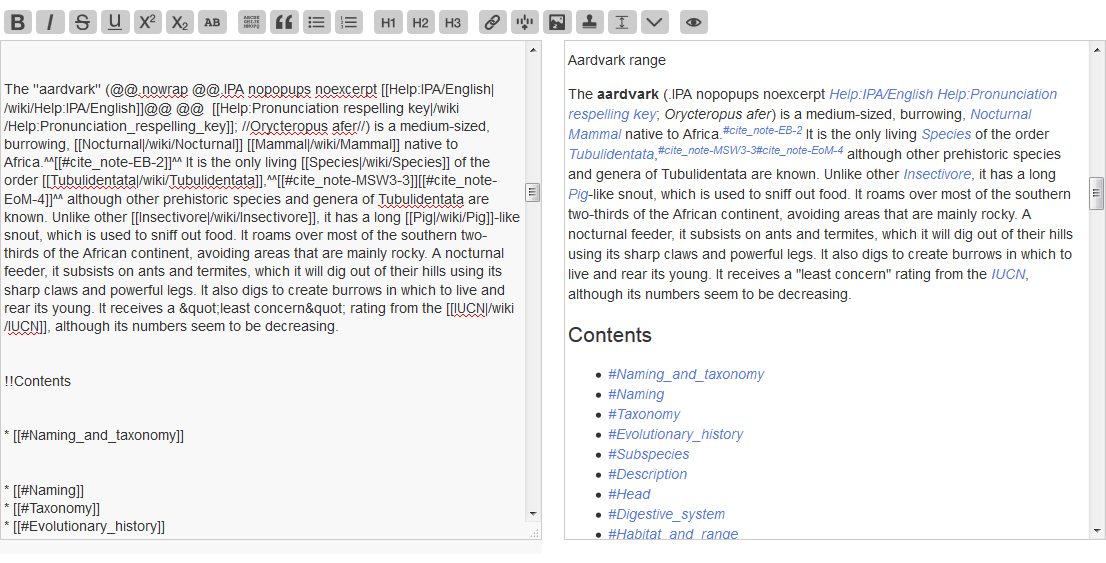
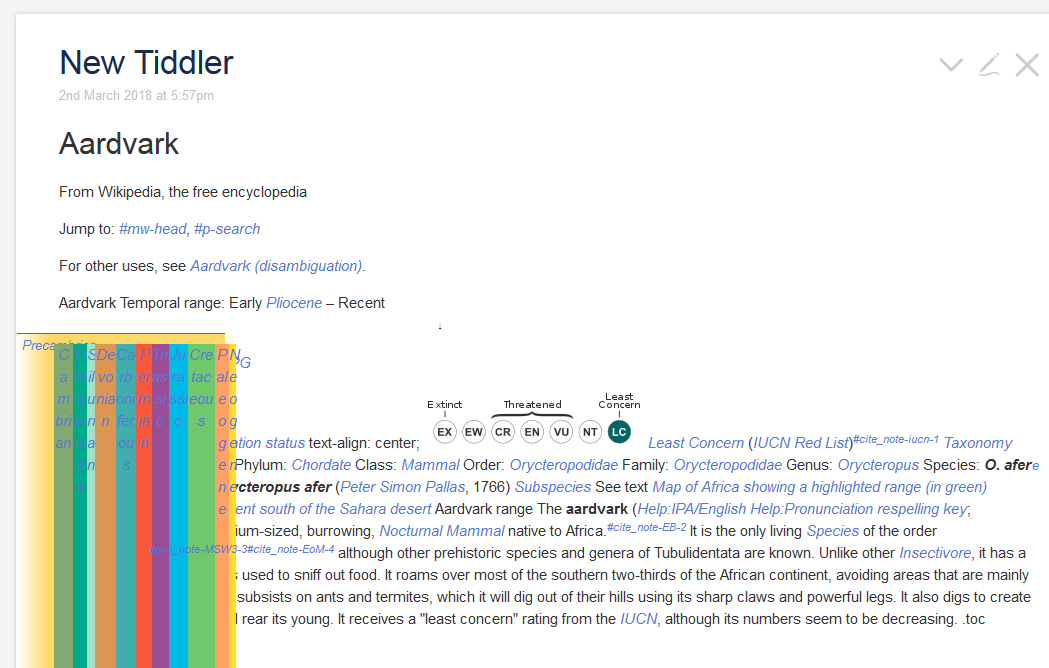
I left <spans> as html since TW has no way of doing nested spans and lua-filters doesn't seem to have a way to tell you when you're inside a nested span. As you can see from the screen shot, without the right classes and context, the output from WP may not play nicely inside of TW.
Probably someone would need to tailor the script for whatever platform they're looking at.
This is very beta. Not sure if it's worth pursuing further, but it was interesting. Probably adding a template wrapper so that the resulting file is a draggable tid would be a next step.
-- Mark
pandoc -f html -t TW5.lua myfile.html -o myfile.tid
or
env basename="/mylocaldir/" pandoc -f html -t TW5.lua myfile.html -o myfile.tid
... if you want to specify a basename file to be appended to links -- not that it does much good with Wikipedia links since they seem to use some internal linking mechanism.
I left <spans> as html since TW has no way of doing nested spans and lua-filters doesn't seem to have a way to tell you when you're inside a nested span. As you can see from the screen shot, without the right classes and context, the output from WP may not play nicely inside of TW.
Probably someone would need to tailor the script for whatever platform they're looking at.
This is very beta. Not sure if it's worth pursuing further, but it was interesting. Probably adding a template wrapper so that the resulting file is a draggable tid would be a next step.
-- Mark
@TiddlyTweeter
Mar 3, 2018, 1:47:09 PM3/3/18
to tiddl...@googlegroups.com
Ciao Mark S.
I found it interesting. Though I shouldn't pretend I really understand the lua code.
I had a look at WikiPedia HTML. Its a lot cleaner than a lot. I wouldn't say it was easily human readable but it doesn't have the extreme complexities/redundancies(?) so many big traffic sites have.
Its also interesting that lua doesn't seem to cope with nested spans any better than TW.
My ONE wondering about these conversions is whether they should focus on simplifying HTML or producing markup. NOT that I mean they are orthogonal. But rather the question of WHAT to include in the conversion and what to throw away. But, maybe that kind of thought can only be answered in terms of destination usage needs?
Just thoughts
Josiah
I found it interesting. Though I shouldn't pretend I really understand the lua code.
I had a look at WikiPedia HTML. Its a lot cleaner than a lot. I wouldn't say it was easily human readable but it doesn't have the extreme complexities/redundancies(?) so many big traffic sites have.
Its also interesting that lua doesn't seem to cope with nested spans any better than TW.
My ONE wondering about these conversions is whether they should focus on simplifying HTML or producing markup. NOT that I mean they are orthogonal. But rather the question of WHAT to include in the conversion and what to throw away. But, maybe that kind of thought can only be answered in terms of destination usage needs?
Just thoughts
Josiah
Mark S. wrote:
Here's where I'm at with using lua filters inside of Pandoc. The script is attached.
I left <spans> as html since TW has no way of doing nested spans and lua-filters doesn't seem to have a way to tell you when you're inside a nested span.
As you can see from the screen shot, without the right classes and context, the output from WP may not play nicely inside of TW.
Probably someone would need to tailor the script for whatever platform they're looking at.
Not sure if it's worth pursuing further, but it was interesting.
Mark S.
Mar 6, 2018, 6:22:57 PM3/6/18
to tiddl...@googlegroups.com
The original request was to split off the WP article into separate tids. If you replace the BulletList section of the code I previously provided with this:
and feed it just an HTML file containing the "Players" from the article specified, you will get a directory full of numbered tid files that can be dnd into TW resulting in per-name tiddlers tagged with "People".
The timeline elements were not as regular as the "Players" elements, so they would be harder to work out. But everything in principle should be here for anyone that wants to follow-up.
I think there's probably a better approach using just Javascript macros and TW, but there you are.
-- Mark
function BulletList(items)
local buffer = {}
local name = ""
local cnt = 0
for _, item in pairs(items) do
buffer = {}
name = string.match(item, "([%w%s%.]+),")
if name then
cnt = cnt + 1
buffer = {}
filename= cnt .. ".tid"
table.insert(buffer, "title: " .. name )
table.insert(buffer, "tags: " .. "People" )
table.insert(buffer, "")
table.insert(buffer, item)
local file = io.open(filename, "w")
file:write(table.concat(buffer,"\n"))
file:close()
end
end
return table.concat(buffer)
end
and feed it just an HTML file containing the "Players" from the article specified, you will get a directory full of numbered tid files that can be dnd into TW resulting in per-name tiddlers tagged with "People".
The timeline elements were not as regular as the "Players" elements, so they would be harder to work out. But everything in principle should be here for anyone that wants to follow-up.
I think there's probably a better approach using just Javascript macros and TW, but there you are.
-- Mark
Steven Schneider
Mar 7, 2018, 2:51:08 PM3/7/18
to TiddlyWiki
Thanks, Mark. I'm working on a perl script to manage this (since I don't know JavaScript, but vaguely remember perl). It would seem that it will be necessary to rely on the willingness of the wikipedia editors to maintain their page in standard structure. And every wikipedia page will be different, though there should be some overlaps across pages.
This is an interesting project, but one that will take a bit of a backseat for a while, unless I continue to be interested in the substance...
//steve.

{kind=link}
{kind=link}
Diego Mesa
Sep 7, 2018, 3:09:40 PM9/7/18
to TiddlyWiki
Hey Mark,
Im not at all familiar with haskell, lua writers, etc. but do you think this is enough to open it up to the pandoc community? I think it would be GREAT if .tid was a 100% supported member of the pandoc community, letting us import from essentially anywhere directly into .tid
Mark S.
Sep 7, 2018, 4:28:35 PM9/7/18
to TiddlyWiki
What?! I learned it in an afternoon 6 months ago ... not remembering that much ;-)
The lua filter I made might be useful to someone who knew Haskell and Pandoc better as a starting guide. I had the impression that LUA filters were not first-class citizens of Pandoc so they might not be willing to grant it an official place in the pantheon of converters without "real" Haskell code. But you could ask.
Have fun,
-- Mark
Diego Mesa
Aug 4, 2020, 5:38:33 PM8/4/20
to TiddlyWiki
Also reviving this thread/conversation, as it relates to getting TW integrated into pandoc, opening up a much wider world of content!
TW Tones
Aug 4, 2020, 8:32:59 PM8/4/20
to TiddlyWiki
I second that!
TiddlyWiki needs to be in the list of converters,
Ideally someone may be able to implement Pandoc in Tiddlywiki so it could become a markdown tool extraordinaire.
Regards
Tony
Reply all
Reply to author
Forward
0 new messages