
Arlen Beiler

TonyM
- Allow an online readlony hosted wiki to connect to a database and with the right credentials save changes to tiddlers in an sql database and reload them as needed somewhat like Browser local storage does.
- Store all of the wiki in a database. Or perhaps with the javascript or core in a file to help launch the wiki.
- I believe there is a possibility for users to easily install SQL DB's they can connect to locally (Device or LAN) and overcome the limitations of browser local storage with trusted persistent storage (We can possible find multiple OS installs for this).
- One minimal tiddlywiki could be configured to connect to more than one database, but one at a time, so the user or designer selects which database they are using (Like CouchDB), thus each user could perhaps have their own version of a tiddlywiki.
Regards

ILYA
Sent from my Android device with K-9 Mail. Please excuse my brevity.

Jed Carty

PMario
ArangoDB is the open-source native multi-model database for graph, document, key/value and search needs.
Foxx is a JavaScript framework for writing data-centric HTTP microservices that run directly inside of ArangoDB.
PMario
PMario
Jed Carty
PMario
Running a ArangoDB for hosting peoples tiddlywiki like tiddlyspot would probably work well, I am less certain about local installations.

Mark S.
Jed Carty
Arlen Beiler
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/1fb383cf-b1d0-4cd0-9768-a6f315076b53%40googlegroups.com.
Mark S.
TonyM
TonyM
Sorry. Mobile gg can be a pain.
I understand Jed has done a lot of on securing bob when internet facing.
So what I am asking is if node where more common on hosting and safe to open to the internet could we not focus on a smaller subset of technologies with similar outcomes?
Of course we value a diversity of solutions.
Arlen Beiler
- First we need to "invent" client-only data folders and implement them.
- Second, we need to attach a more robust storage system that isn't encumbered by the various file systems. This would allow us to implement multi-user and version control quite a bit easier.
- Third, we need to implement this in PHP as an identical implementation.
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/e7fd7b93-d44d-4de2-bbe5-63492ce18501%40googlegroups.com.

Jeremy Ruston
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/CAJ1vdSS3Z4J5asgfhG82aHK6%2BwRxVwR-kpH%3DvBuea%3DnBD2uBdg%40mail.gmail.com.

Dave
Yay for increased stability (I assume that's what this is about)
1 vote for making this thing a snap or app image or flat pak that an amateur like me could install in an old computer or pi on the home network and see from another network safely.
1 vote for at least being able to act as if tiddlers were still text files you can modify outside the browser (e.g. an API that allows you to modify or create tiddlers from the command line)
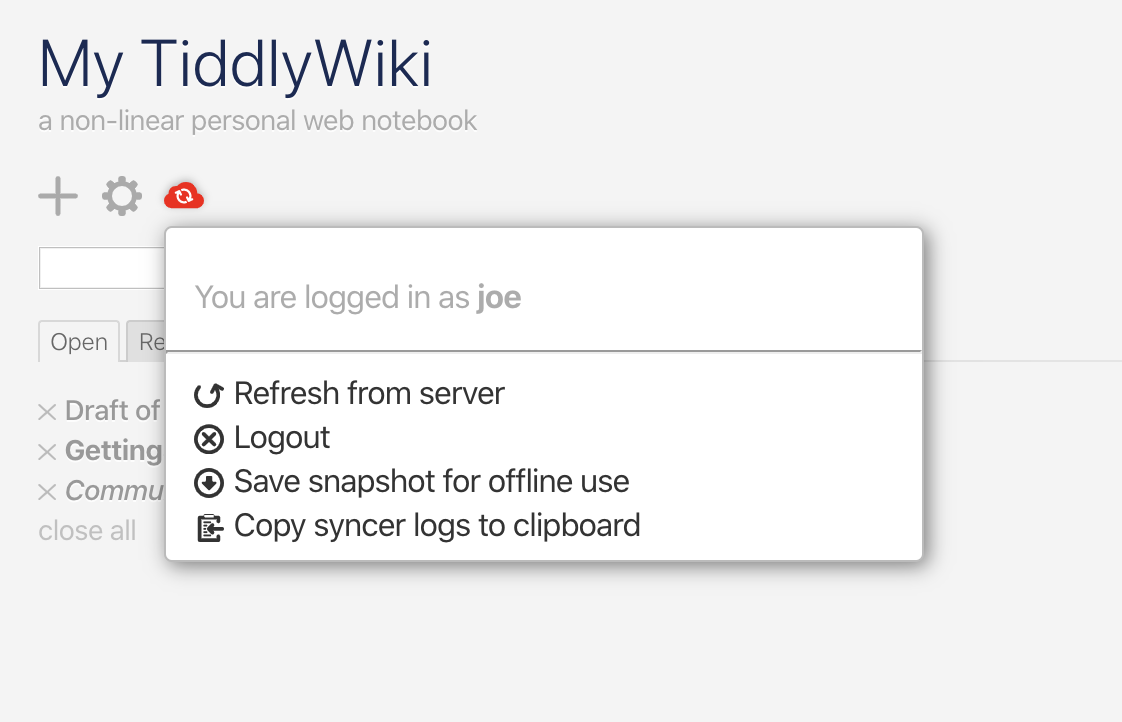
P.s. I love the "save snapshot for offline use later" idea. I've more than once lost work because I didn't notice the big red banner that I was not connected to the server, ha ha
Jed Carty
TonyM
Jed Carty
Jeremy Ruston
It is stored locally on the hard drive like other node wikis, the difference is that this is stored in some database files instead of individual tiddler files. It is not localStorage or a browser based solution.If you use the browser based version of pouchdb it is generally built on top of indexeddb or websql which are just localStorage. It doesn't have any magical fixes and isn't any more persistent than the localstorage plugin. In browser it is just localStorage with a slightly different interface and data model on top of it.To put this online you would end up just duplicating noteself I think.
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/d406b178-989e-4c43-a9e4-a2efb476bdc2%40googlegroups.com.

mauloop
- It has MySQL backend
- It is multiuser and allows concurrent editing
- It has public and private spaces
- It uses the standard Node.js sync-adaptor
- It works with TWC as well
TonyM
I do have a possibly faulty distant memory of a tiddlywiki writing to a Google sheet. I found it curious but it had no use case for me at the time. I will see if I can find anything.
We are spoilt for choice in some ways yet I feel we need to remove a few speed humps.
Regards
Tony

TiddlyTweeter
I do have a possibly faulty distant memory of a tiddlywiki writing to a Google sheet.
Arlen Beiler
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/952167f3-cc7f-44a7-8093-629b2b3ef1a3%40googlegroups.com.
Arlen Beiler
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/cb3cdfd0-e05a-417a-a329-1281e2064ecb%40googlegroups.com.
Arlen Beiler
Arlen Beiler

bimlas
bimlas
bimlas
Jeremy Ruston
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/5bb9370d-0f8c-4623-9033-94c8f7de42c5%40googlegroups.com.
TonyM
we could make use of the sql database that is build to support word press. However as you say using the api would be more sophisticated.
I have played with building custom post types and would be interested in creating a tiddler post type. We could also support plugins as JSON packages.
Tiddlers as a custom post type would make them full word press citizens and enable a meta site. We could store macros doco and more. Perhaps even click and create wiki editions.
See my initial investigation and ideas in the choice of menus. http://www.colabteam.net/tiddlywiki/ I own the domain and hosting. Bit I have not put cloudflare can on yet.
I am all for drinking our own Champaign but until we get multiuser sites worked out I see value in an open id community site. I can install almost anything on my host including node but the security on internet facing node is unknowen to me.
Regards
Tony
Tony
TonyM
I would love to enable contributions to tiddler content via got hub a bit like when you edit tiddlywiki.com but have the changes appear online. We could open our published editions to issues and changes. But your idea sounds even better.
Regards
Tony
PMario
bimlas
Another interesting sync adaptor would be one that retrieved and stored tiddlers via the Wordpress API.
I would love to enable contributions to tiddler content via got hub a bit like when you edit tiddlywiki.com but have the changes appear online.
TiddlyTweeter
I think the main problem with "database backends" (Google Sheets, Wordpress, PouchDB) is that by default they are not accessible as a web page, but everyone has to set up credentials to read and edit the wiki.
A workaround is to add new Personal Access Tokens to the repository, one for each user, so they will have their own "TiddlyWiki password".
bimlas
I think for wider apps the widely used system to login using existing credentials (Google, Twitter, LinkedIn, Facebook etc) for authorisation is easiest.
Arlen Beiler
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/3f3dd877-878f-4ad3-9c4c-4b8bc752567c%40googlegroups.com.
bimlas
WordPress (that's an interesting but very feasible suggestion), Google, and Github all support multi-user editing natively, so each user would have their own login credentials.
Arlen Beiler
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/9d41a1f9-5d7f-4384-8385-2689c29d0cfc%40googlegroups.com.
TonyM
On Saturday, December 7, 2019 at 12:58:58 AM UTC+11, Arlen Beiler wrote:
All three of those sites have an OAuth flow setup for that. Basically you get redirected to the login page and then the login page returns a code back to the client page. Wordpress might just involve using the browser session, though, I’m not sure.
On Fri, Dec 6, 2019 at 07:58 bimlas <bimba...@gmail.com> wrote:
Arlen,--WordPress (that's an interesting but very feasible suggestion), Google, and Github all support multi-user editing natively, so each user would have their own login credentials.True, but we want to access the API with the saver, so we need a Personal Access Token. Or is it possible to use the API with native user credentials?
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddl...@googlegroups.com.

Mohamed Amin
On Friday, November 29, 2019 at 1:59:43 AM UTC+2, Arlen Beiler wrote:
I have a radical proposal which would take data folders to the next level. What if instead of the file system adapter we would write a new adapter to use a database. We could use PouchDB, but I would vote for something much more widespread like SQLite. We could also write it in a generic way that makes it easy to use with the regular SQL databases. It would be easy to build but I would want to make it robust enough to use in a wide array of platforms.I have already worked with the tiddler loading code enough to be certain it is self contained and can easily be made asynchronous to accommodate this feature. Or the preload tiddlers feature can be used, but I think it’s better to separate out the loaders as Jeremy has mentioned.Any thoughts on this or things I should keep in mind as I brainstorm?Arlen