Tesseract won't read some parts of a document
60 views
Skip to first unread message

iparr...@gmail.com
Jul 30, 2014, 3:24:38 AM7/30/14
to tesser...@googlegroups.com
Hi All,
I have been playing around with Tesseract as I need to write some software that uses OCR (preferably open source). So far I have found that Tesseract reads part of my document quite accurately, but ignores some of it completely. Unfortunately the part it ignores is the part I need to read. The following is the image I am trying to read (I have blanked out certain parts to protect identities):
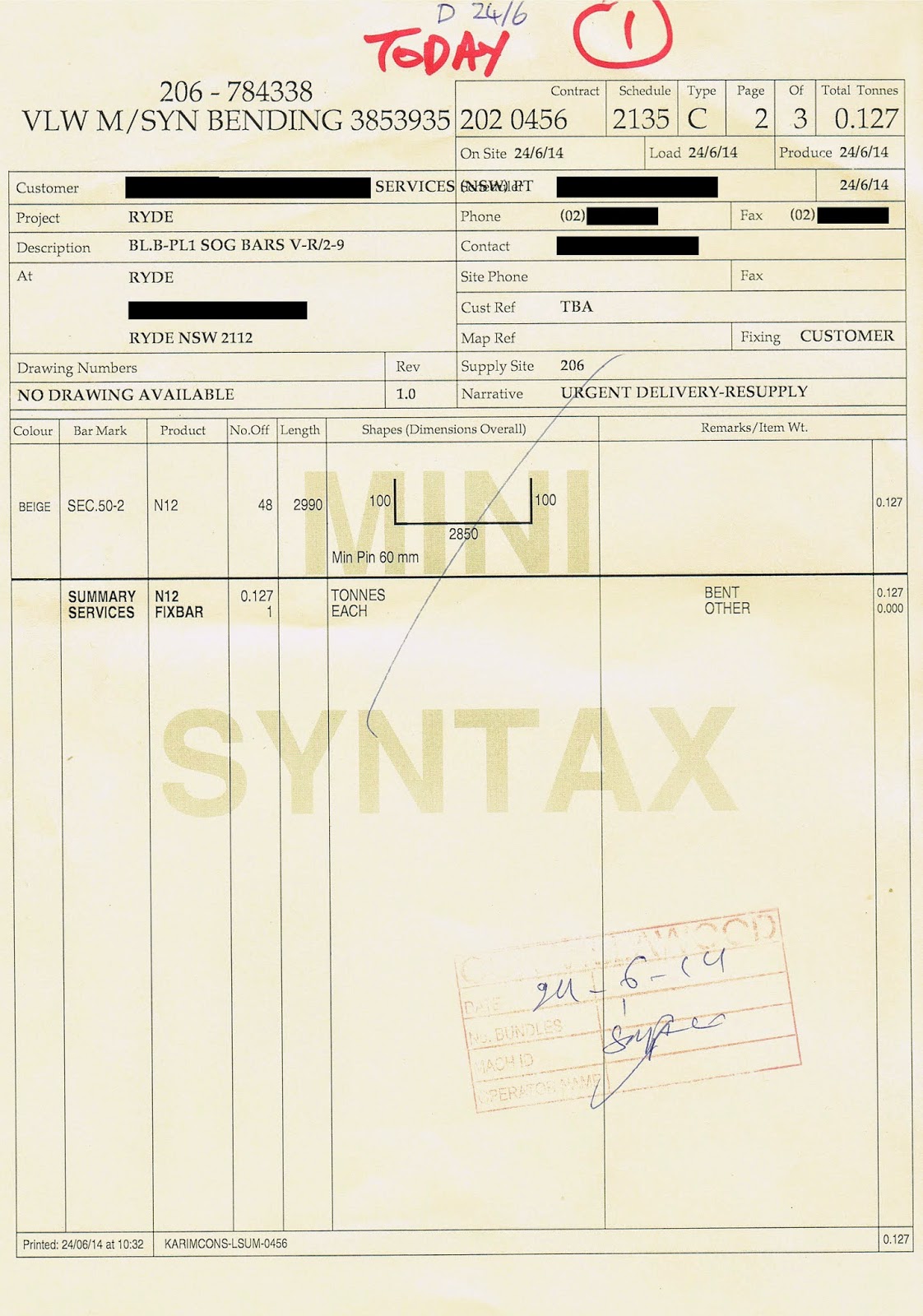
What I need to read is the contract and schedule number at the top of the page just right of centre. These numbers are amongst the biggest font on the page, so Tesseract should have no difficulty reading it given it's accuracy on the smaller fonts. However these numbers seem to get ignored. I am assuming it has something to do with the page layout, or more specifically, assumptions that Tesseract makes about page layout. So my question is, can I force Tesseract not to make these assumptions about page layout? I am not concerned if the text comes out in a strange order as I can procedurally filter out the noise, as long as it reads everything on the page. For reference, this is the output I get when I use Tesseract on this document (note that I have inserted asterisks again to protect identities):
-— ~ Contract Schedule Type Page Of Total Tonnes
On Site 24/6/14 Load 24/6/14 Produce 24/6/14
Customer ******************* SERVICES %EW01(HT ************* 24/6/14
Project RYDE Phone (02) ******** ‘ Fax (02) *********
Description V-R/2-9 Contact 427 210
At RYDE Site Phone Fax
**************** Cust Ref TBA
RYDE NSW 2112 Map Ref Fixing CUSTOMER
Drawing Numbers Rev Supply Site 206
NO DRAWING AVAILABLE 1.0 Narrative URGENT DELIVERY-RESUPPLY
Colour Bar Mark Product No.Off Length Shapes (Dimensions Overall) A Remarks / Item Wt.
BEIGE SEC.50-2 N12 48 2990 0.127
Min Pin 60 mm
I
SUMMARY N12 0.127 TONNES BENT 0.127
SERVICES FIXBAR 1 EACH OTHER 0.000
5 I < ‘“‘
0..//‘
Printed: 24/06/14 at10:32 KARIMCONS-LSUM-0456 0.127

La Monte H. P. Yarroll
Jul 30, 2014, 10:12:43 PM7/30/14
to tesseract-ocr
Tesseract makes an estimation of the size of text in an image. Text which is significantly larger or smaller than that estimate gets ignored. See if you can isolate the larger text in an image by itself, you may find more success.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at http://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/d596be43-4fa3-4cba-ad6c-9c31fe1f068d%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Reply all
Reply to author
Forward
0 new messages