Training error "Couldn't find a matching blob"

Paul Kitchen
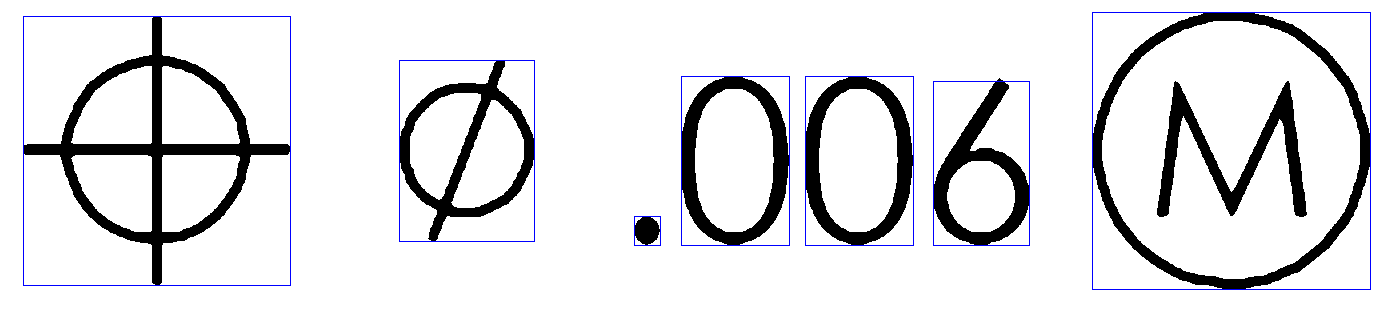
Tesseract Open Source OCR Engine v3.05.01 with LeptonicaPage 1FAIL!APPLY_BOXES: boxfile line 7/Ⓜ ((1153,69),(1431,346)): FAILURE! Couldn't find a matching blobFAIL!APPLY_BOXES: boxfile line 10/Ⓜ ((1993,69),(2268,346)): FAILURE! Couldn't find a matching blobAPPLY_BOXES:Boxes read from boxfile: 10Boxes failed resegmentation: 2Found 8 good blobs.Generated training data for 5 words

Quan Nguyen
Paul Kitchen
Paul Kitchen
1) In file coutln.cpp, function C_OUTLINE::IsLegallyNested(), we assign outer_area() to an inT32, parent_area. Then lower in the function, we multiple child->outer_area() by parent_area. This caused an integer overflow which resulted in a bad sign for the multiplication. The fix was to make parent_area an inT64 so that integer overflow cannot happen.
The two 32-bit integers being multiplied were -51874 and 60218. The true result should be -3123748532 but the maximum result cannot be greater than 2^31 or you will have sign/overflow problems, which is the case here. The computer result was 1171218764, causing the if-statement to go down the wrong path.
dfs

shree

Zdenko Podobny
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/1ef0e822-9518-4cbb-af39-5a8ec6370d00%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Zdenko Podobny
Paul Kitchen
1) In file boxread.cpp, function ReadAllBoxes(), we convert GenericVector<char> to const char* without a trailing ‘\0’. This can cause buffer read overrun inside the call to ReadMemBoxes(). To fix this, change function LoadDataFromFile() to always reserve an extra byte so the caller can add a ‘\0’ if they want. Then in ReadAllBoxes(), append ‘\0’ to the vector after calling LoadDataFromFile(). Here are the fixed functions:
inline bool LoadDataFromFile(const STRING& filename,
GenericVector<char>* data) {
bool result = false;
FILE* fp = fopen(filename.string(), "rb");
if (fp != NULL) {
fseek(fp, 0, SEEK_END);
size_t size = ftell(fp);
fseek(fp, 0, SEEK_SET);
if (size > 0) {
// reserve an extra byte in case caller wants to append a '\0' character
data->reserve(size + 1);
data->resize_no_init(size);
result = fread(&(*data)[0], 1, size, fp) == size;
}
fclose(fp);
}
return result;
}
bool ReadAllBoxes(int target_page, bool skip_blanks, const STRING& filename,
GenericVector<TBOX>* boxes,
GenericVector<STRING>* texts,
GenericVector<STRING>* box_texts,
GenericVector<int>* pages) {
GenericVector<char> box_data;
if (!tesseract::LoadDataFromFile(BoxFileName(filename), &box_data))
return false;
box_data.push_back('\0');
return ReadMemBoxes(target_page, skip_blanks, &box_data[0], boxes, texts,
box_texts, pages);
}
Zdenko Podobny
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/a1b4da88-cb3f-4663-8ffd-d0c911e7b351%40googlegroups.com.

Stefan Weil
Zdenko Podobny
As far as I see 4.0.0 is good. I have sent a pull request which backports the fix from 4.0.0 (a simplified variant of Paul's fix) to 3.05.Stefan
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/e94cad01-0aa2-44c7-8f02-b20188afe91f%40googlegroups.com.
Paul Kitchen
tesseract gdt.symbols.exp0.tif gdt.symbols.exp0 box.trainAnd here is the output:
Tesseract Open Source OCR Engine v3.05.00dev with Leptonica
Page 1
Bad box coordinates in boxfile string! ²²²²▌▌▌▌▌▌▌▌▌▌▌▌▌▌▌╦ÇƧ≡¿←
APPLY_BOXES:
Boxes read from boxfile: 7
Found 7 good blobs.
Generated training data for 3 wordsTesseract Open Source OCR Engine v3.05.00dev with Leptonica
Page 1
APPLY_BOXES:
Boxes read from boxfile: 7
Found 7 good blobs.
Generated training data for 3 wordsPaul Kitchen
box_data.push_back('\0');data->reserve(size + 1);Zdenko Podobny
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/307a7e38-bb5d-4870-ac12-29c735c3c9f8%40googlegroups.com.
Paul Kitchen
Zdenko Podobny
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/37ea9a46-ae6a-4782-b151-9edf90b6f532%40googlegroups.com.
Paul Kitchen
Zdenko Podobny
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/c048b1a4-759e-4e88-8675-a73ef62b69e1%40googlegroups.com.


{kind=link}