Training Sinhala fonts using Tesseract 4.0 version
325 views
Skip to first unread message

isuri anuradha
Sep 23, 2019, 5:37:31 AM9/23/19
to tesseract-ocr
As the initial step I used this command to generate the training data.[1].
rm -rf train/*
tesstrain.sh --fonts_dir fonts \
--fontlist 'FMAbhaya' \
--lang sin \
--linedata_only \
--langdata_dir langdata_lstm \
--tessdata_dir tesseract/tessdata \
--save_box_tiff \
--maxpages 10 \
--output_dir train
I used FMAbhaya font type for the training. But it will prompt error like [2].

Why this kind of error is appearing and what are the solutions to fix this issue?

Shree Devi Kumar
Sep 23, 2019, 5:48:09 AM9/23/19
to tesseract-ocr
You need to use a Unicode font.
Seems like FMAbhaya is not. http://www.sinhalafonts.org/fonts/13142/fm_abhaya.html
lists the fonts used for Tesseract4 alpha
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/f494cac9-3f45-42c9-bce3-e0ae3e9e09a8%40googlegroups.com.
____________________________________________________________
भजन - कीर्तन - आरती @ http://bhajans.ramparivar.com
Isurianuradha96
Sep 23, 2019, 6:08:11 AM9/23/19
to tesser...@googlegroups.com
Thanks a lot.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduU7R2p9TNnFKaM_VVq4E5U8U3BmHaJ21TMHWF_8oF_Csw%40mail.gmail.com.
--
Kind Regards,
Isuri Anuradha.
isuri anuradha
Oct 3, 2019, 4:57:42 AM10/3/19
to tesseract-ocr
As you mentioned tesseract 4.0 is only support for the unicode fonts. What is the procedure if we want to trained with non-unicode fonts. Since most of the documents written in Sri Lanka are in non-unicode fonts and there are lots of historical books available which written on non-unicode forms.
Shree Devi Kumar
Oct 3, 2019, 5:26:30 AM10/3/19
to tesseract-ocr
There is no direct method for training from non-unicode fonts. Tesseract's output is also Unicode text only.
You can work from scanned images of text in non-unicode fonts and provide the unicode transcription of it. You could probably use a legacy to unicode converter for the text.
See https://github.com/tesseract-ocr/tesstrain for training from single line images and its ground truth transcription.
On Thu, Oct 3, 2019 at 2:27 PM isuri anuradha <isurian...@gmail.com> wrote:
As you mentioned tesseract 4.0 is only support for the unicode fonts. What is the procedure if we want to trained with non-unicode fonts. Since most of the documents written in Sri Lanka are in non-unicode fonts and there are lots of historical books available which written on non-unicode forms.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/a280b31b-f2c3-494e-a69e-ac3e36f02382%40googlegroups.com.
Isurianuradha96
Oct 5, 2019, 10:29:23 PM10/5/19
to tesser...@googlegroups.com
Seems this bash script (legacy.sh) is responsible for the mapping of non-Unicode fonts with legacy mapping (as a legacy to Unicode converter). And seems this script file is responsible for the generation of the box,tif and lstmf files. Am I right? so where should I place this script file in tesseract? or should I directly run this before the generation of the
box,tif and lstmf files? Please correct me if my understanding is wrong.
Thank you.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduU%3D7e_BUWrUhzhj4uRd%3DAXXi_46ewkSefUjtu2P69pXOQ%40mail.gmail.com.
Shree Devi Kumar
Oct 6, 2019, 3:14:42 AM10/6/19
to tesseract-ocr
This requires you to create three input files.
1. List of legacy fonts, eg. FM series which all use same mapping for Sinhala
2. Training text in legacy font, usually it will show up as garbled English
3. The above legacy text converted to Unicode, using an existing legacy to Unicode converter, these are available online
Using these 3 files, this script will generate tif image files, wordstr box files, lstmf files, it will also create a unicharset and all-lstmf file.
You can use it in conjunction with tesstrain repo . I plan to add a pull request to the repo with the script along with some documentation.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7D0Dj4G3-FTzuVQy9vq_efYr_OxOGE%3D5%3Ddw%3D1Pyptbu0g%40mail.gmail.com.
Isurianuradha96
Oct 6, 2019, 5:42:15 PM10/6/19
to tesser...@googlegroups.com
Thanks a lot. Similarly as mentioned in above, can other non-unicode fonts also be trained by following the similar way?
Looking forward a reply. Thank you.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduXGAwRCa3HCPZHHgt13K8%2B%3DhfPEbcak81Y6JBLnZ2rjdA%40mail.gmail.com.
Isurianuradha96
Oct 6, 2019, 10:33:10 PM10/6/19
to tesser...@googlegroups.com
I have a small dout related to the 'PREFIX' parameter in legacy.sh. Since for FM models you have entered FM as the value to the prefix param. But for other non-unicodes (which are not a FM models) how we need to change that prefix value? and also I tried to execute the legacy. sh file. But it gave me error like image [1]. I change the font dir too [2]. what is the reason for that and how to fix it?
[1].

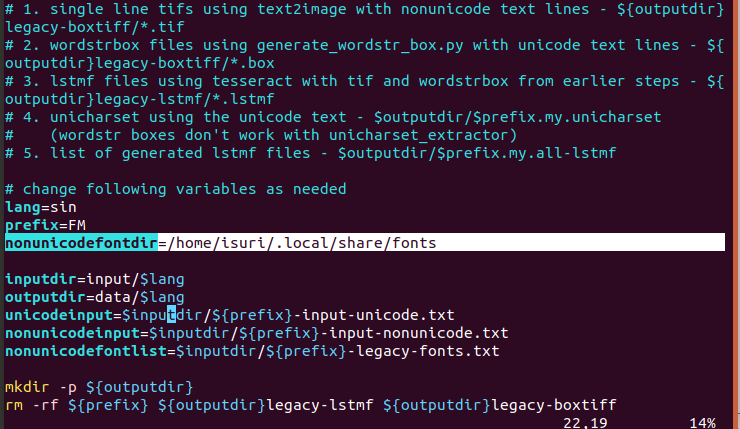
[2].
Shree Devi Kumar
Oct 7, 2019, 1:38:14 AM10/7/19
to tesseract-ocr
You can assign any unique label to prefix and create the required files in input directory to match the names.
How are you running the bash script? bash legacy.sh
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7D%2BHpL3fPTNzuZZ%3DZ10MFksV_LsPn%3D7HQtU8DDbgP3-NA%40mail.gmail.com.
Isurianuradha96
Oct 10, 2019, 6:11:22 AM10/10/19
to tesser...@googlegroups.com
Thanks a lot. But we have a dout on creating the model since in here each sentence is converted into box, tiff and lstmf. So how should we continue the process to make the model?
And also can't we add multiple fonts in the process of creating model. At the moment we are using like the image [1]. If we want to add more fonts to parameter --fontlist how should we proceed?
[1].
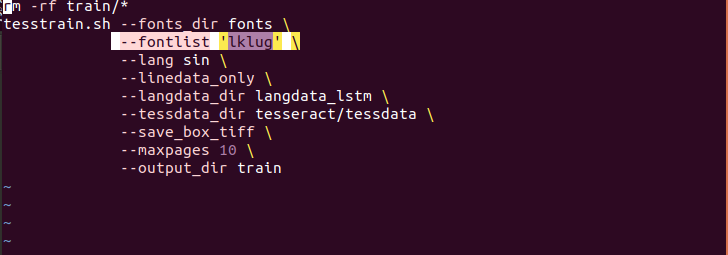
Looking forward to hearing from you.
Thank you.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduUZZdZ-O%2BJ72dRN83%2BGGctjYsNAArh9XrUdi9DX9rrRFg%40mail.gmail.com.
Isurianuradha96
Oct 10, 2019, 6:38:04 AM10/10/19
to tesser...@googlegroups.com
And also I want to know the reason for this kind off error prompting at the terminal in the process of training.[2]
[2].

Thank you. looking forward to your reply.
Shree Devi Kumar
Oct 10, 2019, 7:09:01 AM10/10/19
to tesseract-ocr
Multiple fonts can be given as follows:
--fontlist \
"Adobe Devanagari" \
"Akchyarunicode" \
"Aksharyogini2" \
"Amiri" \
"Adobe Devanagari" \
"Akchyarunicode" \
"Aksharyogini2" \
"Amiri" \
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7B84%2BKTSFCvm-ZNQga9DttZwY%3DRHw-EwZKojMve8%3Dj8%3Dw%40mail.gmail.com.
Shree Devi Kumar
Oct 10, 2019, 7:13:50 AM10/10/19
to tesseract-ocr
0DD0 $ැ SINHALA VOWEL SIGN KETTI AEDA-PILLA
= sinhala vowel sign ae
0DCA $් SINHALA SIGN AL-LAKUNA
= virama
Your training text is not normalized. You have words beginning with combining marks. Fix the text before training to reduce errors.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7BX-EFt5%3DrTrmTjNvwbYDDKuLZe2-y0hDMK5SPVjF67Cg%40mail.gmail.com.
Isurianuradha96
Oct 14, 2019, 12:07:08 AM10/14/19
to tesser...@googlegroups.com
Hi Shree,
Thanks for your help. Is there any way to train fonts sinhala and english languages models in a one script. The scenario is if we need to train the fonts using both Noto Sans Sinhala and Arial Regular how we define the --lang parameter in the script. Normally we are specifying ( --lang eng or sin). So in this case what's the steps that we should proceed?
Looking forward to hearing from you.
Thank you.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduVzKGUAH3wcPy%2B1WMUc0%2BCst5JttLCsVFforuxuMGWHXg%40mail.gmail.com.
Shree Devi Kumar
Oct 14, 2019, 12:35:28 AM10/14/19
to tesseract-ocr
have you tried script/Sinhla.traineddata which supports bith English and Sinhala.
If both your fonts support both Unicode ranges (try Arial Unicode MS instead of Arial), then just use lang as sin and concatenate both training_texts together.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7Adx%3DE654buziGqFs%2Bm2aXPVr0gsHJDeCZztXAX2yv-HQ%40mail.gmail.com.
Shree Devi Kumar
Oct 14, 2019, 2:20:59 AM10/14/19
to tesseract-ocr
Actually, that won't work since eng and sin have different normalization modes. Try creating the training data separately and then merge unicharsets and run combine_lang_model after that.
Isurianuradha96
Oct 14, 2019, 4:16:40 AM10/14/19
to tesser...@googlegroups.com
yes your correct. First method is not worked. will try on the second method. Thanks a lot.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduUGq_3_orWmHsWJcVBMeLBdto2m6UyMHZqWixSvuWhYDA%40mail.gmail.com.
Isurianuradha96
Oct 14, 2019, 5:14:33 AM10/14/19
to tesser...@googlegroups.com
Regarding the normalization issue the training text. the sin.training_text given by the tesseract (inside langdata folder) is raising the same issue. Do you have sort out that error?
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduVzKGUAH3wcPy%2B1WMUc0%2BCst5JttLCsVFforuxuMGWHXg%40mail.gmail.com.
Shree Devi Kumar
Oct 14, 2019, 9:04:15 AM10/14/19
to tesseract-ocr
What about text in langdata_lstm?
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7AoMHQ7F20UsxZRYfT%3DnVxC5PV-h3-Oeko%3DhPCguh3iWg%40mail.gmail.com.
Isurianuradha96
Oct 14, 2019, 9:26:11 AM10/14/19
to tesser...@googlegroups.com
I tried the sin.training_text inside the langdata_lstm (sin) folder. But still same problem is there by giving warning message and normalization failed message [1]
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduW9TjOk7vptzUKqOK-fs7ngtoM6wCeqNq6mxD%2BA%2BryigA%40mail.gmail.com.
{kind=link}
Shree Devi Kumar
Oct 14, 2019, 10:00:27 AM10/14/19
to tesseract-ocr
make the change to your local tesstrain_utils.sh and then run training
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7A%2BScL52%3D2u1GXF1jcBThbcfAxQ%3D%2BbYAEX0HSU%2BmmHZug%40mail.gmail.com.
Isurianuradha96
Oct 15, 2019, 1:56:40 AM10/15/19
to tesser...@googlegroups.com
I changed as you mentioned but giving the same warning as the previously mentioned. Can I know what is the normalization mechanism that you mean? and more information about that normalization process.
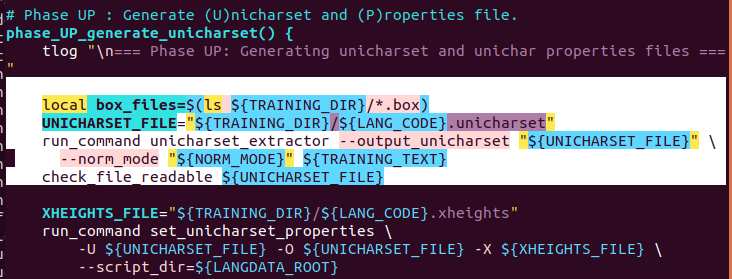
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduVyjf89F_dffk5tBeqvrTNjv1wrnRWXbQeWN810wxbztQ%40mail.gmail.com.
Shree Devi Kumar
Oct 15, 2019, 2:51:25 AM10/15/19
to tesseract-ocr
Check if you also have an installed version of tesstrain.sh?
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABjdo7DU-ySChQAUaRS2buasttgx8ZFT3u5X3pLawUF9PbkdeA%40mail.gmail.com.
Isurianuradha96
Oct 15, 2019, 6:13:49 AM10/15/19
to tesser...@googlegroups.com
Yes. .tesstrain.sh working fine. Generation of lstmf,box files are doing well. Only dout is about normalization issue?
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAG2NduVvWnDtd%3Dk2uO83XaPFhb1wr2bRcfHM7J%3DJVJkNFCuOYg%40mail.gmail.com.
Shree Devi Kumar
Oct 15, 2019, 6:45:42 AM10/15/19
to tesseract-ocr
Shree Devi Kumar
Oct 16, 2019, 9:52:10 AM10/16/19
to tesseract-ocr
Please try the attached traineddata file - trained till CER 1.8% - for fonts Noto Sans Sinhala and Arial
On Mon, Oct 14, 2019 at 9:37 AM Isurianuradha96 <isurian...@gmail.com> wrote:
Reply all
Reply to author
Forward
0 new messages