Improve tesseract accuracy.
460 views
Skip to first unread message

Alex Porter
Feb 17, 2023, 2:08:26 AM2/17/23
to tesseract-ocr
am currently building a pythont tool to read the screenshots of a in-game scoreboard. The scoreboard looks like this: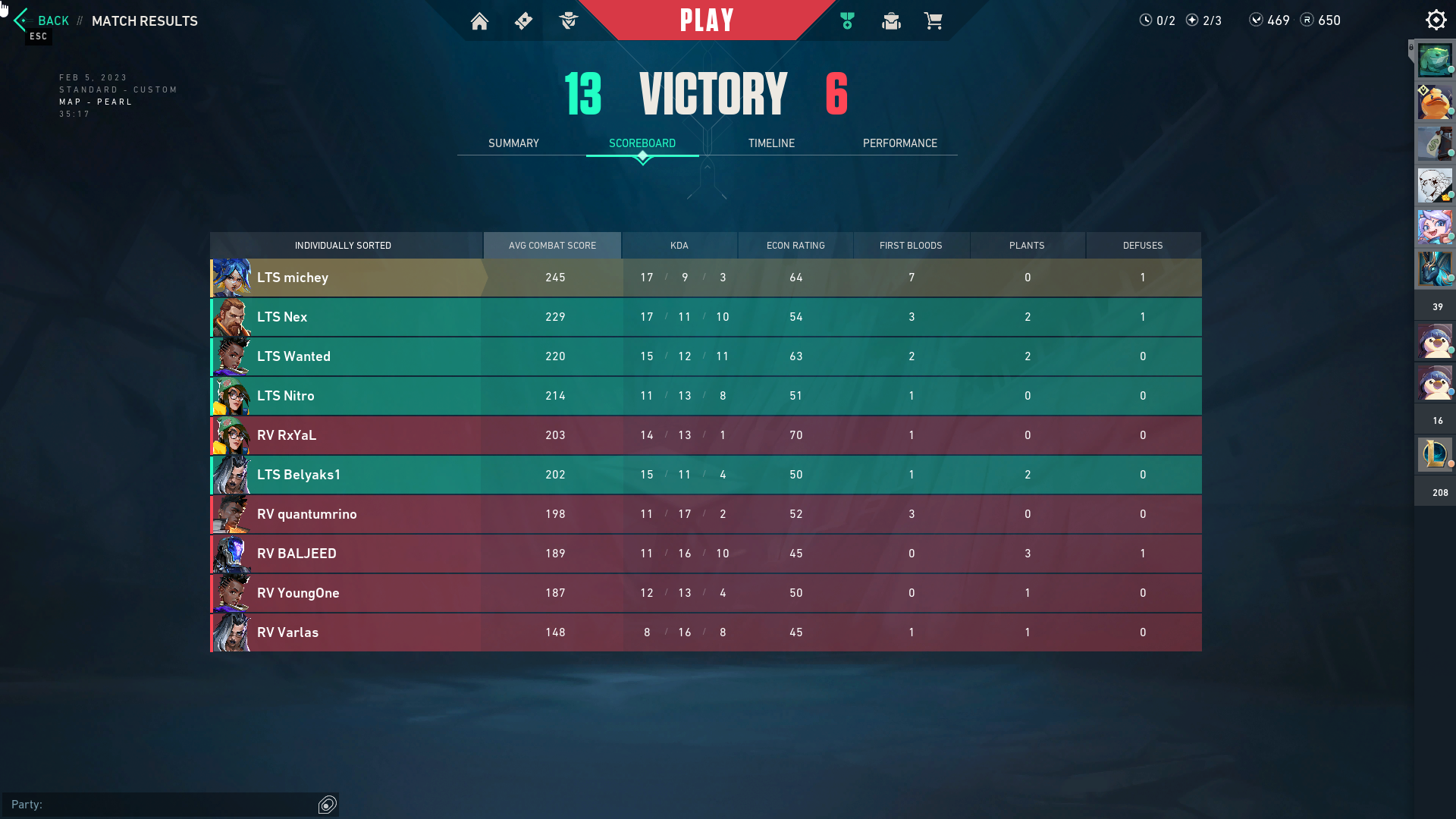
I am using open cv to analyse the scoreboard and can reliably slice the image into rows and extra each value from the scoreboard giving an image, after processing, like this:
I am still having issues with tesseract accurately identifying the numbers. Sometimes it is inaccurate (identifying the wrong number) or not giving any output at all. I have only whitelisted 0-9 when reading the numbers. Any help on pre-processing the image to increase accuracy or any other ideas would be much appreciated!
I have also attatched the python code. It's quite messy in it's current form so please forgive that if you decide to look!

Ger Hobbelt
Feb 18, 2023, 12:40:07 PM2/18/23
to tesser...@googlegroups.com
Hi,
Had a very quick look but got sidetracked into something else, so I didn't write the tesseract test script I wanted, so TILAAEFTR. Here goes:
your '4' output image is rather large for tesseract to treat it as a 'single line'.
tess is known to deliver different accuracies for (*wildly*) different line sizes -- I seem to recall some research and graphs from 2019 where accuracy went down for both too small (8-10px) and *way too high* (200+px), producing a bit of /skewed/ bathtub curve for the OCR error rate, so the idea here is to rescale your extracted number images to a suitable size, before feeding it ot the OCR engine.
Test this remark/idea with a script:
```
let img = 'out.png' // the '4', f.e.
for (let h = 8; h < 500; h = ceil( h * 1.1 /* = +10% */ )) {
/* use imagemagick for scaling, f.e.? */
rescale(img, height: h, unit: 'px') -> img2
tesseract(img2) -> txt
}
```
(pseudocode above; write in your favorite scripting language: bash, js, python, whatever)
collect the `txt` OCR results; rank them and see where your 'optimum height' lands you. Then use that for your application.
Afterthought / Side thought:
I see you are grabbing a computer display screen and applying OCR to it. A few thoughts pop up immediately given the source type:
I see a rather organized screen, no noisy/chaotic background you get with burned-in subtitles, for example. Food for thought.
- doesn't it suffice to take the number (*digit*) images and compare them against a (created) master set, using a image similarity metric? As it's the machine rendering those numbers, they should be pretty consistent, save for some anti-aliasing or non-pixel-accurate positioning in the renderer resulting in (slightly) different pixel values / images for each digit. (Feels like tesseract is an elephant gun for this. But then I probably missed several cues and be utterly wrong...)
- of that same vein, taking it one further: since it's output from a computer machine, can't we hook into the software which produces these images and get the raw digital numeric / scoreboard data from the software straight away? Iff we can, we don't have the significant overhead and data accuracy challenges that come with reversing anything using OCR: it's never a 100% accuracy this way. (software protections and other obstructions related to data commerce and ~ politics can keep us at a distance, where screengrabbing+OCR becomes an optimum viable solution if we want to get access to the data, but I would love to get away with less for the same (or better) result. :-S )
- is it me or am I seeing more of this machine -> screengrab/scan/photograph, digitally or *analog* (phone snaps of other phones' screens) -> machine OCR data transport queries lately ('22 / '23)? Have I missed something?
This looks like trade/score screens and at least the traders would have *some* incentive to provide an API for this. (When you find the related paywall insurmountable, grab+OCR is the way to go, alas, but it will always be somewhat finicky.)
Met vriendelijke groeten / Best regards,
Ger Hobbelt
--------------------------------------------------
web: http://www.hobbelt.com/
http://www.hebbut.net/
mail: g...@hobbelt.com
mobile: +31-6-11 120 978
--------------------------------------------------
Ger Hobbelt
--------------------------------------------------
web: http://www.hobbelt.com/
http://www.hebbut.net/
mail: g...@hobbelt.com
mobile: +31-6-11 120 978
--------------------------------------------------
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/19961d38-af02-4253-801d-4de53493cf54n%40googlegroups.com.
Ger Hobbelt
Feb 22, 2023, 6:31:31 AM2/22/23
to tesseract-ocr
Re the line pixel height research I mentioned I recalled: it's here: https://willus.com/blog.shtml?tesseract_accuracy and here: https://groups.google.com/g/tesseract-ocr/c/Wdh_JJwnw94
I had forgotten I got it from this mailinglist!
Alex Porter
Feb 23, 2023, 6:47:45 AM2/23/23
to tesser...@googlegroups.com
Thanks Ger, this has been incredibly helpful! Reducing the image size for OCR has dramatically increased the accuracy and reliability of my output.
You received this message because you are subscribed to a topic in the Google Groups "tesseract-ocr" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/tesseract-ocr/jWdpUF7mTxE/unsubscribe.
To unsubscribe from this group and all its topics, send an email to tesseract-oc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CAFP60fpxFVty%2Ba66Ndhb258rggN4u4OY%3DC62asW9_j3%2BoNzFAw%40mail.gmail.com.
Ger Hobbelt
Feb 24, 2023, 7:09:29 AM2/24/23
to tesser...@googlegroups.com
:+1: Glad it works out so well for you!
Met vriendelijke groeten / Best regards,
Ger Hobbelt
--------------------------------------------------
web: http://www.hobbelt.com/
http://www.hebbut.net/
mail: g...@hobbelt.com
mobile: +31-6-11 120 978
--------------------------------------------------
Ger Hobbelt
--------------------------------------------------
web: http://www.hobbelt.com/
http://www.hebbut.net/
mail: g...@hobbelt.com
mobile: +31-6-11 120 978
--------------------------------------------------
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/CABVhM9BqV2kuUnP0E3XR2WtNpkiO1BBScerjTZPhcZYg7zZWOA%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages