Tesseract training has an upper limit on the use of cpu?Is the more cpu, the faster the training?
555 views
Skip to first unread message

bruce
Nov 13, 2018, 4:39:22 AM11/13/18
to tesseract-ocr
Is the more cpu, the faster the training?
Tesseract training has an upper limit on the use of cpu?
Two other questions:
What is the best value for parameter --ptsize when training Chinese? 36 or 40 or other?
What is the best value for parameter --leading when training Chinese? 40 or 50 or other?

Junye Li
Nov 26, 2018, 12:06:17 AM11/26/18
to tesseract-ocr
Hi bruce,
Hardware requirements can be found here: https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00#hardware-software-requirements. Tesseract uses 4 cores/threads (if your CPU supports hyperthread) at most. I had the training running on a 40 core workstation and it turned out to be a huge waste lol.
Cheers
Cheers
bruce
Nov 27, 2018, 4:13:29 AM11/27/18
to tesseract-ocr
Hi Junye Li,
I hava an workstation with 36 core(2.0Ghz) and 24G Memory ,RHEL system
在 2018年11月26日星期一 UTC+8下午1:06:17,Junye Li写道:
I'm now running text2image to generate tif/box ,I guess it still needs to be executed for a week.
Next,I will run tesseract to generate .lstm files , I guess it will take about two weeks.
Finally,I will run lstmtraining to generate checkpoint file,I don't know how long it will take.
Follow the previous experience of training on windows,It may take one year or more..
在 2018年11月26日星期一 UTC+8下午1:06:17,Junye Li写道:
Junye Li
Nov 27, 2018, 4:27:44 AM11/27/18
to tesseract-ocr
I don't think that would be the case unless your training text is few hundred megabytes in size...
I am running Tesseract on Ubuntu 18.04 and based a very quick test it turned out Tesseract on Ubuntu performed better than on Windows in terms of agreement accuracy (I'm training it for handwritings).
As for the training, it took probably around 5 minutes to complete 2000 iterations for me (each training sample is of ~500 English character long).
Cheers,
Junye
bruce
Dec 9, 2018, 9:23:12 PM12/9/18
to tesseract-ocr
Hi Junye,

在 2018年11月27日星期二 UTC+8下午5:27:44,Junye Li写道:
Now,I hava an workstation with 36 core(Intel(R) Xeon(R) E7-4820 v2 2.00GHz)
32G Memory ,
RHEL7.3 system
My training text is about 29MB including 9470568 characters.
The .tif file is about 2.5GB ,file sizes generated by different fonts are slightly different. It takes about 12 hours to generate a tif file.
The .tif file is about 2.5GB ,file sizes generated by different fonts are slightly different. It takes about 12 hours to generate a tif file.
It takes about 40 hours to generate one lstm files from a .tif file.
this is my command as follows:
/usr/local/bin/tesseract /root/tesseract_train/tif_and_box/lyq_chn.ReejiCloudYuanXiGBK.exp0.tif /root/tesseract_train/lstm/aaa/ReejiCloudYuanXiGBK.exp0 /usr/share/tesseract/4/tessdata/configs/lstm.train /usr/share/tesseract/4/tessdata/scripts/lang/lyq_chn/lyq_chn.config > /root/tesseract_train/lstmlogs/ReejiCloudYuanXiGBK.log 2>&1
/usr/local/bin/tesseract /root/tesseract_train/tif_and_box/lyq_chn.MSmartPRC.exp0.tif /root/tesseract_train/lstm/aaa/MSmartPRC.exp0 /usr/share/tesseract/4/tessdata/configs/lstm.train /usr/share/tesseract/4/tessdata/scripts/lang/lyq_chn/lyq_chn.config > /root/tesseract_train/lstmlogs/MSmartPRC.log 2>&1
/usr/local/bin/tesseract /root/tesseract_train/tif_and_box/lyq_chn.SimSun.exp0.tif /root/tesseract_train/lstm/aaa/SimSun.exp0 /usr/share/tesseract/4/tessdata/configs/lstm.train /usr/share/tesseract/4/tessdata/scripts/lang/lyq_chn/lyq_chn.config > /root/tesseract_train/lstmlogs/SimSun.log 2>&1
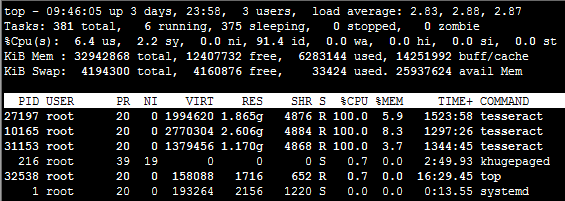
As shown in the screenshot:
I found that a tesseract process can only use one core.
here is the tesseract --version :
This is too time consuming. Is there no other way to speed up?
在 2018年11月27日星期二 UTC+8下午5:27:44,Junye Li写道:
Reply all
Reply to author
Forward
0 new messages