[GSOC] Workflow Support Project Initial Goals Update
118 views
Skip to first unread message

hardik juneja
Jun 4, 2013, 7:15:07 PM6/4/13
to sahan...@googlegroups.com
Hi all,
I was trying to work on my initial goals these days,which are:
a) request processing in the S3 RESTful API
I was trying to work on my initial goals these days,which are:
a) request processing in the S3 RESTful API
b) form processing in S3CRUD
So for request processing Dominic suggested me a very useful flow diagram which explains how s3_rest_controller apply S3 RESTful API and returns the desired output.
here's the link -> http://eden.sahanafoundation.org/attachment/wiki/S3XRC/RESTfulAPI/S3Resource/s3rest.png
So i planned to add some description to this diagram so that the new developer can easily understand how s3_rest_conroller produce the desired output.
So here's the description http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/S3Resource#Description
So, please review it and suggest changes
So for request processing Dominic suggested me a very useful flow diagram which explains how s3_rest_controller apply S3 RESTful API and returns the desired output.
here's the link -> http://eden.sahanafoundation.org/attachment/wiki/S3XRC/RESTfulAPI/S3Resource/s3rest.png
So i planned to add some description to this diagram so that the new developer can easily understand how s3_rest_conroller produce the desired output.
So here's the description http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/S3Resource#Description
So, please review it and suggest changes
----
Also, I saw the following wiki has gone very old but contains very useful information which has not been updated on the new wiki.
So, I have updated the new wiki - http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/s3_rest_controller
I have updated following three headings
I have updated following three headings
1. Prep (diff)
2. Method Handlers ( diff )
3. Custom Methods ( diff )
Please review these too
----
Also,
while studying my second objective I have made a flow Diagram on how Create/Update form is processed in S3CRUD
here's the GET cycle for it
Please review these too
----
Also,
while studying my second objective I have made a flow Diagram on how Create/Update form is processed in S3CRUD
here's the GET cycle for it

please suggest changes in this.
Can i add this to wiki?
Can anyone suggest me possible location to add this?----
I have also studied the how Default forms are formed.
So I will soon post the Flow diagram for it too
Some questions -
While reading the code I came across following variables which i was not able to figure out what they are and what they do and where do they come from:
1. manager https://github.com/flavour/eden/blob/master/modules/s3/s3resource.py#L160
2. Audit Hook https://github.com/flavour/eden/blob/master/modules/s3/s3resource.py#L237
3. from_record, from_table, map_fields https://github.com/flavour/eden/blob/master/modules/s3/s3resource.py#L237 ( are these used while pre-populating forms )
Regards,
So I will soon post the Flow diagram for it too
Some questions -
While reading the code I came across following variables which i was not able to figure out what they are and what they do and where do they come from:
1. manager https://github.com/flavour/eden/blob/master/modules/s3/s3resource.py#L160
2. Audit Hook https://github.com/flavour/eden/blob/master/modules/s3/s3resource.py#L237
3. from_record, from_table, map_fields https://github.com/flavour/eden/blob/master/modules/s3/s3resource.py#L237 ( are these used while pre-populating forms )
Regards,
Hardik Juneja

Dominic König
Jun 5, 2013, 4:01:01 PM6/5/13
to sahan...@googlegroups.com
Hardik--
nice work so far.
As for the wiki updates - you may have overlooked a few shn_ prefixes when
copying the old stuff into the new places, so maybe you want to correct that.
With the diagram, I think you've captured the second level of the onion (i.e.
what happens below the RESTful API) - but the most interesting level is still
a mystery ;) I think it'd be good to dive a little deeper and describe what
happens inside S3SQLDefaultForm/S3SQLCustomForm during GET and POST.
A good way for you to learn this is to answer the following question:
If the user submits a form (POST), and there is a validation error in one of
the fields, then all form widgets are called *2* times before the form is
returned - but why?
I'd say, if you can answer that (it's relatively easy, trust me), then you've
understood the process.
---
Where to store the current status of an uncompleted wizard form? In the
session? In the database? In the page?
I think to discuss this question properly, we need a better understanding of
the purpose of a wizard form. Sure, the discussion suggested "better UX", but
that's just a buzz phrase people use to whomp sceptics like me over the head
with.
I'm ok with that for a proposal - but for a design I don't buy it, and my
point here is that the exact opposite of wizard forms - i.e. combining
multiple forms into a single form - is also "better UX" and "ease of data
entry".
So - what now? What's the reason to provide a multi-step wizard form rather
than an all-in-one-page form? (please avoid comparative adjectives like
"better" or "easier" in your reasoning - try if/then instead, that's very
helpful for the design).
---
Thanks for today + Good night!
Dominic
> (diff<http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/s3_rest_contro
> ller?action=diff&version=83&old_version=82> )
> 2. Method Handlers (
> diff<http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/s3_rest_control
> ler?action=diff&version=81&old_version=80> )
> 3. Custom Methods (
> diff<http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/s3_rest_control
> ler?action=diff&version=80&old_version=79> )
> g> I have also studied the how Default forms are formed.
nice work so far.
As for the wiki updates - you may have overlooked a few shn_ prefixes when
copying the old stuff into the new places, so maybe you want to correct that.
With the diagram, I think you've captured the second level of the onion (i.e.
what happens below the RESTful API) - but the most interesting level is still
a mystery ;) I think it'd be good to dive a little deeper and describe what
happens inside S3SQLDefaultForm/S3SQLCustomForm during GET and POST.
A good way for you to learn this is to answer the following question:
If the user submits a form (POST), and there is a validation error in one of
the fields, then all form widgets are called *2* times before the form is
returned - but why?
I'd say, if you can answer that (it's relatively easy, trust me), then you've
understood the process.
---
Where to store the current status of an uncompleted wizard form? In the
session? In the database? In the page?
I think to discuss this question properly, we need a better understanding of
the purpose of a wizard form. Sure, the discussion suggested "better UX", but
that's just a buzz phrase people use to whomp sceptics like me over the head
with.
I'm ok with that for a proposal - but for a design I don't buy it, and my
point here is that the exact opposite of wizard forms - i.e. combining
multiple forms into a single form - is also "better UX" and "ease of data
entry".
So - what now? What's the reason to provide a multi-step wizard form rather
than an all-in-one-page form? (please avoid comparative adjectives like
"better" or "easier" in your reasoning - try if/then instead, that's very
helpful for the design).
---
Thanks for today + Good night!
Dominic
> ller?action=diff&version=83&old_version=82> )
> 2. Method Handlers (
> diff<http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/s3_rest_control
> ler?action=diff&version=81&old_version=80> )
> 3. Custom Methods (
> diff<http://eden.sahanafoundation.org/wiki/S3XRC/RESTfulAPI/s3_rest_control
> ler?action=diff&version=80&old_version=79> )
>
> Please review these too
>
> ----
>
> Also,
> while studying my second objective I have made a flow Diagram on how
> Create/Update form is processed in S3CRUD
>
> here's the GET cycle for it
>
>
>
> https://docs.google.com/file/d/0B6c1EPLOwdAhMWYxb3BIWHVlZFU/edit?usp=sharing
>
>
> [image: Inline image 1]
>
>
> please suggest changes in this.
> Can i add this to wiki?
> Can anyone suggest me possible location to add this?
>
> ----
>
> <https://docs.google.com/file/d/0B6c1EPLOwdAhMWYxb3BIWHVlZFU/edit?usp=sharin
> Please review these too
>
> ----
>
> Also,
> while studying my second objective I have made a flow Diagram on how
> Create/Update form is processed in S3CRUD
>
> here's the GET cycle for it
>
>
>
> https://docs.google.com/file/d/0B6c1EPLOwdAhMWYxb3BIWHVlZFU/edit?usp=sharing
>
>
> [image: Inline image 1]
>
>
> please suggest changes in this.
> Can i add this to wiki?
> Can anyone suggest me possible location to add this?
>
> ----
>
> g> I have also studied the how Default forms are formed.
Dominic König
Jun 5, 2013, 4:15:48 PM6/5/13
to sahan...@googlegroups.com
Ah - and...not to forget:
for the next step, I'd recommend you to come up with a *case*, i.e. a concrete
use-case where a wizard form would improve UX.
Forget about the "org_organisation" or "pr_person" cases - that's not it. I'd
prefer a case where wizard forms provide an obvious practical advantage - not
a "could be" case.
This case is for any further discussion, for demo and testing - so don't
choose too simple nor too complex ;) and always ask: would this really be done
by one user?
Dominic
for the next step, I'd recommend you to come up with a *case*, i.e. a concrete
use-case where a wizard form would improve UX.
Forget about the "org_organisation" or "pr_person" cases - that's not it. I'd
prefer a case where wizard forms provide an obvious practical advantage - not
a "could be" case.
This case is for any further discussion, for demo and testing - so don't
choose too simple nor too complex ;) and always ask: would this really be done
by one user?
Dominic
hardik juneja
Jun 6, 2013, 2:28:41 PM6/6/13
to sahan...@googlegroups.com, franc...@gmail.com, Dominic König
Hi,
As for the wiki updates - you may have overlooked a few shn_ prefixes when
copying the old stuff into the new places, so maybe you want to correct that.
Done.
A good way for you to learn this is to answer the following question:
If the user submits a form (POST), and there is a validation error in one of
the fields, then all form widgets are called *2* times before the form is
returned - but why?
I'd say, if you can answer that (it's relatively easy, trust me), then you've
understood the process.
I will come up with DETAILED answer for this and the other two diagram soon.
Where to store the current status of an uncompleted wizard form? In the
session? In the database? In the page?
I think storing in the page is a good option.
The only disadvantage here would be that user can lose data if his browser crashes.
But i will like to what community thinks on that.
Maybe Fran can tell us what would be the best option
The only disadvantage here would be that user can lose data if his browser crashes.
But i will like to what community thinks on that.
Maybe Fran can tell us what would be the best option
I think to discuss this question properly, we need a better understanding of
the purpose of a wizard form. Sure, the discussion suggested "better UX", but
that's just a buzz phrase people use to whomp sceptics like me over the head
with.
I'm ok with that for a proposal - but for a design I don't buy it, and my
point here is that the exact opposite of wizard forms - i.e. combining
multiple forms into a single form - is also "better UX" and "ease of data
entry".
So - what now? What's the reason to provide a multi-step wizard form rather
than an all-in-one-page form? (please avoid comparative adjectives like
"better" or "easier" in your reasoning - try if/then instead, that's very
helpful for the design).
I totally agree with you point multi-step forms are made to make your users not to think about what to do next, Since making decisions can be an unwelcome burden for users doing but not always , Some expert user can find these wizards a waste of time and bit frustrating and they will prefer all-in-one-page forms over it.
I think different user will want different thing, some will prefer multi-step form over one big form and other will prefer one big form over multi-step form
So if we don't talk about UX, Other reasons to provide multi-step form to Sahana Eden can be.
a) If we have multi-step forms we will be able to complete related tasks easily. So the developer will have complete freedom to relate resource A with resource B or component of resource A with component of resource B through steps.
b) These multi-step forms can be a overview of a resource i.e they will contain the features of a resource for eg. if we have a multi-step form for a resource X then, step 1 show that we can add details about the resource and step 2 show we can add details about the component of the resource and step 3 show that we can search over the resource.
so this will help the new user to understand the workflow of this resource or it can even teach them the order in which they should fill the form when they are not taking the wizard.
c) Also if we will have the multi-step form we can suffice the need of both types of users, one who like single page form and those who like the multi-step forms. So the taking a wizard will be optional for the user.
c) Also if we will have the multi-step form we can suffice the need of both types of users, one who like single page form and those who like the multi-step forms. So the taking a wizard will be optional for the user.
I hope you are convinced and will try to buy the design now ;)
Regards,
Hardik Juneja
hardik juneja
Jun 6, 2013, 10:06:21 PM6/6/13
to sahan...@googlegroups.com
Hello Dominic
I have made the flow diagram for the Default form you can find it below.
A good way for you to learn this is to answer the following question:
If the user submits a form (POST), and there is a validation error in one of
the fields, then all form widgets are called *2* times before the form is
returned - but why?
Ok, the check for errors happens in the Process function where we have a condition check
like this ( if form.accepts(....) ) this accepts function is a web2py function which return true if the form is accepted and false if it has errors.
so the errors are stored in the form.errors in the form of dictionary with fieldname as key.
Here's the diagram for default forms
like this ( if form.accepts(....) ) this accepts function is a web2py function which return true if the form is accepted and false if it has errors.
so the errors are stored in the form.errors in the form of dictionary with fieldname as key.
Here's the diagram for default forms
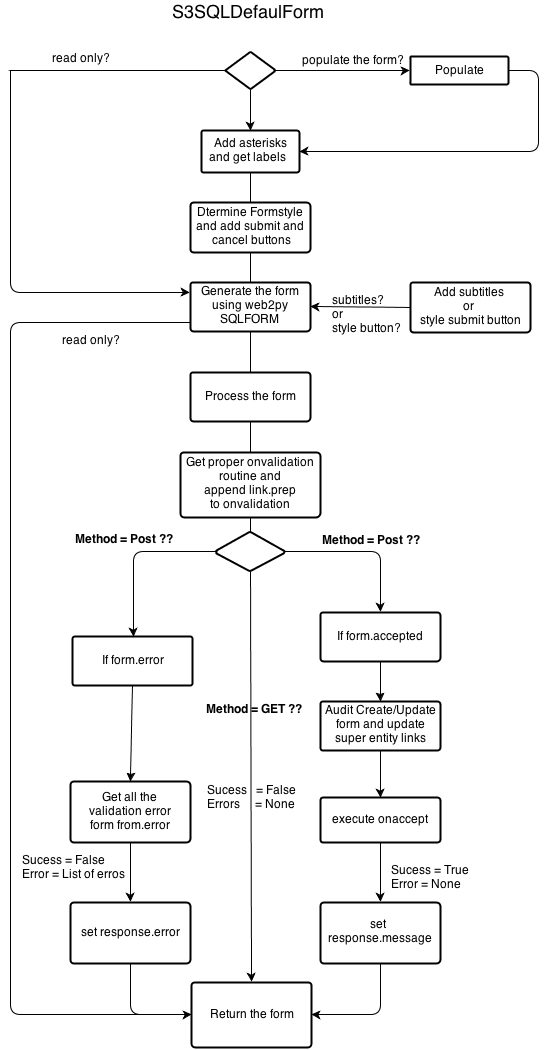
Next steps -
I will soon post a flow diagram for Custom Forms.
and will try to find a concrete use case.
I will soon post a flow diagram for Custom Forms.
and will try to find a concrete use case.

Fran Boon
Jun 7, 2013, 3:29:30 AM6/7/13
to sahan...@googlegroups.com
On 7 June 2013 03:06, hardik juneja <hardikj...@gmail.com> wrote:
and will try to find a concrete use case.
Here's a simple one, but which could be useful:
A simple 'Add Data' button opens a simple form with a dropdown to select which type of data, next step is the create form for that resource.
- better than a massively long list of Create XX options...
F
Dominic König
Jun 8, 2013, 4:42:48 PM6/8/13
to sahan...@googlegroups.com
fredagen den 7 juni 2013 07.36.21 skrev hardik juneja:
> Ok, the check for errors happens in the Process function where we have a
> condition check
> like this ( if form.accepts(....) ) this accepts function is a web2py
> function which return true if the form is accepted and false if it has
> errors.
> so the errors are stored in the form.errors in the form of dictionary with
> fieldname as key.
Good.
> Ok, the check for errors happens in the Process function where we have a
> condition check
> like this ( if form.accepts(....) ) this accepts function is a web2py
> function which return true if the form is accepted and false if it has
> errors.
> so the errors are stored in the form.errors in the form of dictionary with
> fieldname as key.
But why does it call each widget in the form a second time if there was an
error?
Why does it call widgets at all?
"check for errors happens" - where exactly? In the process() function? In
form.accepts()? No.
This comes down to the general design of web2py's self-processing forms:
widgets and validators.
What's a form widget?
What's a validator?
What does "onvalidation" do and when?
How are data transmitted from the client to the server (I don't mean "via
network" - that's clear - I rather mean "with which data format" and where are
they initially stored)?
Keep digging, you're at the right place, but still at the surface ;) and you
should ask (me) these questions ;)
Dominic
hardik juneja
Jun 10, 2013, 4:22:03 AM6/10/13
to sahan...@googlegroups.com
Hi Dominic,
I tried to dig a bit deeper into web2py.
How are data transmitted from the client to the server (I don't mean "via
network" - that's clear - I rather mean "with which data format" and where are
they initially stored)?
I am not sure about this but the data is stored in the form of dictionary in the get_vars and post_vars.
What's a form widget?
Form widget includes for EX selector widget, password field , Upload Widget, Input field widget etc
First they are called when we try to build a form using SQLFORM() function of web2py
So web2py has custom form widgets which are defined in gluon/html.py
So web2py has custom form widgets which are defined in gluon/html.py
What's a validator?
Validators are used for validating each fields.
we use S3Validators and over rides the web2py validation but i am not sure if this is done every-time
we use S3Validators and over rides the web2py validation but i am not sure if this is done every-time
What does "onvalidation" do and when?
The onvalidation is used to tell what to do after the form is validated, this includes what to do on Success , On Failure.
"check for errors happens" - where exactly? In the process() function? In
form.accepts()? No.
check for errors happen using different validators.
This is actually done in the function called _traverse
which checks each field in the form and validates its.
This is actually done in the function called _traverse
which checks each field in the form and validates its.
Why does it call widgets at all?
First they are called when we try to build a form using SQLFORM() function of web2py.
why does it call each widget in the form a second time if there was an
error?
Okhay, the form widgets are called second time whenever there is an error
and this is done because whenever their is an error, we have to hold the data and show it again with the error messages.
Is this correct? I am not sure about this?
Regards
Har
dik Juneja
Dominic König
Jun 11, 2013, 5:17:50 AM6/11/13
to sahan...@googlegroups.com
måndagen den 10 juni 2013 13.52.03 skrev hardik juneja:
> I am not sure about this but the data is stored in the form of dictionary
> in the get_vars and post_vars.
Hmm, where exactly?
> I am not sure about this but the data is stored in the form of dictionary
> in the get_vars and post_vars.
I think the point is that they are stored in web2py's global "request" object.
If the form is submitted by POST, then its request.post_vars, if it is a GET-
form, then it's request.get_vars (=URL query).
How is an S3Request instance related to web2py's global "request" instance?
> Form widget includes for EX selector widget, password field , Upload
> Widget, Input field widget etc
Each Field in a Table can have a widget-attribute (Field.widget) to specify
the form widget for this field. If no widget for a field is not defined, then
SQLFORM will fall back the pre-defined widget for the respective field type
(defined in gluon.sqlhtml.py).
> First they are called when we try to build a form using SQLFORM() function
> of web2py
all fields in the form and create a nested structure of XMLComponent instances.
In addition to form widgets, SQLFORM also needs the labels for each of the
form fields (using Field.label if defined or capitalized Field.name) - and a so-
called "formstyle", which is a function that combines label + widget into a
form row - and then the form rows are wrapped in a FORM instance.
> Validators are used for validating each fields.
submitted form (post_vars, mostly).
SQLFORM is using the validators set for each Field.requires, and falls back to
the default validators for the respective Field.type if .requires isn't set.
But validators do one more thing: if a field has options to select, then the
validator is used to retrieve the options during rendering of the form. This
is a bit confusing because you would expect the widget to do this - however,
the logic is that the validator "knows" which options are allowed anyway, so
the widget can just "ask" the validator.
> we use S3Validators and over rides the web2py validation but i am not sure
> if this is done every-time
a base class for validators ("Validator") which can be used for that.
> > What does "onvalidation" do and when?
>
> The onvalidation is used to tell what to do after the form is validated,
> this includes what to do on Success , On Failure.
all fields have been successfully validated, but before any data are written
into DB.
The purpose of "onvalidation" is to perform additional validation beyond field-
by-field, e.g. where the values from two fields need to fit together.
The onvalidation-callback is not supposed to do anything else than to tell
whether the form is ok (or to hook in an error if not). In particular, it must
neither expect nor perform any interactions (e.g. redirection) - because it is
also called from the non-interactive importer.
"onvalidation" can be separated into a create_onvalidation and an
update_onvalidation routine, if the procedures differ between create and update
(however, the callback could also introspect the form and detect updates from
the pre-existing form.vars.id which isn't available in create).
This should not be confused with the web2py "onvalidation" setting, which is
related to web2py's Crud tool - but not used by Sahana Eden.
> > "check for errors happens" - where exactly? In the process() function? In
> > form.accepts()? No.
>
> check for errors happen using different validators.
> This is actually done in the function called _traverse
> which checks each field in the form and validates its.
(field validation) and in the onvalidation callback (form validation).
form.accepts() invokes both.
> First they are called when we try to build a form using SQLFORM() function
> of web2py.
>
> Okhay, the form widgets are called second time whenever there is an error
> and this is done because whenever their is an error, we have to hold the
> data and show it again with the error messages.
> Is this correct? I am not sure about this?
Yes, correct.
> and this is done because whenever their is an error, we have to hold the
> data and show it again with the error messages.
> Is this correct? I am not sure about this?
The first call happens during the instantiation of the FORM - which calls all
widgets with the default values for the fields.
Only when we have a FORM instance, we can actually call form.accepts(), which
receives the request.post_vars as parameter.
If this finds an error, then it needs to restore the submitted values into the
widgets - and that is why it calls the widgets again, this time with the
values that had been submitted for validation.
---
Please checkout SQLFORM.factory - what can this be used for and how?
(recommend you read the web2py book for easy understanding before you dive
into the code).
Regards,
Dominic
Dominic König
Jun 11, 2013, 5:24:24 AM6/11/13
to sahan...@googlegroups.com
tisdagen den 11 juni 2013 11.17.50 skrev du:
> If this finds an error, then it needs to restore the submitted values into
> the widgets - and that is why it calls the widgets again, this time with
> the values that had been submitted for validation.
What do you think - what consequences does that have for the widget design?
> If this finds an error, then it needs to restore the submitted values into
> the widgets - and that is why it calls the widgets again, this time with
> the values that had been submitted for validation.
Dominic
Dominic König
Jun 11, 2013, 7:25:37 AM6/11/13
to sahan...@googlegroups.com
Hardik--
> My point here was that these multi-step forms or wizards give freedom to
> the developer
> to relate different tables together and this relation will be setted in
> steps.
Developers already have the "freedom" to relate different tables together
(actually, there is no way around it). The important difference is steps -
and the question was what exactly this is needed for
> I think multi-step form will be important in the situations where the step
> 2 in dependent on step 1 , So the above situation that you defined can be
> tackled by multi-step form.
> Also it can be useful in the situation where we want to have validation
> after each steps, I will have to find situation in eden where this can be
> applied.
Aha - getting closer.
I think this "sequential dependency" and "interim validation" are critical
points for the design - much more than "guidance" or "UX" - and they do need a
framework:
1) Validation
2) Condition checkpoints (hooks?)
3) Data transfer between steps (~interim data storage)
As a next step, could you please brainstorm typical dependencies between
steps, and try to generalize them? Include all of the three above.
Also, maybe you could ponder a little about how this would work RESTfully?
> > E.g. when creating a request, you first enter the basic request data,
> > thereby
> > choosing the request type (inventory items or human resources?). In a next
> > step you would choose either the items you're requesting - or the skills
> > and
> > quantity of human resources (alternative tables), and finally you would
> > probably enter additional information to specify supply routes/conditions
> > (e.g. whether transport security is required) - or you get provided with a
> > bunch of warehouses which have the items you requested so you can choose
> > which
> > of those to request the items from (*if* you requested inventory items -
> > for
> > human resources this would again look differently).
> >
> > For this, it's not the user preferences that decide whether or not to use
> > the
> > wizard - this scenario can simply only be done with a wizard, every other
> > design would be inappropriate.
>
> I agree, this type of scenario can be simple done with the help of wizard.
> we can use this example as a test case too.
> but i will still try finding more like these.
Let me turn this upside down, just to illustrate what kind of "freedom" we
give to the developers. Imagine a different design of the same process:
Instead of creating a request and then adding items to it, we design the
process in a more "natural" manner: shopping list.
The user needs both equipment and manpower to clear a road from fallen trees,
so he goes shopping in a "virtual warehouse" (it's virtual because it's
actually just a list of pledges):
He performs a series of catalog searches for
a) axes
b) chainsaws
c) sturdy guys who can operate these tools
and adds each of them to the "shopping list" (together with the required
quantities), or call it a "needs list"? During the search, he can see whether
the respective catalog item is available, which quantities, and where and when
and for how long etc.
Then he clicks "make request" to actually create a request for these things
(he could also store the list, so he can return later and make
additions/corrections).
With "make request", he gets a pre-filled order form for the items he selected,
and fills in his requester details - then probably another form to fill in
recipient/transport details etc...
And finally, he may specify when/how he wants to get notified, e.g. when the
requested stuff/people become available.
---
This does basically the same thing - but requires less pre-emptive decisions
from the user, and /that/ makes for better UX more than the guidance (which is
always necessary, not just in multi-step forms).
With a wizard generator, the one design can easily be changed into the other
(i.e. by configuration, without having to rewrite the whole application).
Hope this helps you to better analyze (+generalize) requirements for your
design ;)
Please try to keep all emails on the public list.
Thanks,
Dominic
> My point here was that these multi-step forms or wizards give freedom to
> the developer
> to relate different tables together and this relation will be setted in
> steps.
Developers already have the "freedom" to relate different tables together
(actually, there is no way around it). The important difference is steps -
and the question was what exactly this is needed for
> I think multi-step form will be important in the situations where the step
> 2 in dependent on step 1 , So the above situation that you defined can be
> tackled by multi-step form.
> Also it can be useful in the situation where we want to have validation
> after each steps, I will have to find situation in eden where this can be
> applied.
Aha - getting closer.
I think this "sequential dependency" and "interim validation" are critical
points for the design - much more than "guidance" or "UX" - and they do need a
framework:
1) Validation
2) Condition checkpoints (hooks?)
3) Data transfer between steps (~interim data storage)
As a next step, could you please brainstorm typical dependencies between
steps, and try to generalize them? Include all of the three above.
Also, maybe you could ponder a little about how this would work RESTfully?
> > E.g. when creating a request, you first enter the basic request data,
> > thereby
> > choosing the request type (inventory items or human resources?). In a next
> > step you would choose either the items you're requesting - or the skills
> > and
> > quantity of human resources (alternative tables), and finally you would
> > probably enter additional information to specify supply routes/conditions
> > (e.g. whether transport security is required) - or you get provided with a
> > bunch of warehouses which have the items you requested so you can choose
> > which
> > of those to request the items from (*if* you requested inventory items -
> > for
> > human resources this would again look differently).
> >
> > For this, it's not the user preferences that decide whether or not to use
> > the
> > wizard - this scenario can simply only be done with a wizard, every other
> > design would be inappropriate.
>
> I agree, this type of scenario can be simple done with the help of wizard.
> we can use this example as a test case too.
> but i will still try finding more like these.
Let me turn this upside down, just to illustrate what kind of "freedom" we
give to the developers. Imagine a different design of the same process:
Instead of creating a request and then adding items to it, we design the
process in a more "natural" manner: shopping list.
The user needs both equipment and manpower to clear a road from fallen trees,
so he goes shopping in a "virtual warehouse" (it's virtual because it's
actually just a list of pledges):
He performs a series of catalog searches for
a) axes
b) chainsaws
c) sturdy guys who can operate these tools
and adds each of them to the "shopping list" (together with the required
quantities), or call it a "needs list"? During the search, he can see whether
the respective catalog item is available, which quantities, and where and when
and for how long etc.
Then he clicks "make request" to actually create a request for these things
(he could also store the list, so he can return later and make
additions/corrections).
With "make request", he gets a pre-filled order form for the items he selected,
and fills in his requester details - then probably another form to fill in
recipient/transport details etc...
And finally, he may specify when/how he wants to get notified, e.g. when the
requested stuff/people become available.
---
This does basically the same thing - but requires less pre-emptive decisions
from the user, and /that/ makes for better UX more than the guidance (which is
always necessary, not just in multi-step forms).
With a wizard generator, the one design can easily be changed into the other
(i.e. by configuration, without having to rewrite the whole application).
Hope this helps you to better analyze (+generalize) requirements for your
design ;)
Please try to keep all emails on the public list.
Thanks,
Dominic
hardik juneja
Jun 12, 2013, 4:32:14 PM6/12/13
to sahan...@googlegroups.com
Hello Dominic,
> I am not sure about this but the data is stored in the form of dictionaryHmm, where exactly?
> in the get_vars and post_vars.
I think the point is that they are stored in web2py's global "request" object.
If the form is submitted by POST, then its request.post_vars, if it is a GET-
form, then it's request.get_vars (=URL query).
How is an S3Request instance related to web2py's global "request" instance?
Are they related though the args and vars that are dictionary of arguments and variable respectively?
I forgot to ask one question that came up when i was studying S3Request, what does the __parse actually function do?
It parses the web2py request but can you please explain it to me in detail.
c
reate a nested structure of XMLComponent instances.
why we need this? can you please explain me this part?
Please checkout SQLFORM.factory - what can this be used for and how?
(recommend you read the web2py book for easy understanding before you dive
into the code).
Thanks, I completely forgot to read the web2py book and now most of the things are clear.
So, SQLFORM.factory is used when we have to take advantage of the web2py's SQLFORM but we don't want to generate the form using table.
The S3SQLCustomForms use SQLFORM.factory function to generate the form and if the form get accepted we use S3SQLCustomForm's accept function to fill the database.
The S3SQLCustomForms use SQLFORM.factory function to generate the form and if the form get accepted we use S3SQLCustomForm's accept function to fill the database.
Regards,
Hardik Juneja
hardik juneja
Jun 12, 2013, 4:32:22 PM6/12/13
to sahan...@googlegroups.com
What do you think - what consequences does that have for the widget design?
Widget have field and value as an their first two arguments and returns a representation of that field for EX a stringwidget would return INPUT(**attr) .
Dominic König
Jun 12, 2013, 5:54:15 PM6/12/13
to sahan...@googlegroups.com
torsdagen den 13 juni 2013 02.02.14 skrev hardik juneja:
> > How is an S3Request instance related to web2py's global "request"
> > instance?
>
> Are they related though the args and vars that are dictionary of arguments
> and variable respectively?
Hmm, not exactly.
> > How is an S3Request instance related to web2py's global "request"
> > instance?
>
> Are they related though the args and vars that are dictionary of arguments
> and variable respectively?
The global "request" object holds the details of the HTTP request, interpreted
for the web2py context, which means, a URL is translated like:
http://server/application/controller/function/arg/arg?var=value&var=value
so "request" has:
request.application
request.controller
request.function
request.args (a list)
request.vars (a dict)
Note that request.vars is a union of request.get_vars and request.post_vars.
In many occasions it is important to distinguish between URL query variables
(GET vars) and form data (POST vars).
The request.controller attribute identifies the file in the controllers/
directory which is to be imported (=executed!), and controller.function
identifies the function within this file which will eventually be called.
Many of these functions hand over to the s3_rest_controller function, which is
a helper method that instantiates and executes an S3Request.
> I forgot to ask one question that came up when i was studying S3Request,
> what does the __parse actually function do?
> It parses the web2py request but can you please explain it to me in detail.
contains the same details of the HTTP request, but additionally interpreted in
the Eden context, which means, a URL is translated like:
http://server/application/module/resource_name/record_id/component_name/method
so "S3Request" has (in addition to all the attributes of request):
S3Request.prefix (the module name)
S3Request.name (the resource name)
S3Request.id (the record ID)
S3Request.component_name (the component name)
S3Request.method (to identify the REST method handler for this request)
Furthermore, S3Request instantiates the relevant S3Resource(s) for this
request (as S3Request.resource and S3Request.component).
The S3Request instance is callable - and when it's called, it will "execute"
the request, i.e. perform the requested method on the target resource.
That means, S3Request *is* the RESTful API for Eden on top of the web2py HTTP
framework - it takes the URL to identify the data resource, and then performs
the requested method on that resource.
This API is extensible - that's why it was originally called "S3 eXtensible
Resource Controller" (S3XRC). That means, you can easily implement new methods
using a standard interface (S3Method) and then "plug" them into S3Request
(which is exactly what happens in the s3_rest_controller helper function).
> create a nested structure of XMLComponent instances.
> why we need this? can you please explain me this part?
XMLComponent and its subclasses are used to represent HTML (XML) elements in
Python. They can be nested like:
output = DIV(H2("Heading"), P("Text"))
where the inner elements are "components" of the outer elements (typically,
the class name is the uppercase HTML element name - so this is very easy to
work with).
Since these are Python objects, they can easily be traversed - and both
contents as well as attributes can be manipulated, e.g.:
output.add_class("example")
The good thing about these "helpers" is that they don't render any HTML (XML)
until their .xml() method is called - which happens automatically in the view
template:
{{=output}}
or when you call:
print output
This would give:
<div class="example"><h2>Heading</h2><p>Text</p></div>
There are many more things to say about and do with XMLComponents, but I think
you can read this better in the web2py book. In any case - FORMs are also
XMLComponents.
> Thanks, I completely forgot to read the web2py book
can be more confusing the other way around. But once you dive this deep into
Eden code, it's useful to become a bit more familiar with web2py.
> So, SQLFORM.factory is used when we have to take advantage of the web2py's
> SQLFORM but we don't want to generate the form using table.
> The S3SQLCustomForms use SQLFORM.factory function to generate the form
any of them, but need to work with .factory from a field list instead.
> and
> if the form get accepted we use S3SQLCustomForm's accept function to fill
> the database.
.factory doesn't do that, so we have to do it ourselves in S3SQLCustomForm.
This DB transaction method in S3SQLCustomForm is not exactly the same as the
SQLFORM one - it's a little more taylored to the Eden needs, i.e. it does some
extra stuff specific for Eden, but also omits some steps which are /not/ needed
for Eden.
Hope this clears up a few more details for you.
Keep asking ;)
Dominic
Dominic König
Jun 12, 2013, 5:57:28 PM6/12/13
to sahan...@googlegroups.com
onsdagen den 12 juni 2013 23.54.15 skrev du:
> so "S3Request" has (in addition to all the attributes of request):
>
> S3Request.prefix (the module name)
> S3Request.name (the resource name)
> S3Request.id (the record ID)
> S3Request.component_name (the component name)
> S3Request.method (to identify the REST method handler for this request)
...this is what the __parse function (a subfunction of the constructor) does:
> so "S3Request" has (in addition to all the attributes of request):
>
> S3Request.prefix (the module name)
> S3Request.name (the resource name)
> S3Request.id (the record ID)
> S3Request.component_name (the component name)
> S3Request.method (to identify the REST method handler for this request)
translating the URL into the Eden RESTful context.
Dominic
Dominic König
Jun 12, 2013, 6:11:46 PM6/12/13
to sahan...@googlegroups.com
onsdagen den 12 juni 2013 23.54.15 skrev Dominic König:
> so "S3Request" has (in addition to all the attributes of request):
Note that each S3Request can override some details of "request", e.g. all of
> so "S3Request" has (in addition to all the attributes of request):
the URL (including args and vars).
In contrast to the one global "request" (which is the one and only "real" HTTP
request), there can be multiple S3Request instances during the same call -
addressing different resources with different methods.
An S3Request that overrides some request attributes is sometimes called a
"fake S3Request" - but of course it's not "fake", it's just not 100% congruent
with the global "request".
Many s3_rest_controller calls, for example, "fake" the S3Request by overriding
module prefix and resource name (which would otherwise be the same as
request.controller and request.function).
However, therefore, method handlers must always only work from the S3Request
instance they're given, and not read the real "request" - and as much as
possible use the Eden-specific attributes rather than the web2py-generic.
Dominic
hardik juneja
Jun 12, 2013, 6:58:07 PM6/12/13
to sahan...@googlegroups.com
Hope this clears up a few more details for you
Yes, thanks a lot :)
> so "S3Request" has (in addition to all the attributes of request):
Note that each S3Request can override some details of "request", e.g. all of
the URL (including args and vars).
In contrast to the one global "request" (which is the one and only "real" HTTP
request), there can be multiple S3Request instances during the same call -
addressing different resources with different methods.
You mean to say we can have more than one S3Request instances during same call? is it possible?
An S3Request that overrides some request attributes is sometimes called a
"fake S3Request" - but of course it's not "fake", it's just not 100% congruent
with the global "request".
Many s3_rest_controller calls, for example, "fake" the S3Request by overriding
module prefix and resource name (which would otherwise be the same as
request.controller and request.function).
Can you please explain me "fake S3Request" once again and where is this useful?
Dominic König
Jun 14, 2013, 4:01:30 AM6/14/13
to sahan...@googlegroups.com
torsdagen den 13 juni 2013 04.28.07 skrev hardik juneja:
> You mean to say we can have more than one S3Request instances during same
> call? is it possible?
Yes, that's possible.
> You mean to say we can have more than one S3Request instances during same
> call? is it possible?
> Can you please explain me "fake S3Request" once again and where is this
> useful?
actions on data objects: The URL specifies the data object, and the HTTP
request method specifies the action to perform.
Thus, when you instantiate an S3Request, it automatically looks up all the
REST parameters from the global web2py "request" object (i.e. from the
underlying HTTP request):
r = S3Request()
But you /can/ also override some (or even all) of the REST parameters
explicitly in the constructor - which is a little bit like "rewriting" the
HTTP request.
For example, there are many cases where the controller/function names do not
correspond to the resource prefix/name - e.g. on index pages. Then you need to
override prefix and name in the controller:
r = S3Request(prefix="org", name="organisation")
...which is common in s3_rest_controller.
And since such an S3Request request is no longer 100% congruent with the
underlying HTTP request, it is sometimes called a "fake" S3Request.
That's basically it - but it gives you a lot of freedom:
E.g. a single HTTP request could spawn multiple REST requests for different
resources with different methods - yet retaining common parameters, e.g. data
format or filters. Not really RESTful then anymore - but not entirely stupid
either ;)
Dominic
hardik juneja
Jun 16, 2013, 9:04:39 PM6/16/13
to sahan...@googlegroups.com
And since such an S3Request request is no longer 100% congruent with theunderlying HTTP request, it is sometimes called a "fake" S3Request.
Ok, so its called "fake" S3Request coz it is not 100% congruent to the web2py's request or the HTTP request
Got it,
Thanks a lot
Got it,
Thanks a lot
hardik juneja
Jun 16, 2013, 9:05:29 PM6/16/13
to sahan...@googlegroups.com
Here, the flow diagram of S3SQLCustomForm

Sorry, i am very late with this
Are both the diagram good to go?
Can i add both, default and the custom form diagrams in the wiki?
The 1st week of the official coding period starts from tomorrow.
The 1st week of the official coding period starts from tomorrow.
Here's my plan for Week 1
Discuss the design to save user progress and users step.
Creating models (if required ) to save the user progress and the step is on.
- Discussing and planning the design of the project with mentors and community.
and here's full Timeline Timeline and outputs
Regards,
Hardik Juneja
Dominic König
Jun 17, 2013, 3:25:40 AM6/17/13
to sahan...@googlegroups.com
söndagen den 16 juni 2013 18.05.29 skrev hardik juneja:
> Here, the flow diagram of S3SQLCustomForm
>
> <https://lh6.googleusercontent.com/-WuDgd98FYHs/Ub5e840I3HI/AAAAAAAAAII/iT85
> Here, the flow diagram of S3SQLCustomForm
>
> n6zT2P0/s1600/S3SQLCustomForms.png>
>
> Sorry, i am very late with this
> Are both the diagram good to go?
The diagrams have a weakness: the accepts() gateway has actually three
> Sorry, i am very late with this
> Are both the diagram good to go?
possible exits:
The two you outline:
- form gets accepted
- form has errors
and a third:
- form has not been submitted yet (=GET cycle)
How does accepts() check whether the form has been submitted? What's for
_formkey for?
> Can i add both, default and the custom form diagrams in the wiki?
I don't think the diagrams should be your focus anymore - it's time to code.
> Discuss the design to save user progress and users step.
>
> Creating models (if required ) to save the user progress and the step
> is on.
> - Discussing and planning the design of the project with mentors and
> Creating models (if required ) to save the user progress and the step
> is on.
> community.
Let's have our weekly meeting on Wednesday, 08:15 UTC.
Remember that I still need a daily short progress report (3 bullet points, not
more): what have you accomplished today? What are you going to accomplish
tomorrow? Are there any roadblocks?
Dominic
hardik juneja
Jun 17, 2013, 8:12:01 PM6/17/13
to sahan...@googlegroups.com
The diagrams have a weakness: the accepts() gateway has actually threepossible exits:
The two you outline:
- form gets accepted
- form has errors
and a third:
- form has not been submitted yet (=GET cycle)
Right, here the GET and POST cycle
.png?part=0.1)
How does accepts() check whether the form has been submitted? What's for
_formkey for?
_formkey is the hidden field associated with each form and its a token which is generated by web2py every time the form is serialised and is stored in sessions. so if the form is submitted the accepts function check this _formkey with the _formkey in the request_vars or post_vars and if they don't match it return False without errors.
this _formkey prevent double submission of forms.
this _formkey prevent double submission of forms.
I don't think the diagrams should be your focus anymore - it's time to code.
Right, i am excited :)
Let's have our weekly meeting on Wednesday, 08:15 UTC.
Wednesday is good :)
This will be a IRC chat ?
This will be a IRC chat ?
Remember that I still need a daily short progress report (3 bullet points, not
more): what have you accomplished today? What are you going to accomplish
tomorrow? Are there any roadblocks?
Sure :)
We still have to finalise the best way to save user progress.
Database ? or On the page?
Database ? or On the page?
Regards
Hardik Juneja
hardik juneja
Jun 18, 2013, 10:06:04 AM6/18/13
to sahan...@googlegroups.com
Great :)
Can you please reply the mail i send you earlier.
I have some questions there regarding the weekly meeting on wednesday and i have answered some questions.
Can you please reply the mail i send you earlier.
I have some questions there regarding the weekly meeting on wednesday and i have answered some questions.
Thanks a lot
Hardik
Hardik
Dominic König
Jun 18, 2013, 5:50:03 PM6/18/13
to sahan...@googlegroups.com
tisdagen den 18 juni 2013 05.42.01 skrev hardik juneja:
> Let's have our weekly meeting on Wednesday, 08:15 UTC.
>
>
> Wednesday is good
> Let's have our weekly meeting on Wednesday, 08:15 UTC.
>
>
> Wednesday is good
> This will be a IRC chat ?
Yes - #sahana-eden please.
I'm probably going to be a bit late tomorrow - could we postpone to 09:00 UTC
(only this time)?
Dominic
Dominic König
Jun 18, 2013, 5:59:48 PM6/18/13
to sahan...@googlegroups.com
tisdagen den 18 juni 2013 05.42.01 skrev hardik juneja:
> this _formkey prevent double submission of forms.
Why do you think this is necessary?
This is going to be my last question for your "learning" goals - I think it's
time to move on. There's certainly still a lot more for you to learn - mostly
small yet important details - but theory isn't nearly as effective as practice
with these ;)
If you have any code ready to review it would be good to publish it before our
meeting. You're a couple of hours ahead of me, so you should still have the
time.
Thanks,
Dominic
hardik juneja
Jun 18, 2013, 11:17:25 PM6/18/13
to sahan...@googlegroups.com
I'm probably going to be a bit late tomorrow - could we postpone to 09:00 UTC
(only this time)?
Sure :)
> this _formkey prevent double submission of forms.
Why do you think this is necessary?
I think this is _formkey is necessary in the case when the user press the submit button multiple times.
So when the first time when the Submit button is pressed this form key is generated.
but i am not really sure about what happen when the user click the Submit button second time?
does the form key is generated again?
So when the first time when the Submit button is pressed this form key is generated.
but i am not really sure about what happen when the user click the Submit button second time?
does the form key is generated again?
This is going to be my last question for your "learning" goals - I think it's
time to move on. There's certainly still a lot more for you to learn - mostly
small yet important details - but theory isn't nearly as effective as practice
with these ;)
I agree :)
If you have any code ready to review it would be good to publish it before our
meeting. You're a couple of hours ahead of me, so you should still have the
time.
Sorry, I don't have any code ready for review now.
I have some questions, which i will ask you during the meeting.
I have some questions, which i will ask you during the meeting.
Regards,
Hardik Juneja
hardik juneja
Jun 19, 2013, 9:33:24 AM6/19/13
to sahan...@googlegroups.com, Dominic König
Hi Dominic,
I am still confused with the S3WorkflowNode function that we discussed on IRC.
So here i have in my mind.
let say we have to define three nodes
I am still confused with the S3WorkflowNode function that we discussed on IRC.
So here i have in my mind.
let say we have to define three nodes
node1 = S3WorkflowForm(resourcename, crudform = form1)
node2 = S3WorkflowForm(resourcename, crudform = form2)
node3 = S3WorkflowForm(resourcename, "Search")
where form1 and form2 will be S3SQLCustomForm.
and node3 is a "search" view.
now S3WorkflowForm will be a class.
now i want to ask you where should the prep and the postp will be defined should i add them as argument too?
was this design was on your mind or it was something else?
or
do you actually want developer to define the node like this -
def node1():
prep():
#prep code
return True
form = S3SQLCustomForm()
s3db.configure(resource, crudform = form)
postp():
#postp code
return True
return s3_rest_controller()
S3WorkflowNode(node1)
return s3_rest_controller()
S3WorkflowNode(node1)
No this is not correct
then what ?
sorry i am taking time to catch up
then what ?
sorry i am taking time to catch up

Pat Tressel
Jun 19, 2013, 11:47:09 AM6/19/13
to sahan...@googlegroups.com, Dominic König
I am still confused with the S3WorkflowNode function that we discussed on IRC.
Hardik and I are having a chat about this on IRC right now, where we're speculating on the earlier IRC discussion. What I was thinking was that the regular controllers look for workflow indicators in the request or session, and call out to workflow helpers. S3Workflow would be the overall workflow that the user is progressing through, and S3WorkflowNode is the current step. But we weren't sure if these supplant all or most of the controller, or just supplement it.
The chat is at 14:40 and following in:
http://logs.sahanafoundation.org/sahana-eden/2013-06-19.txt
The chat is at 14:40 and following in:
http://logs.sahanafoundation.org/sahana-eden/2013-06-19.txt
Perhaps Hardik could summarize / comment.
-- Pat
Dominic König
Jun 19, 2013, 1:39:49 PM6/19/13
to sahan...@googlegroups.com
All correct,
except that it's not the controller to detect the workflow and hand over to the
corresponding S3Workflow instance, but the REST API (S3Request). The controller
would hand over to s3_rest_controller as usual.
The S3Workflow instance would then detect the current/next step (from the URL
and/or POST data), check conditions and instantiate the corresponding
S3WorkflowNode to continue, then run it.
And finally, the node itself runs the respective method as defined in the config
and with the data from the request - and updates status and data in the
workflow.
If the node has a prep or postp of its own, it would execute these instead of
the controller's prep and postp (i.e. optional override). But it could also
just extend it (i.e. execute both prep and both postp) - this is still to be
thought through.
So, "workflow" is an alternate route for regular REST requests - if no workflow
can be detected, it's just a normal REST call.
Dominic
except that it's not the controller to detect the workflow and hand over to the
corresponding S3Workflow instance, but the REST API (S3Request). The controller
would hand over to s3_rest_controller as usual.
The S3Workflow instance would then detect the current/next step (from the URL
and/or POST data), check conditions and instantiate the corresponding
S3WorkflowNode to continue, then run it.
And finally, the node itself runs the respective method as defined in the config
and with the data from the request - and updates status and data in the
workflow.
If the node has a prep or postp of its own, it would execute these instead of
the controller's prep and postp (i.e. optional override). But it could also
just extend it (i.e. execute both prep and both postp) - this is still to be
thought through.
So, "workflow" is an alternate route for regular REST requests - if no workflow
can be detected, it's just a normal REST call.
Dominic
Dominic König
Jun 19, 2013, 1:59:39 PM6/19/13
to sahan...@googlegroups.com
Or let me put it differently:
A normal REST request is a workflow with a single node. So, if the request does
not indicate any particular workflow, then we run such a single-node request.
However, the request could also address a particular workflow (usually by a URL
parameter). In this case, the REST API would instantiate the S3Workflow
instance and hand over the request processing.
The S3Workflow instance would take the request data (URL parameters and/or POST
data and/or session data and/or DB data) to detect its own current status and
the current/next steps, check conditions and instantiate the corresponding
S3WorkflowNode to execute the request.
The S3WorkflowNode can utilize then regular S3Methods to execute the step, and
then update status and/or data for the workflow.
Dominic
A normal REST request is a workflow with a single node. So, if the request does
not indicate any particular workflow, then we run such a single-node request.
However, the request could also address a particular workflow (usually by a URL
parameter). In this case, the REST API would instantiate the S3Workflow
instance and hand over the request processing.
The S3Workflow instance would take the request data (URL parameters and/or POST
data and/or session data and/or DB data) to detect its own current status and
the current/next steps, check conditions and instantiate the corresponding
S3WorkflowNode to execute the request.
The S3WorkflowNode can utilize then regular S3Methods to execute the step, and
then update status and/or data for the workflow.
Dominic
Dominic König
Jun 19, 2013, 2:28:33 PM6/19/13
to sahan...@googlegroups.com
Err...sorry -
am I making sense at all? Why are we suddenly working on a workflow engine?
Of course I prefer that - but it's not centered on multi-page forms anymore.
I'm not sure where we left the original path - it seems after the n-th
iteration of explaining the difference between wizard forms and workflow, we've
finally changed the horse. Unconciously.
I don't think that's wrong, though - this one here can run too, and probably
even further than the wizard - and Hardik has repeatedly indicated a stronger
interest in the workflow engine.
However, Hardik, you need to confirm whether that's really what you want to do,
otherwise we better take a step back, and take the other road.
Dominic
am I making sense at all? Why are we suddenly working on a workflow engine?
Of course I prefer that - but it's not centered on multi-page forms anymore.
I'm not sure where we left the original path - it seems after the n-th
iteration of explaining the difference between wizard forms and workflow, we've
finally changed the horse. Unconciously.
I don't think that's wrong, though - this one here can run too, and probably
even further than the wizard - and Hardik has repeatedly indicated a stronger
interest in the workflow engine.
However, Hardik, you need to confirm whether that's really what you want to do,
otherwise we better take a step back, and take the other road.
Dominic
Fran Boon
Jun 19, 2013, 2:36:26 PM6/19/13
to sahan...@googlegroups.com
On 19 June 2013 19:28, Dominic König <dom...@nursix.org> wrote:
> am I making sense at all? Why are we suddenly working on a workflow engine?
> Of course I prefer that - but it's not centered on multi-page forms anymore.
> I'm not sure where we left the original path - it seems after the n-th
> iteration of explaining the difference between wizard forms and workflow, we've
> finally changed the horse. Unconciously.
> I don't think that's wrong, though - this one here can run too, and probably
> even further than the wizard
I would be a big +1 to continue this direction....almost sent a "love
> am I making sense at all? Why are we suddenly working on a workflow engine?
> Of course I prefer that - but it's not centered on multi-page forms anymore.
> I'm not sure where we left the original path - it seems after the n-th
> iteration of explaining the difference between wizard forms and workflow, we've
> finally changed the horse. Unconciously.
> I don't think that's wrong, though - this one here can run too, and probably
> even further than the wizard
the way this is looking" mail already :)
To me this is *much* more useful than a Wizard.
> - and Hardik has repeatedly indicated a stronger
> interest in the workflow engine.
F
hardik juneja
Jun 20, 2013, 5:03:21 AM6/20/13
to sahan...@googlegroups.com, Dominic König
However, Hardik, you need to confirm whether that's really what you want to do,
otherwise we better take a step back, and take the other road.
Workflow Engine interests me and i think we can continue towards the new direction.
will like to develope something useful and if Workflow Engine is more useful than a wizards lets go for it.
I think the S3WorkflowNode Will be same have the same structure as discussed yesterday.
I think the S3WorkflowNode Will be same have the same structure as discussed yesterday.
So now each S3WorkflowNode can be anything, a list view , a search view, a create form, update form.
And work of workflow engine is to look for the the configuration and go the next step after executing the current node.
this configuration will be defined by the user.
So the S3WorkflowNode will still be defined the same way with prep and postp function which can be overridden by the new prep and postp function and they can be combined too( this still need to be thought though).
so now all the nodes will be passed to the S3Workflow , where they will be executed one by one after condition checks.
And work of workflow engine is to look for the the configuration and go the next step after executing the current node.
this configuration will be defined by the user.
So the S3WorkflowNode will still be defined the same way with prep and postp function which can be overridden by the new prep and postp function and they can be combined too( this still need to be thought though).
so now all the nodes will be passed to the S3Workflow , where they will be executed one by one after condition checks.
and we also will have to extend the S3REST so that it can hand over the workflow to the another method handler.
I still need more light on this, please?
Is this correct
?Is this correct
Regards,
Hardik Juneja
hardik juneja
Jun 20, 2013, 5:10:08 AM6/20/13
to sahan...@googlegroups.com, Dominic König
I have some more questions.
A normal REST request is a workflow with a single node. So, if the request does
not indicate any particular workflow, then we run such a single-node request.
However, the request could also address a particular workflow (usually by a URL
parameter). In this case, the REST API would instantiate the S3Workflow
instance and hand over the request processing.
How will it detect if we are in a workflow or not?
The S3WorkflowNode can utilize then regular S3Methods to execute the step, and
then update status and/or data for the workflow.
Are we talking about S3Method Class here?
what all regular methods will be used here?
what all regular methods will be used here?
hardik juneja
Jun 21, 2013, 1:49:04 AM6/21/13
to sahan...@googlegroups.com, Dominic König
I want to share something i have in my mind about workflow engine-
The main aim of workflow engine is to create a route for the user to perform the all the predefined/selected task in sequence.
The main aim of workflow engine is to create a route for the user to perform the all the predefined/selected task in sequence.
So, we can have a menu for user which will display all possible task user can perform in eden.
After selecting the full route the user will click submit and the request will be handover to the Method handler of the S3Workflow by the S3REST . the full route will be in the post_vars.
After selecting the full route the user will click submit and the request will be handover to the Method handler of the S3Workflow by the S3REST . the full route will be in the post_vars.
So now, its on S3Workflow to complete one step, change status , add data and adapt next step and so on.. .
Now, if are going to have S3WorkflowNode then we will have to define such nodes for all the tasks
something like S3WorkflowNode("req","req","create"), S3WorkflowNode("project","project","create")
Now, if are going to have S3WorkflowNode then we will have to define such nodes for all the tasks
something like S3WorkflowNode("req","req","create"), S3WorkflowNode("project","project","create")
So each node will be callable and will contain prep and postp which can be overridden by the new prep and postp function.
and will return s3_rest_controller() function
so this each node will be executed by the S3Workflow class in the same order in which the user route has been defined.
So, design is what i have in my mind about workflow engine.
Regards,
Hardik Juneja
and will return s3_rest_controller() function
so this each node will be executed by the S3Workflow class in the same order in which the user route has been defined.
So, design is what i have in my mind about workflow engine.
Regards,
Hardik Juneja
hardik juneja
Jun 24, 2013, 6:51:08 AM6/24/13
to sahan...@googlegroups.com, Dominic König
Hello Dominic,
I was working on the design to make something working
Though i have not done much code in this regard, appoligies but as my timeline say my first week was to brainstorm on the project design.
So this is what i have done so far.
I was working on the design to make something working
Though i have not done much code in this regard, appoligies but as my timeline say my first week was to brainstorm on the project design.
So this is what i have done so far.
First there will be a controller which will have something like workflow/index where a menu will be provided to user and all the task which can be performed by the user in sahana eden will be listed there-
these will be radio fields (but right now i am just using input fields.)
Then, i made S3REST to decide if the request is a workflow or node.
so, this will happen something like this:
http://pastebin.ubuntu.com/5795121/
session = current.session
if "workflow" in r.post_vars or r.post_vars and "workflow" in session.v:
from s3.s3workflow import S3Workflow
if "workflow" in r.post_vars:
session.v = r.post_vars.items()
session.v= session.v[:3]
request.post_vars = {}
c = session.v.pop()
w = S3Workflow()
output = w(c)
# Execute the request
else:
output = r(**attr)
now, the S3Workflow class will be a place where the checks will happen and the instance of S3WorkflowNode will be executed:
http://pastebin.ubuntu.com/5795138/
class S3WorkflowNode():
def __call__(self,c):
s3_rest_controller = current.rest_controller
return s3_rest_controller("req",c[1])
class S3Workflow(object):
def __call__(self,c):
node = S3WorkflowNode()
output = node(c)
Is this approach good?
Though it still has lots of issues?
One is, i am returning the s3_rest_controller for workflow/index, so Step1 for eg will display req/req/list view but on url workflow/index?
I have some questions-
One is, i am returning the s3_rest_controller for workflow/index, so Step1 for eg will display req/req/list view but on url workflow/index?
I have some questions-
Now, though the S3WorkflowNode will subclass S3Method, but i want to ask is what will be its advantage?
Also if Node be returning s3_rest_controller, is there any way to get /create on the url instead of lisl?
hardik juneja
Jun 24, 2013, 3:25:50 PM6/24/13
to sahan...@googlegroups.com, Dominic König
I hope this message will make the above approach more clear -
I was trying to make a workflow that first go to req/req and then to req/commit.
just to try things out,
Now, first check for workflow field take place in post_vars and if it's found then it means that the workflow is on the first node so here we copy the post_vars in the sessions.v and also make the post_vars empty and pop one the first field input and send it to S3Workflow().
I was trying to make a workflow that first go to req/req and then to req/commit.
just to try things out,
I made a model containing a hidden field named workflow and two other fields where i add information like "req" and "commit".
So as i click submit, all the three will be stored in post_vars.
session = current.sessionif "workflow" in r.post_vars or r.post_vars and "workflow" in session.v:from s3.s3workflow import S3Workflowif "workflow" in r.post_vars:session.v = r.post_vars.items()session.v= session.v[:3]request.post_vars = {}
c = session.v.pop()w = S3Workflow()output = w(c)
Now, first check for workflow field take place in post_vars and if it's found then it means that the workflow is on the first node so here we copy the post_vars in the sessions.v and also make the post_vars empty and pop one the first field input and send it to S3Workflow().
class S3WorkflowNode():def __call__(self,c):s3_rest_controller = current.rest_controllerreturn s3_rest_controller("req",c[1])
Now the first node is executed and return the s3_rest_controller that mean the request again come back to the condition check but this time, post_vars are empty so normal request will be executed and list view of req/req will be displayed.
Now, First problem is that the req/req rest controller is displayed on the workflow/index controller so all the CRUD buttons will map to URL like these - workflow/index/1/update instead of req/req/1/update.
Second, i have to figure out how i can show a create or search or list view here?
Now, if we would have a create view. then user will enter the data and press submit then again we have post_vars and also we have 'workflow' in the session.v:
So this will again request is handled by s3workflow and second step will be displayed
I will have to implement a logic to store the data.
Because Using this approach the data is not get saved, So we can store the data and and save it all together, so if user want to go back one step he can do it easily.
Dominic König
Jun 24, 2013, 4:09:58 PM6/24/13
to sahan...@googlegroups.com
Generally,
the flow is relatively clear, although I can not see why it calls a "workflow"
controller?
It should call
/req/req/create?workflow=<workflow_name>:<workflow_uid>
to resume a workflow from that node on, or
/req/req/create?workflow=<workflow_name>
to initiate a workflow. This will automatically resolve the URL issue.
workflow_name - identifies the workflow type
workflow_uid - identifies a workflow instance (so you can resume a workflow after
navigating away from it)
And the rest of the URL identifies the current node - I mean, that /is/ the URL
of the node, so why call a separate controller? Up to the
S3Request.__call__(), everything is the same as in a regular request.
But then it will detect the ?workflow= and hence hand over to the workflow
instead of just executing the request. The workflow will detect the node (from
the URL and the status/data of the workflow instance), and execute the request
as workflow node instead of as standalone request.
Instead of the name and ID of the current workflow instance (which will then
always be in the URL, i.e. request.get_vars), you have to store any submitted
data and the workflow status (i.e. the current node for this instance). Whether
session is a good place for that is a separate discussion - I'd say "clearly
not".
That "not" is because there is a risk for a huge stack of abandoned zombie-
workflows, which the user started, but navigated away and instead of resuming,
started a new one. Especially re-used session on terminals with multiple users
are at risk.
Since session is pickled and stored on disk (or in the DB) after every
request, it is /not/ a good data store. DB (even a temporary DB) is a better
place, or even the file system, provided you implement routines to purge
abandoned workflows (either manually or routinely automatic).
Best regards,
Dominic
the flow is relatively clear, although I can not see why it calls a "workflow"
controller?
It should call
/req/req/create?workflow=<workflow_name>:<workflow_uid>
to resume a workflow from that node on, or
/req/req/create?workflow=<workflow_name>
to initiate a workflow. This will automatically resolve the URL issue.
workflow_name - identifies the workflow type
workflow_uid - identifies a workflow instance (so you can resume a workflow after
navigating away from it)
And the rest of the URL identifies the current node - I mean, that /is/ the URL
of the node, so why call a separate controller? Up to the
S3Request.__call__(), everything is the same as in a regular request.
But then it will detect the ?workflow= and hence hand over to the workflow
instead of just executing the request. The workflow will detect the node (from
the URL and the status/data of the workflow instance), and execute the request
as workflow node instead of as standalone request.
Instead of the name and ID of the current workflow instance (which will then
always be in the URL, i.e. request.get_vars), you have to store any submitted
data and the workflow status (i.e. the current node for this instance). Whether
session is a good place for that is a separate discussion - I'd say "clearly
not".
That "not" is because there is a risk for a huge stack of abandoned zombie-
workflows, which the user started, but navigated away and instead of resuming,
started a new one. Especially re-used session on terminals with multiple users
are at risk.
Since session is pickled and stored on disk (or in the DB) after every
request, it is /not/ a good data store. DB (even a temporary DB) is a better
place, or even the file system, provided you implement routines to purge
abandoned workflows (either manually or routinely automatic).
Best regards,
Dominic

{kind=link}
{kind=link}
Fran Boon
Jun 24, 2013, 4:24:19 PM6/24/13
to sahan...@googlegroups.com
Since we're talking about 'Workflows' now, I think this is a good time
to be aware of the connection with Ashwyn's Parser project.
This has the concept of Workflows too.
The Workflows here are non-interactive ones.
They currently start with an input 'Source' which is a Messaging
Channel (these are currently being rewritten so will be clearer soon)
The model for these is stored here:
https://github.com/flavour/eden/blob/master/modules/s3db/msg.py#L540
This is very simple so easily adapted to whatever you folks come up
with as/when suitable.
As I mentioned the Messaging Models are being rewritten right now, so
changes coming in now are good if we have some clarity on which
direction they should take.
However it can also wait if you're simply not at that stage yet - all
as you like :)
F
FYI the current actual Parsers are here:
https://github.com/flavour/eden/blob/master/private/templates/default/parser.py
to be aware of the connection with Ashwyn's Parser project.
This has the concept of Workflows too.
The Workflows here are non-interactive ones.
They currently start with an input 'Source' which is a Messaging
Channel (these are currently being rewritten so will be clearer soon)
The model for these is stored here:
https://github.com/flavour/eden/blob/master/modules/s3db/msg.py#L540
This is very simple so easily adapted to whatever you folks come up
with as/when suitable.
As I mentioned the Messaging Models are being rewritten right now, so
changes coming in now are good if we have some clarity on which
direction they should take.
However it can also wait if you're simply not at that stage yet - all
as you like :)
F
FYI the current actual Parsers are here:
https://github.com/flavour/eden/blob/master/private/templates/default/parser.py
Fran Boon
Jun 24, 2013, 4:56:09 PM6/24/13
to sahan...@googlegroups.com
On 24 June 2013 21:54, Dominic König <dom...@nursix.org> wrote:
> I prefer pull requests on GitHub over pastebin snippets when I'm to review
> code/changes - even if incomplete.
+1
> I prefer pull requests on GitHub over pastebin snippets when I'm to review
> code/changes - even if incomplete.
The comment can say 'For review...not really ready to merge'
But the highlighting & the ability to comment inline in GitHub are awesome :)
F
hardik juneja
Jun 24, 2013, 5:27:01 PM6/24/13
to sahan...@googlegroups.com
Looks good :)
Just one quick question -
Just one quick question -
/req/req/create?workflow=<workflow_name>:<workflow_uid>
workflow_name - identifies the workflow type
workflow_uid - identifies a workflow instance (so you can resume a workflow after
navigating away from it)
how will i generate this uid?
Fran --
However it can also wait if you're simply not at that stage yet - all
as you like :)
Can you please wait.
Just few more days
Hardik Juneja
Fran Boon
Jun 24, 2013, 5:28:30 PM6/24/13
to sahan...@googlegroups.com
On 24 June 2013 22:27, hardik juneja <hardikj...@gmail.com> wrote:
>> However it can also wait if you're simply not at that stage yet - all
>> as you like :)
> Can you please wait.
> Just few more days
Probably better for us :)
>> However it can also wait if you're simply not at that stage yet - all
>> as you like :)
> Can you please wait.
> Just few more days
Let's see if next week we can talk about this - either on-list or,
if-necessary, we can escalate to a call.
F
hardik juneja
Jun 24, 2013, 5:35:51 PM6/24/13
to sahan...@googlegroups.com, Dominic König, Francis Boon
I prefer pull requests on GitHub over pastebin snippets when I'm to review
code/changes - even if incomplete.
I am at my uncle's place.
So, here , I am not able to access some sites, Github is one of them.
I tried to find proper solution for this but didn't succeed.
May be something wrong with the router.
Will fix it soon.
Fran--
I tried to find proper solution for this but didn't succeed.
May be something wrong with the router.
Will fix it soon.
Fran--
Probably better for us :)
Let's see if next week we can talk about this - either on-list or,
if-necessary, we can escalate to a call.
Sure :)
hardik juneja
Jun 24, 2013, 5:44:59 PM6/24/13
to sahan...@googlegroups.com
we can create a uuid for each workflow
using python's uuid.UUID.
using python's uuid.UUID.
--
Hardik Juneja
Fran Boon
Jun 24, 2013, 5:45:57 PM6/24/13
to sahan...@googlegroups.com
On 24 June 2013 22:44, hardik juneja <hardikj...@gmail.com> wrote:
> we can create a uuid for each workflow
> using python's uuid.UUID.
If the workflow is being stored in the DB, then this could be the
> we can create a uuid for each workflow
> using python's uuid.UUID.
record.id or record.uuid
ID is shorter...
F
> On Tue, Jun 25, 2013 at 3:03 AM, Dominic König <dom...@nursix.org> wrote:
>>
>> tisdagen den 25 juni 2013 02.57.01 skrev hardik juneja:
>> > how will i generate this uid?
>> :D you tell me - I'm your mentor, not your ghost writer.
>>
>> Dominic
>
>
>
>
> --
> Hardik Juneja
>
> You received this message because you are subscribed to the Google Groups
> "Sahana-Eden" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to sahana-eden...@googlegroups.com.
> To post to this group, send email to sahan...@googlegroups.com.
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/sahana-eden/CACKBQ1dav2916kO4GU%2B06Yy7ruS%2BNmn1c8CfbaETojwCEGn8bA%40mail.gmail.com.
>
> For more options, visit https://groups.google.com/groups/opt_out.
>
>
hardik juneja
Jun 24, 2013, 5:51:23 PM6/24/13
to sahan...@googlegroups.com, Francis Boon
"Instead of the name and ID of the current workflow instance (which will then
always be in the URL, i.e. request.get_vars), you have to store any submitted
data and the workflow status (i.e. the current node for this instance)."
always be in the URL, i.e. request.get_vars), you have to store any submitted
data and the workflow status (i.e. the current node for this instance)."
So i don't think we will be storing workflow in the db?
To view this discussion on the web visit https://groups.google.com/d/msgid/sahana-eden/CAPKzkt%2BOzzQ1tgMZWQtBfiBXmM98zJc%3Dgy0t7sEHWXMN4viO2w%40mail.gmail.com.
Hardik Juneja
Reply all
Reply to author
Forward
0 new messages