Gerrit 3.1.4 can't handle the load that Gerrit 2.15.18 could?
277 views
Skip to first unread message

Elijah Newren
May 18, 2020, 5:49:19 PM5/18/20
to repo-discuss
Hi,
We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
(temporarily going through 2.16.18 in order to migrate off NoteDB),
and had a couple outages when developers came online today. After
some digging, we found the following things that looked weird:
1)
There are nearly always four open ssh connections attempting to do
nothing more than run "gerrit version", and the jobs seem to hang
around indefinitely unless I manually close them (with "gerrit
close-connection"):
$ grep -F -f <(ssh -i special-key -p 29418 special-user@localhost
gerrit show-connections | awk {print\$1} | grep -E '[0-9a-f]{8}')
~/installation/logs/sshd_log | grep jenkins-gerrit-ro
[2020-05-18 20:09:46,994 +0000] 43948657
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-2] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.106
[2020-05-18 20:09:47,000 +0000] a3a0e2b7
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-15] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.38
[2020-05-18 20:09:47,000 +0000] 83a59ec9
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-15] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.48
[2020-05-18 20:09:47,046 +0000] 038a0e30
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-8] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.38
[2020-05-18 20:09:47,046 +0000] a3a0e2b7 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 11ms 0ms
0
[2020-05-18 20:09:47,046 +0000] 43948657 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 0ms
0
[2020-05-18 20:09:47,048 +0000] 83a59ec9 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 20:09:47,102 +0000] 038a0e30 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 1ms
0
$ date
Mon May 18 21:22:08 UTC 2020
Apparently our CI jobs occasionally query for the gerrit version, so
the fact that there are such jobs is fine, but the fact that there is
no corresponding "LOGOUT" line in the logs and that the connection is
clearly still open from "gerrit show-connections" makes me wonder why
these zombies exist. (If I use gerrit close-connection" to shut them
down, I'll soon just have another four. It never seems to grow more
than four, though.)
2)
The number of upload-pack processes would increase (as shown by
"gerrit show-connections" and "gerrit show-queue"), most coming from
our CI user of jenkins-gerrit-ro, until the system became
unresponsive. The same number of users and clones and CI jobs were
used last week without issue. The first time, we just restarted the
server. Subsequent times, I discovered that using "gerrit
close-connection" to just close the ssh jobs from jenkins-gerrit-ro
would restore the server to a working state and bring the load way
down (but, of course, break various CI jobs).
It may be worth noting that this instance is just used for serving one
repository, though it's a big one:
$ du -hs ~/installation/git/PATH/TO/REPO.git/
14G /home/gerrit/installation/git/PATH/TO/REPO.git/
The box is a 16 processor machine with 64 GB of RAM, and
container.heapLimit set to 32g (and core.packedGitLimit set at 10g).
Also, from the sshd_log, I can determine that the relevant git version
used by jenkins-gerrit-ro is either 2.9.3 or 2.17.1:
$ grep jenkins-gerrit-ro.*git/ sshd_log | grep -o git/.* | sort | uniq -c
1097 git/2.17.1
1095 git/2.9.3
Does anyone have any ideas what might be causing these problems? Any
ideas of what settings I can/should look into that might help either
fix this, or even just ameliorate this kind of problem? Are there any
other details that would be useful for me to provide? Are there any
known scaling issues that I might just be bumping up close to? (Is it
safe to bump container.heapLimit above 32g? We did that around 7
years ago and got some nasty performance issues despite being on a
machine with even more memory than what we're using now.)
3)
We did find one CI job (unchanged from last week) that was issuing
full clones and seemed to be responsible for a good chunk of the
piled-up ssh jobs. We have temporarily disabled this job and will be
switching over to getting an initial bundle via another means. Doing
this has reduced the gerrit server load enough that we're stable now
and have some time to investigate.
Thanks,
Elijah
We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
(temporarily going through 2.16.18 in order to migrate off NoteDB),
and had a couple outages when developers came online today. After
some digging, we found the following things that looked weird:
1)
There are nearly always four open ssh connections attempting to do
nothing more than run "gerrit version", and the jobs seem to hang
around indefinitely unless I manually close them (with "gerrit
close-connection"):
$ grep -F -f <(ssh -i special-key -p 29418 special-user@localhost
gerrit show-connections | awk {print\$1} | grep -E '[0-9a-f]{8}')
~/installation/logs/sshd_log | grep jenkins-gerrit-ro
[2020-05-18 20:09:46,994 +0000] 43948657
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-2] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.106
[2020-05-18 20:09:47,000 +0000] a3a0e2b7
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-15] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.38
[2020-05-18 20:09:47,000 +0000] 83a59ec9
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-15] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.48
[2020-05-18 20:09:47,046 +0000] 038a0e30
[sshd-SshDaemon[51e14cb6](port=22)-nio2-thread-8] jenkins-gerrit-ro
a/1429 LOGIN FROM 10.2.217.38
[2020-05-18 20:09:47,046 +0000] a3a0e2b7 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 11ms 0ms
0
[2020-05-18 20:09:47,046 +0000] 43948657 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 0ms
0
[2020-05-18 20:09:47,048 +0000] 83a59ec9 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 20:09:47,102 +0000] 038a0e30 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 1ms
0
$ date
Mon May 18 21:22:08 UTC 2020
Apparently our CI jobs occasionally query for the gerrit version, so
the fact that there are such jobs is fine, but the fact that there is
no corresponding "LOGOUT" line in the logs and that the connection is
clearly still open from "gerrit show-connections" makes me wonder why
these zombies exist. (If I use gerrit close-connection" to shut them
down, I'll soon just have another four. It never seems to grow more
than four, though.)
2)
The number of upload-pack processes would increase (as shown by
"gerrit show-connections" and "gerrit show-queue"), most coming from
our CI user of jenkins-gerrit-ro, until the system became
unresponsive. The same number of users and clones and CI jobs were
used last week without issue. The first time, we just restarted the
server. Subsequent times, I discovered that using "gerrit
close-connection" to just close the ssh jobs from jenkins-gerrit-ro
would restore the server to a working state and bring the load way
down (but, of course, break various CI jobs).
It may be worth noting that this instance is just used for serving one
repository, though it's a big one:
$ du -hs ~/installation/git/PATH/TO/REPO.git/
14G /home/gerrit/installation/git/PATH/TO/REPO.git/
The box is a 16 processor machine with 64 GB of RAM, and
container.heapLimit set to 32g (and core.packedGitLimit set at 10g).
Also, from the sshd_log, I can determine that the relevant git version
used by jenkins-gerrit-ro is either 2.9.3 or 2.17.1:
$ grep jenkins-gerrit-ro.*git/ sshd_log | grep -o git/.* | sort | uniq -c
1097 git/2.17.1
1095 git/2.9.3
Does anyone have any ideas what might be causing these problems? Any
ideas of what settings I can/should look into that might help either
fix this, or even just ameliorate this kind of problem? Are there any
other details that would be useful for me to provide? Are there any
known scaling issues that I might just be bumping up close to? (Is it
safe to bump container.heapLimit above 32g? We did that around 7
years ago and got some nasty performance issues despite being on a
machine with even more memory than what we're using now.)
3)
We did find one CI job (unchanged from last week) that was issuing
full clones and seemed to be responsible for a good chunk of the
piled-up ssh jobs. We have temporarily disabled this job and will be
switching over to getting an initial bundle via another means. Doing
this has reduced the gerrit server load enough that we're stable now
and have some time to investigate.
Thanks,
Elijah
Elijah Newren
May 18, 2020, 6:05:52 PM5/18/20
to repo-discuss
On Mon, May 18, 2020 at 2:49 PM Elijah Newren <new...@gmail.com> wrote:
>
> Hi,
>
> We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
> (temporarily going through 2.16.18 in order to migrate off NoteDB),
> and had a couple outages when developers came online today. After
> some digging, we found the following things that looked weird:
>
...
>
> Hi,
>
> We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
> (temporarily going through 2.16.18 in order to migrate off NoteDB),
> and had a couple outages when developers came online today. After
> some digging, we found the following things that looked weird:
>
> 3)
>
> We did find one CI job (unchanged from last week) that was issuing
> full clones and seemed to be responsible for a good chunk of the
> piled-up ssh jobs. We have temporarily disabled this job and will be
> switching over to getting an initial bundle via another means. Doing
> this has reduced the gerrit server load enough that we're stable now
> and have some time to investigate.
Sorry, my editing of the email made that confusing. Item *3* did NOT
>
> We did find one CI job (unchanged from last week) that was issuing
> full clones and seemed to be responsible for a good chunk of the
> piled-up ssh jobs. We have temporarily disabled this job and will be
> switching over to getting an initial bundle via another means. Doing
> this has reduced the gerrit server load enough that we're stable now
> and have some time to investigate.
look weird to us, only items 1 and 2 did. Item 3 was just a note I
added about what we've done as an interim workaround.

Luca Milanesio
May 18, 2020, 6:08:53 PM5/18/20
to Elijah Newren, Luca Milanesio, repo-discuss
On 18 May 2020, at 22:49, Elijah Newren <new...@gmail.com> wrote:Hi,
We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
(temporarily going through 2.16.18 in order to migrate off NoteDB),
and had a couple outages when developers came online today.
Migrating from v2.15.x to v3.1.x means a 4 major versions change.
Gerrit is a completely different beast in v3.1 :-)
- Different UI
- Different backend storage
- Different versions of the HTTP and SSH protocol libraries
- Different JGit versions
Also note that also the storage of the changes meta-data has changed and it is all in your Git repositories.
(NoteDb)
Have you done a test migration beforehand?
If yes, did you use any load-testing tool (e.g. Gatling or similar) for checking the performance of the system once migrated to v3.1?
(See [1] below on the e-mail, for a useful blogpost and video of how to use Gatling for testing Gerrit)
After
some digging, we found the following things that looked weird:
1)
There are nearly always four open ssh connections attempting to do
nothing more than run "gerrit version", and the jobs seem to hang
around indefinitely unless I manually close them (with "gerrit
close-connection"):
They can’t be hanged forever, otherwise they’ll be a lot more than just 4, isn’t it?
I believe they are possibly going over and over again asking for a Gerrit version.
SSH connections are a very precious resource in Gerrit, why are you asking for the version all the times?
Are you trying to do some sort of healthcheck?
If yes, why don’t you use the healthcheck plugin instead? (See [2]).
Are you using the Gerrit-trigger plugin on Jenkins?
It could be possibly that plugin doing this type of polling.
P.S. When migrating to a newer version of Gerrit, one of the things to test is the integration with the other CI/CD components, 1st place the Jenkins CI pipeline.
2)
The number of upload-pack processes would increase (as shown by
"gerrit show-connections" and "gerrit show-queue"), most coming from
our CI user of jenkins-gerrit-ro, until the system became
unresponsive. The same number of users and clones and CI jobs were
used last week without issue.
Have you performed some aggressive GC after migration?
It is well known that after the migration to NoteDb the repositories are left in a quite unoptimised state: they do need aggressive GC for coming back to shape.
Also, bear in mind that you’ll have an incredible amount of new refs, so you should use a recent Git client on the CI side to enable the protocol v2.
See at [3] for a blog post on how to enable Git protocol v2.
The first time, we just restarted the
server. Subsequent times, I discovered that using "gerrit
close-connection" to just close the ssh jobs from jenkins-gerrit-ro
would restore the server to a working state and bring the load way
down (but, of course, break various CI jobs).
It may be worth noting that this instance is just used for serving one
repository, though it's a big one:
$ du -hs ~/installation/git/PATH/TO/REPO.git/
14G /home/gerrit/installation/git/PATH/TO/REPO.git/
Wow, that’s a big repo indeed. And that’s the compressed size.
Have you tried running git-sizer on it? (See [4]).
The box is a 16 processor machine with 64 GB of RAM, and
container.heapLimit set to 32g (and core.packedGitLimit set at 10g).
Also, from the sshd_log, I can determine that the relevant git version
used by jenkins-gerrit-ro is either 2.9.3 or 2.17.1:
$ grep jenkins-gerrit-ro.*git/ sshd_log | grep -o git/.* | sort | uniq -c
1097 git/2.17.1
1095 git/2.9.3
Those look *veeery* old. You should consider using a more recent Git client version that supports protocol v2.
Does anyone have any ideas what might be causing these problems?
Many many things can happen in 4 major migrations, including a NoteDb conversion.
What I typically do with my clients is to go through a full health-check of the system, logs and configuration.
Have you done a health-check before starting the migration process?
And after the migration?
Any
ideas of what settings I can/should look into that might help either
fix this, or even just ameliorate this kind of problem? Are there any
other details that would be useful for me to provide?
Yes:
- full config
- the past 7 days of logs (before the migration) and 24h after the migration
- metrics
Are there any
known scaling issues that I might just be bumping up close to?
AFAIK the conversion to NoteDb with the increased number of refs is the major performance issue.
It can be mitigated though, with proper healthcheck and testing.
(Is it
safe to bump container.heapLimit above 32g? We did that around 7
years ago and got some nasty performance issues despite being on a
machine with even more memory than what we're using now.)
Not a good idea IMHO, unless you move to Java11.
Java 8 won’t be able to manage an effective GC phase with very large heaps.
References:
HTH
Luca.
Elijah Newren
May 18, 2020, 8:54:33 PM5/18/20
to Luca Milanesio, repo-discuss
Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
> On 18 May 2020, at 22:49, Elijah Newren <new...@gmail.com> wrote:
>
> Hi,
>
> We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
> (temporarily going through 2.16.18 in order to migrate off NoteDB),
> and had a couple outages when developers came online today.
>
>
> Migrating from v2.15.x to v3.1.x means a 4 major versions change.
Actually, 3. (-> 2.16 -> 3.0 -> 3.1) But yeah, I get your point that
it was a bunch to do at once. I didn't want to be stuck on 2.16 with
ReviewDB, though, especially since it too will be EOL very soon. :-)
> Gerrit is a completely different beast in v3.1 :-)
> - Different UI
> - Different backend storage
> - Different versions of the HTTP and SSH protocol libraries
> - Different JGit versions
>
> Also note that also the storage of the changes meta-data has changed and it is all in your Git repositories.
> (NoteDb)
Yep, I know, I read through all the release notes.
> Have you done a test migration beforehand?
> If yes, did you use any load-testing tool (e.g. Gatling or similar) for checking the performance of the system once migrated to v3.1?
> (See [1] below on the e-mail, for a useful blogpost and video of how to use Gatling for testing Gerrit)
Yes, multiple test migrations actually...but not with load-testing; I
agree that would have been better. Thanks for the link.
> After
> some digging, we found the following things that looked weird:
>
> 1)
>
> There are nearly always four open ssh connections attempting to do
> nothing more than run "gerrit version", and the jobs seem to hang
> around indefinitely unless I manually close them (with "gerrit
> close-connection"):
>
>
> They can’t be hanged forever, otherwise they’ll be a lot more than just 4, isn’t it?
> I believe they are possibly going over and over again asking for a Gerrit version.
>
>
> SSH connections are a very precious resource in Gerrit, why are you asking for the version all the times?
> Are you trying to do some sort of healthcheck?
> If yes, why don’t you use the healthcheck plugin instead? (See [2]).
I'm not sure right now what is triggering them, though if the
Gerrit-Trigger plugin in jenkins does this as you guess below, then it
is quite likely it is the one doing it.
Interestingly enough, it does appear to be exactly four; and if I
manually close them, then a new four immediately start. I can see
which ones have been around during the day as well:
$ grep SSH.gerrit.version.*jenkins-gerrit-ro sshd_log
<snip>
[2020-05-18 19:40:50,761 +0000] 4866bfda [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 5ms 1ms 0
[2020-05-18 19:40:50,823 +0000] 886cb7ba [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 8ms 1ms 0
[2020-05-18 19:40:50,833 +0000] a8717b95 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 6ms 0ms 0
[2020-05-18 19:40:50,843 +0000] e83e93ac [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 15ms 1ms
0
[2020-05-18 19:56:30,827 +0000] 488a5a2b [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 1ms 0
[2020-05-18 19:56:30,837 +0000] e88eae3b [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 3ms 0ms 0
[2020-05-18 19:56:30,882 +0000] 857b5d0d [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 1ms 0ms 0
[2020-05-18 21:24:51,769 +0000] 8e5fc3f6 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 1ms 1ms 0
[2020-05-18 21:24:51,786 +0000] ae6727d4 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 1ms 0ms 0
The times when a new four were launched correspond to when I decided
to do "gerrit close-connection" runs on the previous ones, assuming
they were stuck.
> Are you using the Gerrit-trigger plugin on Jenkins?
> It could be possibly that plugin doing this type of polling.
Yes, we're using the Gerrit-trigger plugin on Jenkins. (And have two
different Jenkins instances, though that's another story)
> P.S. When migrating to a newer version of Gerrit, one of the things to test is the integration with the other CI/CD components, 1st place the Jenkins CI pipeline.
Yep, that has bit us in past upgrades before and is a place we know we
should check. Though we have only ever checked that connections and
builds succeed; we haven't previously done load testing on our staging
instance as part of the test upgrade process.
> 2)
>
> The number of upload-pack processes would increase (as shown by
> "gerrit show-connections" and "gerrit show-queue"), most coming from
> our CI user of jenkins-gerrit-ro, until the system became
> unresponsive. The same number of users and clones and CI jobs were
> used last week without issue.
>
>
> Have you performed some aggressive GC after migration?
> It is well known that after the migration to NoteDb the repositories are left in a quite unoptimised state: they do need aggressive GC for coming back to shape.
I did a gc, but not an aggressive one. I'll try that tonight.
> Also, bear in mind that you’ll have an incredible amount of new refs, so you should use a recent Git client on the CI side to enable the protocol v2.
>
> See at [3] for a blog post on how to enable Git protocol v2.
Protocol v2 is certainly one of the things I've been looking forward
to, though I really wanted to avoid switching to it until I first
finished the upgrade and had a good baseline with it in combination
with everything else staying as it was.
Also...is it really that many more refs? I don't see anything that
suggests an order of magnitude difference:
$ cd /PATH/TO/our-big-repo.git
$ git show-ref | wc -l
475393
$ git show-ref | grep meta | wc -l
136129
I seem to recall somewhere in the 300K range being the amount we had
before, so I'm guessing that the NoteDB refs are limited to the "meta"
ones. While this is certainly a big jump, it's not an order of
magnitude difference.
Also, the protocol v2 issues noted in git-2.26 particularly with the
reports from the linux kernel folks, had me slightly spooked about
jumping to it too early. (The pack protocol isn't a part of git I'm
familiar with or want to debug, though I am definitely looking forward
to when it's safe to try to switch over to it.)
> The first time, we just restarted the
> server. Subsequent times, I discovered that using "gerrit
> close-connection" to just close the ssh jobs from jenkins-gerrit-ro
> would restore the server to a working state and bring the load way
> down (but, of course, break various CI jobs).
>
> It may be worth noting that this instance is just used for serving one
> repository, though it's a big one:
>
> $ du -hs ~/installation/git/PATH/TO/REPO.git/
> 14G /home/gerrit/installation/git/PATH/TO/REPO.git/
>
>
> Wow, that’s a big repo indeed. And that’s the compressed size.
> Have you tried running git-sizer on it? (See [4]).
Yes, a few times over the years. It's annoyingly big, and yes there
are large binaries in the past that it would be nice to clean up. But
it's not just one or two big binaries, and even though we now have
nice tools to rewrite the history since about a year ago, even if we
could easily figure out all the things we should delete (which is a
big project itself), actually deleting them is a big flag day event
that has lots of ramifications throughout the rest of our systems.
It's not clear yet that we're ready for that; making the Gerrit UI
understand replace refs, and modifying commit-graph in git to not shut
itself off when there are replace refs that don't change the topology
are probably some needed pre-requisites.
Even if we did nuke old binaries from the repo, it would help less
than you think (I have done some exploratory testing examples in the
past). In part, the repo is just really big.
> The box is a 16 processor machine with 64 GB of RAM, and
> container.heapLimit set to 32g (and core.packedGitLimit set at 10g).
>
> Also, from the sshd_log, I can determine that the relevant git version
> used by jenkins-gerrit-ro is either 2.9.3 or 2.17.1:
> $ grep jenkins-gerrit-ro.*git/ sshd_log | grep -o git/.* | sort | uniq -c
> 1097 git/2.17.1
> 1095 git/2.9.3
>
> Those look *veeery* old. You should consider using a more recent Git client version that supports protocol v2.
Yep, agreed.
> Does anyone have any ideas what might be causing these problems?
>
>
> Many many things can happen in 4 major migrations, including a NoteDb conversion.
>
> What I typically do with my clients is to go through a full health-check of the system, logs and configuration.
> Have you done a health-check before starting the migration process?
> And after the migration?
Not sure exactly what you're looking for, but we had been going
through the logs to find for example that we were affected by
https://bugs.eclipse.org/bugs/show_bug.cgi?id=544199 (an upgrade to
gerrit 2.15.18 fixed that), and were getting occasional database
connection issues ("Concurrent modification detected" and some others,
maybe a few times a week; all my leads turned up dry so I still don't
know the cause on those) despite MariaDB being on localhost. We
wanted to get off ReviewDB as a way of just making the issue moot,
plus we felt bad that we had gone so long without an upgrade.
I was looking through the logs after the migration and even during the
system becoming non-responsive; all I saw was that the SAML plugin is
extraordinarily chatty and some internal server errors on upload-pack
operations that look like the kind you get when someone hits Ctrl-C
during a fetch that they decide they don't want to wait for after all.
> Any
> ideas of what settings I can/should look into that might help either
> fix this, or even just ameliorate this kind of problem? Are there any
> other details that would be useful for me to provide?
>
>
> Yes:
> - full config
Attached as redacted-gerrit.config. I am slightly surprised that the
notedb migration didn't remove the database section from
gerrit.config. Is that still needed or can I remove it?
(Several other settings in our gerrit.config might be left over from
any of the dozens of different versions we've used over the last
decade too; please do feel free to tell me to remove or update stuff.)
> - the past 7 days of logs (before the migration) and 24h after the migration
That's 1M lines of logs, 223MB uncompressed. It'll take me a long
time to go through and check for whatever needs to be redacted. Is
there anything in particular you're looking for that I might be able
to find more quickly?
> - metrics
What metrics in particular?
One bit of good news is that redoing that one CI job that was using
full clones each time seems to have dropped the load to very low; our
load average stayed below 3 afterward and now that most have ended the
workday, it's actually below 0.1.
Maybe we were just close to pushing things over before, and the NoteDB
and other changes just pushed us past some limit?
> Are there any
> known scaling issues that I might just be bumping up close to?
>
>
> AFAIK the conversion to NoteDb with the increased number of refs is the major performance issue.
> It can be mitigated though, with proper healthcheck and testing.
Thanks, this and your suggestion to do an aggressive gc are exactly
the types of tips that I was hoping I might get. As noted above, I'll
try out the aggressive gc tonight.
> (Is it
> safe to bump container.heapLimit above 32g? We did that around 7
> years ago and got some nasty performance issues despite being on a
> machine with even more memory than what we're using now.)
>
>
> Not a good idea IMHO, unless you move to Java11.
>
> Java 8 won’t be able to manage an effective GC phase with very large heaps.
Thanks, that's good info to be aware of. Since the Gerrit release
notes suggest Java 11 isn't officially supported until Gerrit-3.2,
we'll have to wait off on that.
> References:
> [1] https://gitenterprise.me/2019/12/20/stress-your-gerrit-with-gatling/
> [2] https://gerrit.googlesource.com/plugins/healthcheck
> [3] https://gitenterprise.me/2020/05/15/gerrit-goes-git-v2/
> [4] https://github.com/github/git-sizer
Ooh, I wasn't aware of the gatling or healthcheck things. I'll make a
note to check out gatling later.
The healthcheck plugin seems nice, but there's something weird with it
trying it out just now. After getting a Gerrit http password
generated for a service account and specifying that username and
password in healthcheck.config so that the auth check would pass, the
query check is still failing. Yet using the REST API to do a query
with the same user and password to query for open tickets from my
laptop (which has to round-trip from western USA to eastern USA)
returns 10K lines of output in a little over 1.2 seconds. How is the
healthcheck plugin attempting to do its querychanges? Does it not
re-use the credentials specified for the auth check? (The other
checks all pass.)
> HTH
Yes, very much, thank you!
One other related question: I noticed at
https://gerrit-review.googlesource.com/Documentation/access-control.html#capability_priority
that I should be able to grant some group Priority-Batch permissions
somehow so that I can limit the number of CI jobs hitting the server
at once, which seems like another way that might help avoid these
overloads. I don't seem to have a Non-Interactive Users group or
anything with this capability already set. However, when I go to
https://gerrit.COMPANY.SITE/admin/repos/All-Projects,access, I can
only figure out how to set "Priority" global capability, not
"Priority: Batch" or however it's called. How do I set this? (If the
UI doesn't allow it, can I work around it by cloning the
All-Projects.git repo and doing some nice "git config -f ..." command
and pushing it back?)
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
> On 18 May 2020, at 22:49, Elijah Newren <new...@gmail.com> wrote:
>
> Hi,
>
> We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
> (temporarily going through 2.16.18 in order to migrate off NoteDB),
> and had a couple outages when developers came online today.
>
>
> Migrating from v2.15.x to v3.1.x means a 4 major versions change.
it was a bunch to do at once. I didn't want to be stuck on 2.16 with
ReviewDB, though, especially since it too will be EOL very soon. :-)
> Gerrit is a completely different beast in v3.1 :-)
> - Different UI
> - Different backend storage
> - Different versions of the HTTP and SSH protocol libraries
> - Different JGit versions
>
> Also note that also the storage of the changes meta-data has changed and it is all in your Git repositories.
> (NoteDb)
> Have you done a test migration beforehand?
> If yes, did you use any load-testing tool (e.g. Gatling or similar) for checking the performance of the system once migrated to v3.1?
> (See [1] below on the e-mail, for a useful blogpost and video of how to use Gatling for testing Gerrit)
agree that would have been better. Thanks for the link.
> After
> some digging, we found the following things that looked weird:
>
> 1)
>
> There are nearly always four open ssh connections attempting to do
> nothing more than run "gerrit version", and the jobs seem to hang
> around indefinitely unless I manually close them (with "gerrit
> close-connection"):
>
>
> They can’t be hanged forever, otherwise they’ll be a lot more than just 4, isn’t it?
> I believe they are possibly going over and over again asking for a Gerrit version.
>
>
> SSH connections are a very precious resource in Gerrit, why are you asking for the version all the times?
> Are you trying to do some sort of healthcheck?
> If yes, why don’t you use the healthcheck plugin instead? (See [2]).
Gerrit-Trigger plugin in jenkins does this as you guess below, then it
is quite likely it is the one doing it.
Interestingly enough, it does appear to be exactly four; and if I
manually close them, then a new four immediately start. I can see
which ones have been around during the day as well:
$ grep SSH.gerrit.version.*jenkins-gerrit-ro sshd_log
<snip>
[2020-05-18 19:40:50,761 +0000] 4866bfda [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 5ms 1ms 0
[2020-05-18 19:40:50,823 +0000] 886cb7ba [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 8ms 1ms 0
[2020-05-18 19:40:50,833 +0000] a8717b95 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 6ms 0ms 0
[2020-05-18 19:40:50,843 +0000] e83e93ac [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 15ms 1ms
0
[2020-05-18 19:56:30,827 +0000] 488a5a2b [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 1ms 0
[2020-05-18 19:56:30,837 +0000] e88eae3b [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 19:56:30,865 +0000] 2885a61a [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 3ms 0ms 0
[2020-05-18 19:56:30,882 +0000] 857b5d0d [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 20:09:47,046 +0000] a3a0e2b7 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 11ms 0ms
0
[2020-05-18 20:09:47,046 +0000] 43948657 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 0ms
0
[2020-05-18 20:09:47,048 +0000] 83a59ec9 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 20:09:47,102 +0000] 038a0e30 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 1ms
0
[2020-05-18 21:24:51,718 +0000] ee92ffc4 [SSH gerrit version
[2020-05-18 20:09:47,046 +0000] a3a0e2b7 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 11ms 0ms
0
[2020-05-18 20:09:47,046 +0000] 43948657 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 0ms
0
[2020-05-18 20:09:47,048 +0000] 83a59ec9 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 20:09:47,102 +0000] 038a0e30 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 14ms 1ms
0
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 2ms 0ms 0
[2020-05-18 21:24:51,742 +0000] 4e59cb0f [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 1ms 0ms 0
[2020-05-18 21:24:51,769 +0000] 8e5fc3f6 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 1ms 1ms 0
[2020-05-18 21:24:51,786 +0000] ae6727d4 [SSH gerrit version
(jenkins-gerrit-ro)] jenkins-gerrit-ro a/1429 gerrit.version 1ms 0ms 0
The times when a new four were launched correspond to when I decided
to do "gerrit close-connection" runs on the previous ones, assuming
they were stuck.
> Are you using the Gerrit-trigger plugin on Jenkins?
> It could be possibly that plugin doing this type of polling.
different Jenkins instances, though that's another story)
> P.S. When migrating to a newer version of Gerrit, one of the things to test is the integration with the other CI/CD components, 1st place the Jenkins CI pipeline.
should check. Though we have only ever checked that connections and
builds succeed; we haven't previously done load testing on our staging
instance as part of the test upgrade process.
> 2)
>
> The number of upload-pack processes would increase (as shown by
> "gerrit show-connections" and "gerrit show-queue"), most coming from
> our CI user of jenkins-gerrit-ro, until the system became
> unresponsive. The same number of users and clones and CI jobs were
> used last week without issue.
>
>
> Have you performed some aggressive GC after migration?
> It is well known that after the migration to NoteDb the repositories are left in a quite unoptimised state: they do need aggressive GC for coming back to shape.
> Also, bear in mind that you’ll have an incredible amount of new refs, so you should use a recent Git client on the CI side to enable the protocol v2.
>
> See at [3] for a blog post on how to enable Git protocol v2.
to, though I really wanted to avoid switching to it until I first
finished the upgrade and had a good baseline with it in combination
with everything else staying as it was.
Also...is it really that many more refs? I don't see anything that
suggests an order of magnitude difference:
$ cd /PATH/TO/our-big-repo.git
$ git show-ref | wc -l
475393
$ git show-ref | grep meta | wc -l
136129
I seem to recall somewhere in the 300K range being the amount we had
before, so I'm guessing that the NoteDB refs are limited to the "meta"
ones. While this is certainly a big jump, it's not an order of
magnitude difference.
Also, the protocol v2 issues noted in git-2.26 particularly with the
reports from the linux kernel folks, had me slightly spooked about
jumping to it too early. (The pack protocol isn't a part of git I'm
familiar with or want to debug, though I am definitely looking forward
to when it's safe to try to switch over to it.)
> The first time, we just restarted the
> server. Subsequent times, I discovered that using "gerrit
> close-connection" to just close the ssh jobs from jenkins-gerrit-ro
> would restore the server to a working state and bring the load way
> down (but, of course, break various CI jobs).
>
> It may be worth noting that this instance is just used for serving one
> repository, though it's a big one:
>
> $ du -hs ~/installation/git/PATH/TO/REPO.git/
> 14G /home/gerrit/installation/git/PATH/TO/REPO.git/
>
>
> Wow, that’s a big repo indeed. And that’s the compressed size.
> Have you tried running git-sizer on it? (See [4]).
are large binaries in the past that it would be nice to clean up. But
it's not just one or two big binaries, and even though we now have
nice tools to rewrite the history since about a year ago, even if we
could easily figure out all the things we should delete (which is a
big project itself), actually deleting them is a big flag day event
that has lots of ramifications throughout the rest of our systems.
It's not clear yet that we're ready for that; making the Gerrit UI
understand replace refs, and modifying commit-graph in git to not shut
itself off when there are replace refs that don't change the topology
are probably some needed pre-requisites.
Even if we did nuke old binaries from the repo, it would help less
than you think (I have done some exploratory testing examples in the
past). In part, the repo is just really big.
> The box is a 16 processor machine with 64 GB of RAM, and
> container.heapLimit set to 32g (and core.packedGitLimit set at 10g).
>
> Also, from the sshd_log, I can determine that the relevant git version
> used by jenkins-gerrit-ro is either 2.9.3 or 2.17.1:
> $ grep jenkins-gerrit-ro.*git/ sshd_log | grep -o git/.* | sort | uniq -c
> 1097 git/2.17.1
> 1095 git/2.9.3
>
> Those look *veeery* old. You should consider using a more recent Git client version that supports protocol v2.
> Does anyone have any ideas what might be causing these problems?
>
>
> Many many things can happen in 4 major migrations, including a NoteDb conversion.
>
> What I typically do with my clients is to go through a full health-check of the system, logs and configuration.
> Have you done a health-check before starting the migration process?
> And after the migration?
through the logs to find for example that we were affected by
https://bugs.eclipse.org/bugs/show_bug.cgi?id=544199 (an upgrade to
gerrit 2.15.18 fixed that), and were getting occasional database
connection issues ("Concurrent modification detected" and some others,
maybe a few times a week; all my leads turned up dry so I still don't
know the cause on those) despite MariaDB being on localhost. We
wanted to get off ReviewDB as a way of just making the issue moot,
plus we felt bad that we had gone so long without an upgrade.
I was looking through the logs after the migration and even during the
system becoming non-responsive; all I saw was that the SAML plugin is
extraordinarily chatty and some internal server errors on upload-pack
operations that look like the kind you get when someone hits Ctrl-C
during a fetch that they decide they don't want to wait for after all.
> Any
> ideas of what settings I can/should look into that might help either
> fix this, or even just ameliorate this kind of problem? Are there any
> other details that would be useful for me to provide?
>
>
> Yes:
> - full config
notedb migration didn't remove the database section from
gerrit.config. Is that still needed or can I remove it?
(Several other settings in our gerrit.config might be left over from
any of the dozens of different versions we've used over the last
decade too; please do feel free to tell me to remove or update stuff.)
> - the past 7 days of logs (before the migration) and 24h after the migration
time to go through and check for whatever needs to be redacted. Is
there anything in particular you're looking for that I might be able
to find more quickly?
> - metrics
What metrics in particular?
One bit of good news is that redoing that one CI job that was using
full clones each time seems to have dropped the load to very low; our
load average stayed below 3 afterward and now that most have ended the
workday, it's actually below 0.1.
Maybe we were just close to pushing things over before, and the NoteDB
and other changes just pushed us past some limit?
> Are there any
> known scaling issues that I might just be bumping up close to?
>
>
> AFAIK the conversion to NoteDb with the increased number of refs is the major performance issue.
> It can be mitigated though, with proper healthcheck and testing.
the types of tips that I was hoping I might get. As noted above, I'll
try out the aggressive gc tonight.
> (Is it
> safe to bump container.heapLimit above 32g? We did that around 7
> years ago and got some nasty performance issues despite being on a
> machine with even more memory than what we're using now.)
>
>
> Not a good idea IMHO, unless you move to Java11.
>
> Java 8 won’t be able to manage an effective GC phase with very large heaps.
notes suggest Java 11 isn't officially supported until Gerrit-3.2,
we'll have to wait off on that.
> References:
> [1] https://gitenterprise.me/2019/12/20/stress-your-gerrit-with-gatling/
> [2] https://gerrit.googlesource.com/plugins/healthcheck
> [3] https://gitenterprise.me/2020/05/15/gerrit-goes-git-v2/
> [4] https://github.com/github/git-sizer
note to check out gatling later.
The healthcheck plugin seems nice, but there's something weird with it
trying it out just now. After getting a Gerrit http password
generated for a service account and specifying that username and
password in healthcheck.config so that the auth check would pass, the
query check is still failing. Yet using the REST API to do a query
with the same user and password to query for open tickets from my
laptop (which has to round-trip from western USA to eastern USA)
returns 10K lines of output in a little over 1.2 seconds. How is the
healthcheck plugin attempting to do its querychanges? Does it not
re-use the credentials specified for the auth check? (The other
checks all pass.)
> HTH
Yes, very much, thank you!
One other related question: I noticed at
https://gerrit-review.googlesource.com/Documentation/access-control.html#capability_priority
that I should be able to grant some group Priority-Batch permissions
somehow so that I can limit the number of CI jobs hitting the server
at once, which seems like another way that might help avoid these
overloads. I don't seem to have a Non-Interactive Users group or
anything with this capability already set. However, when I go to
https://gerrit.COMPANY.SITE/admin/repos/All-Projects,access, I can
only figure out how to set "Priority" global capability, not
"Priority: Batch" or however it's called. How do I set this? (If the
UI doesn't allow it, can I work around it by cloning the
All-Projects.git repo and doing some nice "git config -f ..." command
and pushing it back?)
Luca Milanesio
May 19, 2020, 5:06:10 AM5/19/20
to Elijah Newren, Luca Milanesio, repo-discuss
On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 18 May 2020, at 22:49, Elijah Newren <new...@gmail.com> wrote:
Hi,
We upgraded over the weekend from Gerrit 2.15.18 to Gerrit.3.1.4
(temporarily going through 2.16.18 in order to migrate off NoteDB),
and had a couple outages when developers came online today.
Migrating from v2.15.x to v3.1.x means a 4 major versions change.
Actually, 3. (-> 2.16 -> 3.0 -> 3.1) But yeah, I get your point that
it was a bunch to do at once. I didn't want to be stuck on 2.16 with
ReviewDB, though, especially since it too will be EOL very soon. :-)
v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
Also, the API behave differently when you are on ReviewDb compared to NoteDb.
It is therefore a migration and needs to be executed as such.
Thanks to the excellent work of Dave Borowitz, the NoteDb migration can be done with zero-downtime.
Gerrit is a completely different beast in v3.1 :-)
- Different UI
- Different backend storage
- Different versions of the HTTP and SSH protocol libraries
- Different JGit versions
Also note that also the storage of the changes meta-data has changed and it is all in your Git repositories.
(NoteDb)
Yep, I know, I read through all the release notes.Have you done a test migration beforehand?
If yes, did you use any load-testing tool (e.g. Gatling or similar) for checking the performance of the system once migrated to v3.1?
(See [1] below on the e-mail, for a useful blogpost and video of how to use Gatling for testing Gerrit)
Yes, multiple test migrations actually...but not with load-testing; I
agree that would have been better. Thanks for the link.
As Shawn (the Gerrit project founder) always said: “performance is a feature, and a very important one”.
The session IDs look all different, so they are not “stuck” but just different sessions.
It’s a +40% increment on the number of refs, that could have a massive impact on the Git negotiation phase.
I seem to recall somewhere in the 300K range being the amount we had
before, so I'm guessing that the NoteDB refs are limited to the "meta"
ones. While this is certainly a big jump, it's not an order of
magnitude difference.
Bear in mind that the complexity of the Git negotiation phase is not linear: a doubling on the number of refs could mean more than doubling of the negotiation phase.
That’s the reason why the Git protocol was changed :-)
Also, the protocol v2 issues noted in git-2.26 particularly with the
reports from the linux kernel folks, had me slightly spooked about
jumping to it too early. (The pack protocol isn't a part of git I'm
familiar with or want to debug, though I am definitely looking forward
to when it's safe to try to switch over to it.)
Can you report to the discussions and the issues they were referring to?
I was referring to the health-check service we provide as a company (GerritForge).
It includes a lot of activities, including configuration and performance check.
Any
ideas of what settings I can/should look into that might help either
fix this, or even just ameliorate this kind of problem? Are there any
other details that would be useful for me to provide?
Yes:
- full config
Attached as redacted-gerrit.config. I am slightly surprised that the
notedb migration didn't remove the database section from
gerrit.config. Is that still needed or can I remove it?
Not needed in v3.1. Did you amend the configuration after migration?
The NoteDb migration *should not* change the gerrit.config because ReviewDb is still needed in v2.16.
(Several other settings in our gerrit.config might be left over from
any of the dozens of different versions we've used over the last
decade too; please do feel free to tell me to remove or update stuff.)- the past 7 days of logs (before the migration) and 24h after the migration
That's 1M lines of logs, 223MB uncompressed. It'll take me a long
time to go through and check for whatever needs to be redacted. Is
there anything in particular you're looking for that I might be able
to find more quickly?
See my comments above on the healthcheck service.
But of course, you could do the same yourself.
You should look for:
- configuration settings up to date compared to the configs
- timeouts
- known issues
- performance of the Git/HTTP and Git/SSH protocol
- wait times
- errors and warnings
- JGit errors
- metrics
What metrics in particular?
JavaMelody for start.
One bit of good news is that redoing that one CI job that was using
full clones each time seems to have dropped the load to very low; our
load average stayed below 3 afterward and now that most have ended the
workday, it's actually below 0.1.
Maybe we were just close to pushing things over before, and the NoteDB
and other changes just pushed us past some limit?
See my previous comment on the more than linear complexity of the Git negotiation protocol.
Are there any
known scaling issues that I might just be bumping up close to?
AFAIK the conversion to NoteDb with the increased number of refs is the major performance issue.
It can be mitigated though, with proper healthcheck and testing.
Thanks, this and your suggestion to do an aggressive gc are exactly
the types of tips that I was hoping I might get. As noted above, I'll
try out the aggressive gc tonight.
+1
(Is it
safe to bump container.heapLimit above 32g? We did that around 7
years ago and got some nasty performance issues despite being on a
machine with even more memory than what we're using now.)
Not a good idea IMHO, unless you move to Java11.
Java 8 won’t be able to manage an effective GC phase with very large heaps.
Thanks, that's good info to be aware of. Since the Gerrit release
notes suggest Java 11 isn't officially supported until Gerrit-3.2,
we'll have to wait off on that.
It is *unofficially* supported though from v2.16 onwards, as DavidO merged a lot of patches to allow that.
References:
[1] https://gitenterprise.me/2019/12/20/stress-your-gerrit-with-gatling/
[2] https://gerrit.googlesource.com/plugins/healthcheck
[3] https://gitenterprise.me/2020/05/15/gerrit-goes-git-v2/
[4] https://github.com/github/git-sizer
Ooh, I wasn't aware of the gatling or healthcheck things. I'll make a
note to check out gatling later.
+1
The healthcheck plugin seems nice, but there's something weird with it
trying it out just now. After getting a Gerrit http password
generated for a service account and specifying that username and
password in healthcheck.config so that the auth check would pass, the
query check is still failing. Yet using the REST API to do a query
with the same user and password to query for open tickets from my
laptop (which has to round-trip from western USA to eastern USA)
returns 10K lines of output in a little over 1.2 seconds. How is the
healthcheck plugin attempting to do its querychanges? Does it not
re-use the credentials specified for the auth check? (The other
checks all pass.)
There was actually a bug in Gerrit I fixed in stable-2.16 for that: not a healthcheck problem but rather a regression in core.
The latest patch-releases by end of this week would include the fix for the query healthcheck.
HTH
Yes, very much, thank you!
One other related question: I noticed at
https://gerrit-review.googlesource.com/Documentation/access-control.html#capability_priority
that I should be able to grant some group Priority-Batch permissions
somehow so that I can limit the number of CI jobs hitting the server
at once, which seems like another way that might help avoid these
overloads. I don't seem to have a Non-Interactive Users group or
anything with this capability already set. However, when I go to
https://gerrit.COMPANY.SITE/admin/repos/All-Projects,access, I can
only figure out how to set "Priority" global capability, not
"Priority: Batch" or however it's called. How do I set this? (If the
UI doesn't allow it, can I work around it by cloning the
All-Projects.git repo and doing some nice "git config -f ..." command
and pushing it back?)
That’s the configuration to allow the use of batch vs. Interactive thread pools.
Are you already defining two different max number of connections for batch and interactive users?
Luca.
Elijah Newren
May 19, 2020, 12:41:48 PM5/19/20
to Luca Milanesio, repo-discuss
On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
> On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
>
> Hi Luca,
>
> Wow, thanks for the quick response and many pointers.
>
> On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
> v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
>
> The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
> Also, the API behave differently when you are on ReviewDb compared to NoteDb.
>
> It is therefore a migration and needs to be executed as such.
Fair enough; in fact, that was one of the two big hurdles in our
>
> On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
>
> Hi Luca,
>
> Wow, thanks for the quick response and many pointers.
>
> On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
> v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
>
> The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
> Also, the API behave differently when you are on ReviewDb compared to NoteDb.
>
> It is therefore a migration and needs to be executed as such.
migration. (The other being that Gerrit-3.1 wanted the changes
reindexed offline before it'd start, which of course took forever.)
>
> Thanks to the excellent work of Dave Borowitz, the NoteDb migration can be done with zero-downtime.
did exactly that, but I really wanted to upgrade through 2.16 and end
up at a newer version instead of moving to a soon-to-also-be-EOL
version. :-)
> Bear in mind that the complexity of the Git negotiation phase is not linear: a doubling on the number of refs could mean more than doubling of the negotiation phase.
> That’s the reason why the Git protocol was changed :-)
> Also, the protocol v2 issues noted in git-2.26 particularly with the
> reports from the linux kernel folks, had me slightly spooked about
> jumping to it too early. (The pack protocol isn't a part of git I'm
> familiar with or want to debug, though I am definitely looking forward
> to when it's safe to try to switch over to it.)
>
>
> Can you report to the discussions and the issues they were referring to?
the default), Linux kernel folks reported that fetches expected to
download small updates were instead forced to download gigabytes. The
protocol v2 as default was even reverted; there are fixes for the v2
protocol bugs and the protocol v2 as default was restored (in git
master), but the fact that there were a bunch of reports just after v2
was switched to the default made me worried there might be more issues
lurking. Given that are repo is particularly large and hard to
download and which people sometimes fail to get clones of, anything
that might force downloading much larger portions of it is quite scary
to me, so out of an abundance of caution protocol v2 is now one of
those things where I want there to be more real world testing before I
recommend folks switch to using it internally.
Some links:
https://lore.kernel.org/git/xmqqblnk...@gitster.c.googlers.com/
https://lore.kernel.org/git/20200422095...@coredump.intra.peff.net/
https://lore.kernel.org/git/20200422155...@google.com/
https://lore.kernel.org/git/cover.1588031728....@google.com/
> It may be worth noting that this instance is just used for serving one
> repository, though it's a big one:
>
> $ du -hs ~/installation/git/PATH/TO/REPO.git/
> 14G /home/gerrit/installation/git/PATH/TO/REPO.git/
>
>
> Wow, that’s a big repo indeed. And that’s the compressed size.
> Have you tried running git-sizer on it? (See [4]).
> I was referring to the health-check service we provide as a company (GerritForge).
> It includes a lot of activities, including configuration and performance check.
>
> Of course, it’s a bit difficult to provide that service on a mailing list discussion though :-(
>
>
> Any
> ideas of what settings I can/should look into that might help either
> fix this, or even just ameliorate this kind of problem? Are there any
> other details that would be useful for me to provide?
>
>
> Yes:
> - full config
>
>
> Attached as redacted-gerrit.config. I am slightly surprised that the
> notedb migration didn't remove the database section from
> gerrit.config. Is that still needed or can I remove it?
>
>
> Not needed in v3.1. Did you amend the configuration after migration?
saml.useNameQualifier = false and change httpd.filterClass from
com.thesamet.gerrit.plugins.saml.SamlWebFilter to
com.googlesource.gerrit.plugins.saml.SamlWebFilter due to changes in
the saml plugin. The 2.16 upgrade process (the 'java -jar gerrit.war
init ...' program) itself added the two container.javaOptions
settings.
The 3.1 upgrade process changed index.type from LUCENE to lucene, and
changed the whitespace on the cache.diff.timeout line. As part of
switching to 3.1, we switched from owners to find-owners, and thus
added the plugin.find-owners block.
And thanks for verifying I can remove the database block; I'll remove it.
> The NoteDb migration *should not* change the gerrit.config because ReviewDb is still needed in v2.16.
from that migration. Also, I was unable to turn off mariadb in 2.16
even after migrating to NoteDb, but was able to turn it off after we
switched to 3.1.
> (Several other settings in our gerrit.config might be left over from
> any of the dozens of different versions we've used over the last
> decade too; please do feel free to tell me to remove or update stuff.)
>
> - the past 7 days of logs (before the migration) and 24h after the migration
>
>
> That's 1M lines of logs, 223MB uncompressed. It'll take me a long
> time to go through and check for whatever needs to be redacted. Is
> there anything in particular you're looking for that I might be able
> to find more quickly?
>
>
> See my comments above on the healthcheck service.
> But of course, you could do the same yourself.
>
> You should look for:
> - configuration settings up to date compared to the configs
> - timeouts
> - known issues
> - performance of the Git/HTTP and Git/SSH protocol
> - wait times
> - errors and warnings
> - JGit errors
item and only having a rough feel on the performance timings. I've
got our gerrit.config under version control so I know what changed and
when, but I'm not familiar enough with all the settings to know if
it's considered up to date or obsolete. I tended to only change
things that I knew were needed or okay to change. I'll keep digging
on both.
> - metrics
>
>
> What metrics in particular?
>
>
> JavaMelody for start.
> Thanks, that's good info to be aware of. Since the Gerrit release
> notes suggest Java 11 isn't officially supported until Gerrit-3.2,
> we'll have to wait off on that.
>
>
> It is *unofficially* supported though from v2.16 onwards, as DavidO merged a lot of patches to allow that.
> The healthcheck plugin seems nice, but there's something weird with it
> trying it out just now. After getting a Gerrit http password
> generated for a service account and specifying that username and
> password in healthcheck.config so that the auth check would pass, the
> query check is still failing. Yet using the REST API to do a query
> with the same user and password to query for open tickets from my
> laptop (which has to round-trip from western USA to eastern USA)
> returns 10K lines of output in a little over 1.2 seconds. How is the
> healthcheck plugin attempting to do its querychanges? Does it not
> re-use the credentials specified for the auth check? (The other
> checks all pass.)
>
>
> There was actually a bug in Gerrit I fixed in stable-2.16 for that: not a healthcheck problem but rather a regression in core.
> The latest patch-releases by end of this week would include the fix for the query healthcheck.
will land in the healthcheck plugin repo by end of week, or that the
fixes will land in the Gerrit codebase by end of week and a Gerrit
upgraded would be needed to fix it?
> One other related question: I noticed at
> https://gerrit-review.googlesource.com/Documentation/access-control.html#capability_priority
> that I should be able to grant some group Priority-Batch permissions
> somehow so that I can limit the number of CI jobs hitting the server
> at once, which seems like another way that might help avoid these
> overloads. I don't seem to have a Non-Interactive Users group or
> anything with this capability already set. However, when I go to
> https://gerrit.COMPANY.SITE/admin/repos/All-Projects,access, I can
> only figure out how to set "Priority" global capability, not
> "Priority: Batch" or however it's called. How do I set this? (If the
> UI doesn't allow it, can I work around it by cloning the
> All-Projects.git repo and doing some nice "git config -f ..." command
> and pushing it back?)
>
>
> That’s the configuration to allow the use of batch vs. Interactive thread pools.
> Are you already defining two different max number of connections for batch and interactive users?
since it appears to have been accumulation of certain clone jobs from
CI that made Gerrit non-responsive for us yesterday.
Any hints about how to set this "Priority: Batch" permission? It
doesn't look so clear to me.
Thanks for all the help!
Elijah
Luca Milanesio
May 19, 2020, 12:54:45 PM5/19/20
to Elijah Newren, Luca Milanesio, repo-discuss
On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
Also, the API behave differently when you are on ReviewDb compared to NoteDb.
It is therefore a migration and needs to be executed as such.
Fair enough; in fact, that was one of the two big hurdles in our
migration. (The other being that Gerrit-3.1 wanted the changes
reindexed offline before it'd start, which of course took forever.)
If you do not skip steps, you’ll never have to perform offline reindexing anymore.
On GerritHub it would take *days* to complete, not even sure it would succeed though.
Thanks to the excellent work of Dave Borowitz, the NoteDb migration can be done with zero-downtime.
Yes, but only if you want to stay on 2.16. One of my test upgrades
did exactly that, but I really wanted to upgrade through 2.16 and end
up at a newer version instead of moving to a soon-to-also-be-EOL
version. :-)
Not really, because *once* you’ve migrated to v2.16 / NoteDb then you can start doing rolling upgrades without any downtime or read-only window.
Again, thanks to the amazing job done by Dave Borowitz.
Thanks for the pointers, will look through them.
It may be worth noting that this instance is just used for serving one
repository, though it's a big one:
$ du -hs ~/installation/git/PATH/TO/REPO.git/
14G /home/gerrit/installation/git/PATH/TO/REPO.git/
Wow, that’s a big repo indeed. And that’s the compressed size.
Have you tried running git-sizer on it? (See [4]).
A 'git gc --aggressive' dropped this down to under 10G.
That sounds really good !
Also pay attention to the plugins upgrades / introductions: plugins can also play a role in the upgrade process and the overall scalability.
Always check carefully the differences in the configuration between releases: there are also changes to the default values that require special attention.
E.g. timeouts are the most noticeable ones.
- metrics
What metrics in particular?
JavaMelody for start.
Looks like another thing to add to my list to learn about.
Look at the Gerrit-monitoring project, which contains a lot of configuration and help charts examples of monitoring metrics and dashboards:
Thanks, that's good info to be aware of. Since the Gerrit release
notes suggest Java 11 isn't officially supported until Gerrit-3.2,
we'll have to wait off on that.
It is *unofficially* supported though from v2.16 onwards, as DavidO merged a lot of patches to allow that.
I saw that too, but wanted to stick with officially supported configurations.The healthcheck plugin seems nice, but there's something weird with it
trying it out just now. After getting a Gerrit http password
generated for a service account and specifying that username and
password in healthcheck.config so that the auth check would pass, the
query check is still failing. Yet using the REST API to do a query
with the same user and password to query for open tickets from my
laptop (which has to round-trip from western USA to eastern USA)
returns 10K lines of output in a little over 1.2 seconds. How is the
healthcheck plugin attempting to do its querychanges? Does it not
re-use the credentials specified for the auth check? (The other
checks all pass.)
There was actually a bug in Gerrit I fixed in stable-2.16 for that: not a healthcheck problem but rather a regression in core.
The latest patch-releases by end of this week would include the fix for the query healthcheck.
Are you saying that you have fixed for the healthcheck plugin that
will land in the healthcheck plugin repo by end of week,
No, the healthcheck plugin is fine.
or that the
fixes will land in the Gerrit codebase by end of week and a Gerrit
upgraded would be needed to fix it?
This is correct, Gerrit v2.16.19, v3.0.9 and v3.1.5 will contain the fix in Gerrit core.
It was impacting *ALL* plugins, not just the healthcheck.
One other related question: I noticed at
https://gerrit-review.googlesource.com/Documentation/access-control.html#capability_priority
that I should be able to grant some group Priority-Batch permissions
somehow so that I can limit the number of CI jobs hitting the server
at once, which seems like another way that might help avoid these
overloads. I don't seem to have a Non-Interactive Users group or
anything with this capability already set. However, when I go to
https://gerrit.COMPANY.SITE/admin/repos/All-Projects,access, I can
only figure out how to set "Priority" global capability, not
"Priority: Batch" or however it's called. How do I set this? (If the
UI doesn't allow it, can I work around it by cloning the
All-Projects.git repo and doing some nice "git config -f ..." command
and pushing it back?)
That’s the configuration to allow the use of batch vs. Interactive thread pools.
Are you already defining two different max number of connections for batch and interactive users?
We have not done that in the past, but I wanted to start doing so
since it appears to have been accumulation of certain clone jobs from
CI that made Gerrit non-responsive for us yesterday.
Any hints about how to set this "Priority: Batch" permission? It
doesn't look so clear to me.
I am not really familiar with the “Priority” permission feature in v3.1.x.
Luca

Nasser Grainawi
May 19, 2020, 1:23:46 PM5/19/20
to Luca Milanesio, Elijah Newren, repo-discuss
On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
Also, the API behave differently when you are on ReviewDb compared to NoteDb.
It is therefore a migration and needs to be executed as such.
Fair enough; in fact, that was one of the two big hurdles in our
migration. (The other being that Gerrit-3.1 wanted the changes
reindexed offline before it'd start, which of course took forever.)If you do not skip steps, you’ll never have to perform offline reindexing anymore.On GerritHub it would take *days* to complete, not even sure it would succeed though.
Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?
Elijah, how long did it take you to complete this upgrade/migration? Sorry if you mentioned it before and I missed it.
Thanks to the excellent work of Dave Borowitz, the NoteDb migration can be done with zero-downtime.
Yes, but only if you want to stay on 2.16. One of my test upgrades
did exactly that, but I really wanted to upgrade through 2.16 and end
up at a newer version instead of moving to a soon-to-also-be-EOL
version. :-)Not really, because *once* you’ve migrated to v2.16 / NoteDb then you can start doing rolling upgrades without any downtime or read-only window.Again, thanks to the amazing job done by Dave Borowitz.Bear in mind that the complexity of the Git negotiation phase is not linear: a doubling on the number of refs could mean more than doubling of the negotiation phase.
That’s the reason why the Git protocol was changed :-)
Noted, thanks.
This is a change that we’ve had in our fork for 6+ years now that significantly reduces the impact of additional refs: https://git.eclipse.org/r/24295
Elijah, how many changes total do you have on your server and in this big project specifically?
Java 8 can work quite well with larger heaps and I think there are many users/admins of Gerrit that have large heaps with Java 8. For example, our largest Gerrit server has 256GB of physical memory and we typically size the heap to use 75% of it. Our gerrit javaOptions look roughly like:
javaOptions = "\
-server -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails \
-Xloggc:/path/to/jvm.log \
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=14 \
-XX:GCLogFileSize=1024M \
-Xms193378m -Xmn63814m \
-XX:+UseParallelOldGC -XX:ParallelGCThreads=24 \
-XX:MetaspaceSize=128m \
-XX:+UseNUMA -XX:+UseBiasedLocking \
-XX:+AggressiveOpts”
Luca, if you know of specific Java 8 issues, please reference a bug or documentation.
--
--
To unsubscribe, email repo-discuss...@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-discuss...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/repo-discuss/12CA23E5-A438-4153-875E-8C6F75F48F37%40gmail.com.
Elijah Newren
May 19, 2020, 4:43:18 PM5/19/20
to Nasser Grainawi, Luca Milanesio, repo-discuss
Hi Nasser,
On Tue, May 19, 2020 at 10:23 AM Nasser Grainawi <nas...@codeaurora.org> wrote:
>
> On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:
>
> On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:
>
> On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
>
> On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
>
> Hi Luca,
>
> Wow, thanks for the quick response and many pointers.
>
> On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
>
>
> v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
>
> The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
> Also, the API behave differently when you are on ReviewDb compared to NoteDb.
>
> It is therefore a migration and needs to be executed as such.
>
>
> Fair enough; in fact, that was one of the two big hurdles in our
> migration. (The other being that Gerrit-3.1 wanted the changes
> reindexed offline before it'd start, which of course took forever.)
>
>
> If you do not skip steps, you’ll never have to perform offline reindexing anymore.
> On GerritHub it would take *days* to complete, not even sure it would succeed though.
>
>
> Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?
>
> Elijah, how long did it take you to complete this upgrade/migration? Sorry if you mentioned it before and I missed it.
Specifically, the
java -Xmx32g -jar bin/gerrit-3.1.4.war reindex --threads 12 --index changes
step took approximately 12 hours. I did a gc on the All-Users.git
repository (which finished very quickly) and our large repository
(which added about 40 minutes since I didn't use --aggressive) just
before running this, as well as dramatically lowering
cache.diff.timeout and cache.diff_intraline.timeout (because I don't
care if ancient gargantuan reviews are indexed perfectly accurately --
I'd rather those particular reviews just timed out and did so much
earlier because we're not looking at them again anyway).
In contrast, reindexing projects and groups were both about 15 seconds
each (and were done during the 2.15->2.16 migration, not the 2.16->3.1
upgrade).
The only other part of our upgrade that took a noticeable time was the
java -Xmx12g -jar bin/gerrit-2.16.18.war migrate-to-note-db -d $(pwd)
step. That took around 40 minutes, a good portion of which was
dumping lots of really scary-looking backtraces (which appear to have
been from ancient corruption that affected defunct projects; saw the
same thing during the test migration and spot checked many of the
errors to confirm that they were corruption issues that we knew about
previously, and then also did extra testing in staging to verify that
the repo we cared about was not adversely affected).
> This is a change that we’ve had in our fork for 6+ years now that significantly reduces the impact of additional refs: https://git.eclipse.org/r/24295
Interesting. I see that the patch has sat there for a long time,
though both Matthias and Jonathan have restored it to make sure it
didn't get forgotten. Don't think I want to attempt to forward port
it, but I'm curious to see where it goes.
> Elijah, how many changes total do you have on your server and in this big project specifically?
I'm not sure the way to get the total number. The most recent CR
number is currently 340711, which is probably a pretty good
approximation. (We have had projects deleted in the past, we've had
outages with some corruption in the early Gerrit 2.x days long ago,
etc.)
As for this particular project of interest, I'm guessing I can just
count by the NoteDB meta refs:
$ cd PATH/TO/big-repo.git
Far less than what I hear chromium and other projects have. We have
another project which was sunset a few years back that has more CRs
than this (but still had a smaller repo size), but just barely (~142K
CRs).
On Tue, May 19, 2020 at 10:23 AM Nasser Grainawi <nas...@codeaurora.org> wrote:
>
> On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:
>
> On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:
>
> On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
>
> On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
>
> Hi Luca,
>
> Wow, thanks for the quick response and many pointers.
>
> On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
>
>
>
> v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
>
> The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
> Also, the API behave differently when you are on ReviewDb compared to NoteDb.
>
> It is therefore a migration and needs to be executed as such.
>
>
> Fair enough; in fact, that was one of the two big hurdles in our
> migration. (The other being that Gerrit-3.1 wanted the changes
> reindexed offline before it'd start, which of course took forever.)
>
>
> If you do not skip steps, you’ll never have to perform offline reindexing anymore.
> On GerritHub it would take *days* to complete, not even sure it would succeed though.
>
>
> Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?
>
> Elijah, how long did it take you to complete this upgrade/migration? Sorry if you mentioned it before and I missed it.
java -Xmx32g -jar bin/gerrit-3.1.4.war reindex --threads 12 --index changes
step took approximately 12 hours. I did a gc on the All-Users.git
repository (which finished very quickly) and our large repository
(which added about 40 minutes since I didn't use --aggressive) just
before running this, as well as dramatically lowering
cache.diff.timeout and cache.diff_intraline.timeout (because I don't
care if ancient gargantuan reviews are indexed perfectly accurately --
I'd rather those particular reviews just timed out and did so much
earlier because we're not looking at them again anyway).
In contrast, reindexing projects and groups were both about 15 seconds
each (and were done during the 2.15->2.16 migration, not the 2.16->3.1
upgrade).
The only other part of our upgrade that took a noticeable time was the
java -Xmx12g -jar bin/gerrit-2.16.18.war migrate-to-note-db -d $(pwd)
step. That took around 40 minutes, a good portion of which was
dumping lots of really scary-looking backtraces (which appear to have
been from ancient corruption that affected defunct projects; saw the
same thing during the test migration and spot checked many of the
errors to confirm that they were corruption issues that we knew about
previously, and then also did extra testing in staging to verify that
the repo we cared about was not adversely affected).
> This is a change that we’ve had in our fork for 6+ years now that significantly reduces the impact of additional refs: https://git.eclipse.org/r/24295
though both Matthias and Jonathan have restored it to make sure it
didn't get forgotten. Don't think I want to attempt to forward port
it, but I'm curious to see where it goes.
> Elijah, how many changes total do you have on your server and in this big project specifically?
number is currently 340711, which is probably a pretty good
approximation. (We have had projects deleted in the past, we've had
outages with some corruption in the early Gerrit 2.x days long ago,
etc.)
As for this particular project of interest, I'm guessing I can just
count by the NoteDB meta refs:
$ cd PATH/TO/big-repo.git
$ git show-ref | grep meta | wc -l
136202
Far less than what I hear chromium and other projects have. We have
another project which was sunset a few years back that has more CRs
than this (but still had a smaller repo size), but just barely (~142K
CRs).
Luca Milanesio
May 19, 2020, 5:05:47 PM5/19/20
to Nasser Grainawi, Luca Milanesio, Elijah Newren, repo-discuss
There is one currently open:
with a change proposed by Ponch to fix it:
But there could be more that I am not aware of.

Matthias Sohn
May 19, 2020, 6:56:46 PM5/19/20
to Elijah Newren, Luca Milanesio, repo-discuss
Gerrit 3.1.4 when freshly installed configures this automatically for the group Non-Interactive Users:
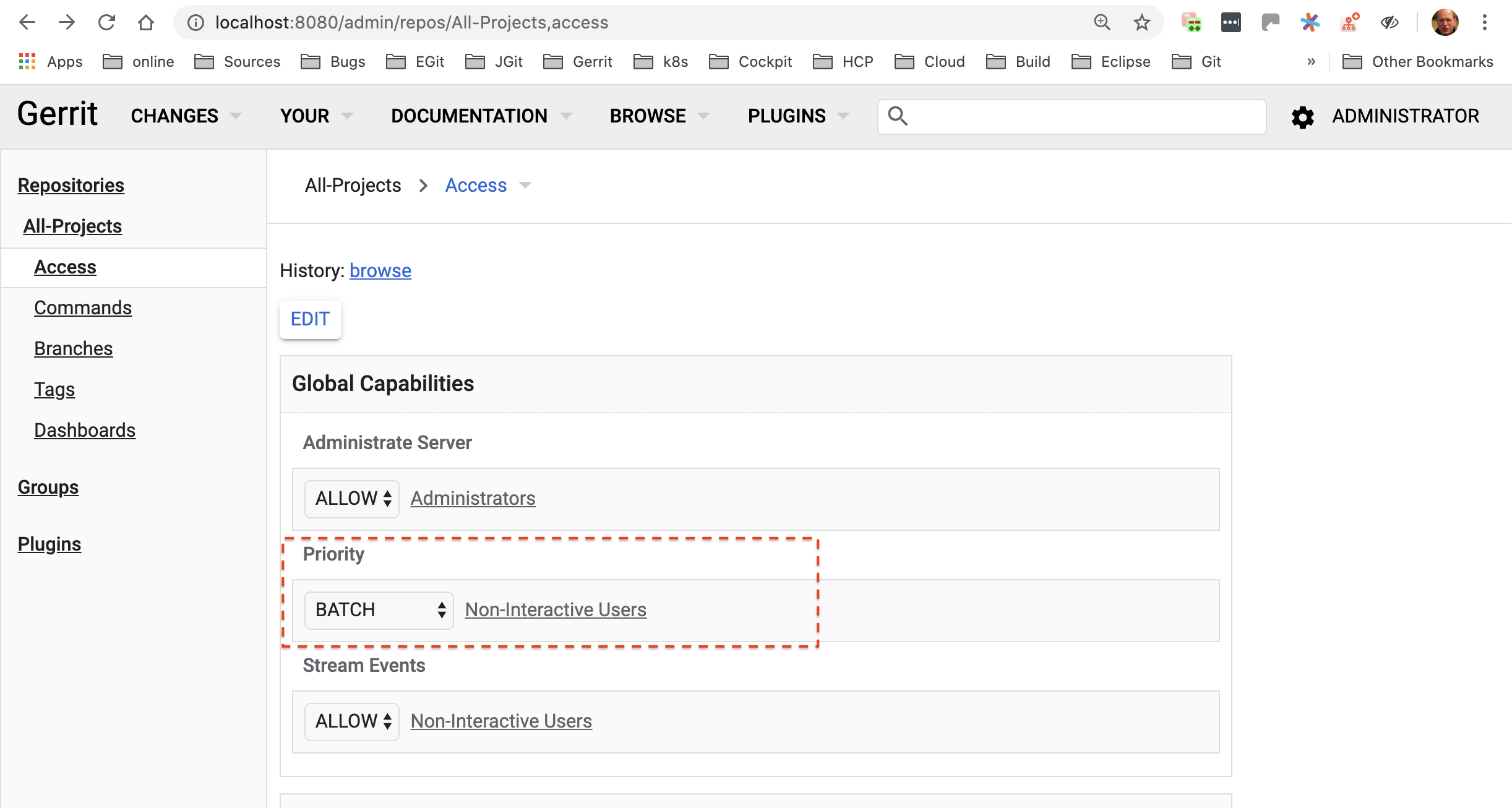
if you want to add this for another group click "edit" and add the group.
-Matthias
Matthias Sohn
May 19, 2020, 7:11:46 PM5/19/20
to Nasser Grainawi, Luca Milanesio, Elijah Newren, repo-discuss
On Tue, May 19, 2020 at 7:23 PM Nasser Grainawi <nas...@codeaurora.org> wrote:
On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
Also, the API behave differently when you are on ReviewDb compared to NoteDb.
It is therefore a migration and needs to be executed as such.
Fair enough; in fact, that was one of the two big hurdles in our
migration. (The other being that Gerrit-3.1 wanted the changes
reindexed offline before it'd start, which of course took forever.)If you do not skip steps, you’ll never have to perform offline reindexing anymore.On GerritHub it would take *days* to complete, not even sure it would succeed though.Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?
We do the bulk of reindexing on a copy of the productive server (we do a full backup using filesystem snapshot every weekend).
During the upgrade of the productive server we first copy the indexes from this staging server and only have to reindex the delta since
the copy was taken.
this monitoring setup is a game changer for us, since we implemented it we see what happens
when we upgrade to a newer version or change configuration
Thanks, that's good info to be aware of. Since the Gerrit release
notes suggest Java 11 isn't officially supported until Gerrit-3.2,
we'll have to wait off on that.
It is *unofficially* supported though from v2.16 onwards, as DavidO merged a lot of patches to allow that.
I saw that too, but wanted to stick with officially supported configurations.Java 8 can work quite well with larger heaps and I think there are many users/admins of Gerrit that have large heaps with Java 8. For example, our largest Gerrit server has 256GB of physical memory and we typically size the heap to use 75% of it. Our gerrit javaOptions look roughly like:javaOptions = "\-server -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails \-Xloggc:/path/to/jvm.log \-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=14 \-XX:GCLogFileSize=1024M \-Xms193378m -Xmn63814m \-XX:+UseParallelOldGC -XX:ParallelGCThreads=24 \-XX:MetaspaceSize=128m \-XX:+UseNUMA -XX:+UseBiasedLocking \-XX:+AggressiveOpts”
we use heap of 256GB on machines with 1TB physical memory with the following java options
javaOptions = "-Dflogger.backend_factory=com.google.common.flogger.backend.log4j.Log4jBackendFactory#getInstance"
javaOptions = "-Dflogger.logging_context=com.google.gerrit.server.logging.LoggingContext#getInstance"
javaOptions = -Djavax.net.ssl.trustStore=$gerrit_site/etc/keystore
javaOptions = -XX:+GCHistory
javaOptions = -XX:+PrintAdaptiveSizePolicy
javaOptions = -XX:+PrintGCApplicationStoppedTime
javaOptions = -XX:+PrintGCDateStamps
javaOptions = -XX:+PrintGCDetails
javaOptions = -XX:+PrintReferenceGC
javaOptions = -XX:+PrintTenuringDistribution
javaOptions = -XX:+UnlockDiagnosticVMOptions
javaOptions = -XX:+UseG1GC
javaOptions = -XX:+UseGCLogFileRotation
javaOptions = -XX:GCLogFileSize=40M
javaOptions = -XX:MaxGCPauseMillis=5000
javaOptions = -XX:NumberOfGCLogFiles=20
javaOptions = -Xloggc:$gerrit_site/logs/javagc.log
javaOptions = -Xms256g
javaOptions = -Xmx256g
To view this discussion on the web visit https://groups.google.com/d/msgid/repo-discuss/D95D4858-5D52-498A-8C2E-0FD5EE239193%40codeaurora.org.

Raviraj Karasulli
May 20, 2020, 1:48:32 AM5/20/20
to Repo and Gerrit Discussion
We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.
After increasing -XX:ParallelGCThreads we did not see it again.
We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.
Parellel GC threads value of 16 seems to be working fine for 188 G.
Just curious to know what is the number of GC threads on the host Mathias is using :)
To unsubscribe, email repo-discuss+unsub...@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-d...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/repo-discuss/12CA23E5-A438-4153-875E-8C6F75F48F37%40gmail.com.
--
--
To unsubscribe, email repo-d...@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-d...@googlegroups.com.
Luca Milanesio
May 20, 2020, 5:04:09 AM5/20/20
to Raviraj Karasulli, Luca Milanesio, Repo and Gerrit Discussion
On 20 May 2020, at 06:48, Raviraj Karasulli <ravirajk...@gmail.com> wrote:We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.After increasing -XX:ParallelGCThreads we did not see it again.We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.Parellel GC threads value of 16 seems to be working fine for 188 G.Just curious to know what is the number of GC threads on the host Mathias is using :)
Matthias is also using a custom-built JVM made by SAP :-)
Anyway, Java 8 can still trigger a SOW GC with large heaps, and that may even last tens of minutes for a “hundreds-Gigs” heap.
We definitely need Java 11 to have a GC that is optimised for large heaps.
HTH
Luca.
To unsubscribe, email repo-discuss...@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-discuss...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/repo-discuss/557bff7c-ba88-4933-ad57-86cea60fcf96%40googlegroups.com.
Luca Milanesio
May 20, 2020, 5:32:25 AM5/20/20
to Raviraj Karasulli, Luca Milanesio, Repo and Gerrit Discussion
On 20 May 2020, at 10:03, Luca Milanesio <luca.mi...@gmail.com> wrote:On 20 May 2020, at 06:48, Raviraj Karasulli <ravirajk...@gmail.com> wrote:We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.After increasing -XX:ParallelGCThreads we did not see it again.We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.Parellel GC threads value of 16 seems to be working fine for 188 G.Just curious to know what is the number of GC threads on the host Mathias is using :)Matthias is also using a custom-built JVM made by SAP :-)Anyway, Java 8 can still trigger a SOW GC
Typo: I meant “STW” (Stop-The-World) GC, where all threads are blocked and the whole JVM is suspended.
Having a 15 mins STW GC means effectively an outage.
Luca.

David Ostrovsky
May 20, 2020, 5:58:06 AM5/20/20
to Repo and Gerrit Discussion
Am Mittwoch, 20. Mai 2020 11:04:09 UTC+2 schrieb lucamilanesio:
On 20 May 2020, at 06:48, Raviraj Karasulli <ravirajk...@gmail.com> wrote:We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.After increasing -XX:ParallelGCThreads we did not see it again.We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.Parellel GC threads value of 16 seems to be working fine for 188 G.Just curious to know what is the number of GC threads on the host Mathias is using :)Matthias is also using a custom-built JVM made by SAP :-)Anyway, Java 8 can still trigger a SOW GC with large heaps, and that may even last tens of minutes for a “hundreds-Gigs” heap.We definitely need Java 11 to have a GC that is optimised for large heaps.
Gerrit 3.2 removed dependency on unused Guice AOP feature,
and thus is able to run on any new JDK version. I would look into
new and shiny Z garbage collector: [1] that has seen substantial
improvements in latest JDK releases and is scheduled to be production
ready in upcoming JDK 15 release: [2]. It supports up to 16 TB heap
size, that should be sufficient for medium to big gerrit sites ;-)
But even today I would be interested to hear feedback of running
Gerrit 3.2 on JDK14 with ZGC enabled on say 1 TB heap size.
Matthias, can you give it a try? I guess only few gerrit sites in the
wild have a staging machine of this size?
Nasser Grainawi
May 20, 2020, 3:00:23 PM5/20/20
to Matthias Sohn, Luca Milanesio, Elijah Newren, repo-discuss
On May 19, 2020, at 5:11 PM, Matthias Sohn <matthi...@gmail.com> wrote:On Tue, May 19, 2020 at 7:23 PM Nasser Grainawi <nas...@codeaurora.org> wrote:On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
Also, the API behave differently when you are on ReviewDb compared to NoteDb.
It is therefore a migration and needs to be executed as such.
Fair enough; in fact, that was one of the two big hurdles in our
migration. (The other being that Gerrit-3.1 wanted the changes
reindexed offline before it'd start, which of course took forever.)If you do not skip steps, you’ll never have to perform offline reindexing anymore.On GerritHub it would take *days* to complete, not even sure it would succeed though.Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?We do the bulk of reindexing on a copy of the productive server (we do a full backup using filesystem snapshot every weekend).During the upgrade of the productive server we first copy the indexes from this staging server and only have to reindex the delta sincethe copy was taken.
That’s good to know. I think I heard that at the hackathon too. Does that work for any upgrade? Can some details of how you do that be added to the Gerrit docs somewhere?
To view this discussion on the web visit https://groups.google.com/d/msgid/repo-discuss/CAKSZd3TcOU-4QQjJ54h7LZy0qbFoZAmTxEoyJ5oQ6wuXjdj%2BwQ%40mail.gmail.com.
Elijah Newren
May 20, 2020, 3:11:57 PM5/20/20
to Matthias Sohn, Nasser Grainawi, Luca Milanesio, repo-discuss
On Tue, May 19, 2020 at 4:11 PM Matthias Sohn <matthi...@gmail.com> wrote:
>
> On Tue, May 19, 2020 at 7:23 PM Nasser Grainawi <nas...@codeaurora.org> wrote:
>>
>>
>> On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:
>>
>>
>>
>> On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:
>>
>> On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
>>
>>
>> On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
>>
>> Hi Luca,
>>
>> Wow, thanks for the quick response and many pointers.
>>
>> On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
>>
>>
>>
>> v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
>>
>> The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
>> Also, the API behave differently when you are on ReviewDb compared to NoteDb.
>>
>> It is therefore a migration and needs to be executed as such.
>>
>>
>> Fair enough; in fact, that was one of the two big hurdles in our
>> migration. (The other being that Gerrit-3.1 wanted the changes
>> reindexed offline before it'd start, which of course took forever.)
>>
>>
>> If you do not skip steps, you’ll never have to perform offline reindexing anymore.
>> On GerritHub it would take *days* to complete, not even sure it would succeed though.
>>
>>
>> Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?
>
>
> We do the bulk of reindexing on a copy of the productive server (we do a full backup using filesystem snapshot every weekend).
> During the upgrade of the productive server we first copy the indexes from this staging server and only have to reindex the delta since
> the copy was taken.
So that is possible? I attempted to do that during one of my practice
>
> On Tue, May 19, 2020 at 7:23 PM Nasser Grainawi <nas...@codeaurora.org> wrote:
>>
>>
>> On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:
>>
>>
>>
>> On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:
>>
>> On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
>>
>>
>> On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
>>
>> Hi Luca,
>>
>> Wow, thanks for the quick response and many pointers.
>>
>> On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
>>
>>
>>
>> v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
>>
>> The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
>> Also, the API behave differently when you are on ReviewDb compared to NoteDb.
>>
>> It is therefore a migration and needs to be executed as such.
>>
>>
>> Fair enough; in fact, that was one of the two big hurdles in our
>> migration. (The other being that Gerrit-3.1 wanted the changes
>> reindexed offline before it'd start, which of course took forever.)
>>
>>
>> If you do not skip steps, you’ll never have to perform offline reindexing anymore.
>> On GerritHub it would take *days* to complete, not even sure it would succeed though.
>>
>>
>> Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?
>
>
> We do the bulk of reindexing on a copy of the productive server (we do a full backup using filesystem snapshot every weekend).
> During the upgrade of the productive server we first copy the indexes from this staging server and only have to reindex the delta since
> the copy was taken.
migrations, where I first did an offline reindex on a copy of the data
that was a few days old, then copied
$INSTALLATION_DIR/index/changes_0057/ from there. Then I got a copy
of the production server with newer data, copied the
$INSTALLATION_DIR/index/changes_0057/ into place assuming that would
make the reindex be really fast because most the data is available,
and then the reindex still took half a day making me believe it just
ignored the previous indexing I had tried to copy into place. What
are the other steps needed to pull this off?
Matthias Sohn
May 20, 2020, 5:39:06 PM5/20/20
to Luca Milanesio, Raviraj Karasulli, Repo and Gerrit Discussion
On Wed, May 20, 2020 at 11:04 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 20 May 2020, at 06:48, Raviraj Karasulli <ravirajk...@gmail.com> wrote:We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.After increasing -XX:ParallelGCThreads we did not see it again.We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.Parellel GC threads value of 16 seems to be working fine for 188 G.Just curious to know what is the number of GC threads on the host Mathias is using :)Matthias is also using a custom-built JVM made by SAP :-)
you are right, we use sapjvm 8.1 [1] which is basically the hotspot 10 JVM with JDK 8 class library
plus extensive diagnostics (monitoring, tracing, developer tooling). I especially like debugging on demand which
means you can switch on the debugger without restarting the JVM. Due to its license it is only available in SAP internally
and for SAP customers. I guess when we upgrade soon to 3.1 we will switch to sapmachine 11 which is open source [2].
Anyway, Java 8 can still trigger a SOW GC with large heaps, and that may even last tens of minutes for a “hundreds-Gigs” heap.We definitely need Java 11 to have a GC that is optimised for large heaps.
out of curiosity I checked the gc logs of one of our servers for the last 2.5 days and found the longest full gc took 16.5 sec
not tens of minutes. Find more details in the corresponding gc report attached at the bottom of this email.
We don't configure the number of parallel threads used by G1GC so it uses the default (5/8 of available CPUs,
this would be 100, I observed 103).
In average we spend around 5% CPU on Java gc (see the gc diagram at the bottom right):
We did some more detailed tracing on a test system while we ran load tests cloning a huge repository concurrently from multiple clients
and found that uncompression done frequently when reading git objects from packfiles imposes additional constraints on
what Java gc can do. The reason is that the uncompression is implemented in native code (e.g. [3]) which involves
critical sections (e.g. [4]) which impose restrictions on what Java gc can do at the same time.
Under high load we observed that quite frequently the Java gc drops the jgit buffer cache when heap usage comes close to the maximum
heap size. This means the JVM reclaims the memory which was occupied by the jgit buffer cache but jgit will immediately
rebuild the cache content which again creates new garbage which soon needs to be cleaned up by Java gc adding additional pressure on
Java gc. We first tried to increase -XX:SoftRefLRUPolicyMSPerMB to 20000 which helped a bit but still Java gc interfered with jgit's usage
of soft references. Therefore I added an option in jgit [5] to use strong references instead of soft references for the buffer cache. We are using this
since a couple of weeks and observe more stable usage of the JGit buffer cache and less pressure on Java gc.
HTHLuca.
To unsubscribe, email repo-discuss...@googlegroups.com
To view this discussion on the web visit https://groups.google.com/d/msgid/repo-discuss/B9F96CEC-7115-4827-8FC6-70572FAFE0BE%40gmail.com.
Matthias Sohn
May 20, 2020, 5:48:13 PM5/20/20
to Nasser Grainawi, Luca Milanesio, Elijah Newren, repo-discuss
On Wed, May 20, 2020 at 9:00 PM Nasser Grainawi <nas...@codeaurora.org> wrote:
On May 19, 2020, at 5:11 PM, Matthias Sohn <matthi...@gmail.com> wrote:On Tue, May 19, 2020 at 7:23 PM Nasser Grainawi <nas...@codeaurora.org> wrote:On May 19, 2020, at 10:54 AM, Luca Milanesio <luca.mi...@gmail.com> wrote:On 19 May 2020, at 17:41, Elijah Newren <new...@gmail.com> wrote:On Tue, May 19, 2020 at 2:06 AM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 19 May 2020, at 01:54, Elijah Newren <new...@gmail.com> wrote:
Hi Luca,
Wow, thanks for the quick response and many pointers.
On Mon, May 18, 2020 at 3:08 PM Luca Milanesio <luca.mi...@gmail.com> wrote:v2.16 ReviewDb => v2.16 NoteDb is a *major migration* in my experience.
The Gerrit. v2.16 contains basically *two* code-bases: the ReviewDb persistence and the NoteDb persistence.
Also, the API behave differently when you are on ReviewDb compared to NoteDb.
It is therefore a migration and needs to be executed as such.
Fair enough; in fact, that was one of the two big hurdles in our
migration. (The other being that Gerrit-3.1 wanted the changes
reindexed offline before it'd start, which of course took forever.)If you do not skip steps, you’ll never have to perform offline reindexing anymore.On GerritHub it would take *days* to complete, not even sure it would succeed though.Coming from someone who plans to use offline reindexing, “not even sure it would succeed” is a concerning statement. Are there open bugs to track that?We do the bulk of reindexing on a copy of the productive server (we do a full backup using filesystem snapshot every weekend).During the upgrade of the productive server we first copy the indexes from this staging server and only have to reindex the delta sincethe copy was taken.That’s good to know. I think I heard that at the hackathon too. Does that work for any upgrade? Can some details of how you do that be added to the Gerrit docs somewhere?
I can try to find time to write this down.
Sasa tested if we can use the same approach for notedb migration in 2.16 (we currently use 2.16 still with reviewDB)
and found that this works. At the size of our sites offline notedb migration takes north of a week, online migration would
probably take months. Sasa wrote a test script to test if we can do the notedb migration on a copy and replicate back
the git notes it creates to the running production server (which would ignore these notes since it's still using reviewdb.
Our plan is to use this approach to reduce the impact of the notedb migration on the production system.
Matthias Sohn
May 20, 2020, 5:56:28 PM5/20/20
to Elijah Newren, Nasser Grainawi, Luca Milanesio, repo-discuss
we did this several times already and could reduce reindexing time for the productive system from a week to a few hours
since the bulk of reindexing is done on the copy and only the delta between the time when the copy is created until
the time when the productive system is upgraded (around a week worth of changes) needs to be reindexed on the productive server.
AFAIR you need to ensure that the diff summary cache is large enough to cache the summary of all changes on the server
otherwise reindexing has to recompute these summaries for all changes that are not in the cache.
Luca Milanesio
May 20, 2020, 5:57:53 PM5/20/20
to Matthias Sohn, Luca Milanesio, Raviraj Karasulli, Repo and Gerrit Discussion
On 20 May 2020, at 22:38, Matthias Sohn <matthi...@gmail.com> wrote:On Wed, May 20, 2020 at 11:04 AM Luca Milanesio <luca.mi...@gmail.com> wrote:On 20 May 2020, at 06:48, Raviraj Karasulli <ravirajk...@gmail.com> wrote:We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.After increasing -XX:ParallelGCThreads we did not see it again.We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.Parellel GC threads value of 16 seems to be working fine for 188 G.Just curious to know what is the number of GC threads on the host Mathias is using :)Matthias is also using a custom-built JVM made by SAP :-)you are right, we use sapjvm 8.1 [1] which is basically the hotspot 10 JVM with JDK 8 class libraryplus extensive diagnostics (monitoring, tracing, developer tooling). I especially like debugging on demand whichmeans you can switch on the debugger without restarting the JVM. Due to its license it is only available in SAP internallyand for SAP customers. I guess when we upgrade soon to 3.1 we will switch to sapmachine 11 which is open source [2].Anyway, Java 8 can still trigger a SOW GC with large heaps, and that may even last tens of minutes for a “hundreds-Gigs” heap.We definitely need Java 11 to have a GC that is optimised for large heaps.out of curiosity I checked the gc logs of one of our servers for the last 2.5 days and found the longest full gc took 16.5 secnot tens of minutes.
But your machine is a *monster-machine* also :-) I saw 160 CPUs, is that right?
P.S. Our healthcheck has a timeout of 10s in production, that means that also with a monster-machine like yours, the node would still be declared unhealthy because it won’t be responding for over 10s.
Find more details in the corresponding gc report attached at the bottom of this email.We don't configure the number of parallel threads used by G1GC so it uses the default (5/8 of available CPUs,this would be 100, I observed 103).In average we spend around 5% CPU on Java gc (see the gc diagram at the bottom right):
<Screenshot 2020-05-20 at 22.43.59.png>
We did some more detailed tracing on a test system while we ran load tests cloning a huge repository concurrently from multiple clientsand found that uncompression done frequently when reading git objects from packfiles imposes additional constraints onwhat Java gc can do. The reason is that the uncompression is implemented in native code (e.g. [3]) which involvescritical sections (e.g. [4]) which impose restrictions on what Java gc can do at the same time.Under high load we observed that quite frequently the Java gc drops the jgit buffer cache when heap usage comes close to the maximumheap size. This means the JVM reclaims the memory which was occupied by the jgit buffer cache but jgit will immediatelyrebuild the cache content which again creates new garbage which soon needs to be cleaned up by Java gc adding additional pressure onJava gc.
I also observed that behaviour in situations where we put the JVM heap under huge pressure, in conjunction with large heap and super-beefy mono-repos.
We first tried to increase -XX:SoftRefLRUPolicyMSPerMB to 20000 which helped a bit but still Java gc interfered with jgit's usageof soft references. Therefore I added an option in jgit [5] to use strong references instead of soft references for the buffer cache.
Yeah, I saw that coming through. It is definitely something to try out.
We are using thissince a couple of weeks and observe more stable usage of the JGit buffer cache and less pressure on Java gc.
That looks really promising, thanks for sharing your experience with it.
We will also roll out this week Gerrit v3.2.0 with Java11 on GerritHub.io (2 out of 4 sites), so that we can compare the differences in the management of large heaps.
Luca.
<Mail Attachment>
Matthias Sohn
May 20, 2020, 6:35:51 PM5/20/20
to Luca Milanesio, Raviraj Karasulli, Repo and Gerrit Discussion
On Wed, May 20, 2020 at 11:57 PM Luca Milanesio <luca.mi...@gmail.com> wrote:
On 20 May 2020, at 22:38, Matthias Sohn <matthi...@gmail.com> wrote:On Wed, May 20, 2020 at 11:04 AM Luca Milanesio <luca.mi...@gmail.com> wrote:On 20 May 2020, at 06:48, Raviraj Karasulli <ravirajk...@gmail.com> wrote:We also had an issue of Gerrit going into an 'end of the world' state when we increased the heap settings.After increasing -XX:ParallelGCThreads we did not see it again.We were using 74 G heap on a 128 G RAM and later increased to 188 G on 356 G RAM.Parellel GC threads value of 16 seems to be working fine for 188 G.Just curious to know what is the number of GC threads on the host Mathias is using :)Matthias is also using a custom-built JVM made by SAP :-)you are right, we use sapjvm 8.1 [1] which is basically the hotspot 10 JVM with JDK 8 class libraryplus extensive diagnostics (monitoring, tracing, developer tooling). I especially like debugging on demand whichmeans you can switch on the debugger without restarting the JVM. Due to its license it is only available in SAP internallyand for SAP customers. I guess when we upgrade soon to 3.1 we will switch to sapmachine 11 which is open source [2].Anyway, Java 8 can still trigger a SOW GC with large heaps, and that may even last tens of minutes for a “hundreds-Gigs” heap.We definitely need Java 11 to have a GC that is optimised for large heaps.out of curiosity I checked the gc logs of one of our servers for the last 2.5 days and found the longest full gc took 16.5 secnot tens of minutes.But your machine is a *monster-machine* also :-) I saw 160 CPUs, is that right?
yep, I agree it's a big one, though you didn't see the build server machines fetching changes from this server, they are even larger ;-)
We combine multiple Gerrit instances on each machine and isolate them from each other using Linux cgroups.
We have 2 test instances per productive instance (one for testing fixes and config changes, one for testing upgrades),
these test instances are installed on the same server but with smaller configuration (smaller heap etc.).
Normally one productive instance resides on the same machine with two test instances (which typically carry
little load most of the time). Only in case of a fail-over we may end up with two productive instances on one machine
which could overload this machine until the other one recovered from whatever failure it suffered from.
We are working on a kubernetes based setup to replace a few over-sized machines by a fleet of containers
running in the cloud which can more flexibly adapt to the current load and don't need to be (over-) sized to
survive peak load. There is still some way to go. We will start soon by first using kubernetes based slaves
replacing the docker based ones we are using today. We plan to implement auto-scaling so that slaves grow
and shrink depending on current load.
P.S. Our healthcheck has a timeout of 10s in production, that means that also with a monster-machine like yours, the node would still be declared unhealthy because it won’t be responding for over 10s.Find more details in the corresponding gc report attached at the bottom of this email.We don't configure the number of parallel threads used by G1GC so it uses the default (5/8 of available CPUs,this would be 100, I observed 103).In average we spend around 5% CPU on Java gc (see the gc diagram at the bottom right):<Screenshot 2020-05-20 at 22.43.59.png>If you look at the left side of the graph, I can see some “black bars” which indicates that Prometheus did not receive any data from the host: that is typically a symptom of a STW GC cycle.
Our monitoring stack runs on kubernetes in a different datacenter and sometimes there are network glitches.
We use a single monitoring installation for all of our Gerrit instances.
Elijah Newren
May 21, 2020, 12:08:24 AM5/21/20
to Luca Milanesio, repo-discuss
A correction...
On Tue, May 19, 2020 at 9:41 AM Elijah Newren <new...@gmail.com> wrote:
> Just after git-2.26.0 was released (which flipped the v2 protocol to
> the default), Linux kernel folks reported that fetches expected to
> download small updates were instead forced to download gigabytes. The
> protocol v2 as default was even reverted; there are fixes for the v2
> protocol bugs and the protocol v2 as default was restored (in git
> master), but the fact that there were a bunch of reports just after v2
> was switched to the default made me worried there might be more issues
> lurking.
<snip>
Sorry, I misunderstood previously. Protocol v2's demotion from the
default has not been undone and the release notes will likely
prominently mention the demotion in the upcoming Git 2.27 release:
https://lore.kernel.org/git/xmqq5zcqu...@gitster.c.googlers.com/
On Tue, May 19, 2020 at 9:41 AM Elijah Newren <new...@gmail.com> wrote:
> Just after git-2.26.0 was released (which flipped the v2 protocol to
> the default), Linux kernel folks reported that fetches expected to
> download small updates were instead forced to download gigabytes. The
> protocol v2 as default was even reverted; there are fixes for the v2
> protocol bugs and the protocol v2 as default was restored (in git
> master), but the fact that there were a bunch of reports just after v2
> was switched to the default made me worried there might be more issues
> lurking.
Sorry, I misunderstood previously. Protocol v2's demotion from the
default has not been undone and the release notes will likely
prominently mention the demotion in the upcoming Git 2.27 release:
https://lore.kernel.org/git/xmqq5zcqu...@gitster.c.googlers.com/
Reply all
Reply to author
Forward
0 new messages