Spike in CPU/RAM on mirrored node, RabbitMQ 3.8.2, Erlang 22.1.8
511 views
Skip to first unread message

Amin
Dec 12, 2019, 4:28:58 AM12/12/19
to rabbitmq-users
Hi Guys,
I'm hoping that you could point us in the right direction for an issue that we are currently facing.At the moment, in our Live platform, we are running a 2 node cluster on the following versions:rabbitmq-server: 3.7.9-1.el7
Erlang: 21.0-1.el7
CentOS Linux release 7.6.1810 (Core)We are aware that this is incorrect (odd nodes...), so we are currently setting up a new cluster in our QA environment for testing:rabbitmq-server: 3.8.2-1.el7
erlang: 22.1.8-1.el7
CentOS Linux release 7.7.1908 (Core), Disk Space 36GB, RAM 16GB
Erlang: 21.0-1.el7
CentOS Linux release 7.6.1810 (Core)We are aware that this is incorrect (odd nodes...), so we are currently setting up a new cluster in our QA environment for testing:rabbitmq-server: 3.8.2-1.el7
erlang: 22.1.8-1.el7
CentOS Linux release 7.7.1908 (Core), Disk Space 36GB, RAM 16GB
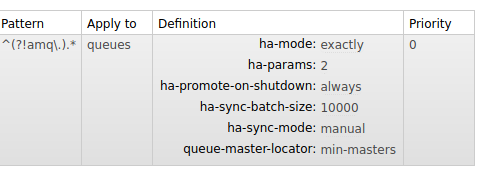
HA Policy
Out put from rabbitmqctl environment
[{amqp_client,[{prefer_ipv6,false},{ssl_options,[]}]},
{asn1,[]},
{aten,
[{detection_threshold,0.99},
{heartbeat_interval,100},
{poll_interval,1000}]},
{compiler,[]},
{cowboy,[]},
{cowlib,[]},
{credentials_obfuscation,
[{enabled,true},{ets_table_name,credentials_obfuscation}]},
{crypto,[{fips_mode,false},{rand_cache_size,896}]},
{gen_batch_server,[]},
{goldrush,[]},
{inets,[]},
{jsx,[]},
{kernel,
[{inet_default_connect_options,[{nodelay,true}]},
{inet_default_listen_options,[{nodelay,true}]},
{inet_dist_listen_max,25672},
{inet_dist_listen_min,25672},
{logger,
[{handler,default,logger_std_h,
#{config => #{type => standard_io},
formatter =>
{logger_formatter,
#{legacy_header => true,single_line => false}}}}]},
{logger_level,notice},
{logger_sasl_compatible,false}]},
{lager,
[{async_threshold,20},
{async_threshold_window,5},
{colored,false},
{colors,
[{debug,"\e[0;38m"},
{info,"\e[1;37m"},
{notice,"\e[1;36m"},
{warning,"\e[1;33m"},
{error,"\e[1;31m"},
{critical,"\e[1;35m"},
{alert,"\e[1;44m"},
{emergency,"\e[1;41m"}]},
{crash_log,"log/crash.log"},
{crash_log_count,5},
{crash_log_date,"$D0"},
{crash_log_msg_size,65536},
{crash_log_rotator,lager_rotator_default},
{crash_log_size,10485760},
{error_logger_format_raw,true},
{error_logger_hwm,50},
{error_logger_hwm_original,50},
{error_logger_redirect,true},
{extra_sinks,
[{error_logger_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_channel_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_connection_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_ldap_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_mirroring_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_queue_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_ra_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_federation_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_shovel_lager_event,
[{handlers,[{lager_forwarder_backend,[lager_event,inherit]}]},
{rabbit_handlers,
[{lager_forwarder_backend,[lager_event,inherit]}]}]},
{rabbit_log_upgrade_lager_event,
[{handlers,
[{lager_file_backend,
[{date,[]},
{file,
"/var/log/rabbitmq/rabbit@rabbitmq02_upgrade.log"},
{formatter_config,
[date," ",time," ",color,"[",severity,"] ",
{pid,[]},
" ",message,"\n"]},
{level,info},
{size,0}]}]},
{rabbit_handlers,
[{lager_file_backend,
[{date,[]},
{file,
"/var/log/rabbitmq/rabbit@rabbitmq02_upgrade.log"},
{formatter_config,
[date," ",time," ",color,"[",severity,"] ",
{pid,[]},
" ",message,"\n"]},
{level,info},
{size,0}]}]}]}]},
{handlers,
[{lager_file_backend,
[{date,[]},
{file,"/var/log/rabbitmq/rab...@rabbitmq02.log"},
{formatter_config,
[date," ",time," ",color,"[",severity,"] ",
{pid,[]},
" ",message,"\n"]},
{level,info},
{size,0}]}]},
{log_root,"/var/log/rabbitmq"},
{rabbit_handlers,
[{lager_file_backend,
[{date,[]},
{file,"/var/log/rabbitmq/rab...@rabbitmq02.log"},
{formatter_config,
[date," ",time," ",color,"[",severity,"] ",
{pid,[]},
" ",message,"\n"]},
{level,info},
{size,0}]}]}]},
{mnesia,
[{dir,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq02"},
{schema_location,opt_disc}]},
{observer_cli,[{plugins,[]}]},
{os_mon,
[{start_cpu_sup,false},
{start_disksup,false},
{start_memsup,false},
{start_os_sup,false}]},
{public_key,[]},
{ra,[{data_dir,"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq02/quorum"},
{logger_module,rabbit_log_ra_shim},
{segment_max_entries,32768},
{wal_max_size_bytes,536870912}]},
{rabbit,
[{auth_backends,[rabbit_auth_backend_internal]},
{auth_mechanisms,['PLAIN','AMQPLAIN']},
{autocluster,
[{peer_discovery_backend,rabbit_peer_discovery_classic_config}]},
{background_gc_enabled,true},
{background_gc_target_interval,60000},
{backing_queue_module,rabbit_priority_queue},
{channel_max,2047},
{channel_operation_timeout,15000},
{channel_tick_interval,60000},
{cluster_keepalive_interval,10000},
{cluster_nodes,{[],disc}},
{cluster_partition_handling,ignore},
{collect_statistics,fine},
{collect_statistics_interval,5000},
{config_entry_decoder,[{passphrase,undefined}]},
{connection_max,infinity},
{credit_flow_default_credit,{400,200}},
{default_consumer_prefetch,{false,0}},
{default_permissions,[<<".*">>,<<".*">>,<<".*">>]},
{default_user,<<"guest">>},
{default_user_tags,[administrator]},
{default_vhost,<<"/">>},
{delegate_count,16},
{disk_free_limit,{mem_relative,1.0}},
{disk_monitor_failure_retries,10},
{disk_monitor_failure_retry_interval,120000},
{enabled_plugins_file,"/etc/rabbitmq/enabled_plugins"},
{feature_flags_file,
"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq02-feature_flags"},
{fhc_read_buffering,false},
{fhc_write_buffering,true},
{frame_max,131072},
{halt_on_upgrade_failure,true},
{handshake_timeout,10000},
{heartbeat,60},
{hipe_compile,false},
{hipe_modules,
[rabbit_reader,rabbit_channel,gen_server2,rabbit_exchange,
rabbit_command_assembler,rabbit_framing_amqp_0_9_1,rabbit_basic,
rabbit_event,lists,queue,priority_queue,rabbit_router,rabbit_trace,
rabbit_misc,rabbit_binary_parser,rabbit_exchange_type_direct,
rabbit_guid,rabbit_net,rabbit_amqqueue_process,
rabbit_variable_queue,rabbit_binary_generator,rabbit_writer,
delegate,gb_sets,lqueue,sets,orddict,rabbit_amqqueue,
rabbit_limiter,gb_trees,rabbit_queue_index,
rabbit_exchange_decorator,gen,dict,ordsets,file_handle_cache,
rabbit_msg_store,array,rabbit_msg_store_ets_index,rabbit_msg_file,
rabbit_exchange_type_fanout,rabbit_exchange_type_topic,mnesia,
mnesia_lib,rpc,mnesia_tm,qlc,sofs,proplists,credit_flow,pmon,
ssl_connection,tls_connection,ssl_record,tls_record,gen_fsm,ssl]},
{lager_default_file,"/var/log/rabbitmq/rab...@rabbitmq02.log"},
{lager_extra_sinks,
[rabbit_log_lager_event,rabbit_log_channel_lager_event,
rabbit_log_connection_lager_event,rabbit_log_ldap_lager_event,
rabbit_log_mirroring_lager_event,rabbit_log_queue_lager_event,
rabbit_log_ra_lager_event,rabbit_log_federation_lager_event,
rabbit_log_shovel_lager_event,rabbit_log_upgrade_lager_event]},
{lager_log_root,"/var/log/rabbitmq"},
{lager_upgrade_file,"/var/log/rabbitmq/rabbit@rabbitmq02_upgrade.log"},
{lazy_queue_explicit_gc_run_operation_threshold,1000},
{log,
[{file,[{file,"/var/log/rabbitmq/rab...@rabbitmq02.log"}]},
{categories,
[{upgrade,
[{file,
"/var/log/rabbitmq/rabbit@rabbitmq02_upgrade.log"}]}]}]},
{log_levels,[{connection,error},{queue,error}]},
{loopback_users,[<<"guest">>]},
{max_message_size,134217728},
{memory_monitor_interval,2500},
{mirroring_flow_control,true},
{mirroring_sync_batch_size,4096},
{mnesia_table_loading_retry_limit,10},
{mnesia_table_loading_retry_timeout,30000},
{msg_store_credit_disc_bound,{4000,800}},
{msg_store_file_size_limit,16777216},
{msg_store_index_module,rabbit_msg_store_ets_index},
{msg_store_io_batch_size,4096},
{num_ssl_acceptors,10},
{num_tcp_acceptors,10},
{password_hashing_module,rabbit_password_hashing_sha256},
{plugins_dir,
"/usr/lib/rabbitmq/plugins:/usr/lib/rabbitmq/lib/rabbitmq_server-3.8.2/plugins"},
{plugins_expand_dir,
"/var/lib/rabbitmq/mnesia/rabbit@rabbitmq02-plugins-expand"},
{proxy_protocol,false},
{queue_explicit_gc_run_operation_threshold,1000},
{queue_index_embed_msgs_below,4096},
{queue_index_max_journal_entries,32768},
{quorum_cluster_size,5},
{quorum_commands_soft_limit,256},
{reverse_dns_lookups,false},
{server_properties,[]},
{ssl_allow_poodle_attack,false},
{ssl_apps,[asn1,crypto,public_key,ssl]},
{ssl_cert_login_from,distinguished_name},
{ssl_handshake_timeout,5000},
{ssl_listeners,[]},
{ssl_options,[]},
{tcp_listen_options,
[binary,
{packet,raw},
{reuseaddr,true},
{backlog,128},
{nodelay,true},
{exit_on_close,false},
{keepalive,false},
{linger,{true,0}}]},
{tcp_listeners,[{"auto",5672}]},
{trace_vhosts,[]},
{vhost_restart_strategy,continue},
{vm_memory_calculation_strategy,rss},
{vm_memory_high_watermark,0.66},
{vm_memory_high_watermark_paging_ratio,0.5}]},
{rabbit_common,[]},
{rabbitmq_delayed_message_exchange,[]},
{rabbitmq_management,
[{content_security_policy,"default-src 'self'"},
{cors_allow_origins,[]},
{cors_max_age,1800},
{http_log_dir,none},
{listener,[{port,15672}]},
{load_definitions,none},
{management_db_cache_multiplier,5},
{process_stats_gc_timeout,300000},
{stats_event_max_backlog,250}]},
{rabbitmq_management_agent,
[{rates_mode,basic},
{sample_retention_policies,
[{global,[{605,5},{3660,60},{29400,600},{86400,1800}]},
{basic,[{605,5},{3600,60}]},
{detailed,[{605,5}]}]}]},
{rabbitmq_top,[]},
{rabbitmq_web_dispatch,[]},
{ranch,[]},
{recon,[]},
{sasl,[{errlog_type,error},{sasl_error_logger,false}]},
{ssl,[]},
{stdlib,[]},
{stdout_formatter,[]},
{syntax_tools,[]},
{sysmon_handler,
[{busy_dist_port,true},
{busy_port,false},
{gc_ms_limit,0},
{heap_word_limit,0},
{port_limit,100},
{process_limit,100},
{schedule_ms_limit,0}]},
{tools,[{file_util_search_methods,[{[],[]},{"ebin","esrc"},{"ebin","src"}]}]},
{xmerl,[]}]
Output of rabbitmq-diagnostics -q status at the time when the issue occured
Runtime
OS PID: 14337
OS: Linux
Uptime (seconds): 53002
RabbitMQ version: 3.8.2
Node name: rabbit@rabbitmq02
Erlang configuration: Erlang/OTP 22 [erts-10.5.6] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:64] [hipe]
Erlang processes: 1115 used, 1048576 limit
Scheduler run queue: 1
Cluster heartbeat timeout (net_ticktime): 60
Plugins
Enabled plugin file: /etc/rabbitmq/enabled_plugins
Enabled plugins:
* rabbitmq_top
* rabbitmq_management
* rabbitmq_management_agent
* rabbitmq_web_dispatch
* rabbitmq_delayed_message_exchange
* cowboy
* amqp_client
* cowlib
Data directory
Node data directory: /var/lib/rabbitmq/mnesia/rabbit@rabbitmq02
Config files
* /etc/rabbitmq/rabbitmq.config
Log file(s)
* /var/log/rabbitmq/rabbit@rabbitmq02.log
* /var/log/rabbitmq/rabbit@rabbitmq02_upgrade.log
Alarms
(none)
Memory
Calculation strategy: rss
Memory high watermark setting: 0.66 of available memory, computed to: 10.9936 gb
binary: 3.2632 gb (51.84 %)
queue_slave_procs: 2.7376 gb (43.49 %)
allocated_unused: 0.2098 gb (3.33 %)
code: 0.0256 gb (0.41 %)
other_proc: 0.0236 gb (0.38 %)
other_system: 0.014 gb (0.22 %)
plugins: 0.0086 gb (0.14 %)
other_ets: 0.0033 gb (0.05 %)
connection_channels: 0.0022 gb (0.03 %)
connection_other: 0.0016 gb (0.02 %)
atom: 0.0015 gb (0.02 %)
mgmt_db: 0.001 gb (0.02 %)
queue_procs: 0.0009 gb (0.01 %)
mnesia: 0.0006 gb (0.01 %)
metrics: 0.0004 gb (0.01 %)
connection_writers: 0.0002 gb (0.0 %)
connection_readers: 0.0002 gb (0.0 %)
quorum_ets: 0.0 gb (0.0 %)
msg_index: 0.0 gb (0.0 %)
quorum_queue_procs: 0.0 gb (0.0 %)
reserved_unallocated: 0.0 gb (0.0 %)
File Descriptors
Total: 27, limit: 65438
Sockets: 5, limit: 58892
Free Disk Space
Low free disk space watermark: 16.657 gb
Free disk space: 37.4225 gb
Totals
Connection count: 5
Queue count: 102
Virtual host count: 1
Listeners
Interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Interface: [::], port: 15672, protocol: http, purpose: HTTP API
The queue we testing against is declared lazy, we test with 1m messages which is total around 1GB as follow:

We have already enabled the background garabage collections as it can be seen and also added SERVER_ADDITIONAL_ERL_ARGS='+sbwt none' to /etc/rabbitmq/rabbitmq-env.conf as suggested elsewhere but didn't solve the issue.
Any help would be appreciate it very much. Thanks for your time in advance.

Karl Nilsson
Dec 12, 2019, 5:31:55 AM12/12/19
to rabbitm...@googlegroups.com
Hi,
So it looks like you had a sudden influx of messages which caused a backlog in the queue. This would have caused a RAM/CPU spike until your consumers can catch up.
Cheers
Karl
--
You received this message because you are subscribed to the Google Groups "rabbitmq-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/bd0c8c9b-8514-4ef3-8c7a-73672b0e3192%40googlegroups.com.
Karl Nilsson
Pivotal/RabbitMQ
justMe
Dec 12, 2019, 6:08:02 AM12/12/19
to rabbitmq-users
Hi Karl,
Thanks for the reply but this is only happening on the mirrored node, the leader (master node) doesn't have any issues, also when the messages all processed by the leader the mirrored node still running out of memory for about an hour later
From the mirrored node log
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-12-12 09:13:11.878 [info] <0.412.0> vm_memory_high_watermark clear. Memory used:10250829824 allowed:10993648680
2019-12-12 09:13:11.878 [warning] <0.410.0> memory resource limit alarm cleared on node rabbit@rabbitmq02
2019-12-12 09:13:11.878 [warning] <0.410.0> memory resource limit alarm cleared across the cluster
2019-12-12 09:13:20.890 [info] <0.412.0> vm_memory_high_watermark set. Memory used:11062611968 allowed:10993648680
2019-12-12 09:13:20.891 [warning] <0.410.0> memory resource limit alarm set on node rabbit@rabbitmq02.
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-12-12 09:13:31.903 [info] <0.412.0> vm_memory_high_watermark clear. Memory used:10982731776 allowed:10993648680
2019-12-12 09:13:31.903 [warning] <0.410.0> memory resource limit alarm cleared on node rabbit@rabbitmq02
2019-12-12 09:13:31.904 [warning] <0.410.0> memory resource limit alarm cleared across the cluster
2019-12-12 09:13:32.904 [info] <0.412.0> vm_memory_high_watermark set. Memory used:11029897216 allowed:10993648680
2019-12-12 09:13:32.905 [warning] <0.410.0> memory resource limit alarm set on node rabbit@rabbitmq02.
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
If we run on a single node then we don't have any issues (I would expected the same behaviour on a single node)
Also just for info we have not changed the test case, the test case we run on QA with the new environment we have run the exact same test on the old environment and this issues didn't occure.
I have also enabled top plugin on the mirroed node and it shows a process mirror_queue_slave using lots of RAM
Regards
Amin
Dec 16, 2019, 6:41:18 AM12/16/19
to rabbitmq-users
Just for more info the issue can be replicated using rabbitmq-perf-test tool with the following command:
rabbitmq-perf-test-2.9.1$ bin/runjava com.rabbitmq.perf.PerfTest -h amqp://user:password@localhost -x2 -y0 -u "throughput-1m-nc" --id "1m-no-consumer" -qa x-dead-letter-exchange=exchange-name,x-queue-mode=lazy,x-max-priority=9 -ad false -s 1000 -C 1800000 -f persistent --json-body --body-count 50000 -m 800000
The above will create 2 publisher to produce 2 transactions each with 800K messages total 1.8m messages, less than 2GB of data, this will cause the mirrored queue to go into a wired mode, RabbitMQ Top plug-in shows mirror_queue_slave using 6GB

Output of rabbitmq-diagnostics -q status on the mirroed node
Runtime
OS PID: 13183
OS: Linux
Uptime (seconds): 257977
RabbitMQ version: 3.8.2
Node name: rabbit@rabbitmq02
Erlang configuration: Erlang/OTP 22 [erts-10.5.6] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:64] [hipe]
Erlang processes: 1055 used, 1048576 limit
Scheduler run queue: 1
Cluster heartbeat timeout (net_ticktime): 60
Plugins
Enabled plugin file: /etc/rabbitmq/enabled_plugins
Enabled plugins:
* rabbitmq_top
* rabbitmq_management
* rabbitmq_management_agent
* rabbitmq_web_dispatch
* rabbitmq_delayed_message_exchange
* cowboy
* amqp_client
* cowlib
Data directory
Node data directory: /var/lib/rabbitmq/mnesia/rabbit@rabbitmq02
Config files
* /etc/rabbitmq/rabbitmq.config
Log file(s)
* /var/log/rabbitmq/rabbit@rabbitmq02.log
* /var/log/rabbitmq/rabbit@rabbitmq02_upgrade.log
Alarms
Memory alarm on node rabbit@rabbitmq02
Memory
Calculation strategy: rss
Memory high watermark setting: 0.66 of available memory, computed to: 10.9936 gb
queue_slave_procs: 6.4312 gb (51.58 %)
binary: 5.834 gb (46.79 %)
allocated_unused: 0.0916 gb (0.73 %)
plugins: 0.0274 gb (0.22 %)
code: 0.0256 gb (0.21 %)
other_proc: 0.0175 gb (0.14 %)
mgmt_db: 0.0149 gb (0.12 %)
other_system: 0.0138 gb (0.11 %)
queue_procs: 0.0046 gb (0.04 %)
other_ets: 0.0033 gb (0.03 %)
atom: 0.0015 gb (0.01 %)
connection_other: 0.0013 gb (0.01 %)
metrics: 0.0007 gb (0.01 %)
mnesia: 0.0006 gb (0.0 %)
connection_readers: 0.0003 gb (0.0 %)
connection_channels: 0.0002 gb (0.0 %)
connection_writers: 0.0001 gb (0.0 %)
quorum_ets: 0.0 gb (0.0 %)
msg_index: 0.0 gb (0.0 %)
quorum_queue_procs: 0.0 gb (0.0 %)
reserved_unallocated: 0.0 gb (0.0 %)
File Descriptors
Total: 30, limit: 65438
Sockets: 6, limit: 58892
Free Disk Space
Low free disk space watermark: 16.657 gb
Free disk space: 38.152 gb
Totals
Connection count: 6
Queue count: 103
Virtual host count: 1
Listeners
Interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Interface: [::], port: 15672, protocol: http, purpose: HTTP API
Regards
Luke Bakken
Dec 17, 2019, 11:16:32 AM12/17/19
to rabbitmq-users
Hi Amin,
Did you run this exact test using version 3.7.9? Did it exhibit the same behavior?
Some suggestions after our discussion on the public slack channel (rabbitmq.slack.com - https://rabbitmq.slack.com/archives/C1EDN83PA/p1576597656042200):
- Use three nodes (this is now the case)
- Re-run your test without using priority queues. Do you see the same behavior?
- Re-run your test using a quorum queue. There is no need to declare the queue to be lazy and remove all HA policy applied to it. Do you see the same behavior?
Luke
Amin
Dec 17, 2019, 12:40:33 PM12/17/19
to rabbitmq-users
Hi Luke,
Thanks for the information on here and on the slack channel.
Yes same exact test on 3.7.9 Erlang 21.0 results in the same issue.
3 nodes or 2 seems to be doesn't make any difference in this case but yes the resent tests all done on three nodes cluster
In regards with Re-run your test without using priority queues. Do you see the same behavior?
Yes I have tested based on your instructions on 3.7.9 and Erlang 21.0, 3 nodes cluster with the following command and the exact same result (Mirrored node spikes on memorry and memory alarm went off (watermark is on 0.66 out of 16GB of RAM))
bin/runjava com.rabbitmq.perf.PerfTest -h amqp://user:password@localhost -x2 -y0 -u "test-no-consumer" --id "test-no-consumer" -e test-exchange -qa x-dead-letter-exchange=test-exchange -ad false -s 1000 -C 1800000 -f persistent --json-body -m 800000The priority didn't make any difference in this case
The quorum queue test has to be done on 3.8.x I will report back once I have run the test
Regrads,
Amin
Dec 18, 2019, 3:38:39 AM12/18/19
to rabbitmq-users
Hi Luke,
I have now tested the quorum queue on RabbitMQ 3.8.2, Erlang 22.1.8 using the following steps:
1- Removed the HA policy
2- Removed Lazy argument
3- Changed the test command to look as follow:
bin/runjava com.rabbitmq.perf.PerfTest -h amqp://user:password@localhost -x2 -y0 -u "test-quorum" --id "test-no-consumer" -e test-exchange -qa x-dead-letter-exchange=test-exchange,x-queue-type=quorum -ad false -s 1000 -C 1800000 -f persistent --json-body -m 800000
Based on the above and the following result it seems to be the problem gone much worse
1- Not read about quorum that much yet but it seems to be uses much more memory that the classic queue, as soon as I run the test soon after the memory alarm gone on the leader node, also there were an error in the logs as follow:
2019-12-18 07:57:56.701 [warning] <0.345.0> segment_writer: failed to open segment file /var/lib/rabbitmq/mnesia/rabbit@rabbitmq02/quorum/rabbit@rabbitmq02/2F_TES0N37S1QOWRK8/00000001.segmenterror: enoent
2019-12-18 07:57:56.701 [warning] <0.345.0> segment_writer: skipping segment as directory /var/lib/rabbitmq/mnesia/rabbit@rabbitmq02/quorum/rabbit@rabbitmq02/2F_TES0N37S1QOWRK8 does not exist
2019-12-18 07:58:37.438 [warning] <0.373.0> memory resource limit alarm set on node rabbit@rabbitmq01.
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-12-18 07:58:43.470 [warning] <0.373.0> memory resource limit alarm cleared on node rabbit@rabbitmq01
2019-12-18 07:58:43.470 [warning] <0.373.0> memory resource limit alarm cleared across the cluster
2019-12-18 07:58:45.484 [warning] <0.373.0> memory resource limit alarm set on node rabbit@rabbitmq01.
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-12-18 07:58:48.556 [warning] <0.373.0> memory resource limit alarm cleared on node rabbit@rabbitmq01
2019-12-18 07:58:48.556 [warning] <0.373.0> memory resource limit alarm cleared across the cluster
And on node 3
2019-12-18 07:57:51.347 [warning] <0.1506.0>
segment_writer: failed to open segment file
/var/lib/rabbitmq/mnesia/rabbit@rabbitmq03/quorum/rabbit@rabbitmq03/2F_TES1MJ1PJHMMLPY/00000001.segmenterror:
enoent
2019-12-18 07:57:51.347 [warning] <0.1506.0>
segment_writer: skipping segment as directory
/var/lib/rabbitmq/mnesia/rabbit@rabbitmq03/quorum/rabbit@rabbitmq03/2F_TES1MJ1PJHMMLPY
does not exist
2019-12-18 07:58:37.439 [warning] <0.1528.0> memory resource limit alarm set on node rabbit@rabbitmq01.
**********************************************************
*** Publishers will be blocked until this alarm clears ***
**********************************************************
2019-12-18 07:58:43.473 [warning] <0.1528.0> memory resource limit alarm cleared on node rabbit@rabbitmq01
2019-12-18 07:58:43.473 [warning] <0.1528.0> memory resource limit alarm cleared across the cluster
2019-12-18 07:58:45.485 [warning] <0.1528.0> memory resource limit alarm set on node rabbit@rabbitmq01.The permissions on that directory
ls -ltr /var/lib/rabbitmq/mnesia/rabbit@rabbitmq02/quorum/rabbit@rabbitmq02/
total 786704
-rw-r----- 1 rabbitmq rabbitmq 5909 Dec 18 07:54 names.dets
-rw-r----- 1 rabbitmq rabbitmq 537192105 Dec 18 08:04 00000147.wal
-rw-r----- 1 rabbitmq rabbitmq 197792468 Dec 18 08:04 00000148.wal
-rw-r----- 1 rabbitmq rabbitmq 5929 Dec 18 08:04 meta.dets
drwxr-x--- 3 rabbitmq rabbitmq 4096 Dec 18 08:04 2F_TESLG3RWFWM07BH
2- The memory stays high on all three nodes even when the process seems to be finished
3- Might be just the way I run the tests but few times I tried and got exact same result (It seems it duplicates the request), I was expecting 1.6m in total but it will do that and then tries to run it again till it get double the amount of messages:
Regards,
Luke Bakken
Dec 19, 2019, 4:28:29 PM12/19/19
to rabbitmq-users
Hi Amin,
Don't use transactions for this use-case. In fact, you should never use transactions but instead use publisher confirms:
Here's how I tested in my environment (using the latest RabbitMQ code and Erlang 22.2) using publisher confirms:
* Create a three-node cluster, and a HA policy matching yours.
* Created a classic queue named test-queue that was declared lazy. Confirm that the queue is mirrored to one other node.
* Run PerfTest with these arguments:
--predeclared --queue test-queue --producers 2 --consumers 0 --id 1m-no-consumer --auto-delete false --size 1000 --pmessages 1800000 --flag persistent --json-body --body-count 50000 --confirm 64
Memory consumption remained constant throughout. The above arguments ensure that no more than 64 unconfirmed messages are in-flight. Once that number goes below 64, additional messages are published.
In a real-world application, you must safely preserve messages that have not yet been confirmed in the event that an exceptional event happens. This applies to the use of transactions, of course - you can't discard messages at your application until the transaction is confirmed, either.
Let me know if you have additional questions about publisher confirms.
Thanks,
Luke
Razh Amin
Dec 19, 2019, 5:10:30 PM12/19/19
to rabbitm...@googlegroups.com
Hi Luke,
Thanks for the reply and I appreciate your time, the client at the moment using transaction so it is all 800k or nothing, hence I was trying to replicate the issue using the tool. Can the the same be achieved using publisher confirm?
I will try your suggestions and let you know how it goes.
If publisher /confirm didn't do what we need can we do anything to make transaction better? As mentioned initially there is no issue on a single node it only happening in cluster environment and affects mirrored node, anything we could do to make inter communication better between the node?
Regards
--
You received this message because you are subscribed to the Google Groups "rabbitmq-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/0adef7a8-729e-4e22-87d1-2202d0e858b2%40googlegroups.com.
Luke Bakken
Dec 19, 2019, 9:09:42 PM12/19/19
to rabbitmq-users
Thanks for the reply and I appreciate your time, the client at the moment using transaction so it is all 800k or nothing, hence I was trying to replicate the issue using the tool. Can the the same be achieved using publisher confirm?
Yes. Publish messages using confirms. Once all 800K are published and confirmed, you know you are successful. Anything else, delete the queue and re-try. I'm assuming this is a one-shot bulk upload operation.
You must use publisher confirms correctly, which is why I provided a link to that Java tutorial. The concepts there apply to other languages as well.
If publisher /confirm didn't do what we need can we do anything to make transaction better? As mentioned initially there is no issue on a single node it only happening in cluster environment and affects mirrored node, anything we could do to make inter communication better between the node?
As far as I know, transactions aren't meant to be used with this many messages. If you must use transactions, you should try disabling the queue mirroring during the time when messages are being uploaded, and then re-enable mirroring (and synchronize) after the upload.
Finally, I do see the same memory issue locally when using transactions but do not have an explanation for it.
Thanks,
Luke
Amin
Dec 23, 2019, 6:02:39 AM12/23/19
to rabbitmq-users
Hi Luke,
Thanks for the reply again
Unfortunately I can't see the same behaviour as transactional when using
the publisher confirm, with transaction the messages doesn't got out
until all batch size committed, didn't see the same when I am trying the
following using the test tool
bin/runjava com.rabbitmq.perf.PerfTest -h amqp://user:password@localhost --predeclared --queue test-queue --producers 2 --consumers 2 --id throughput-no-consumer --auto-delete false --size 1000 --pmessages 1600000 --flag persistent --json-body --confirm 800000
On the other hand we can't delete the queue when exceptions occur, other things using the same queue
FYI The client is using spring AMQP and I have been told we need to have transaction (Either process all 800K or rollback)
In regards to:
- Transactions aren't meant to be used with this many messages
Is there a limitation on transaction? if so what is the max batch size recommend for transaction?
- Disabling the queue mirroring during the time when messages are being uploaded
How I could try this? can this be done using a policy?
- I do see the same memory issue locally when using transactions but do not have an explanation for it.
Anything I could do to some sort of debug etc to help understand the issue
Many thanks again
Regards,
Amin
Luke Bakken
Dec 23, 2019, 5:42:07 PM12/23/19
to rabbitmq-users
Hello - responses in-line:
Unfortunately I can't see the same behaviour as transactional when using the publisher confirm, with transaction the messages doesn't got out until all batch size committed, didn't see the same when I am trying the following using the test tool
Correct, publisher confirms do not work the same way as transactions. However, they do provide the same delivery guarantees.
On the other hand we can't delete the queue when exceptions occur, other things using the same queue
OK, that's good to know.
FYI The client is using spring AMQP and I have been told we need to have transaction (Either process all 800K or rollback)
Well, I don't think it's going to work in your case. That is simply too many large messages.
- Transactions aren't meant to be used with this many messagesIs there a limitation on transaction? if so what is the max batch size recommend for transaction?
I just tried with a batch size of 1000 messages and memory use appears to be alright. You should experiment with different batch sizes in your environment.
- Disabling the queue mirroring during the time when messages are being uploadedHow I could try this? can this be done using a policy?
Yes. Create a higher-priority policy that matches the queue you are using, and set ha-mode: exactly with 1 as the parameter. Then, when you're done, remove that policy.
- I do see the same memory issue locally when using transactions but do not have an explanation for it.Anything I could do to some sort of debug etc to help understand the issue
I asked the rest of the team and this issue is not common enough for us to work on it at this time. If other users report it, or a paying customer reports it, that will affect the priority.
Thanks,
Luke
Razh Amin
Dec 24, 2019, 7:46:25 AM12/24/19
to rabbitm...@googlegroups.com
Hi Luke,
Thanks for all your help, to me it feels like some sort of configurations not correct between the nodes as it works well without the mirror policy.
Unfortunately the issue still on going, If we found something to sort it I will report back here and please you do the same.
Many thanks again
Amin
--
You received this message because you are subscribed to the Google Groups "rabbitmq-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/a7487dc2-c64e-4172-9c00-aa3bf85130f4%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages