filtering json data from mysql
41 views
Skip to first unread message

John Mark Johnson
May 24, 2021, 10:22:54 PM5/24/21
to PsiTurk
Hi there,
I am completely new to all of this and I have managed to construct the experiment using psiturk/jspsych, set up my MySql database, and extract the json file of the datastring that is created for participants. However, I am trying to figure out how to filter (or parse?) all of the data created in the datastring from the experiment.
Here is an example of one of the trials created:
{
"id": "debugYINRXB:debug8L5CCL",
"data": [
"id": "debugYINRXB:debug8L5CCL",
"data": [
{
"dateTime": 1621722226854,
"uniqueid": "debugYINRXB:debug8L5CCL",
"trialdata": {
"rt": 323,
"task": "B_80",
"accuracy": true,
"response": "y",
"stimulus": "<p> Was a letter displayed?</p> <p>Press <b>'y'</b> for <b>yes</b>.</p> <p> Press <b>'n'</b> for <b>no</b></p>.",
"trial_type": "html-keyboard-response",
"trial_index": 41,
"time_elapsed": 36417,
"test_condition": "letter_detection",
"trial_duration": 80,
"target_stimulus": "B",
"correct_response": "Y",
"internal_node_id": "0.0-9.0-0.0-5.0"
},
"current_trial": 1
"dateTime": 1621722226854,
"uniqueid": "debugYINRXB:debug8L5CCL",
"trialdata": {
"rt": 323,
"task": "B_80",
"accuracy": true,
"response": "y",
"stimulus": "<p> Was a letter displayed?</p> <p>Press <b>'y'</b> for <b>yes</b>.</p> <p> Press <b>'n'</b> for <b>no</b></p>.",
"trial_type": "html-keyboard-response",
"trial_index": 41,
"time_elapsed": 36417,
"test_condition": "letter_detection",
"trial_duration": 80,
"target_stimulus": "B",
"correct_response": "Y",
"internal_node_id": "0.0-9.0-0.0-5.0"
},
"current_trial": 1
Can someone please show me how to write a short python script to parse or filter through the data so that it gives the uniqueId, accuracy, and current trial and the corresponding values?
I am toward the end of my project and I need some help pulling through this last part. Any advice is greatly appreciated.

Dave Eargle
May 24, 2021, 10:31:19 PM5/24/21
to John Mark Johnson, PsiTurk
Soapbox first: I have learned through pain and suffering to not collect live data until I have a dummy script set up for parsing the collected data -- to ensure that I'm actually collecting what I intend to.
That aside, look over this documentation page: https://psiturk.readthedocs.io/en/latest/retrieving.html
--
You received this message because you are subscribed to the Google Groups "PsiTurk" group.
To unsubscribe from this group and stop receiving emails from it, send an email to psiturk+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/psiturk/fb9345e6-016e-4626-92aa-ab700e60b20an%40googlegroups.com.
Dave Eargle
May 26, 2021, 12:14:59 PM5/26/21
to PsiTurk
John responded:
>
I have read the documentation and I am still unsure as to what I am doing when it comes to this part. Is it common practice to parse the data and then somehow resave this to that database or? Pardon my ignorance, I am just learning this on the fly with very little direction besides what I can find on the internet. While the documentation is excellent with respect to using and setting up psiturk, it doesn't offer a ton in terms of examples and what to do with the data part. Obviously, that is not psiturk developers job, I am just looking for direction from those that have used it and are seasoned in their ability to take the data from psiturk that is sent to mysql db, parse the data, send/save it (whether that be to the another table or db?), and then to take the parsed data and pass it on to spss.
John: You're asking a broad statistics data handling question here. The `trialdata` file will give you a "flat" file with one row per participant-trialdata. It's called "flat" because it's a CSV with one value per cell. What you _do_ with that data is largely up to your study design and research questions. In the case of the example stroop task, it's a repeated measures design, with one "participant-trialdata" per participant-stimulus response.
One row per participant-stimulus is called "long format." On the other hand, one row per participant, with one column per stimulus response, is called "wide" format. google searching for "spss repeated measures long format", first two search results look helpful. It's possible to transform back and forth between long and wide. IIRC, spss needs "wide" format, while everything else wants "long."
Again, once you have your trialdata, you're outside the world of psiturk and in regular plain statistics. Soapbox again, this is _not_ the area where you want to be "learning this on the fly" after you have already done data collection. Most unis have a stats department or something like that that should be able to help you from here.
Dave Eargle
Jun 2, 2021, 2:15:34 AM6/2/21
to PsiTurk
John responded (please respond to the group):
> No, I am not asking a statistics question as I know what I’m doing when I get the data into spss. I am asking how to filter the trial data I need for each participant from MySQL into a table or format that can then be transferred into spss to run the statistics. I’m not a coder. I’m a grad student designing an experiment that was supposed to be run in a lab but due to covid had to be moved online.
> As of right now, I can’t _do_ anything because the psiturk data spits out things I don’t want to be a part of the spss data analysis (ex. Practice trials, etc.) but are still important in my study. I am not a coder and never taken computer science so yes I’m learning that part on the fly but I don’t have much of a choice.
You're in the ETL phase of your statistical analysis then, and still beyond psiturk's purpose. Data munging -- transformations, filtering, the like -- are still requirements for any real-world statistical analysis and statistician in my opinion, but that stuff just gets in the way of most stats courses. You say you're not a coder, which is probably why you're using graphical spss, but no actual data collection that I have ever done has immediately led to data ready to go for statistical modeling. Statisticans would scoff at this being labeled "computer science." I still bet your statistics department will be able to help you, whether using SPSS, R, Python, whatever, there's countless ways to do it. Language you can use with them, "I have a flat file of events (the parsed trialdata file), but I need to filter out all but a certain type of those to feed into my model, can you help me?" Heck, you could use excel pivot tables. I don't know how to do it in spss, I hate stats guis, sorry. But Google suggests the "spss select cases" functionality. Again though, beyond the scope of psiturk
You received this message because you are subscribed to a topic in the Google Groups "PsiTurk" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/psiturk/uQYimZDt4VY/unsubscribe.
To unsubscribe from this group and all its topics, send an email to psiturk+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/psiturk/06b0214e-8dd3-4bf9-bfb6-a05027fd9571n%40googlegroups.com.
Dave Eargle
Jun 3, 2021, 1:07:41 AM6/3/21
to PsiTurk
John, who is having trouble using google groups, responded:
> Ok, I see what you're saying now and I am sorry I didn't make this clear: Yes, I know that what I am talking about is outside of psiturks scope. In my original post, I thought I mentioned that I was hoping to see how others handled filtering of data they derived from psiturk. Essentially, I was hoping to find info on other programs through the psiturk group. Maybe this was the incorrect way to go about it and I apologize for that. I just wanted more examples to compare against the data extraction example and script included in the manual.
> I appreciate your advice and will approach accordingly.
My apologies, you did say as much in your original post. My interpretation is likely a result of me typically responding when I'm about to fall asleep lol
Others welcome to respond, but I usually use python pandas dataframes to do my filtering plus feature engineering, then I save the df to a csv (or if multiple dataframes, then one csv per df), and load that in R using tidyverse readr, then dplyr to do any extra feature engineering or outlier removal or whatever.
If I didn't know pandas or dplyr, I would use just regular excel (no pivot tables necessarily) to filter the output of trialdata, and save the result from excel to a new csv, or whatever format spss needs (I think spss can load xlsx?). But the excel part wouldn't be scriptable since in this thought exercise I don't know how to script. I'd just use the excel filtering buttons. Then when I had everything, I'd copy-paste the still-showing rows into a new excel workbook, then save-as that as a csv. Except then I would rage because I would realize that excel had copied the hidden filtered-out rows, too. So I'd google and find out how to copy just visible rows, and find https://support.microsoft.com/en-us/office/copy-visible-cells-only-6e3a1f01-2884-4332-b262-8b814412847e , and I'd try again, and this time I'd have great success. I'd save that as a csv and load into spss. But then I'd realize at some point that I needed to filter to _different_ rows, so I'd go back to excel and start again to get a new csv. Then I would rage at the repettetiveness and I'd learn how to script. 10 hours to learn what I could have error-prone done in 10 minutes.
But no, I absolutely would not save the data back to a mysql table. Once flat, csv's all the way for program interchangeability.
On Wed, Jun 2, 2021, 7:41 AM John Mark Johnson <johnso...@gmail.com> wrote:
Ok, I see what you're saying now and I am sorry I didn't make this clear: Yes, I know that what I am talking about is outside of psiturks scope. In my original post, I thought I mentioned that I was hoping to see how others handled filtering of data they derived from psiturk. Essentially, I was hoping to find info on other programs through the psiturk group. Maybe this was the incorrect way to go about it and I apologize for that. I just wanted more examples to compare against the data extraction example and script included in the manual.I appreciate your advice and will approach accordingly.
To view this discussion on the web visit https://groups.google.com/d/msgid/psiturk/CAKL%3D07Rnibr88_7m5T33a1yDfD7h8C7bDjT9P36fZkd%2BuFQnNg%40mail.gmail.com.
John Mark Johnson
Jun 3, 2021, 7:22:56 PM6/3/21
to Dave Eargle, PsiTurk
This is exactly what I was looking for! Thank you so much for your help and advice.
I do know some basic scripting I am just trying to minimize causes of confusion as much as possible. Everything is going well so far. The psiturk manual/documentation was extremely helpful and was able to carry a complete rookie, such as myself, all the way to the data extraction step. I must admit that MySQL was pretty intimidating when I arrived to that step which caused me to start looking for help. Again- if I’m being honest- I do need to spend more trial and error with MySQL but I felt I was almost to the end and just started looking for pointers.
In any event, thank you again for your help. Your recommendations are greatly appreciated and will be closely observed in my next steps of the project.
Best wishes
To view this discussion on the web visit https://groups.google.com/d/msgid/psiturk/CAKL%3D07T5jH%2Bc8y1Qcw10dXcNuAiYa70cGd5kib%2BFr7UGF4vGdA%40mail.gmail.com.
John Mark Johnson
Jun 6, 2021, 2:52:02 PM6/6/21
to PsiTurk
Hi Dave (or anyone else that is nice enough to help),
I am sorry but I am pulling my hair out with trying to figure out what is going wrong with retrieving my data using Python. I understand that this is very simple to you and many others. However, I keep getting errors with the following script: 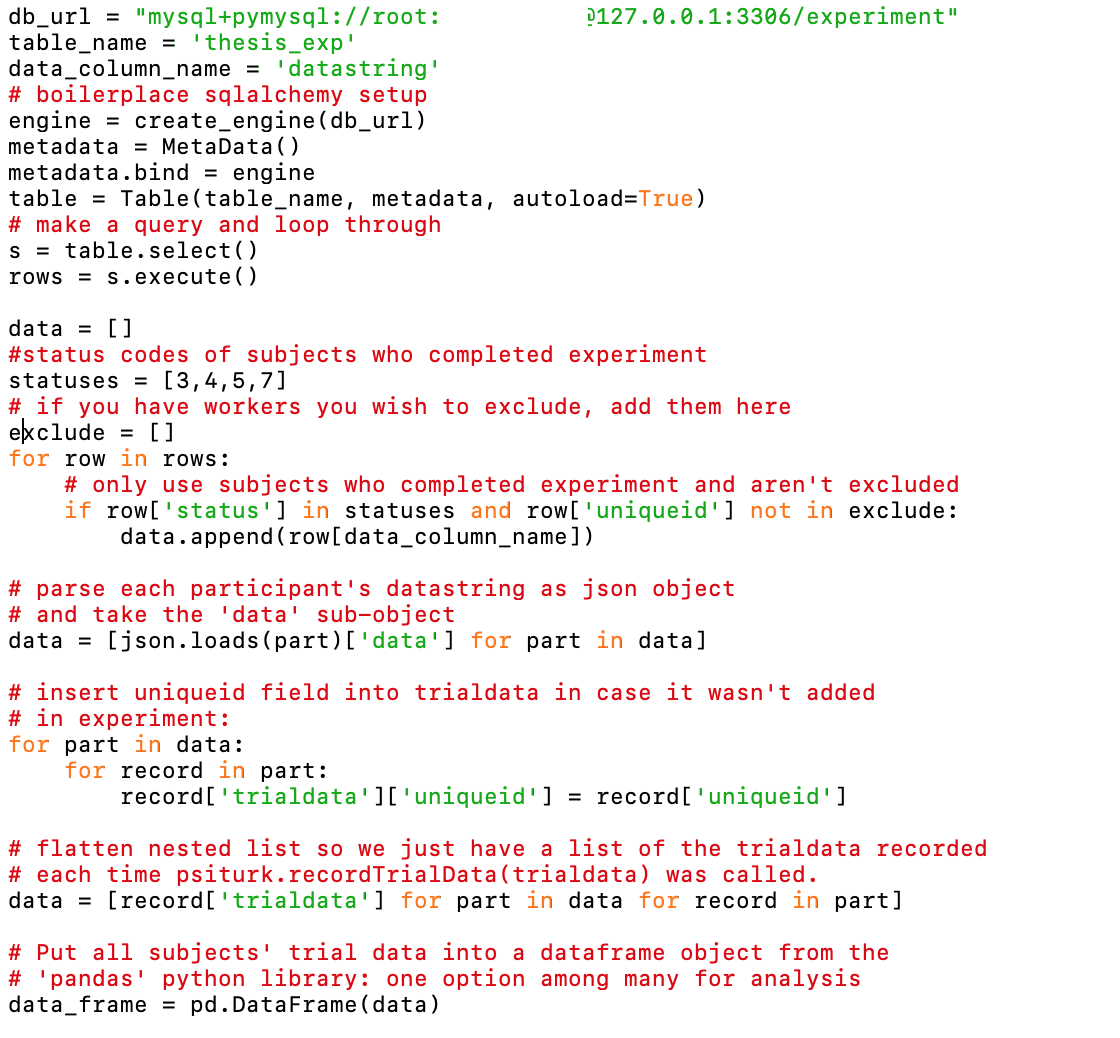
when I run this script I get the following error:
Traceback (most recent call last):
File "/Users/JMJ/Desktop/analysis_new.py", line 30, in <module>
data = [json.loads(part)['data',] for part in data]
File "/Users/JMJ/Desktop/analysis_new.py", line 30, in <listcomp>
data = [json.loads(part)['data',] for part in data]
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/json/__init__.py", line 341, in loads
raise TypeError(f'the JSON object must be str, bytes or bytearray, '
TypeError: the JSON object must be str, bytes or bytearray, not dict
File "/Users/JMJ/Desktop/analysis_new.py", line 30, in <module>
data = [json.loads(part)['data',] for part in data]
File "/Users/JMJ/Desktop/analysis_new.py", line 30, in <listcomp>
data = [json.loads(part)['data',] for part in data]
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/json/__init__.py", line 341, in loads
raise TypeError(f'the JSON object must be str, bytes or bytearray, '
TypeError: the JSON object must be str, bytes or bytearray, not dict
I searched this error online and most of the suggestions involve using json.dumps rather than json.loads. I have tried json.dumps, json.dump, json.load, saving the database into a json file and then opening using with open('example.json', 'r') as f:.
If you don't mind walking me through what might be going wrong here or any information at all I won't have to take up any more of your time.
Dave Eargle
Jun 6, 2021, 8:27:07 PM6/6/21
to John Mark Johnson, PsiTurk
> saving the database into a json file and then opening using with open('example.json', 'r') as f:.
There's your problem probably. The error message you're showing seems like it would maybe come from trying to load that file, because what used to be a string would have already been converted to a json at some point. I'm also suspicious because the error message shows a comma after 'data', which suggests that maybe the error message doesn't come from running the code you showed.
Regardless, I'm guessing you screwed something up at some point, and hopefully your data is still intact. Does running "download_datafiles" not suffice your needs? Does the "datastring" column in your database still look like actually a string? Debugging your particular case would require a few rounds of trial and error.
To view this discussion on the web visit https://groups.google.com/d/msgid/psiturk/3d278009-0fa1-4637-860f-7aed0d8c41cdn%40googlegroups.com.
John Mark Johnson
Jun 7, 2021, 10:41:02 AM6/7/21
to Dave Eargle, PsiTurk
Download_data files works fine. I only tried the saving as a Json file because everything else up to that point.
In the database the data seems to save as data datastring in json format. Is this incorrect?
The data I have so far is just debug and worthless anyway so I’d rather get it fixed now
And have everything working correctly.
John Mark Johnson
Jun 7, 2021, 10:42:48 AM6/7/21
to Dave Eargle, PsiTurk
And by worthless, I mean worthless to my study.
John Mark Johnson
Jun 7, 2021, 12:00:44 PM6/7/21
to Dave Eargle, PsiTurk
Never mind! I finally got it to work. I went to mysql and input ALTER TABLE xxxxx MODIFY COLUMN xxxxx LONGTEXT. Although nothing supposedly changed according to MySQL, when I ran the analysis it worked.
Thanks for your help.
Dave Eargle
Jun 7, 2021, 1:33:05 PM6/7/21
to John Mark Johnson, PsiTurk
Weird, what was the column datatype before you ran that alter statement? The psiturk db create code is already supposed to set it as "text".
John Mark Johnson
Jun 7, 2021, 2:43:41 PM6/7/21
to Dave Eargle, PsiTurk
Before and after it listed the data as json in mysql. From what I understand, longtext = json? I'm really not sure what happened, I am just glad it is working now.
Dave Eargle
Jun 7, 2021, 4:15:27 PM6/7/21
to John Mark Johnson, PsiTurk
Hrm, that's interesting, I'll look more into that. If that's the case, you would just drop the `json.loads()` call since it's already a dict.
Reply all
Reply to author
Forward
0 new messages