Prometheus High RAM Investigation
7,656 views
Skip to first unread message

Shubham Shrivastav
Feb 9, 2022, 9:45:51 PM2/9/22
to Prometheus Users
Hi all,
I've been investigating Prometheus memory utilization over the last couple of days.
Based on pprof command outputs, I do see a lot of memory utilized by getOrSet function, but according to docs, it's just for creating new series, so not sure what I can do about it.
I've been investigating Prometheus memory utilization over the last couple of days.
Based on pprof command outputs, I do see a lot of memory utilized by getOrSet function, but according to docs, it's just for creating new series, so not sure what I can do about it.
Also, to figure out if I have any metrics that I can remove I ran ./tsdb analyze on memory (output here: https://pastebin.com/twsFiuRk)
I did find some metrics having more cardinality than others but the difference was not very massive.
With ~100 nodes our RAM takes around 15 Gigs.
Present Situation:
Prometheus Containers got restarted due to OOM and I have fewer targets now (~6). That's probably why numbers seem low, but the metrics pulled will be the same.
I was trying to recognize the pattern
Some metrics:
Apart from distributing our load over multiple Prometheus nodes, are there any alternatives?
TIA,
Shubham
With ~100 nodes our RAM takes around 15 Gigs.
We're getting average Metrics Per node: 8257
Our estimation is around 200 nodes, which will make our RAM go through the roof.Present Situation:
Prometheus Containers got restarted due to OOM and I have fewer targets now (~6). That's probably why numbers seem low, but the metrics pulled will be the same.
I was trying to recognize the pattern
Some metrics:
process_resident_memory_bytes{instance="localhost:9090", job="prometheus"} 1536786432
go_memstats_alloc_bytes{instance="localhost:9090", job="prometheus"} 908149496
Apart from distributing our load over multiple Prometheus nodes, are there any alternatives?
TIA,
Shubham

Brian Candler
Feb 10, 2022, 3:20:04 AM2/10/22
to Prometheus Users
What prometheus version? How often are you polling? How are you measuring the RAM utilisation?
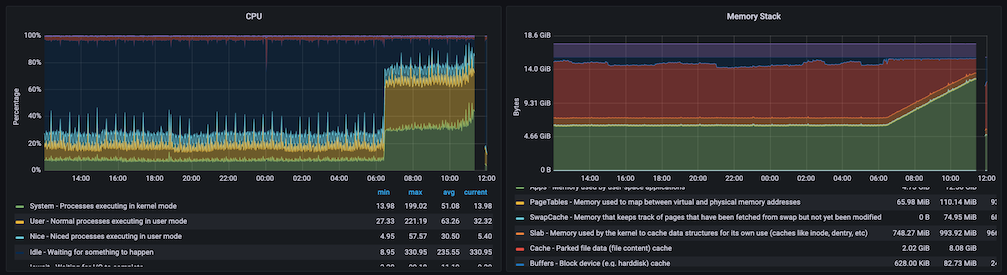
Let me give you a comparison. I have a prometheus instance here which is polling 161 node_exporter targets, 38 snmp_exporter targets, 46 blackbox_exporter targets, and a handful of others, with a 1 minute scrape interval. It's running inside an lxd container, and uses a grand total of 2.5GB RAM (as reported by "free" inside the container, "used" column). The entire physical server has 16GB of RAM, and is running a bunch of other monitoring tools in other containers as well. The physical host has 9GB of available RAM (as reported by "free" on the host, "available" column).
This is with prometheus-2.33.0, under Ubuntu 18.04, although I haven't noticed significantly higher RAM utilisation with older versions of prometheus.
Using "Status" in the Prometheus web UI, I see the following Head Stats:
Number of Series 525141
Number of Chunks 525141
Number of Label Pairs 15305
I can use a relatively expensive query to count the individual metrics at the current instance in time (takes a few seconds):
Number of Chunks 525141
Number of Label Pairs 15305
I can use a relatively expensive query to count the individual metrics at the current instance in time (takes a few seconds):
count by (job) ({__name__=~".+"})
This shows 391,863 metrics for node(*), 99,175 metrics for snmp, 23,138 metrics for haproxy (keepalived), and roughly 10,000 other metrics in total.
(*) Given that there are 161 node targets, that's an average of 2433 metrics per node (from node_exporter).
In summary, I find prometheus to be extremely frugal in its use of RAM, and therefore if you're getting OOM problems then there must be something different about your system.
Are you monitoring kubernetes pods by any chance? Is there a lot of churn in those pods (i.e. pods being created and destroyed)? If you generate large numbers of short-lived timeseries, then that will require a lot more memory. The Head Stats figures is the place to start.
Aside: a week or two ago, there was an isolated incident where this server started using more CPU and RAM. Memory usage graphs showed the RAM growing steadily over a period of about 5 hours; at that point, it was under so much memory pressure I couldn't log in to diagnose, and was forced to reboot. However since node_exporter is only returning the overall RAM on the host, not per-container, I can't tell which of the many containers running on that host was the culprit.
This server is also running victoriametrics, nfsen, loki, smokeping, oxidized, netdisco, nagios, and some other bits and bobs - so it could have been any one of those. In fact, given that Ubuntu does various daily housecleaning activities at 06:25am, it could have been any of those as well.
Shubham Shrivastav
Feb 10, 2022, 4:16:57 AM2/10/22
to Prometheus Users
Hey, I'm using Prometheus v2.29.1.
My scrape interval is 15 seconds and I'm measuring RAM using "container_memory_working_set_bytes"(metrics used to check k8s pod usage)
Using "Status" in the Prometheus web UI, I see the following Head Stats:
Number of Series 7644889
Number of Chunks 8266039
Number of Label Pairs 9968
Like I mentioned above, We're getting the average Metrics Per node as 8257
and we have around 300 targets now, which makes our total metrics around 2,100,000.Number of Chunks 8266039
Number of Label Pairs 9968
Are you monitoring Kubernetes pods by any chance? I'm not monitoring any pods, I connect to certain nodes that send in custom metrics. Since I'm using a pod and not a node, the resources assigned to this pod are exclusive.

Ben Kochie
Feb 10, 2022, 4:35:12 AM2/10/22
to Shubham Shrivastav, Prometheus Users
You say you have 2.1 million metrics, but your head series is 7.6 million. This means you have a huge amount of series / label churn. This is going to hugely bloat the memory use.
You have several options here
* Increase your memory allocation
* Reduce the number of metrics per target
* Find if you have problematic labels that are causing series churn
* Shard Prometheus
Handling millions of series requires capacity planning. There is just no way around this.
--
You received this message because you are subscribed to the Google Groups "Prometheus Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to prometheus-use...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/prometheus-users/cb2f43ff-eebf-48cc-a77a-637482430448n%40googlegroups.com.
Brian Candler
Feb 10, 2022, 8:01:56 AM2/10/22
to Prometheus Users
On Thursday, 10 February 2022 at 09:16:57 UTC shrivasta...@gmail.com wrote:
Number of Series 7644889Like I mentioned above, We're getting the average Metrics Per node as 8257 and we have around 300 targets now, which makes our total metrics around 2,100,000.
Number of Chunks 8266039
Number of Label Pairs 9968
I don't know how you're determining "average Metrics per node". But you can get total metrics at the current time instant via a direct query:
count({__name__=~".+"})
> Are you monitoring Kubernetes pods by any chance? I'm not monitoring any pods, I connect to certain nodes that send in custom metrics.
Then maybe your metrics are at fault.
If there are 8 million series in your head chunk, i.e. in the last 2 hours, then you must have lots of series churn. What defines a "timeseries" in Prometheus is the combination of metric name and the bag of labels. If any label changes - even a single label - then that creates a whole new timeseries. For example:
foo{bar="aaa",baz="bbb",qux="ccc"}
foo{bar="aaa",baz="bbb",qux="ccd"}
are two completely different timeseries. The RAM usage is determined in large part by the number of different timeseries seen in the last 2 hours or so, which are in the "head chunk". Therefore if you do something ill-advised, like putting a changing value in a label, you will get an explosion of timeseries. Google "prometheus cardinality explosion": the top hit is this.
Example 1:
http_requests_total{method="POST",path="/"} 1
This might be a reasonable metric, but only if the set of "path" values is limited (i.e. exporter selects from a pre-defined set, no random user-provided paths are ever shown)
Example 2:
http_requests_total{method="POST",source_ip="192.0.2.1",path="/"} 1
This one definitely isn't reasonable, because the source_ip address is a high cardinality value and you'll be creating a separate set of timeseries for every source address. Prometheus will crash and burn.
If you need to store high-cardinality string values, then Prometheus is the wrong tool for the job. Look at Loki or Elasticsearch.
Ben Kochie
Feb 10, 2022, 8:48:37 AM2/10/22
to Shubham Shrivastav, Prometheus Users
Your 8257 metrics per node means you have 825,700 metrics on the server. The typical usage of Prometheus is around 8KiB per active series. This is expected to need 7GiB of memory.
The problem is you have posted pprof and memory usage that do not match what your claims are. Without data while under your real load, it's impossible to tell you what is wrong.
It's also useful to include the prometheus_tsdb_head_series metric. But again, while you have your 100 servers configured.
You need to post more information about your actual setup. Please include your full configuration file and version information.
--
You received this message because you are subscribed to the Google Groups "Prometheus Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to prometheus-use...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/prometheus-users/a74b38ab-ee70-46c6-bd5c-563aede095f4n%40googlegroups.com.
Shubham Shrivastav
Feb 11, 2022, 3:28:55 AM2/11/22
to Prometheus Users
Hi guys,
Current pprof stats: https://pastebin.com/0UnhvWpH
I think I'll probably also consider Loki if this problem is not resolvable
Let me post the tsdb stats, our monitoring team keeps clearing targets out.
TIA,
Shubham Shrivastava
Current pprof stats: https://pastebin.com/0UnhvWpH
@Brian: I do have a metric called node_systemd_unit_state (systemd metric) and installed_software{package_name="GConf2.x86_64",version="3.2.6-8.el7"} (our custom metric) that has high cardinality
Full TSDB Status here: https://pastebin.com/DFJ2k3Q1
I think I'll probably also consider Loki if this problem is not resolvable
Let me post the tsdb stats, our monitoring team keeps clearing targets out.
TIA,
Shubham Shrivastava
Brian Candler
Feb 11, 2022, 4:19:14 AM2/11/22
to Prometheus Users
> installed_software{package_name="GConf2.x86_64",version="3.2.6-8.el7"}
> (our custom metric) that has high cardinality
Cardinality refers to the labels, and those labels are not necessarily high cardinality, as long as they come from a relatively small set and don't keep changing dynamically. You'll see something similar in standard node_exporter metrics like node_uname_info.
Think of it like this. After the scrape, prometheus adds it's own "job" and "instance" labels. So, let's say each target exposes 1,000 'installed_software' metrics, and you have 100 targets, then you'll have a total of 100,000 timeseries which look like this:
installed_software{instance="server1",job="node",package_name="GConf2.x86_64",version="3.2.6-8.el7"} 1
installed_software{instance="server1",job="node",package_name="blah.x86_64",version="a.b.c.d-el7"} 1
installed_software{instance="server2",job="node",package_name="GConf2.x86_64",version="3.2.1-4.el7"} 1
... etc
However, as long as those labels aren't changing, then you will just have the same 100,000 timeseries over time, and that's not a large number of timeseries for Prometheus to deal with. (Aside: they all have the static value "1", so the delta between adjacent scrapes is 0, so they also compress extremely well on disk). Furthermore, the distinct label values like "GConf2.x86_64" are shared between many timeseries.
Now, looking in your TSDB Stats, you have about 1 million of these, followed by 1 million of node_systemd_unit_state, followed by a whole bunch of metrics artemis_XXX each with 200K each. That *is* a lot of metrics, and I can see how this could easily add up to 8 million. You could count all the artemis ones like this:
count({__name__=~"artemis_.*"})
If you genuinely have 8 million timeseries then you're going to have to make a decision.
1. throw money at this to scale Prometheus up to a suitable scale
2. decide which of these metrics have low business value and stop collecting them
3. reduce the number of metrics, e.g. by aggregating them at the exporter
4. collect, store and query this information a different way
Only you can decide the tradeoff. It seems to me that many of these metrics like "artemis_message_count" could be really valuable. But do you really have 200K separate message brokers, or are these metrics giving you too much detail (e.g. separate stats per queue)? Could you just aggregate them down to a single value per node, whilst maintaining their usefulness?
Reply all
Reply to author
Forward
0 new messages