PDF::Reader::MalformedPDFError: Error occured while inflating a compressed stream (Zlib::DataError: invalid stored block lengths)
104 views
Skip to first unread message

Ashish Sethi
May 11, 2020, 6:39:13 PM5/11/20
to PDF::Reader
Hello,
I would appreciate the resolution to this problem:
PDF::Reader::MalformedPDFError: Error occured while inflating a compressed stream (Zlib::DataError: invalid stored block lengths)
I would appreciate the resolution to this problem:
PDF::Reader::MalformedPDFError: Error occured while inflating a compressed stream (Zlib::DataError: invalid stored block lengths)
This happens when I try to extract PDF text.
The attached PDF could be opened in Acrobat Pro and I believe it is not a bad pdf.
The attached PDF could be opened in Acrobat Pro and I believe it is not a bad pdf.
TIA!
-Ashish

Wayne Brissette
May 12, 2020, 1:20:05 PM5/12/20
to pdf-r...@googlegroups.com, Ashish Sethi
Ashish: That PDF is a single page and when I tested it using:
reader = PDF::Reader.new("/Users/wayne/Downloads/Sample1.pdf") reader.pages.each do |page| puts page.fonts puts page.text puts page.raw_content end I end up with: {} ????????????????????? q /Fm0 Do Q So it had no clue about fonts. Which I noticed on a different project myself and makes me wonder if something has changed regarding type. The content of the PDF however was read and displayed without any issues.
Ashish Sethi
May 12, 2020, 1:41:21 PM5/12/20
to PDF::Reader
Thanks, Wayne!
Wayne Brissette
May 12, 2020, 2:15:04 PM5/12/20
to pdf-r...@googlegroups.com, Ashish Sethi
One thing I do wonder. What are the permissions on that PDF? I have in
the past noticed some strange things when I was trying to read a
protected PDF (makes sense really).
Also, while it didn't come across in the email, the output was the
Japanese characters that were displayed on the PDF page.
-Wayne
the past noticed some strange things when I was trying to read a
protected PDF (makes sense really).
Also, while it didn't come across in the email, the output was the
Japanese characters that were displayed on the PDF page.
-Wayne
Ashish Sethi
May 14, 2020, 2:09:23 PM5/14/20
to PDF::Reader
The PDF is not protected.
Thx!
Wayne Brissette
May 14, 2020, 2:11:06 PM5/14/20
to pdf-r...@googlegroups.com, Ashish Sethi
Did you get the full PDF to ever work?
--
You received this message because you are subscribed to the Google Groups "PDF::Reader" group.
To unsubscribe from this group and stop receiving emails from it, send an email to pdf-reader+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/pdf-reader/b7398617-cd34-49f1-8c6d-5565c02c4d90%40googlegroups.com.

James Healy
May 17, 2020, 9:01:59 AM5/17/20
to pdf-r...@googlegroups.com
Hi Ashish,
Can you post an example script that triggers this issue, and some
environment details (ruby version, windows/macos/linux, etc).
On my laptop (ruby 2.7, linux), I can extract the text:
$ pdf_text Sample1.pdf
「辻」と「辻」
James
Can you post an example script that triggers this issue, and some
environment details (ruby version, windows/macos/linux, etc).
On my laptop (ruby 2.7, linux), I can extract the text:
$ pdf_text Sample1.pdf
「辻」と「辻」
James
> --
> You received this message because you are subscribed to the Google Groups "PDF::Reader" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to pdf-reader+...@googlegroups.com.
> To view this discussion on the web visit https://groups.google.com/d/msgid/pdf-reader/a3a7cabc-f632-4487-a4c9-e38b0f9619b5%40googlegroups.com.
> You received this message because you are subscribed to the Google Groups "PDF::Reader" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to pdf-reader+...@googlegroups.com.
Wayne Brissette
May 17, 2020, 9:16:20 AM5/17/20
to pdf-r...@googlegroups.com, James Healy
James:
That mirrors my experience as well, which is why I asked if he ever got
it to work using Mac OS and Ruby 2.7.1.
-Wayne
That mirrors my experience as well, which is why I asked if he ever got
it to work using Mac OS and Ruby 2.7.1.
-Wayne
Ashish Sethi
May 26, 2020, 1:22:02 PM5/26/20
to PDF::Reader
Hello James and Wayne!
Sorry for delayed reply.
Please find attached a new PDF and give it a try.
What I am trying to do:
What I am trying to do:
reader = PDF::Reader.new("sample.pdf")
reader.pages.each do |page|
puts page.fonts
puts page.text
end
I can read the fonts but I get the following error when trying to read text:
"Error occured while inflating a compressed stream (Zlib::DataError: invalid stored block lengths)"
I am using:
Ruby version: ruby 2.6.5p114 (2019-10-01 revision 67812) [x64-mingw32]
Gem: pdf-reader 2.0.0
machine info: Win 10 x64
Thx!
Wayne Brissette
May 26, 2020, 2:06:27 PM5/26/20
to pdf-r...@googlegroups.com, Ashish Sethi
I'm not an expert in PDF data structures.
But there is something wrong here. If I use this sample it too gives me
the same error. If I then open it in any PDF reader, save it using a
different name (you could overwrite the original I suppose), then run
the simple script, it works. So this isn't copy protected because it
doesn't ask you for a PW at any time. However, it's certainly in some
compressed format that the Zlib library/Gem doesn't recognize. Maybe
James will have more insight for you.
-Wayne
-Wayne
--
You received this message because you are subscribed to the Google Groups "PDF::Reader" group.
To unsubscribe from this group and stop receiving emails from it, send an email to pdf-reader+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/pdf-reader/41c2c970-1840-432a-8011-6b8f4b6c86fa%40googlegroups.com.
Ashish Sethi
Jun 3, 2020, 6:17:03 PM6/3/20
to PDF::Reader
@James,
Any inputs?
Thx!
To unsubscribe from this group and stop receiving emails from it, send an email to pdf-r...@googlegroups.com.
James Healy
Jun 5, 2020, 11:16:38 AM6/5/20
to pdf-r...@googlegroups.com
Hi Ashish,
The page in that PDF has it's content defined in 3 objects, and one of them claims to be Flate compressed. However, I believe the compression is broken.
If I open the PDF in firefox (which uses pdf.js), I get console warnings that the zlib compressed data has invalid check bits in the header:
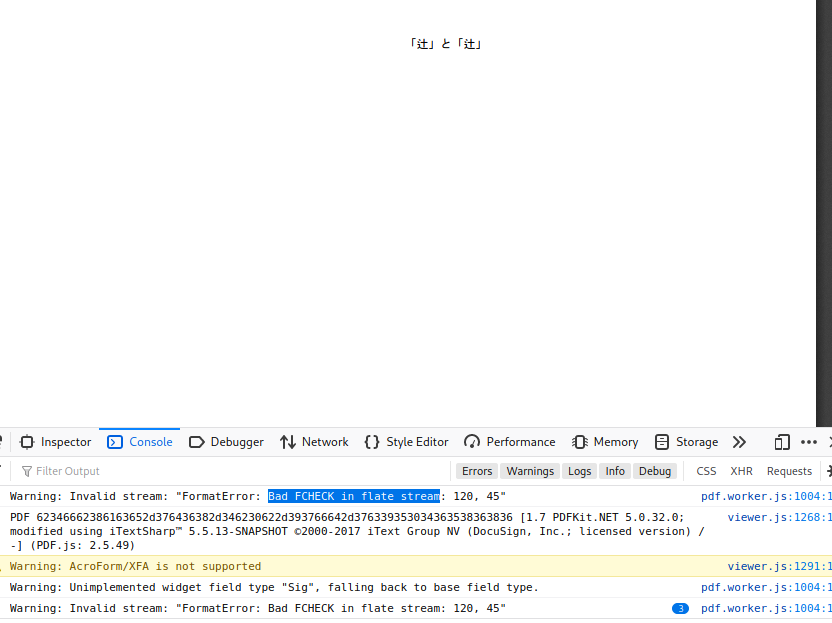
You can see that some text still renders though. pdf.js seems to just skip over the broken stream and attempts to render the page anyway.
I tried a similar approach in pdf-reader, and it works for your file. I made this code change:
diff --git a/lib/pdf/reader/filter/flate.rb b/lib/pdf/reader/filter/flate.rb
index 2489757..aefbc45 100644
--- a/lib/pdf/reader/filter/flate.rb
+++ b/lib/pdf/reader/filter/flate.rb
@@ -32,8 +34,9 @@ class PDF::Reader
Depredict.new(@options).filter(deflated)
rescue Exception => e
# Oops, there was a problem inflating the stream
- raise MalformedPDFError,
- "Error occured while inflating a compressed stream (#{e.class.to_s}: #{e.to_s})"
+ #raise MalformedPDFError,
+ # "Error occured while inflating a compressed stream (#{e.class.to_s}: #{e.to_s})"
+ return ""
end
end
end
index 2489757..aefbc45 100644
--- a/lib/pdf/reader/filter/flate.rb
+++ b/lib/pdf/reader/filter/flate.rb
@@ -32,8 +34,9 @@ class PDF::Reader
Depredict.new(@options).filter(deflated)
rescue Exception => e
# Oops, there was a problem inflating the stream
- raise MalformedPDFError,
- "Error occured while inflating a compressed stream (#{e.class.to_s}: #{e.to_s})"
+ #raise MalformedPDFError,
+ # "Error occured while inflating a compressed stream (#{e.class.to_s}: #{e.to_s})"
+ return ""
end
end
end
.. and the text is extracted:
$ ruby -Ilib bin/pdf_text sample\(1\).pdf
DocuSign Envelope ID: 45BFED27-0910-4248-8030-C853B0DE0248
「辻」と「辻」
DocuSign Envelope ID: 45BFED27-0910-4248-8030-C853B0DE0248
「辻」と「辻」
I'm not sure if that's a general approach I want to commit though. It may not work as well on other PDFs.
James
To unsubscribe from this group and stop receiving emails from it, send an email to pdf-reader+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/pdf-reader/ad3d18b1-2b31-44af-b8d9-ccec7c873fad%40googlegroups.com.
Ashish Sethi
Jun 5, 2020, 12:17:03 PM6/5/20
to PDF::Reader
Thank you, James!
To view this discussion on the web visit https://groups.google.com/d/msgid/pdf-reader/ad3d18b1-2b31-44af-b8d9-ccec7c873fad%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages