Using EQU with dimensioned arrays in the debugger

Joe G
Symbol not found.
STRING: t r L=0 `'
:

Jim Idle
--
You received this message because you are subscribed to
the "Pick and MultiValue Databases" group.
To post, email to: mvd...@googlegroups.com
To unsubscribe, email to: mvdbms+un...@googlegroups.com
For more options, visit http://groups.google.com/group/mvdbms
---
You received this message because you are subscribed to the Google Groups "Pick and MultiValue Databases" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mvdbms+un...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/fe6f8511-9756-478c-b712-a3aae1d28065n%40googlegroups.com.

George Gallen
Sent: Sunday, July 17, 2022 8:09 PM
To: Pick and MultiValue Databases <mvd...@googlegroups.com>
Subject: [mvdbms] Using EQU with dimensioned arrays in the debugger
Joe G

Rex Gozar
Regarding equating attributes, you've described one way I've seen it done, but there is another way.
Instead of:
EQU INVOICE.DATE TO INVOICE.REC(1)
you would only equate the attribute number, e.g.:
EQU INVOICE.DATE.AMC TO 1
That way, the same equate could be used in both dimensioned and dynamic arrays.
CRT INVOICE.REC(INVOICE.DATE.AMC)
CRT INVOICE.ITEM<INVOICE.DATE.AMC>
PROS:
* both dimensioned and dynamic arrays would use the same attribute names
* allows program to have two different records from the same file; e.g., BILLTO.ITEM<CUS.CITY.AMC> and SHIPTO.ITEM<CUS.CITY.AMC>
* unique attribute name is searchable across all program files
* easier to differentiate between a scalar variable and an assignment
CONS:
* does not standardize the variable name
* expression is longer (more characters to type)
See the PickWiki page https://www.pickwiki.com/index.php/CodingStandards for a deeper explanation.
Regarding a utility that maps reads/writes and updates from source programs, I have written my own programs to convert attribute "magic" numbers to attribute names. What you describe about finding all the OPEN statements and file variables used is pretty much what I had to do. All of our software now uses attribute names.
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/fab3ba30-d0e6-4aee-be37-d3f60051ca75n%40googlegroups.com.
Joe G

Jeff Teter
Joe - good to see you posting here. Let me extend this paradigm just a bit further.
I, too, like Rex's idea of using equated integers and using them for either dimensioned or dynamic variables. I'd suggest taking the idea even a bit further...
- For the equated variable name, use a standard format that uses the structure "group.subject.modifier.scope'. Using this model makes the various pieces of data easy to work with in editors providing intellisense, e.g., all entries are sorted by subject, modifier and scope, making selection simple.
- The 'group' is the file name (or reference) or a logical section of data
- The 'subject' is the topic under discussion. In Joe's example above, 'DATE' is the date of the invoice.
- The 'modifier' allows various uses of the subject. For instance, we might use 'INVOICE.DATE.ORDER' or 'INVOICE.DATE.SHIP'.
- 'Scope' refers to various instances of the same subject and modifier. We might want to use 'INVOICE.DATE.ORDER.CLOSED' vs 'INVOICE.DATE.ORDER.STARTED'. In the particular industry that I work in, I use variables such as 'LOAN.INTEREST.PAID.YTD' or 'LOAN.INTEREST.ACCRUED.YTD'
- Note that the names above are the reference name but not the column name used on reports. That might be abbreviated or altered to fit the needs of reporting, etc.
- The team should agree on standard abbreviations. In the example above, 'YTD' refers to 'Year To Date' but I've seen in old dictionaries where 'DATE' is abbreviated as 'DAT', 'DT', 'DATE' or (someone with a German flair) 'DATUM'.
- Dictionaries can/should be built using the subject/modifier/scope. So, in the INVOICE file, I would have a dictionary called 'DATE.ORDER' that would correspond to the include line.
- If an attribute is further broken down by values with particular purposes, the attribute is referenced as 'attribute.INFO' and the values are given more specific names. For instance, attribute 10 might be 'INVOICE.NAME.INFO' and value 1 is used to store the first name, so it would be referenced as 'INVOICE.NAME.FIRST', etc. In this case the include for INVOICE.NAME.INFO would be equated to 10 and the include for INVOICE.NAME.FIRST would be equated to 1. Then, in programs, I can have a statement line 'INVOICE.REC< INVOICE.NAME.INFO, INVOICE.NAME.FIRST > = "Jim"'.
- The include line can be extended with a comment to include data type, length, decimals, justification and description. This, then, gives enough information that dictionaries can be built from the include record. This makes the file self-documenting and the description can be carried from the include file to line 1 of the dictionary.
Brian Leach, in England, has suggested a structure for documenting dictionaries which is very helpful and it works for UniVerse style dictionaries as well as Pick 'S'-type and 'A'-type dictionaries. Since Pick/UniVerse flavors allow multiple dictionaries for a data file, I have extended Brian's work to include a prefix to the description that is for dictionary group. This is an integer that represents a sum of the various dictionary files in which a dictionary is to occur. For instance, the dictionary created with the file is assigned a value of 1 (In Joe's example, this would be the dictionary for the 'INVOICE' file). A dictionary file created for ODBC might be called 'ODBC.INVOICE' and would be assigned a value of 2. If a dictionary occurs in both files (with the same format, etc.), the dictionary group would be 3 (1+2).
Using a subroutine, I can pull all of the data from dictionaries and, if necessary, export them to text files. Using any of the standard compare tools, I can then compare, by example, the INVOICE and the ODBC.INVOICE dictionaries.
The other big advantage to using the equated values is that is someone gets a wild hair and moves a particular element, say from attribute 1 to attribute 5, the included reference to the file does not need to change, only the reference in the include file, followed by re-compiling any programs using that include file. Hopefully, though, we're not moving fields around too often!

Gerd Förthmann
Who in his right mind would want to change the attribute positions in a file?
The only time in my career that I was told to do that was by a so-called analyst who also told me that I was not allowed to use multi-values in data files because according to the school of Codd they are illegal.
That's UK government for you. Hire a Pick analyst-programmer for 35 GBP an hour and an "analyst" who doesn't know Pick at all for 50 to tell the programmer how to do his job. No wonder they can't even organize a piss-up in a brewery.
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/fbb40fe7-da90-4c02-82b5-6a75f773767en%40googlegroups.com.
Jim Idle

Martin Phillips
If we are widening the response beyond UV, it is worth adding that OpenQM has a compiler option to record equate tokens used in the program in the symbol table. They can then be used in the debugger as the OP wants.
From: mvd...@googlegroups.com <mvd...@googlegroups.com>
On Behalf Of Jim Idle
Sent: 21 July 2022 07:40
To: mvd...@googlegroups.com
Subject: Re: [mvdbms] Using EQU with dimensioned arrays in the debugger
|
EXTERNAL EMAIL |
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/CAGPPfg8stSQ_j9g%3D%3DUF4YEhaa63iufOzKxpAVsRXKPUbyDASmA%40mail.gmail.com.
================================
Rocket Software, Inc. and subsidiaries ■ 77 Fourth Avenue, Waltham MA 02451 ■ Main Office Toll Free Number: +1 855.577.4323
Contact Customer Support: https://my.rocketsoftware.com/RocketCommunity/RCEmailSupport
Unsubscribe from Marketing Messages/Manage Your Subscription Preferences - http://www.rocketsoftware.com/manage-your-email-preferences
Privacy Policy - http://www.rocketsoftware.com/company/legal/privacy-policy
================================
This communication and any attachments may contain confidential information of Rocket Software, Inc. All unauthorized use, disclosure or distribution is prohibited. If you are not the intended recipient, please notify Rocket Software immediately and destroy
all copies of this communication. Thank you.
Joe G
* COPYRIGHT (C) BANK OF HORTON - STUDENT LOAN SERVICES
* 108 E. 8TH STREET
* HORTON, KS 66439
* 913/486-2113
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/fbb40fe7-da90-4c02-82b5-6a75f773767en%40googlegroups.com.
Joe G
Joe G
Gerd Förthmann
Most likely because not many people find it useful or see a need
for it.
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/0d8de835-9e1a-4aad-9e3c-d16994ce768en%40googlegroups.com.

James A
At DocMagic we require all files to use EQU’s on dimmed arrays; the array is usually in a named common with the name of the file (there are legacy exceptions).
Naming conventions are essential to make the code clear and avoid collisions and dreaded ‘global common bugs’ (which can and do happen other ways; but that’s the downside of not having an object oriented language in general).
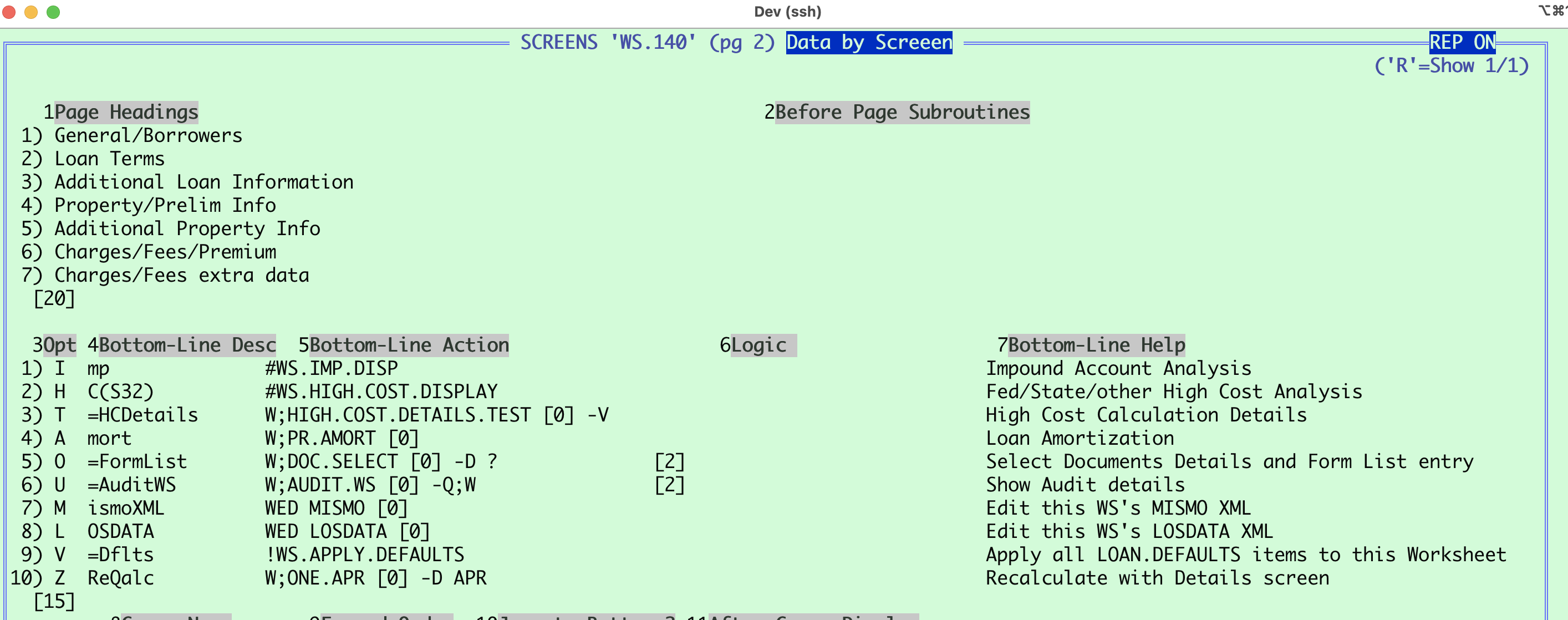
Here’s an example of our INPUT <screen> custom ‘Bottom Line’ options setup that shows lots of our coding conventions developed over 35 years:
- All equates in a program named ‘EQU.<filename>’
- Array is <file>.REC
- Size of the ‘.REC’ array is in <file>.C (for ‘C’ounter): for loops over the entire array etc (ex: initializing it).
- May be in <file>.COMMON; but may be in a more global COMMON.
- All equated names start with the file name and ‘$’; remainder is mixed case
- Append ‘S’ for Multi-Valued field (append ‘SS’ for multi-sub-valued)
- Start the name after the ‘$’ with the C/D Group name if applicable (‘Bottom’ below)
- Comments are <2-spaces>;*<2-spaces>; or line up when possible/convenient
- Keep C/D Groups together; if you haven’t left enough available attributes (don’t do that next time! Always leave unused ‘gaps’ in C/D groups!), put the attribute in numerical order with a ‘see xxx’ comment’; and put a commented version in order in the group (see SCREEN$BottomHelpS below)
INPUT.COMMON:
common /INPUT/ SCREEN.REC(98) ;* See EQU.SCREEN and SCREEN.C
EQU.SCREEN:
equate SCREEN.C to 98
…
…
…
equate SCREEN$IdSeparator to SCREEN.REC(13) ;* Multi-part key separator ('~','_', etc)
equate SCREEN$AllowPartialId to SCREEN.REC(14) ;* 'T'op, 'M'iddle, 'B'ottom, or 'N'one allowed blank (old SCR.KEY.PARTIAL)
equate SCREEN$MiscDisplays to SCREEN.REC(15)
equate SCREEN$PostInputSub to SCREEN.REC(17)
equate SCREEN$PageHeadingS to SCREEN.REC(18) ;* All we have for each Page now
equate SCREEN$BottomHelpS to SCREEN.REC(19) ;* (see below)
equate SCREEN$BottomOptionS to SCREEN.REC(21) ;* Custom bottom-line options
equate SCREEN$BottomDescS to SCREEN.REC(22) ;* and (short) descriptions
equate SCREEN$BottomActionS to SCREEN.REC(23) ;* See SCREEN '?' for Actions syntax
equate SCREEN$BottomLogicS to SCREEN.REC(24) ;* MagicLogic to turn this option on/off
*quate SCREEN$BottomHelpS to SCREEN.REC(19) ;* Full line of help text for '?' option
…
Since we use this is ALL CODE, it never takes more than a few seconds to find all the usages of a data point:
>FIND.BP SCREEN\$Bottom
/u/dsisrc/RMS.BP/EQU.SCREEN:* 28.Apr.2022 james: MV-115: New field SCREEN$BottomHelpS
/u/dsisrc/RMS.BP/EQU.SCREEN: equate SCREEN$BottomHelpS to SCREEN.REC(19) ;* (see below)
/u/dsisrc/RMS.BP/EQU.SCREEN: equate SCREEN$BottomOptionS to SCREEN.REC(21) ;* Custom bottom-line options
/u/dsisrc/RMS.BP/EQU.SCREEN: equate SCREEN$BottomDescS to SCREEN.REC(22) ;* and (short) descriptions
/u/dsisrc/RMS.BP/EQU.SCREEN: equate SCREEN$BottomActionS to SCREEN.REC(23) ;* See SCREEN '?' for Actions syntax
/u/dsisrc/RMS.BP/EQU.SCREEN: equate SCREEN$BottomLogicS to SCREEN.REC(24) ;* MagicLogic to turn this option on/off
/u/dsisrc/RMS.BP/EQU.SCREEN: *quate SCREEN$BottomHelpS to SCREEN.REC(19) ;* Full line of help text for '?' option
/u/dsisrc/RMS.BP/INPUT.MAIN:* 28.Apr.2022 james: MV-115: '?' Help on bottom line options; use SCREEN$BottomHelpS
/u/dsisrc/RMS.BP/INPUT.MAIN: NUM.BOT.OPTS = dcount(SCREEN$BottomOptionS, @VM) ;* Now in Commons
/u/dsisrc/RMS.BP/INPUT.MAIN: Logic = SCREEN$BottomLogicS<1, N.B.O>
/u/dsisrc/RMS.BP/INPUT.MAIN: OPTS<-1> = SCREEN$BottomOptionS<1, N.B.O> ; DESCS<-1> = SCREEN$BottomDescS<1, N.B.O>
/u/dsisrc/RMS.BP/INPUT.MAIN: locate( O, SCREEN$BottomOptionS, 1; N.B.O ) then ;* Entered a user-defined option?
/u/dsisrc/RMS.BP/INPUT.MAIN: BL.ACT = SCREEN$BottomActionS<1,N.B.O> ;* TAKE ACTIOOOOOOWN
/u/dsisrc/RMS.BP/INPUT.MAIN: if SCREEN$BottomOptionS # '' then
/u/dsisrc/RMS.BP/INPUT.MAIN: NUM.BOT.OPTS = dcount(SCREEN$BottomOptionS, @VM) ;* Now in Commons
/u/dsisrc/RMS.BP/INPUT.MAIN: Logic = SCREEN$BottomLogicS<1, N.B.O>
/u/dsisrc/RMS.BP/INPUT.MAIN: HelpLine = SCREEN$BottomHelpS<1, N.B.O>
/u/dsisrc/RMS.BP/INPUT.MAIN: if HelpLine = '' then HelpLine = SCREEN$BottomDescS<1, N.B.O>
/u/dsisrc/RMS.BP/INPUT.MAIN: BotLineHelp := @FM:' ':PrS:SCREEN$BottomOptionS<1, N.B.O>:PrX:' : ':HelpLine
>
And when using the values it’s crystal clear they’re from a global common:
…
* 20.Feb.1986 jim: First Draft
…
…
…
* Add custom options from SCREENS file:
NUM.BOT.OPTS = dcount(SCREEN$BottomOptionS, @VM) ;* Now in Commons
for N.B.O = 1 to NUM.BOT.OPTS
Logic = SCREEN$BottomLogicS<1, N.B.O>
if Logic # '' then
call INPUT.CMD( Logic ) ;* Does this need more setup, etc !?
end else Logic = @TRUE
if Logic then
OPTS<-1> = SCREEN$BottomOptionS<1, N.B.O> ; DESCS<-1> = SCREEN$BottomDescS<1, N.B.O>
end
next N.B.O
…
SCREENS screen definition:
How it renders on the bottom line(s) (from the code snippet above):

‘?’ option shows ‘Help’ details:
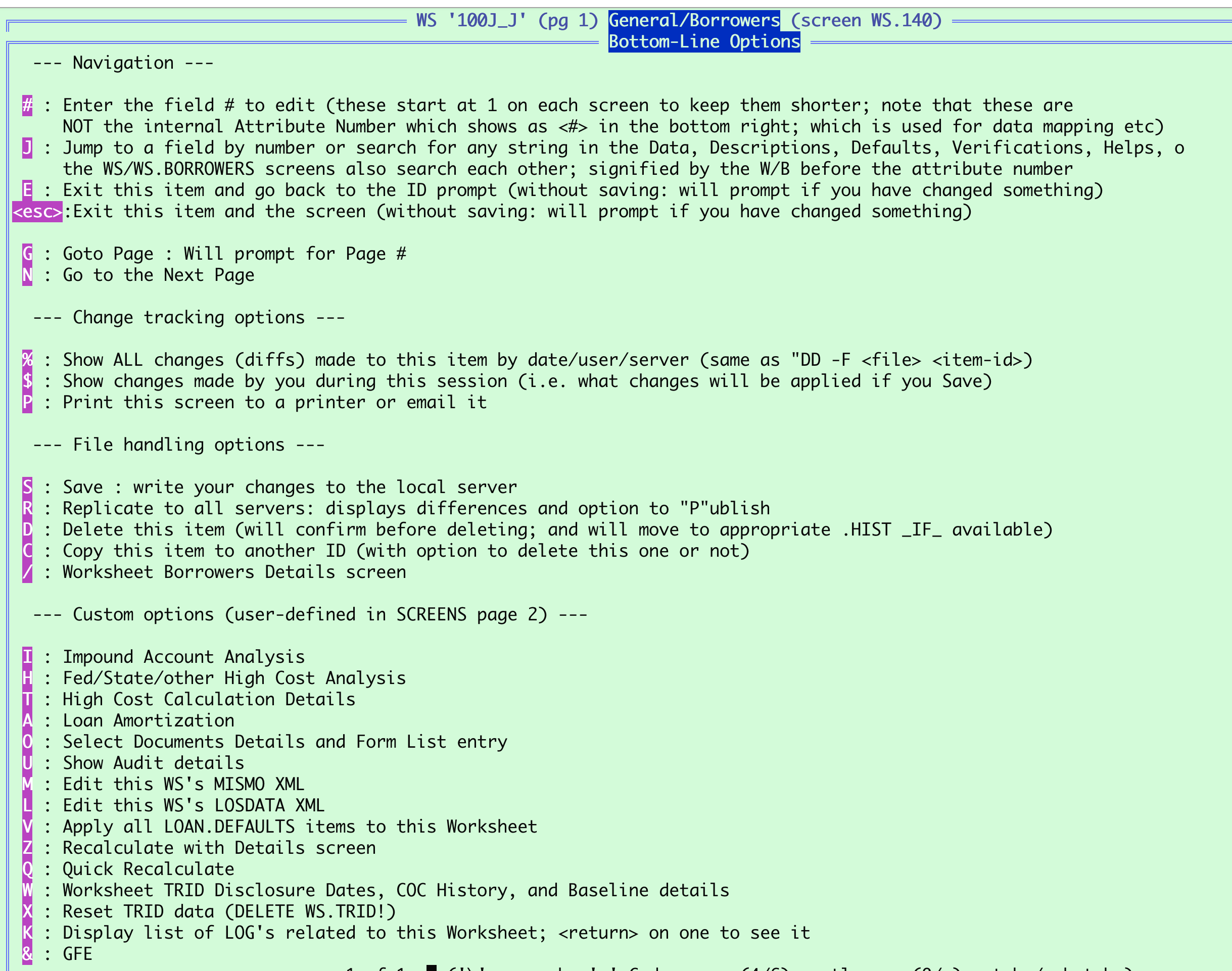
.
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/73e38e3a-7f7c-4a3e-a645-1a5081f18baan%40googlegroups.com.

Peter McMurray
002
003 * Caltex Transfer of Invoices to SAP
004 * oil
005 * 13:40:35 22 Jun 20172 pgm excalv10
006 INCLUDE A.BP A_EQU
007 A.PRASSIGN = "STANDARD\Caltex Transfer]"
008 INCLUDE A.BP A_PRINTCON
009 DIM A.FILNAM(10);MAT A.FILNAM = ''
010 A.FILNAM(1) = 'COMPANIES'
011 EQU COF TO A.FILES(1)
012 DIM COMPANY(52)
013 MAT COMPANY= ''
014 EQU SHCONAME TO COMPANY(1)
015 EQU CONAME TO COMPANY(2)
016 EQU COADD1 TO COMPANY(3)
Jim Idle
To view this discussion on the web visit https://groups.google.com/d/msgid/mvdbms/1cd35f81-a733-4027-a511-53f80f43080dn%40googlegroups.com.