Skip to first unread message

Cristina Ruth Santos
May 27, 2019, 9:37:22 AM5/27/19
to AtoM Users
Hi Dan,
We have a serious problem in the Institution One of the issues of the AToM is not well accepted are
1- The question of uploading images that would result in copies in the storage and this leads to a duplication of images leaving the storage without space (we have in our database to access 1,446,000,000 more or less of access derivatives;
2 - in terms of Brazil, and also in terms of documents we have in our National Archives of Brazil database, will AToM be able to process such information? The main "excuse" of IT, is that AToM would not account for the mass of information and digital objects associated with the descriptions.
Can this be true? I need to elucidate this so I can solve some "prejudices" around here.
Thanks
Cristina Ruth Santos
Arquivo Nacional do Brasil
DIBRARQ

Dan Gillean
May 27, 2019, 12:25:54 PM5/27/19
to ICA-AtoM Users
Hi Cristina,
Regarding the first question:
If your image server can make your images available online via a URL that ends in the file extension (e.g. .jpg, .mp4, etc) then you can use the link digital object option. When this is used, AtoM will not store a copy of the master digital object. Instead, it will generate a reference display copy (for the view description page) and a thumbnail (for search and browse results), but instead of storing the master, it will simply store the path to where the master can be found. See step 5 here:
Note that for a digital object to be linked via URL, several criteria must first be met:
- It must be publicly accessible so AtoM can fetch it - no login requirements, no firewalls or VPNs etc
- It must use an HTTP or HTTPS link - local filesystem paths or FTP links will not work with this method
- The URL provided must end in the file extension - that is, you need a link that points directly to the digital object, and not just to a page where the digital object appears.
Another option: in 2.5, if you have your images on a mounted image server accessible from your AtoM server, you could use the digital object load task, with the new --link-source option added in this release. This will make the load task treat the objects as if they were linked via URL - that is, AtoM will fetch the master to generate the derviatives, but after that it will discard the master and store the file path to the networked image server instead. See:
As for your second question, can you please clarify what you are asking? Is this about the amount of data, or the format of the data and whether you can import it into AtoM?
Cheers,
--
You received this message because you are subscribed to the Google Groups "AtoM Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/006c69e1-4a38-4ae6-832b-60db06e54947%40googlegroups.com.
Cris
May 27, 2019, 2:29:01 PM5/27/19
to Ica ATOM
Thaks Dan, for the quick response!
The Scalability of AtoM software in relation to SIAN (the AtoM would withstand the number of digital representatives of the National Archives both now and in the future.
Search via pdfs does not exist in AtoM, which would be a considerable loss of search capability, it's is true?
Search via pdfs does not exist in AtoM, which would be a considerable loss of search capability, it's is true?
This is the general quantitative document we have in our collection. Be textual, tridimsnional, cartographic, films, iconographic, souds ans microfilms. Not to mention, the digital and born digital files that we have already collected and will still collect.
Fonds / Collections - 946
Sections / Subsections - 69
Series / subseries - 470
Dossier / Process - 1,098,388 (460,843 with digital objects)
Items - 139,474 (6,038 with digital objects),
Sections / Subsections - 69
Series / subseries - 470
Dossier / Process - 1,098,388 (460,843 with digital objects)
Items - 139,474 (6,038 with digital objects),
I hope this helps!
Best regards
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZLZOcEUw3TgTXwQBUi1F%3DJ%3D2Zvv9D_5FKOFKdZG3Q5a8A%40mail.gmail.com.
Cristina R
Dan Gillean
May 28, 2019, 1:38:11 PM5/28/19
to ICA-AtoM Users
Hi Cristina,
Searching PDF text
Search via pdfs does not exist in AtoM, which would be a considerable loss of search capability, it's is true?
Actually, this is not the case. When a digital object with a text layer (such as a PDF) is imported into AtoM, the text layer is indexed and searchable. In fact, there is a field limiter in the Advanced search so you can restrict a search to just the text in a digital object:
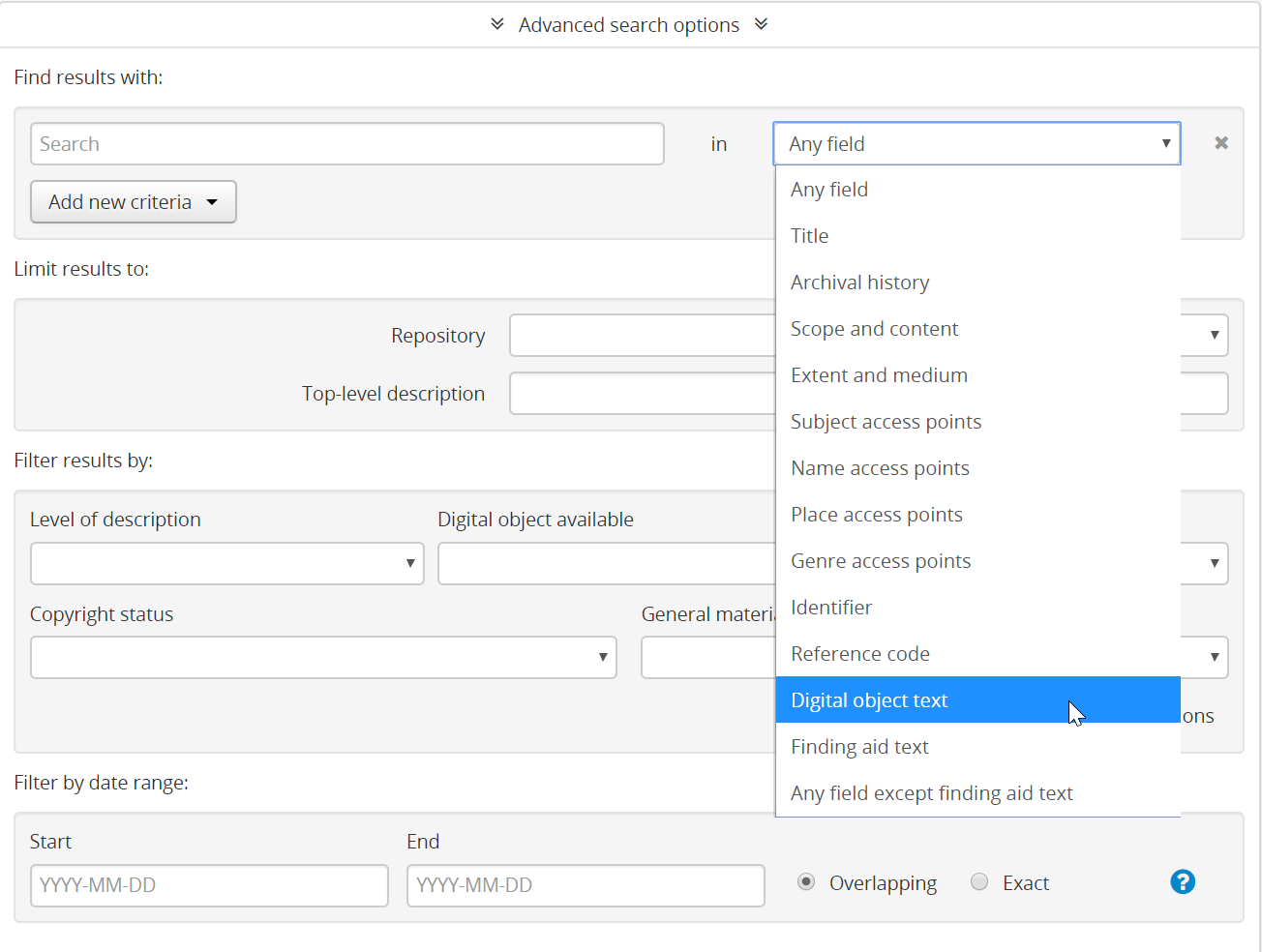
However, there are a couple things to keep in mind with this.
First, just because the text is OCR'ed, it doesn't mean it's good quality - especially with handwritten or older documents! I discuss this with an example in the following thread:
Second, AtoM's database currently has a size limit on the transcript field - this field is a TEXT type field in the property table, whose max length is currently set for 65,535 bytes. This would equal 65,535 characters for single-byte encoded characters (such as Latin-1 encoding), but AtoM uses UTF-8, in which characters can be 1-4 bytes, depending. Soooooooo.... it depends on the characters as to how much text that translates to, unfortunately. When the limit is surpassed, the transcript simply clips - the digital object will be saved, but it means that later pages in a very large PDF or text document may not in fact be searchable.
Scalability in general
AtoM should be able to scale to support millions of records. I would expect to run into issues after about ~2 million records, but even then there are workarounds. Much of it has to do with the deployment - the resources allocated, how you disperse and scale those resources, and also whether you use a 2-site deployment model, which can allow you to increase the caching and reduce the load on the public-facing front end. This has been discussed in the forum recently here:
I know of at least one AtoM site (that is unfortunately not public, so I cannot share) that was heavily modified locally and currently supports 9 million records - but this is an extreme example, and most users would run into major scalability issues beyond about 1-2 million records.
We also continue to add performance and scalability enhancements and code optimizations in each release. At some point we will reach the limit of what we can do without completely rewriting AtoM the ORM included in Symfony 1.x is one of AtoM's biggest bottlenecks currently), but we are considering massive scalability as an important design factor as we evaluate options for AtoM3 - and we intend to ensure that there is an upgrade path from AtoM 2 to AtoM3 when it is finally developed.
So yes - it is not a perfect solution, and you may run into problems as you add millions of records. Many of these can be solved or worked around depending on your deployment and the resources allocated, but AtoM itself, like many web-based applications, may eventually have issues. I hope that perhaps this will at least allow to better evaluate your options and determine if AtoM will meet your needs.
Cheers,
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAA3V%3DduowRTNVyAZO0gKCxZcXipBwcyiAiYjUOjtP_WFCjnMmw%40mail.gmail.com.
Cris
May 28, 2019, 1:50:54 PM5/28/19
to Ica ATOM
Dan, Thank you very much for your attention!! The Directory continues with much work and dedication. Let's go ahead and help us the best way possible.
Best regards
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/CAC1FhZJbV0M4s0N17AxxqKrf6ixQaDGzdOf%2BAGnapdEv3zCR2Q%40mail.gmail.com.
Cristina R
Reply all
Reply to author
Forward
0 new messages