Skip to first unread message

L Snider
Jun 5, 2016, 5:30:40 PM6/5/16
to ica-ato...@googlegroups.com
Hi Everyone,
I was wondering if anyone on the list had ingested InMagic records into AtoM. If you have, would you mind sharing what you did? There is someone that is wanting to do this, and I have thought of a couple of ways, but I would rather not invent the wheel if others have done it.
thearch...@gmail.com
Jun 7, 2016, 10:12:53 AM6/7/16
to ICA-AtoM Users
Hi Lisa!
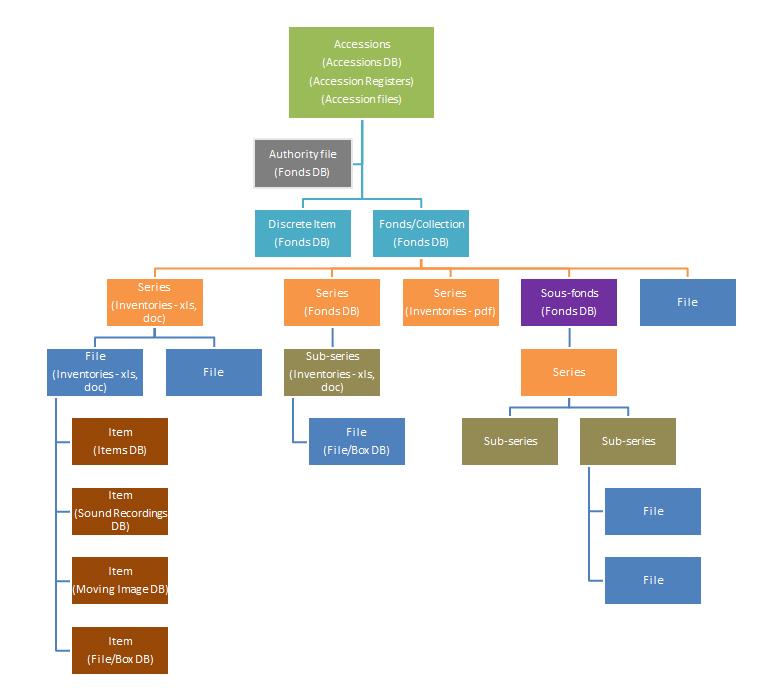
This is precisely what we have done (and are continuing to do). There are a few different ways to get data from one to the other, and we started out with a slightly more complex method (perhaps an understatement) way back before the days of csv importing. The attached diagram shows all the sources we are moving into AtoM, where each of the parenthetical statements identifies the source - those identified as DB are InMagic textbases. Our main method was to export from InMagic into XML, conduct a number of cleanup procedures, then run a PERL script to connect previously unconnected data from the Fonds level (turquoise in the diagram) down through the xls inventories to the File/Box DB (item-level data - brown in the diagram) - the script links three separate sources and produces EAD records. For further details on this exact procedure, you can take a look at the second document I have attached. Depending on the structure of your original data, it may be possible to adjust the scripts we wrote to use in your case (and I'm happy to share)...but I suspect you might have better success with the second option.
This second option would be to export your InMagic data to Delimited ASCII Format, import this data into Excel, and adjust each field (column) in preparation for csv import. You could probably automate these adjustments in some fashion using Google Refine, or even with some of the concatenation or search/replace features in Excel (depending on how you need to massage the data for import). Using the csv templates as a guide (https://wiki.accesstomemory.org/Resources/CSV_templates), it should be fairly easy to map out the crosswalks from your InMagic field names to the AtoM fields.
I hope this helps!
Jeremy
---------------------------------
Jeremy Heil
Digital and Private Records Archivist, Queen's University
This is precisely what we have done (and are continuing to do). There are a few different ways to get data from one to the other, and we started out with a slightly more complex method (perhaps an understatement) way back before the days of csv importing. The attached diagram shows all the sources we are moving into AtoM, where each of the parenthetical statements identifies the source - those identified as DB are InMagic textbases. Our main method was to export from InMagic into XML, conduct a number of cleanup procedures, then run a PERL script to connect previously unconnected data from the Fonds level (turquoise in the diagram) down through the xls inventories to the File/Box DB (item-level data - brown in the diagram) - the script links three separate sources and produces EAD records. For further details on this exact procedure, you can take a look at the second document I have attached. Depending on the structure of your original data, it may be possible to adjust the scripts we wrote to use in your case (and I'm happy to share)...but I suspect you might have better success with the second option.
This second option would be to export your InMagic data to Delimited ASCII Format, import this data into Excel, and adjust each field (column) in preparation for csv import. You could probably automate these adjustments in some fashion using Google Refine, or even with some of the concatenation or search/replace features in Excel (depending on how you need to massage the data for import). Using the csv templates as a guide (https://wiki.accesstomemory.org/Resources/CSV_templates), it should be fairly easy to map out the crosswalks from your InMagic field names to the AtoM fields.
I hope this helps!
Jeremy
---------------------------------
Jeremy Heil
Digital and Private Records Archivist, Queen's University
{kind=link}
L Snider
Jun 7, 2016, 8:03:07 PM6/7/16
to ica-ato...@googlegroups.com
Hi Jeremy,
Thanks so much! I knew some people had done it, so I appreciate you sharing that with me. --
You received this message because you are subscribed to the Google Groups "ICA-AtoM Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ica-atom-user...@googlegroups.com.
To post to this group, send email to ica-ato...@googlegroups.com.
Visit this group at https://groups.google.com/group/ica-atom-users.
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/5569b8f4-2f92-437d-ba07-3b4a77821980%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
L Snider
Jun 9, 2016, 7:40:40 AM6/9/16
to ica-ato...@googlegroups.com
Hi Jeremy,
One more follow up question...Were you working with .dmp files?On Tue, Jun 7, 2016 at 9:12 AM, <thearch...@gmail.com> wrote:
--
L Snider
Jun 9, 2016, 7:44:38 AM6/9/16
to ica-ato...@googlegroups.com
Oh and just to clarify, it looks like you did use .dmp files, but I just wanted to confirm!
thearch...@gmail.com
Jun 9, 2016, 12:32:05 PM6/9/16
to ICA-AtoM Users
Hi Lisa,
They are .dmp files - the delimited ASCII dmp is basically a csv file - even just changing the file name from dmp to csv will display it correctly in Excel...not that I'm advocating that :)
I have also attached a PDF version of our procedures document, which should fill in any of the gaps you may have encountered in the odt version.
Cheers,
Jeremy
They are .dmp files - the delimited ASCII dmp is basically a csv file - even just changing the file name from dmp to csv will display it correctly in Excel...not that I'm advocating that :)
I have also attached a PDF version of our procedures document, which should fill in any of the gaps you may have encountered in the odt version.
Cheers,
Jeremy
Lisa Snider
Jun 9, 2016, 12:37:45 PM6/9/16
to ica-ato...@googlegroups.com
Hi Jeremy,
Thanks so much, really appreciate the information.
I had never come up against .dmp files, except way back with Oracle, so I am learning more about them now!
Thanks again!
Cheers
Lisa
Sent from my iPhone
Sent from my iPhone
To view this discussion on the web visit https://groups.google.com/d/msgid/ica-atom-users/994e8c8d-bfc9-441b-bd1a-7de78f8a5eb7%40googlegroups.com.
<Atom-Import_procedures.pdf>
Reply all
Reply to author
Forward
0 new messages