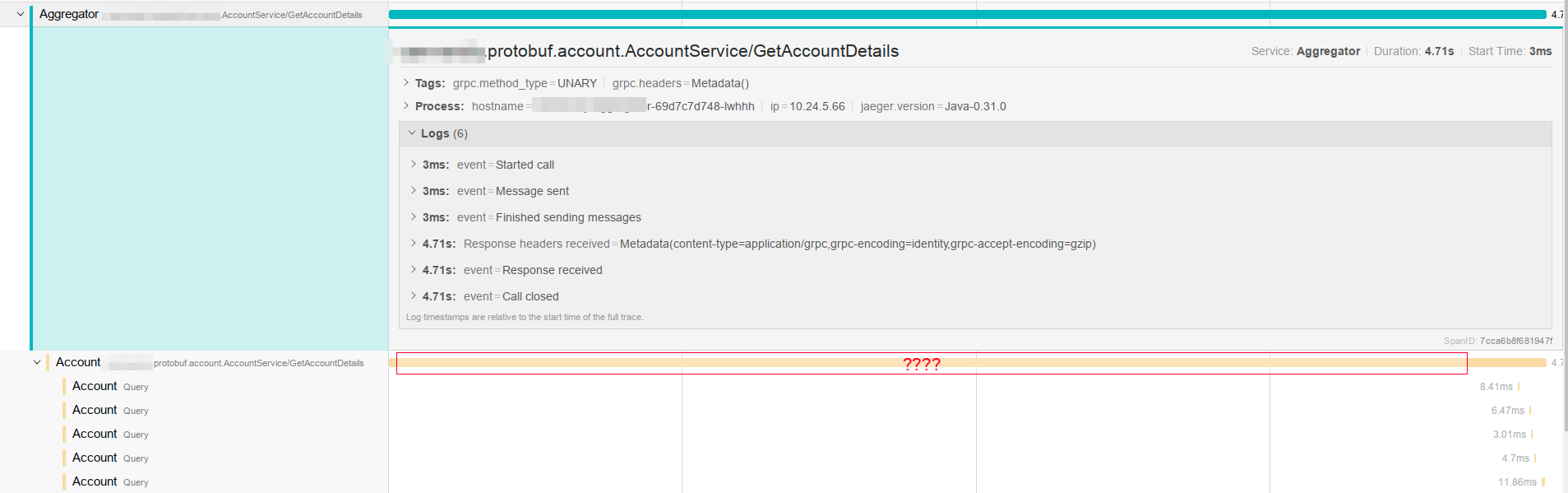
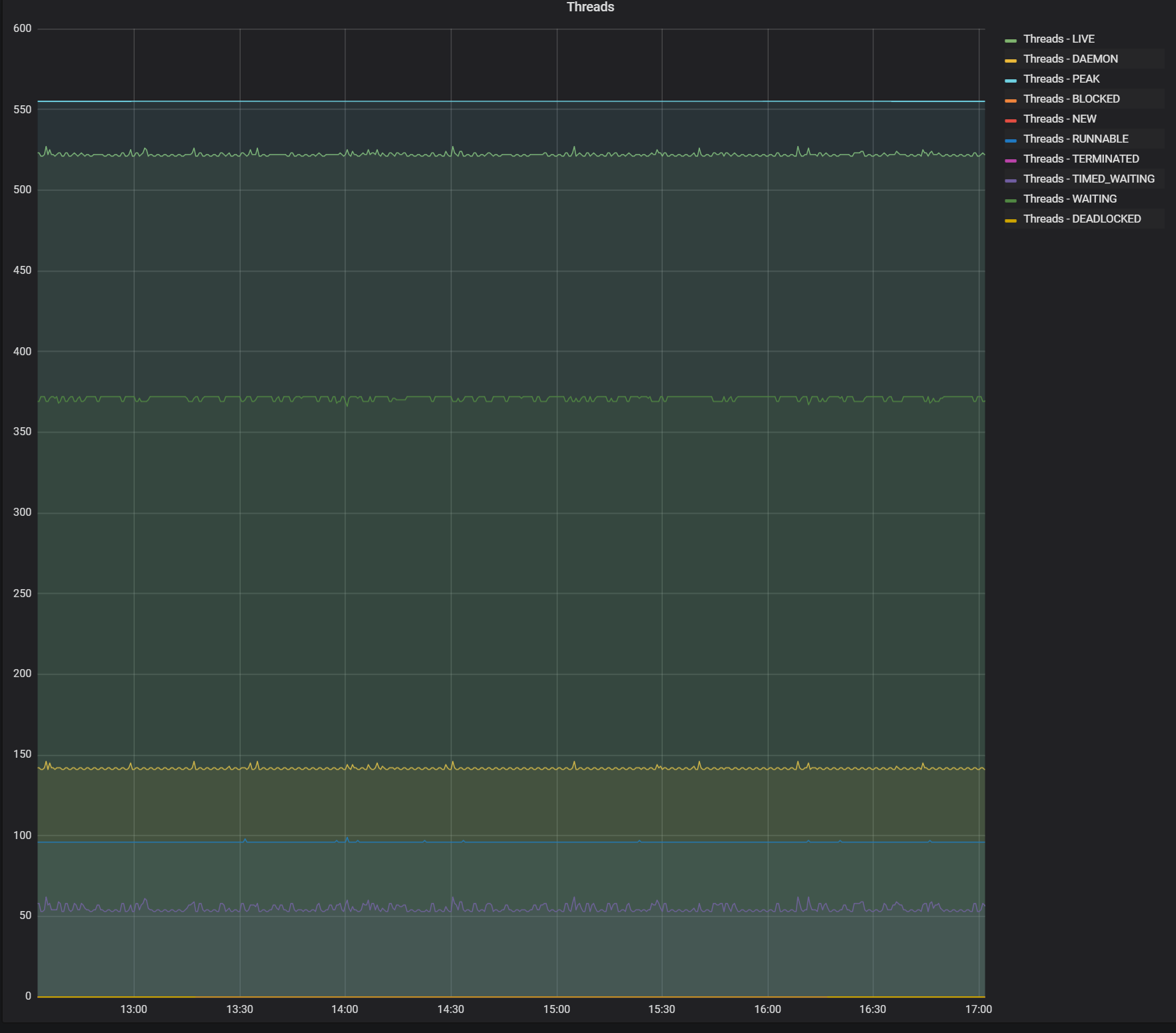
[gRPC Java] need help to diagnose weird stall in grpc call

ake...@pitechnologies.ro

Robert Engels
--<Selection_120.png>
You received this message because you are subscribed to the Google Groups "grpc.io" group.
To unsubscribe from this group and stop receiving emails from it, send an email to grpc-io+u...@googlegroups.com.
To post to this group, send email to grp...@googlegroups.com.
Visit this group at https://groups.google.com/group/grpc-io.
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/3f8075e1-e261-45c9-865f-23285b98cca9%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
<Selection_120.png>
Alexandru Keszeg
Alexandru Keszeg Developer Coratim Business Center Campul Painii nr.3-5 Cluj Napoca ROMANIA |

This message (including any attachment(s)) may be copyright-protected and/or contain privileged and confidential information intended for use by the above-mentioned recipient only. If you are not the intended recipient of this message, then please inform the sender immediately via the telephone number, fax number or e-mail address indicated above and promptly delete this message from your system. Any unauthorized copying, disclosure to third parties or use of this message (including any attachment(s)) is strictly prohibited. It is generally accepted that the security of electronic communications is not failsafe. Despite our best efforts, we cannot guarantee that electronic communications received were in fact sent by the purported sender and we shall not be liable for the improper or incomplete transmission of the information contained in this communication, nor for any delay in its receipt or damage to your system.
Robert Engels
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/CACekFaEPNG6ZhXEZgyY-YwyNSE2V-aAgcsnCGcvN_nb13ovipg%40mail.gmail.com.
Robert Engels
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/FFD79299-249F-47F3-88D8-3251B378B023%40earthlink.net.

namle...@gmail.com
final NettyChannelBuilder channelBuilder = NettyChannelBuilder.forAddress(getHost(), getPort())
.usePlaintext(grpcProperties.isUsePlainText())
.loadBalancerFactory(RoundRobinLoadBalancerFactory.getInstance())
.intercept(getClientInterceptors());
addConnectionPersistenceConfig(channelBuilder);
if (grpcProperties.isEnableClientFixedConcurrency()) {
channelBuilder.executor(Executors.newFixedThreadPool(grpcProperties.getClientThreadNumber()));
}
this.channel = channelBuilder.build();
...
private void addConnectionPersistenceConfig(final NettyChannelBuilder channelBuilder) {
if (grpcProperties.getClientKeepAlive() != 0) {
channelBuilder
.keepAliveTime(grpcProperties.getClientKeepAlive(), SECONDS) // 5
.keepAliveWithoutCalls(grpcProperties.isClientKeepAliveWithoutCalls()) //true
.keepAliveTimeout(grpcProperties.getClientKeepAliveTimeout(), SECONDS); //60
}
if (grpcProperties.getClientIdle() != 0) {
channelBuilder.idleTimeout(grpcProperties.getClientIdle(), SECONDS); //60
}
}
I have added the relevant bits of code that build the client, i think it should reuse the connection.
Robert Engels
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/d3ae5c74-98db-430f-b750-7676170f407c%40googlegroups.com.
Alexandru Keszeg
You received this message because you are subscribed to a topic in the Google Groups "grpc.io" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/grpc-io/D2lsL82beCs/unsubscribe.
To unsubscribe from this group and all its topics, send an email to grpc-io+u...@googlegroups.com.
To post to this group, send email to grp...@googlegroups.com.
Visit this group at https://groups.google.com/group/grpc-io.
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/092D7CAA-6C58-44C9-8194-E0AA9C75BC41%40earthlink.net.
For more options, visit https://groups.google.com/d/optout.
Robert Engels
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/CACekFaGkp9uZkE_bt%2BD%2BsJFAOp4bJfeTXfpS9Hn4%3DGq6a0Ky9g%40mail.gmail.com.
Robert Engels
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/20156BC2-BA04-4A7C-9D57-7FC3C0D6319E%40earthlink.net.

to...@spotify.com
Alexandru Keszeg
To view this discussion on the web visit https://groups.google.com/d/msgid/grpc-io/c82aa2b5-7965-44be-9e19-00430b5a82f7%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.