Unix Socket sometimes not present
371 views
Skip to first unread message

Myles Bostwick
Dec 5, 2016, 1:02:56 PM12/5/16
to Google Cloud SQL discuss
Hello All,
I've been playing around with the pipelines library (https://github.com/GoogleCloudPlatform/appengine-pipelines) in my standard appengine environment and managed to get enough parallel instances running to cause problems. Sometimes, persistent to an instance it seems, I don't have a unix socket (as seen in the below stacktrace). Things I have tried to mitigate this:
- On failed connect, try 3 times with 4 seconds between attempts (since I have a 60 second max request time, this seems HUGE)
- Reducing concurrent requests per instance to 8
- Reducing max concurrent requests to 20
- Upgrading from First Generation to Second Generation Cloud SQL instances
- Restricting to a single instance (which does "solve" the problem, but doesn't meet my throughput goals)
I've consistently been able to reproduce this issue, in its inconsistent nature. My final recourse is going to be wait the 3 times, then connect via IP instead. Any thoughts suggestions in addition to this would be greatly appreciated.
Thanks in advance,
Myles

paynen
Dec 6, 2016, 3:44:54 PM12/6/16
to Google Cloud SQL discuss
Hey Myles,
An issue like this would be best reported in the Public Issue Tracker for Cloud SQL.
Nonetheless, we can continue to work on it here until we can determine more accurately what should go in the report. There are some more pieces of information that could be relevant here:
* The patterns and frequencies of connections on your instances
* The way in which you've determined it's isolated to a given instance
* A description of the pipeline task you're performing so we can attempt to reproduce the issue that way
An issue like this would be best reported in the Public Issue Tracker for Cloud SQL.
Nonetheless, we can continue to work on it here until we can determine more accurately what should go in the report. There are some more pieces of information that could be relevant here:
* The patterns and frequencies of connections on your instances
* The way in which you've determined it's isolated to a given instance
* A description of the pipeline task you're performing so we can attempt to reproduce the issue that way
Feel free to add any more information you think could help in reproducing this issue.
Regards,
Nick
Cloud Platform Community Support
Regards,
Nick
Cloud Platform Community Support
Myles Bostwick
Dec 8, 2016, 4:25:58 PM12/8/16
to Google Cloud SQL discuss
Hi Nick,
I appreciate you getting back to me.
I've attached an example that produces the behavior, through testing I've come to better understand a little what's going on. Once reaching a certain rate, while processing mysql is under load, the error is returned. Originally I created an example that just sent "SELECT 1" to mysql and could not induce the error, so MySQL has to be under some load.
The example I've attached induces the error, though there are two classes of errors:
1. The "No such file" error I've originally reported
2. The understandable Deadlock error from mysql
I'm not concerned about #2 as that's just a SQL optimization I've already taken care of, but I still receive the "No such file" error in my production code without a single deadlock error.
"The patterns and frequences of connections on your instances"
I have a taskqueue that is setup to process all my sql connections, so that 1, requests aren't hampered by SQL operations and 2, we can rate limit the interactions with MySQL. My autoscale settings are set to restrict to 6 connections, due to the 12 connection limit, I wanted to give it some room.
"The way in which you've determined it's isolated to a given instance"
I don't think I was clear when I described this, once an instance starts exhibiting this symptom, subsequent requests to the instance all exhibit the symptom. I determined this just by checking the instance id in the log messages and through restricting to a given instance id.
Hopefully my attached example will enable reproduction. It's a little messy because I consolidated several files into one file for ease of transport, but it should be fairly straightforward.
Let me know if you need me to file this away to the issue tracker you mentioned, I'm happy to do so.
Cheers,
Myles
Myles Bostwick
Dec 9, 2016, 3:20:17 PM12/9/16
to Google Cloud SQL discuss
Hi Nick,
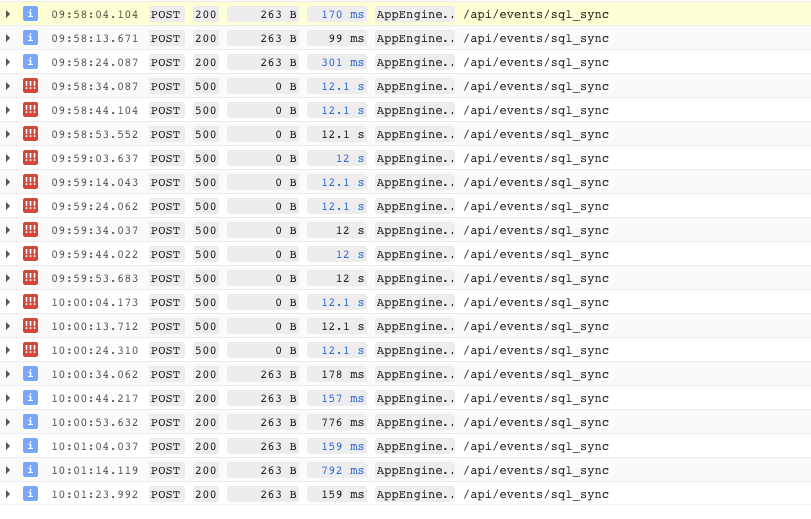
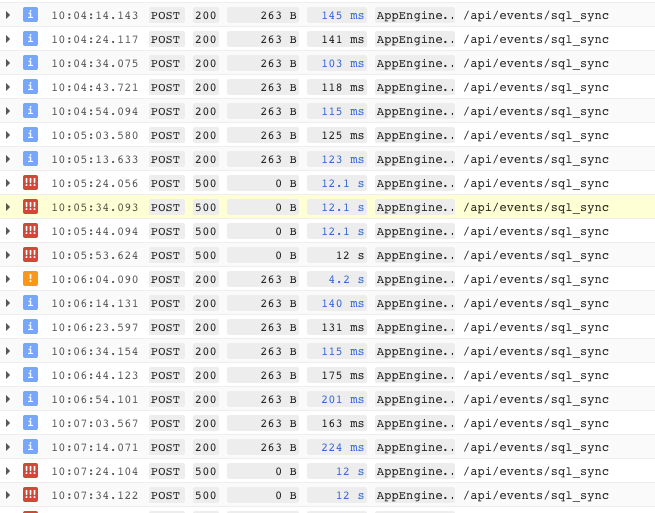
I've been continuing to further isolate the problem by reducing the rate at which I process data. The error appears to fluctuate on an instance when at a slower rate (in this case 6/m). I've attached some screenshots of my log, on one instance. The info messages are successful calls, the warnings are failed in at least one connection attempt and the criticals are failed in all three attempts to connect. I am still seeing a pretty high failure rate of around 30-40 percent vs about 50% at a rate of 10/s. At this point I don't have a theory as to what is happening, 6/m is about 2 orders of magnitude slower than our ideal rate of 10/s.
I'm going to try 2 more tests
1. Change MySQLdb to version 1.2.4 and 1.2.5 (presently at "latest" which is 1.2.4b4 apparently)
2. Try these iterations on CloudSQL First Generation now that the inefficient SQL is no longer present.
Thanks again for looking, I hope we can get to a solution on this.
Cheers,
Myles
{kind=link}
{kind=link}
{kind=link}
paynen
Dec 19, 2016, 4:33:04 PM12/19/16
to Google Cloud SQL discuss
Hey Myles,
You've done an extraordinary job in cataloging the information needed to look into this further. Apologies that I've not got anything definitive to relate, as I'm in the process of attempting to replicate this behaviour. It appears to be related to connection pooling, although I'm not sure exactly how. I hope to update this thread within the next 2 days with more information.
You've done an extraordinary job in cataloging the information needed to look into this further. Apologies that I've not got anything definitive to relate, as I'm in the process of attempting to replicate this behaviour. It appears to be related to connection pooling, although I'm not sure exactly how. I hope to update this thread within the next 2 days with more information.
Regards,
Nick
Cloud Platform Community Support
paynen
Dec 21, 2016, 7:42:16 PM12/21/16
to Google Cloud SQL discuss
Hey Myles,
Other than the hint on connection pooling, I've been unable to reproduce the issues you've seen, despite using a pooled connection as well. Is this still occurring despite switching to a non-pooled connection model?
Other than the hint on connection pooling, I've been unable to reproduce the issues you've seen, despite using a pooled connection as well. Is this still occurring despite switching to a non-pooled connection model?
Regards,
Nick
Cloud Platform Community Support
Adam (Cloud Platform Support)
Jan 2, 2017, 5:29:19 PM1/2/17
to Google Cloud SQL discuss
I've tried reproducing this myself using your code and haven't seen the 'No such file or directory' error either. The only errors I see are (normal) errors about 'Deadlock found when trying to get lock' due to all the concurrently executing transactions and 'Transport endpoint is not connected' once I reach about 5k tasks and 10+ instances saturating all available concurrent connections.
Perhaps I'll simply need to wait until I get a 'bad' instance, but so far it hasn't occurred.
Myles Bostwick
Jan 3, 2017, 6:07:46 PM1/3/17
to Google Cloud SQL discuss
Hi Adam and Nick,
Thanks for the replies and sorry for my delayed response, I've been on a bit of vacation.
Nick, I agree with your findings, I've attached a slightly updated example file (simpler queries) that has the ability to run with MySQLdb directly and with SqlAlchemy and the error doesn't exhibit when running MySQLdb directly, but it does while running SqlAlchemy, even with the NullPool ConnectionPool.
However, as Adam correctly points out, the error message is no longer "No such file or directory", but now "Transport endpoint is not connected". I have an example that I've been running since the start, previously giving the stacktrace I originally posted, that is now giving this "Transport endpoint is not connected" instead. I haven't changed anything on my end, so I have to assume in the weeks that I've been working on this problem something has changed on the google end.
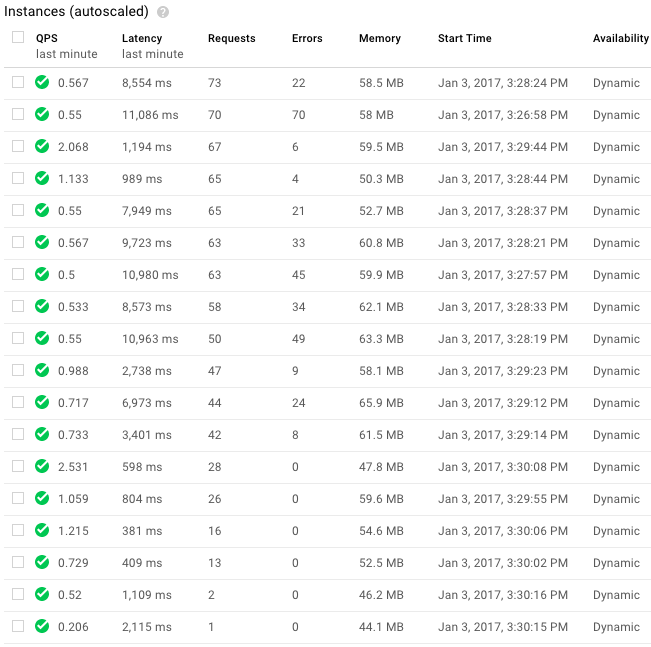
Adam, to your statement that "all available concurrent connections" are saturated. My reading of the documentation stated I should be able to have about 4000 concurrent connections (https://cloud.google.com/sql/faq#sizeqps). When limiting my "max_concurrent_requests" to 72 I am seeing the attached error rates across 18 instances (since my instances is limited to a max of 6 simultaneous requests). It seems like this should be well below the 4000 connection limit, by a couple of orders of magnitude, and yet I am still seeing this error occur. You also mentioned getting 5k tasks in the queue, if the queues are rate limited/concurrent request limited, the size of the queue backlog shouldn't have any effect on concurrent sql connections correct? Or am I misunderstanding something here?
Also, just to clarify, I don't believe there to a "bad" instance floating around out there. Initially, I did not see instances "recover" with subsequent requests, but a slower rate (of about 6/m) proved that bit of information to be incorrect. You can however see by my attached screenshot, that instances vary in their error rate.
I really appreciate the both of you getting back to me and Nick for sticking with this for so long. Unfortunately, work priorities have come up and since I have a work around with the MySQLdb route, I'm going to just take SqlAlchemy out of the mix and move forward with the working solution. If there are other contributions I can make in my spare time, let me know and I'll happily help. Otherwise, this is me "signing off".
Cheers,
Myles
{kind=link}
Adam (Cloud Platform Support)
Jan 6, 2017, 8:05:19 PM1/6/17
to Google Cloud SQL discuss
The 4000 concurrent connection limit is the maximum limit imposed by the platform infrastructure, however this can be much higher than what (for example) a single N1_Standard_1 database instance can handle at a given time (this will vary further based on the storage size which affects the number of IOPS, and what the database is actually doing as a result of each connection). An overloaded instance can still drop connections.
I mentioned that it happened when I reached about 5k tasks enqueued, but didn't mean to imply all of these were executing concurrently. With my queue and scaling settings I ended up with about ~120 - 150 concurrent requests from 13 instances. Setting a smaller pool size of about 5 seemed to reduce the frequency of errors, but evidently this was still enough to bring my puny test instance to its knees.
The reason I mentioned "bad" instance is because the original problem statement suggested that the UNIX socket itself didn't exist on specific instances, and that the issue seemed persistent to an instance.
In any case, I'm glad to hear this seems to be specific to SQLAlchemy and that you were able to work around it.
Reply all
Reply to author
Forward
0 new messages