Task Queue Latency
186 views
Skip to first unread message

Jim
Dec 1, 2015, 11:03:25 AM12/1/15
to Google App Engine
Hello,
Has anyone else noticed a lot of latency in Task Queues within the past few days? We've noticed that our push queues are backing up with thousands, sometimes tens of thousands of tasks. Nothing has changed in our app or traffic profile. Over the past few days we've seen several instances where the queues just seem to stop "pushing" tasks and they fill up. We can go in and manually trigger individual tasks to run; tasks are not generating errors, they're just not running automatically like they should based on our configuration. Eventually things seem to catch up again. Anyone else seeing similar behavior?
Jim

David Fischer
Dec 1, 2015, 12:11:14 PM12/1/15
to Google App Engine
I'm seeing something similar. Our task queues are also filling up with tasks and our traffic hasn't changed. For us, it looks like this started about a week ago. Our tasks are not generating more errors than normal.
Our tasks are run by different instances than our front-end website. Our backend instances are shutting down and restarting a lot more than normal which seems odd. Whenever I look at "instances" in my dashboard, it looks like all my instances have been started in the last 10 minutes or so. Memory usage is well within normal limits and I'm not seeing the instances generating errors or anything.
Jim
Dec 1, 2015, 12:50:05 PM12/1/15
to Google App Engine
I'm seeing the same thing on our instances... they all seem to have been started in the last few minutes... 10 minutes tops. Lots of churn on the instances.

Rene Marty
Dec 1, 2015, 10:43:13 PM12/1/15
to Google App Engine
I have experienced exactly the same problem since two weeks ago. I have a system with 100 restaurantes and 1000 users working without problem, but suddenly, since two weeks ago, every day at rush hour, the tasks in the task queue have experience a long delay in their start, two weeks before was only 1 or 2 seconds, now if 15 to 60 seconds, impacting the user experience and usability. I have to modify all the code with taskqueues and changing it to urlfetch request async qithout waiting for the rpc. The worst is that the task are causing a dealine exeeded 123 error, losing between 50 to 1000 request every day. The task and my proceses are very fast, the last only from 50ms to 3 seconds, not more, but I get a lot of them with 60000ms and more and get cancelled without starting (i have logging.debug message at the very begiining of every task/process that never get executed). I have 2 idel instances and all the settings to increase the instances without restriction. The start time of my instacnes is only 1 second, there are no special processes in the booting. I have 6 modules, separated modules for the task and the problem is affecting the module that call the task.add (not the module that executes the task). I made all the changes to avoid datastore contention, I deactivated the logs, I use a lot the memcache, I changed the F1 instances to F2, ant this error continues. And it APPEARED TWO WEEKS AGO. I have 1 year and a half runing my app, without problems, and suddenly this problem appeared.
This is a HUUUUGE problem, it make me thing about quit GAE and search another provider if I don't get a solution and explanation soon. My customers are very angry and everyday I loose requests (deadline exceeded error, I receive 2 or 3 phone calls). My system is mission critical and 1 munute without answers to request make my customer lose money.
If any google engineer wants more detailed, I kindly offer all my support, I'm engineer with near 30 years experience and 3 years working with GAE Python and many Google Tools (Angular, Firebase, GCP, etc). I can bet that the problem is more related to the platform than to my code.
Rene Marty

{kind=link}
John Wheeler
Dec 2, 2015, 9:40:24 AM12/2/15
to Google App Engine
Whew! So it's not just me then. I've got exactly the problem.
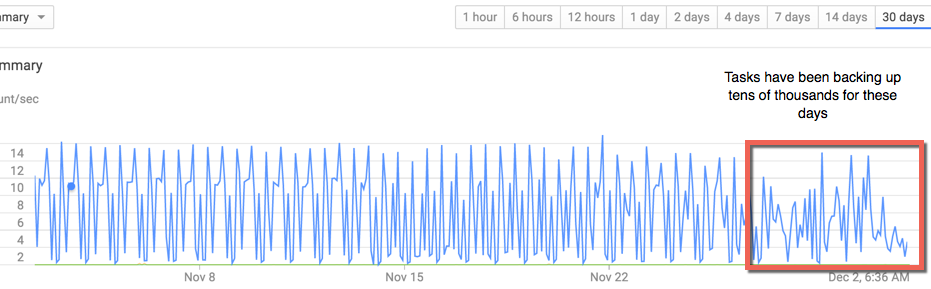
I've attached a picture of my dashboard graph for the last 30 days which you can see very regular peaks at the beginning turn into irregularity since I've been experiencing issues with task queues.
John
On Tuesday, December 1, 2015 at 8:03:25 AM UTC-8, Jim wrote:
{kind=link}
Jim
Dec 2, 2015, 2:55:04 PM12/2/15
to Google App Engine
Can anyone from Google comment on this?
David Fischer
Dec 2, 2015, 7:05:45 PM12/2/15
to Google App Engine
I think this is the status for this event: https://status.cloud.google.com/incident/appengine/15024
Jim
Dec 3, 2015, 11:09:28 AM12/3/15
to Google App Engine
David, thanks I think you're right that looks like the issue.
Google, it sure would be nice if the status page was more granular and showed the status of the task queue separately like it does the datastore and cloud storage. Task Queues are a critically important part of our application architecture and having zero visibility into issues related to them is really a pain when things like this happen. It's understandable that issues occur, but it sure would be nice to be able to know that Google engineers are aware of them and are working on them without poking around blind.
Rene Marty
Dec 3, 2015, 12:07:22 PM12/3/15
to Google App Engine
Dear Google Team,
Rene Marty
I send this issue three weeks ago to one of your developers advocates. I'm very experienced in GAE (three years developing mission critical apps) and if you need my support or testing, it will be a pleasure.
I think there are two issues with the taskqueue:
1) The start of execution is delayed, between 15 and 120 seconds from the estimated time of execution. Until three weeks ago, it was inmediate, only 1 or 3 seconds of delay at rush hour.
2) When the task is being filled with processes not starting, the process that called the taskqueue.add(...) freezes waiting for the response, and subsecuents request to the same instance fails and causes a Deadline Exceeded 123 error. I discover that this is the cause beacuse when I replaced all the taskqueue.add(...) to async urlfetch.make_fetch_call(...) without waiting for the rpc result, I never get again that Deadline Exceeded 123 error.
Please try to solve this issue ASAP. The taskqueue functionality is critical for many developers trying to offer a good sutomer experience. If this becomes unstable, we will need to look another platforms more robust, I'm a big fan of Google, but I don't want loose customers due to platform issues. At the end, my clients blame my company not to Google for these problems...
Thanks,
Rene Marty
Jim
Dec 3, 2015, 12:21:08 PM12/3/15
to Google App Engine
We have been seeing latency of 5 hours or more at times, although it seems to be functioning normally today.
David Fischer
Dec 3, 2015, 7:52:06 PM12/3/15
to Google App Engine
We are also seeing fairly normal operation today.
John Wheeler
Dec 3, 2015, 8:06:05 PM12/3/15
to Google App Engine
Yes back to normal here too
On Tuesday, December 1, 2015 at 8:03:25 AM UTC-8, Jim wrote:
Rene Marty
Dec 4, 2015, 4:00:18 PM12/4/15
to Google App Engine
No news today.. (Google Team promised news at 10:00 but nothing until now, 13:00 US Pacific Time)
Reply all
Reply to author
Forward
0 new messages