GroupBy query hung in Historical server
119 views
Skip to first unread message

ling...@gmail.com
Apr 6, 2022, 12:03:04 AM4/6/22
to Druid User
Hi All,
We found some native groupby queries hung in historical server and caused query timeout.
All these query threads hung in the same place and took up all merge buffers, then we had to restart the historical server.
Anyone encountered this issue? We are on 0.21.0.
Here's the thread dump took after several hours since the timeout happened:
"groupBy_***_[2022-03-06T09:45:00.000Z/2022-03-06T11:15:00.000Z]" #182 daemon prio=5 os_prio=0 tid=0x00007e931c0b8800 nid=0xe30f runnable [0x00007e925faf9000]
java.lang.Thread.State: RUNNABLE
at org.apache.druid.query.groupby.epinephelinae.collection.MemoryOpenHashTable.clear(MemoryOpenHashTable.java:154)
at org.apache.druid.query.groupby.epinephelinae.collection.MemoryOpenHashTable.<init>(MemoryOpenHashTable.java:114)
at org.apache.druid.query.groupby.epinephelinae.HashVectorGrouper.reset(HashVectorGrouper.java:214)
at org.apache.druid.query.groupby.epinephelinae.vector.VectorGroupByEngine$VectorGroupByEngineIterator.hasNext(VectorGroupByEngine.java:303)
at org.apache.druid.java.util.common.guava.BaseSequence.accumulate(BaseSequence.java:43)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.LazySequence.accumulate(LazySequence.java:40)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.MappedSequence.accumulate(MappedSequence.java:43)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.LazySequence.accumulate(LazySequence.java:40)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner$1.accumulate(SpecificSegmentQueryRunner.java:87)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner.doNamed(SpecificSegmentQueryRunner.java:171)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner.access$100(SpecificSegmentQueryRunner.java:44)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner$2.wrap(SpecificSegmentQueryRunner.java:153)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.query.CPUTimeMetricQueryRunner$1.wrap(CPUTimeMetricQueryRunner.java:78)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.query.groupby.epinephelinae.GroupByMergingQueryRunnerV2$1$1$1.call(GroupByMergingQueryRunnerV2.java:246)
at org.apache.druid.query.groupby.epinephelinae.GroupByMergingQueryRunnerV2$1$1$1.call(GroupByMergingQueryRunnerV2.java:233)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.druid.query.PrioritizedListenableFutureTask.run(PrioritizedExecutorService.java:247)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- <0x00000001c102ba20> (a java.util.concurrent.ThreadPoolExecutor$Worker)
java.lang.Thread.State: RUNNABLE
at org.apache.druid.query.groupby.epinephelinae.collection.MemoryOpenHashTable.clear(MemoryOpenHashTable.java:154)
at org.apache.druid.query.groupby.epinephelinae.collection.MemoryOpenHashTable.<init>(MemoryOpenHashTable.java:114)
at org.apache.druid.query.groupby.epinephelinae.HashVectorGrouper.reset(HashVectorGrouper.java:214)
at org.apache.druid.query.groupby.epinephelinae.vector.VectorGroupByEngine$VectorGroupByEngineIterator.hasNext(VectorGroupByEngine.java:303)
at org.apache.druid.java.util.common.guava.BaseSequence.accumulate(BaseSequence.java:43)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.LazySequence.accumulate(LazySequence.java:40)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.MappedSequence.accumulate(MappedSequence.java:43)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.LazySequence.accumulate(LazySequence.java:40)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.java.util.common.guava.SequenceWrapper.wrap(SequenceWrapper.java:55)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner$1.accumulate(SpecificSegmentQueryRunner.java:87)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner.doNamed(SpecificSegmentQueryRunner.java:171)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner.access$100(SpecificSegmentQueryRunner.java:44)
at org.apache.druid.query.spec.SpecificSegmentQueryRunner$2.wrap(SpecificSegmentQueryRunner.java:153)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.java.util.common.guava.WrappingSequence$1.get(WrappingSequence.java:50)
at org.apache.druid.query.CPUTimeMetricQueryRunner$1.wrap(CPUTimeMetricQueryRunner.java:78)
at org.apache.druid.java.util.common.guava.WrappingSequence.accumulate(WrappingSequence.java:45)
at org.apache.druid.query.groupby.epinephelinae.GroupByMergingQueryRunnerV2$1$1$1.call(GroupByMergingQueryRunnerV2.java:246)
at org.apache.druid.query.groupby.epinephelinae.GroupByMergingQueryRunnerV2$1$1$1.call(GroupByMergingQueryRunnerV2.java:233)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.druid.query.PrioritizedListenableFutureTask.run(PrioritizedExecutorService.java:247)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- <0x00000001c102ba20> (a java.util.concurrent.ThreadPoolExecutor$Worker)

Mark Herrera
Apr 6, 2022, 3:30:38 PM4/6/22
to Druid User
Hi,
Can you share anything about the queries? Have you experimented with druid.server.http.defaultQueryTimeout?
Best,
Mark
ling...@gmail.com
Apr 7, 2022, 2:13:54 AM4/7/22
to Druid User
Thanks for replying.
The request did return with a Query Timeout error, and we can also see the related logs in router/broker/historical servers.
Here's the log in the historical server:
INFO [qtp273295484-134[groupBy_[***]_53ed9cca-98c5-4298-b41f-ea7e096783d6]] org.apache.druid.query.groupby.epinephelinae.GroupByMergingQueryRunnerV2 - Query timeout, cancelling pending results for query id [53ed9cca-98c5-4298-b41f-ea7e096783d6]WARN [qtp273295484-134[groupBy_[***]_53ed9cca-98c5-4298-b41f-ea7e096783d6]] org.apache.druid.server.QueryLifecycle - Exception while processing queryId [53ed9cca-98c5-4298-b41f-ea7e096783d6] (QueryInterruptedException{msg=Timeout waiting for task., code=Query timeout, class=java.util.concurrent.TimeoutException, host=null})
The problem is the query threads still hung (for at least several hours until we restart the server) in the historical server and took up all merge buffers, then any new groupby query will fail due to lack of merge buffer.
We found all these threads are related to the same time period of data for the same datasource, so we re-ingested these data, then the same query returned successfully now.
The query is simple, it only contains some filters(selector) and aggregation of count and sum.
Mark Herrera
Apr 7, 2022, 3:19:12 PM4/7/22
to Druid User
Thanks for providing the logs and information about the query. Maybe try increasing the druid.server.http.defaultQueryTimeout and running compaction on the datasource before executing the query?

Ben Krug
Apr 7, 2022, 3:50:03 PM4/7/22
to druid...@googlegroups.com
+1 to the above. Also, have you looked at druid.query.groupBy.maxOnDiskStorage settings? (Eg, see here for a note about this setting.)
--
You received this message because you are subscribed to the Google Groups "Druid User" group.
To unsubscribe from this group and stop receiving emails from it, send an email to druid-user+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-user/6a1accee-4dd8-4cda-8ddc-5e54cd74fb82n%40googlegroups.com.
ling...@gmail.com
Apr 8, 2022, 12:12:14 AM4/8/22
to Druid User
Thanks all.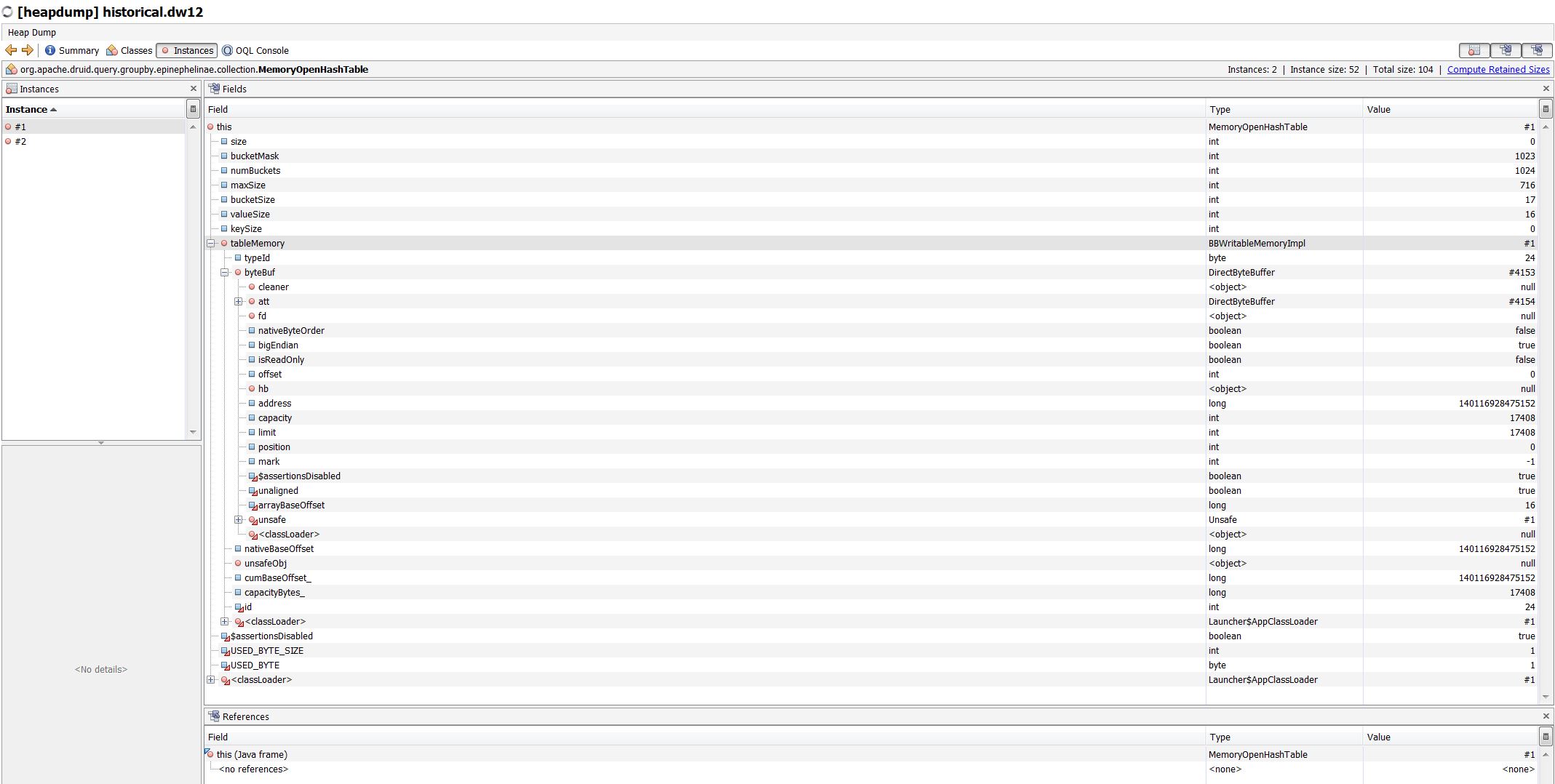
Actually we took thread dump several times and the stack for these query threads never changed.
Meanwhile the CPU usage is high, seems each query thread took 100% (1 core).
We made a heap dump before restart.
We tried the compaction and the issue still existed then we re-ingested the data.
Will try druid.query.groupBy.maxOnDiskStorage if we can reproduce this issue.
ling...@gmail.com
Apr 13, 2022, 8:02:55 AM4/13/22
to Druid User
Hi Team,
The PeriodGranularity may not calculate the bucketStart correctly when works with timeZone that DST is used.

Here's what in our groupby query:
"granularity": {
"type": "period",
"period": "P7D",
"timeZone": "America/Denver",
"origin": "2022-03-27T02:35:00.000-06:00"
},
"type": "period",
"period": "P7D",
"timeZone": "America/Denver",
"origin": "2022-03-27T02:35:00.000-06:00"
},
"intervals": [
"2022-03-06T02:35:00.000-07:00/2022-03-06T03:45:00.000-07:00"
]
"2022-03-06T02:35:00.000-07:00/2022-03-06T03:45:00.000-07:00"
]
Check this code:
org.apache.druid.java.util.common.granularity.PeriodGranularity.truncate(long)
Left: current, Right: possible fix
Check the output from our test program(attached):
origin 2022-03-27T02:35:00.000-06:00
segment min 2022-03-06T02:40:00.000-07:00
bucketStart 2022-03-06T03:35:00.000-07:00
-21D(expected) 2022-03-06T02:35:00.000-07:00
-14D 2022-03-13T03:35:00.000-06:00
-14D-7D 2022-03-06T03:35:00.000-07:00
DST Transition 2022-03-13T03:00:00.000-06:00
segment min 2022-03-06T02:40:00.000-07:00
bucketStart 2022-03-06T03:35:00.000-07:00
-21D(expected) 2022-03-06T02:35:00.000-07:00
-14D 2022-03-13T03:35:00.000-06:00
-14D-7D 2022-03-06T03:35:00.000-07:00
DST Transition 2022-03-13T03:00:00.000-06:00
Due to the DST Transition, the result from origin -21D is not the same with -14D then -7D. It should have the same issue with period Week/Month.
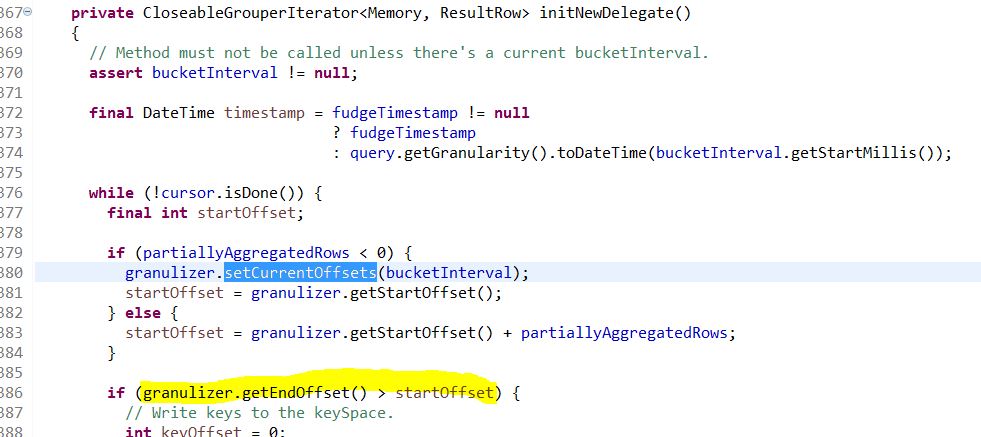
In our case, it causes the granulizer selected nothing for the bucketInterval in the following code:
VectorGroupByEngine$VectorGroupByEngineIterator.initNewDelegate()
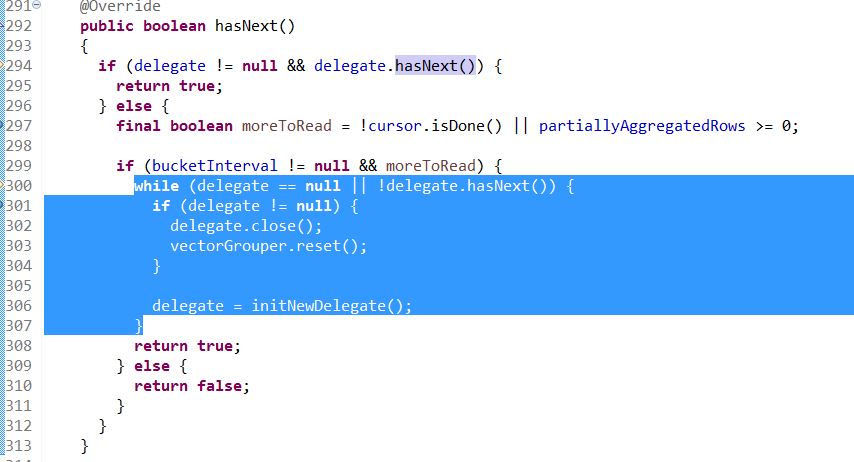
Finally causing a infinite loop in (the selected while loop):
VectorGroupByEngine$VectorGroupByEngineIterator.hasNext()
The query thread will take 100% CPU and never exit, after all merge buffers have been taken by these threads, no more groupby queries can be executed on this historical server. We had to kill this process for restarting.
Thanks!

Peter Marshall
Apr 13, 2022, 9:02:01 AM4/13/22
to Druid User
Hey! Kudos on all this research... In my experience there are two ways to get the attention of developers, which is the official dev list and by raising an issue in Github – as you have quite a bit of research done here, you may want to just go right and create the issue in the repo:
ling...@gmail.com
Apr 13, 2022, 10:33:22 AM4/13/22
to Druid User
Thanks Peter.
An issue has been submitted:
Reply all
Reply to author
Forward
0 new messages