Row count difference after segment handoff
147 views
Skip to first unread message

SAURABH VERMA
Feb 16, 2015, 2:28:38 PM2/16/15
to druid-de...@googlegroups.com
Hello,
I am observing a strange issue, till the time the query is being served by the peon, the row count (for ex.) is X, and after handoff the row count is reported as Y and there is huge difference between X and Y. Total missing count is 20% of X, what am I missing in the configurations, the segments appear to be complete and fine, the historical nodes are able to fetch segments from Deep storage properly
Thanks,
Saurabh

Fangjin Yang
Feb 16, 2015, 5:12:26 PM2/16/15
to druid-de...@googlegroups.com
Hi Saurabh, can you please describe how you are querying a bit more?
Are you issuing the query to the broker with the same interval? How are you comparing the results of the two subsystems?
SAURABH VERMA
Feb 16, 2015, 10:01:30 PM2/16/15
to druid-de...@googlegroups.com
FJ,
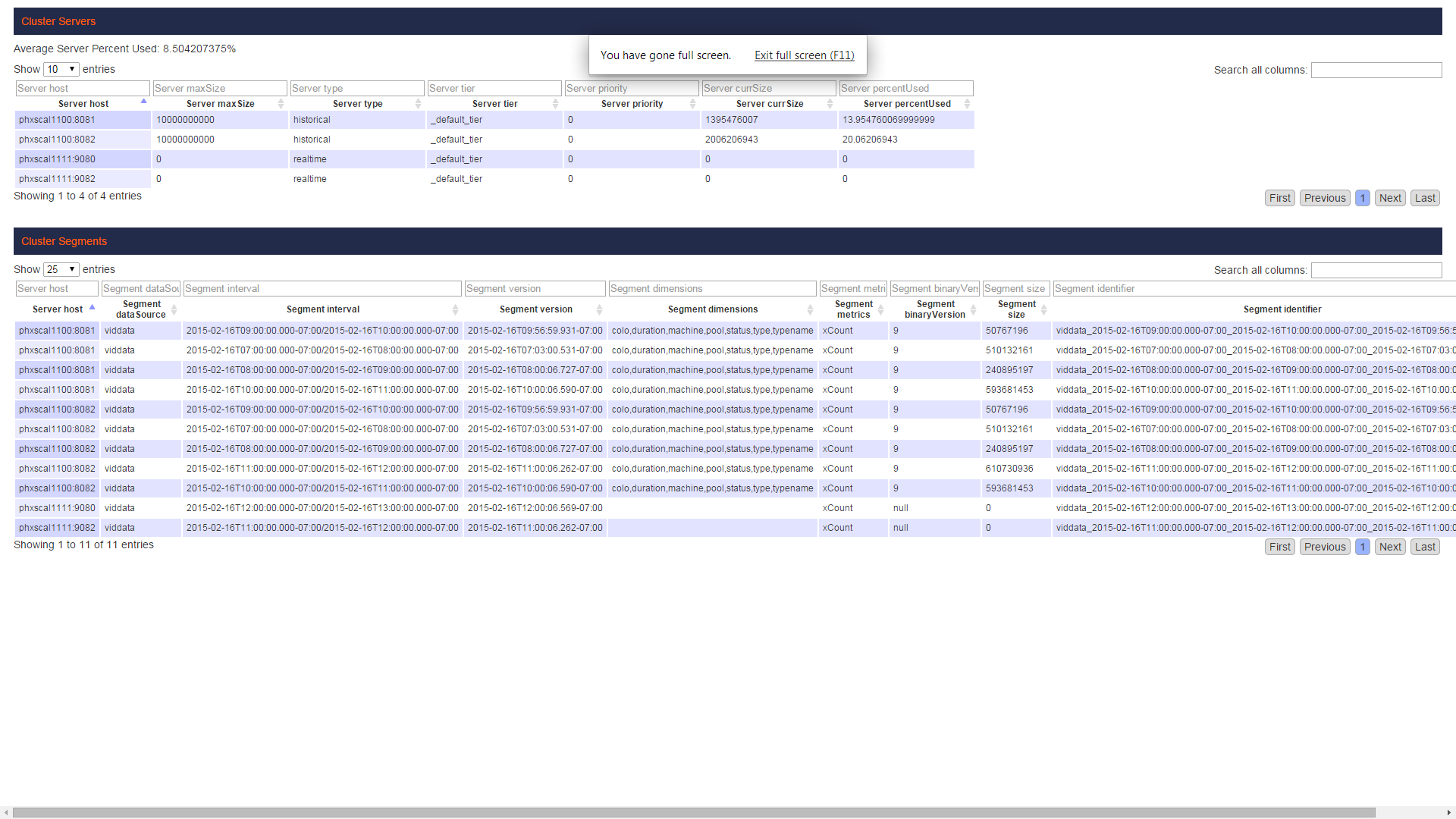
I am using REST interface of brokers for querying. The comparison is visible because before handoff the row count was say 163 M as observed and after handoff the row count was 142M, please the attached snapshot
As visible the same duration segment (11 Am segment) is being served by the peon as well as the historical nodes, this is the snapshot after handoff completed.
One question is why the same segment is being served from historical as well as peons
SAURABH VERMA
Feb 17, 2015, 1:57:28 AM2/17/15
to druid-de...@googlegroups.com
The cause of this issue may be that the peon and historical nodes are serving the same segment and at runtime brokers may direct the query to either of them, but in that case also the reported count should be the same,
it may be that broker counts the data from the 2 paths twice and shows the result, the primary issue is the peons not shuttingOff (peons are never shuttingDown) although I am using timed firehose. This issue seems similar to https://groups.google.com/forum/#!searchin/druid-development/handoff/druid-development/euwe8OXgFQY/pq67gP5jLtsJ
Fangjin Yang
Feb 17, 2015, 1:15:08 PM2/17/15
to druid-de...@googlegroups.com
The segments served on historicals and realtimes are exactly the same. The issue appears that at least 2 of your segments are corrupt and complete not handing off because the historicals throw exceptions right after downloading them. I have never seen the exception that you posted in your previous logs and need to investigate further. For hours 11-13, I don't see any segments even being served by the historicals.
Can you try the same query for 2015-02-16 before hour 11? I suspect results will be correct then.
SAURABH VERMA
Feb 17, 2015, 1:35:45 PM2/17/15
to druid-de...@googlegroups.com
FJ,
Below are some observations around this setup, please see if they make some sense :-
1. Whenever Historicals try to fetch a segment, they throw a FileNotFoundExcpetion
2. Just after this error, they are able to fetch segments from HDFS without an error
3. Handoff ack is not reaching peons and thus they keep running forever
One question is that after step 2, the corresponding peons should get handoff ack and then complete with SUCCESS status but they dont
Is it a possibility that if the ack doesnt reach the peons before the peon shutOffTime param, then peons wont ever complete?
Fangjin Yang
Feb 18, 2015, 1:48:14 PM2/18/15
to druid-de...@googlegroups.com
Hi Saurabh, can you confirm the error on recent segments? I am curious about segments that were generated after you removed NFS from your configs.
SAURABH VERMA
Feb 19, 2015, 1:13:21 PM2/19/15
to druid-de...@googlegroups.com
Hello FJ,
Sorry for late reply, FJ the error seems to be disappeared after configuring timezones correctly on HNs as HNs were trying to search for segments with incorrect names. Still the peons do not get ack and keep running forever, thats an open question, secondly, the row count on successive querying data for the same hour returns different results (after the ingestion for that hour has completed), is this because segments loaded have lesser data than corresponding hour peons ?
Fangjin Yang
Feb 19, 2015, 7:13:51 PM2/19/15
to druid-de...@googlegroups.com
The segment that's handed off by the peon should be exactly the same as the one on the historical node. If I understand your message correctly, the segment inconsistency is gone but you are still having troubles with handoff?
SAURABH VERMA
Feb 19, 2015, 8:29:03 PM2/19/15
to druid-de...@googlegroups.com
FJ,
The segment inconsistency and handoff trouble, both exist as of now. Is there a way I can look into the segment (/metadata) that helps me compare data served by peon vs segment data. Could you provide some clue what may be the reason of inconsistency ?
SAURABH VERMA
Feb 19, 2015, 8:30:40 PM2/19/15
to druid-de...@googlegroups.com
One more question FJ, how can I track the handoff ACK in system, H-nodes console show "Announcing segment for ...", is this announcement treated by peon as ACK or is there some other entry being created in ZK to signal peons about successful segment load at H-node.
Fangjin Yang
Feb 19, 2015, 8:38:31 PM2/19/15
to druid-de...@googlegroups.com
Saurabh, is the segment handoff failing because of exceptions on the historical node as they try to download the segment? Do they fail only for some segments or all segments?
SAURABH VERMA
Feb 19, 2015, 8:57:29 PM2/19/15
to druid-de...@googlegroups.com
FJ,
Let me mention observations as of now :-
1. Peons successfully handoff segment to Deepstorage
2. H node are fetching segments without any excpetion on console (H node loads segment with 30s of pushing to HDFS)
3. Peons are running for the same hour for which H node also have loaded the segment (Peons didnt get ACK of segment load at H node)
4. Querying the cluster in this state for the past 1 hour gives different results (seems queries hitting peons give larger number than queries hitting H nodes for the same duration segment)

Nishant Bangarwa
Feb 19, 2015, 11:11:33 PM2/19/15
to druid-de...@googlegroups.com
Hi Saurabh,
do you see any such loggings in peon logs ?
when the segment is loaded on a historical node it announces the segment it in zk, the peon watches the zk announcements and when it notices the segment being loaded on the historical it unloads the segment and mark the task as finished,
while waiting for the handoff there should be a logging in the peon logs for
Cannot shut down yet! Sinks remaining: <segment_ids>
in the coordinator console do you see the segment for which peon is waiting for loaded on any of the historical nodes ?
and when the peon notices matching segment being loaded
Segment[%s] matches sink[%s] on server[%s]
and Segment version[%s] >= sink version[%s]
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/a4644207-44cb-4dfa-adc7-c73c7e683af8%40googlegroups.com.--
You received this message because you are subscribed to the Google Groups "Druid Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to druid-developm...@googlegroups.com.
To post to this group, send email to druid-de...@googlegroups.com.
|
Nishant Bangarwa
Feb 20, 2015, 2:02:25 AM2/20/15
to druid-de...@googlegroups.com
Hi Saurabh,
in the attached logs i can see the version of the segment is non-UTC,
2015-02-19T17:00:08.079-07:00, this is probably due to overlord running in non UTC timezone,
can you try running all your druid nodes with UTC timezone ?
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/6d395ce5-bb87-49e9-931e-eabe0c25727a%40googlegroups.com.
Nishant Bangarwa
Feb 20, 2015, 2:02:25 AM2/20/15
to druid-de...@googlegroups.com
Hi Saurabh,
in the attached logs i can see the version of the segment is non-UTC,
2015-02-19T17:00:08.079-07:00, this is probably due to overlord running in non UTC timezone,
can you try running all your druid nodes with UTC timezone ?
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/6d395ce5-bb87-49e9-931e-eabe0c25727a%40googlegroups.com.
SAURABH VERMA
Feb 20, 2015, 3:28:59 AM2/20/15
to druid-de...@googlegroups.com
Sure Nishant, I can try that but there is one concern in that path, all our data is in MST and when I put all nodes in UTC, then I need to set windowPeriod as 7 hours, only then tranquility allows events to reach druid and it would not be the right solution for our case. This is because Tranquility has hardcoded timezone as UTC (https://github.com/metamx/tranquility/blob/master/src/main/scala/com/metamx/tranquility/druid/DruidBeamMaker.scala#L220)
Can you suggest a way given these constraints ? (Shall we try to make Timezone a configurable param in Tranquililty and then try everything in MST ?, or is there another quicker way ?)
Gian Merlino
Feb 23, 2015, 8:11:38 PM2/23/15
to druid-de...@googlegroups.com
Saurabh, that mention of UTC is just controlling how tranquility names its firehoses, and is not actually related to what data will be accepted. I think tranquility should work fine in any time zone.
One thing to make sure of with the time zones is that your Timestamper needs to generate DateTimes in the proper zone. If your source data has an ISO8601 timestamp with an offset in it (like "2000-01-02T03:04:05.678-0800") this should happen just by doing "new DateTime(theString)". But, if your source data has timestamps without zones (like "2000-01-02T03:04:05.678") then you will need to provide the proper time zone to the DateTime constructor.
Another thing to make sure of is that your object serializer must serialize timestamps in such a way that Druid can read them properly. Generally this means including a timezone offset in the string. This should happen automatically if you are using Jackson with Joda DateTimes that have timezones set properly.

{kind=link}
Eric Tschetter
Feb 24, 2015, 12:37:04 PM2/24/15
to druid-de...@googlegroups.com
Saurabh,
Btw, the row count different between realtime and historicals is expected and by design. I don't see the query you are doing attached to this thread (sorry if I missed it), but I'm assuming that you are running with the {"type": "count", ... } aggregator.
If that is the case, then it is doing a row count, which is going to count the number of rows that have to be scanned in order to produce the result.
When doing real-time indexing, data is ingested into an in-memory, row-oriented buffer up until that either fills up or "intermediatePersistPeriod" elapses. Once the persist has begun another buffer is created and starts to fill up. It is entirely possible (and likely) that you have duplicate rows between what is in-memory and what has been persisted.
When the realtime goes to hand the segment off to the historical it merges together all of the persisted segments into a single, larger segment. This merge also combines any duplicated rows into a single row. So, the row count can definitely shrink. What shouldn't change is the other aggregations. Say you are ingesting data with the following aggregator:
{"type": "count", "name": "numEvents" }
Then if you query using the aggregator
{"type": "longSum", "name": "numEvents", "fieldName": "numEvents"}
It should given you the same answer in both places.
--Eric
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/76266a14-ab52-472c-b1f2-1a8c78300fd5%40googlegroups.com.
SAURABH VERMA
Feb 24, 2015, 11:02:34 PM2/24/15
to druid-de...@googlegroups.com
Gian,
Thank you for clarifying this part, as you mentioned, I have modified the code to generate timestamps with offset information and it works perfect, the issue of historical unable to notify peons about successful segment upload is still appearing. Right now everything is in MST timezone (Overlord, Peon, MMs, Historicals, Coordinator), a sample peon log is as below :-
"2015-02-24 20:49:57,334 INFO [ServerInventoryView-0] io.druid.curator.inventory.CuratorInventoryManager - CHILD_ADDED[vidmessage_2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00_2015-02-24T19:00:06.899-07:00_6] with version[0]
2015-02-24 20:49:57,435 INFO [ServerInventoryView-0] io.druid.curator.inventory.CuratorInventoryManager - CHILD_ADDED[vidmessage_2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00_2015-02-24T19:00:06.899-07:00_9] with version[0] 2015-02-24 20:49:58,939 INFO [ServerInventoryView-0] io.druid.curator.inventory.CuratorInventoryManager - CHILD_ADDED[vidmessage_2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00_2015-02-24T19:00:06.899-07:00_4] with version[0] 2015-02-24 20:49:59,151 INFO [ServerInventoryView-0] io.druid.curator.inventory.CuratorInventoryManager - CHILD_ADDED[vidmessage_2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00_2015-02-24T19:00:06.899-07:00_7] with version[0]
2015-02-24 20:50:00,564 INFO [ServerInventoryView-0] io.druid.curator.inventory.CuratorInventoryManager - CHILD_ADDED[vidmessage_2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00_2015-02-24T19:00:06.899-07:00_2] with version[0]"
This is the log for peon that created segment for 19th hour (MST),
This is the log for peon while persisting segment to hdfs :-
"Compressing files from[/home/appmon/druid/persistent/task/index_realtime_VidMessage_2015-02-24T19:00:00.000-07:00_0_0_jbkngfcg/work/persist/VidMessage/2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00/merged] to [hdfs://10.86.184.26:54310/druid/segments/vidmessage/20150224T190000.000-0700_20150224T200000.000-0700/2015-02-24T19_00_06.899-07_00/0/index.zip]
2015-02-24 20:16:45,673 INFO [VidMessage-2015-02-24T19:00:00.000-07:00-persist-n-merge] io.druid.utils.CompressionUtils - Adding file[/home/appmon/druid/persistent/task/index_realtime_VidMessage_2015-02-24T19:00:00.000-07:00_0_0_jbkngfcg/work/persist/VidMessage/2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00/merged/meta.smoosh] with size[290]. Total size so far[0] 2015-02-24 20:16:45,674 INFO [VidMessage-2015-02-24T19:00:00.000-07:00-persist-n-merge] io.druid.utils.CompressionUtils - Adding file[/home/appmon/druid/persistent/task/index_realtime_VidMessage_2015-02-24T19:00:00.000-07:00_0_0_jbkngfcg/work/persist/VidMessage/2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00/merged/version.bin] with size[4]. Total size so far[290] 2015-02-24 20:16:45,674 INFO [VidMessage-2015-02-24T19:00:00.000-07:00-persist-n-merge] io.druid.utils.CompressionUtils - Adding file[/home/appmon/druid/persistent/task/index_realtime_VidMessage_2015-02-24T19:00:00.000-07:00_0_0_jbkngfcg/work/persist/VidMessage/2015-02-24T19:00:00.000-07:00_2015-02-24T20:00:00.000-07:00/merged/00000.smoosh] with size[170,947,864]. Total size so far[294] 2015-02-24 20:17:04,129 INFO [VidMessage-2015-02-24T19:00:00.000-07:00-persist-n-merge] io.druid.storage.hdfs.HdfsDataSegmentPusher - Creating descriptor file at[hdfs://10.86.184.26:54310/druid/segments/vidmessage/20150224T190000.000-0700_20150224T200000.000-0700/2015-02-24T19_00_06.899-07_00/0/descriptor.json] 2015-02-24 20:17:04,140 INFO [VidMessage-2015-02-24T19:00:00.000-07:00-persist-n-merge] io.druid.indexing.common.actions.RemoteTaskActionClient - Performing action for task[index_realtime_VidMessage_2015-02-24T19:00:00.000-07:00_0_0_jbkngfcg]: SegmentInsertAction{segments=[DataSegment{size=170948158, shardSpec=LinearShardSpec{partitionNum=0}, metrics=[xCount], dimensions=[colo, duration, machine, pool, status, type, typename], version='2015-02-24T19:00:06.899-07:00', loadSpec={type=hdfs, path=hdfs://10.86.184.26:54310/druid/segments/vidmessage/20150224T190000.000-0700_20150224T200000.000-0700/2015-02-24T19_00_06.899-07_00/0/index.zip}, interval=2015-02-24T19:00:00.000-07:00/2015-02-24T20:00:00.000-07:00, dataSource='vidmessage', binaryVersion='9'}]}
2015-02-24 20:17:04,144 INFO [VidMessage-2015-02-24T19:00:00.000-07:00-persist-n-merge] io.druid.indexing.common.actions.RemoteTaskActionClient - Submitting action for task[index_realtime_VidMessage_2015-02-24T19:00:00.000-07:00_0_0_jbkngfcg] to overlord[http://phxscal1109:8087/druid/indexer/v1/action]: SegmentInsertAction{segments=[DataSegment{size=170948158, shardSpec=LinearShardSpec{partitionNum=0}, metrics=[xCount], dimensions=[colo, duration, machine, pool, status, type, typename], version='2015-02-24T19:00:06.899-07:00', loadSpec={type=hdfs, path=hdfs://10.86.184.26:54310/druid/segments/vidmessage/20150224T190000.000-0700_20150224T200000.000-0700/2015-02-24T19_00_06.899-07_00/0/index.zip}, interval=2015-02-24T19:00:00.000-07:00/2015-02-24T20:00:00.000-07:00, dataSource='vidmessage', binaryVersion='9'}]}"
Please have a look if there is an issue
SAURABH VERMA
Feb 24, 2015, 11:28:13 PM2/24/15
to druid-de...@googlegroups.com
Yes Eric, I was using type:"count" aggregator, after using the correct method to count number of rows using {"type": "longSum", "name": "numEvents", "fieldName": "numEvents"}, the data is always reported to be the same showing that the same data is available at historicals and peons,
Thanks a lot Eric for this useful information
SAURABH VERMA
Feb 25, 2015, 12:04:20 PM2/25/15
to druid-de...@googlegroups.com
Finally the issue of unsuccessful notification got solved ...the root cause of issue is that the data source name has to be all in lowercase letters, I am unable to figure why such a constraint is imposed on data source name, because of this the segment upload notification is not handled appropriately by peons at https://github.com/druid-io/druid/blob/master/server/src/main/java/io/druid/segment/realtime/plumber/RealtimePlumber.java#L875
SAURABH VERMA
Feb 25, 2015, 12:04:20 PM2/25/15
to druid-de...@googlegroups.com
Nishant Bangarwa
Feb 25, 2015, 12:33:52 PM2/25/15
to druid-de...@googlegroups.com
Hi Saurabh,
we have removed casing constraints in druid 0.7.0 release.
druid is now case sensitive.
On Wed, Feb 25, 2015 at 10:34 PM, SAURABH VERMA <saurabh...@gmail.com> wrote:
Finally the issue of unsuccessful notification got solved ...the root cause of issue is that the data source name has to be all in lowercase letters, I am unable to figure why such a constraint is imposed on data source name, because of this the segment upload notification is not handled appropriately by peons at https://github.com/druid-io/druid/blob/master/server/src/main/java/io/druid/segment/realtime/plumber/RealtimePlumber.java#L875
--
You received this message because you are subscribed to the Google Groups "Druid Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to druid-developm...@googlegroups.com.
To post to this group, send email to druid-de...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/ff5945f8-8a3f-49e1-b148-64767b6dbd96%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
SAURABH VERMA
Feb 26, 2015, 7:20:53 AM2/26/15
to druid-de...@googlegroups.com
Hi Nishant,
I got this point but my concern is that when the data source name I provide during ingestion ('VidMessage' in this case), it is internally converted to 'vidmessage' while segment creation and when the segment is uploaded to one of the historicals, then since the name mismatches, it fails, ultimately I had to change the data-source name to vidmessage to overcome this arrangement.
Thanks,
Saurabh
Nishant Bangarwa
Feb 26, 2015, 9:06:19 AM2/26/15
to druid-de...@googlegroups.com
Hi Saurabh,
do you see the same issue with druid 0.7.0 ?
datasource name conversion to lowercase should not happen with druid-0.7.0.
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/79be9405-0168-47f5-ac72-80aacd176750%40googlegroups.com.
SAURABH VERMA
Feb 26, 2015, 9:25:34 AM2/26/15
to druid-de...@googlegroups.com
I believe I forgot to mention that I am using Druid 0.6.171 as of now, didn't notice the version mentioned in the last reply.
--
Thanks & Regards,
Saurabh Verma,
India
It's good to know that this conversion has been fixed in 0.7.0, will upgrade to this
You received this message because you are subscribed to a topic in the Google Groups "Druid Development" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/druid-development/T8KP4W8PX3s/unsubscribe.
To unsubscribe from this group and all its topics, send an email to druid-developm...@googlegroups.com.
To post to this group, send email to druid-de...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/druid-development/CACW6ntc%3Dxc1y4JB1712DEqa%2BXpgFKtamVf069nssFyMcFUgisQ%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
Thanks & Regards,
Saurabh Verma,
India
Reply all
Reply to author
Forward
0 new messages