Skip to first unread message

Philipp at UiT
Jun 1, 2017, 1:49:58 AM6/1/17
to Dataverse Users Community
I just saw that Zenodo has introduced DOI versioning, cf. https://blogs.openaire.eu/?p=2010.
I this something Dataverse is considering?
Best,
Philipp

Philip Durbin
Jun 1, 2017, 6:26:16 AM6/1/17
to dataverse...@googlegroups.com
Thanks for the link to the Zenodo article. There was some lively discussion on this topic on the Force11 Software Citation Working Group* mailing list in early April under the thread "Question: Who does DOI versioning well [and doesn't rely on dot suffixing to do it]" but I'm not aware of any plans to change the way Dataverse handles DOIs in the context of versioning.
What do you and others from the community think?
Phil
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin

Sebastian Karcher
Jun 1, 2017, 8:45:47 AM6/1/17
to dataverse...@googlegroups.com
While this is probably more important for software citation, I think having PIDs for individual versions of a dataset is basically a must going forward. How else are you going to have machine-actionable citations. Or, in the word of some obscure working paper on the topic:
Persistent identifiers for datasets must support multiple levels of granularity to support both the
citation of a specific version and/or individual dataset, as well the citation of an unspecified
version of a dataset and/or a collection of primary data.
I also think the Zenodo implementation is exactly right in the choices they made on how to do this (i.e. only force version changes on file changes -- similar to what DV does already -- not use suffixes)
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.

Mercè Crosas
Jun 1, 2017, 8:47:56 AM6/1/17
to dataverse...@googlegroups.com
Yes, of course, I agree :)
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.

Steven McEachern
Jun 1, 2017, 11:22:03 AM6/1/17
to Dataverse Users Community
Hi all,
We've had an ongoing discussion here at the Australian Data Archive (ADA) about this. I agree with Sebastian's points, particularly that the end-game here is machine-actionable citations. The DV DOI as it currently stands is NOT machine-actionable as best I can tell - or am I missing something? Although you can reference a dataset through a combination of the DOI and the version number, I think that is sub-optimal - why not just have a DOI assigned to the specific version.
It's problematic for us in terms of our longitudinal and time series datasets, where each new wave of data collected results in a new release (version) - but right now NOT a new DOI. We will be implementing a policy where each release is established as a new dataset, given Dataverse's current versioning approach. This will allow a user can reference the specific release/version of the data - but I think the better option really would be to increment the DOI with each version.
(There is an additional complication when you think about variable metadata - if I change a label or a column name, should these trigger a new version? And a new DOI?)
ADA staff would be happy to contribute to a more detailed discussion if that would be of interest.
Regards,
Steve
-------------------------------
Dr. Steven McEachern
Director
Australian Data Archive
-------------------------------
On Thursday, June 1, 2017 at 10:47:56 PM UTC+10, Merce wrote:
Yes, of course, I agree :)
While this is probably more important for software citation, I think having PIDs for individual versions of a dataset is basically a must going forward. How else are you going to have machine-actionable citations. Or, in the word of some obscure working paper on the topic:
Persistent identifiers for datasets must support multiple levels of granularity to support both the
citation of a specific version and/or individual dataset, as well the citation of an unspecified
version of a dataset and/or a collection of primary data.I also think the Zenodo implementation is exactly right in the choices they made on how to do this (i.e. only force version changes on file changes -- similar to what DV does already -- not use suffixes)
On Thu, Jun 1, 2017 at 6:26 AM, Philip Durbin <philip...@harvard.edu> wrote:
Thanks for the link to the Zenodo article. There was some lively discussion on this topic on the Force11 Software Citation Working Group* mailing list in early April under the thread "Question: Who does DOI versioning well [and doesn't rely on dot suffixing to do it]" but I'm not aware of any plans to change the way Dataverse handles DOIs in the context of versioning.What do you and others from the community think?Phil
On Thu, Jun 1, 2017 at 1:49 AM, Philipp at UiT <uit.op...@gmail.com> wrote:
I just saw that Zenodo has introduced DOI versioning, cf. https://blogs.openaire.eu/?p=2010.I this something Dataverse is considering?Best,Philipp
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
Philip Durbin
Jun 1, 2017, 1:47:49 PM6/1/17
to dataverse...@googlegroups.com
I like the idea of machine-readable citations but these would be expressed in JSON, XML, or some other standard format, right?
Dataverse already exports machine-readable citations in the following formats when you click the "Cite Dataset" button:## EndNote XML
<?xml version="1.0" encoding="UTF-8"?>
<xml>
<records>
<record>
<ref-type name="Online Database">45</ref-type>
<contributors>
<authors>
<author>Bakshy, Eytan</author>
<author>Messing, Solomon</author>
<author>Adamic, Lada</author>
</authors>
</contributors>
<titles>
<title>Replication Data for: Exposure to Ideologically Diverse News and Opinion on Facebook</title>
</titles>
<section>2015-05-07</section>
<dates>
<year>2015</year>
</dates>
<publisher>Harvard Dataverse</publisher>
<urls>
<related-urls>
<url>http://dx.doi.org/10.7910/DVN/LDJ7MS</url>
</related-urls>
</urls>
<electronic-resource-num>doi/10.7910/DVN/LDJ7MS</electronic-resource-num>
</record>
</records>
</xml>
Provider: Harvard Dataverse
Content: text/plain; charset="us-ascii"
TY - DBASE
T1 - Replication Data for: Exposure to Ideologically Diverse News and Opinion on Facebook
AU - Bakshy, Eytan
AU - Messing, Solomon
AU - Adamic, Lada
DO - doi/10.7910/DVN/LDJ7MS
PY - 2015
UR - http://dx.doi.org/10.7910/DVN/LDJ7MS
PB - Harvard Dataverse
ER -
## BIbTeX
@data{LDJ7MS_2015,
author = {Bakshy, Eytan and Messing, Solomon and Adamic, Lada},
publisher = {Harvard Dataverse},
title = {Replication Data for: Exposure to Ideologically Diverse News and Opinion on Facebook},
year = {2015},
doi = {10.7910/DVN/LDJ7MS},
url = {http://dx.doi.org/10.7910/DVN/LDJ7MS}
To be clear, I have no knowledge of any of these citation standards, or if they are even standards, and if there's a place to put a version number.
Thanks,
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.

Durand, Gustavo
Jun 1, 2017, 2:03:56 PM6/1/17
to dataverse...@googlegroups.com
This definitely seem like a good lunch table topic for the community meeting! Now to just figure out how to clone myself, so I can be at all of them at once. :)

At the Pidapalooza conference last year, I discussed some of the questions* we were thinking about in regards to this during my presentation. I'll include that slide here.
* a new question: what do we do with the current datasets that have only 1 the one doi tied to multiple versions and have been cited as such?
On Thu, Jun 1, 2017 at 11:22 AM, Steven McEachern <stev...@gmail.com> wrote:
Hi all,
We've had an ongoing discussion here at the Australian Data Archive (ADA) about this. I agree with Sebastian's points, particularly that the end-game here is machine-actionable citations. The DV DOI as it currently stands is NOT machine-actionable as best I can tell - or am I missing something? Although you can reference a dataset through a combination of the DOI and the version number, I think that is sub-optimal - why not just have a DOI assigned to the specific version.
It's problematic for us in terms of our longitudinal and time series datasets, where each new wave of data collected results in a new release (version) - but right now NOT a new DOI. We will be implementing a policy where each release is established as a new dataset, given Dataverse's current versioning approach. This will allow a user can reference the specific release/version of the data - but I think the better option really would be to increment the DOI with each version.
(There is an additional complication when you think about variable metadata - if I change a label or a column name, should these trigger a new version? And a new DOI?)
ADA staff would be happy to contribute to a more detailed discussion if that would be of interest.
Regards,
Steve
-------------------------------Dr. Steven McEachernDirectorAustralian Data Archive-------------------------------
On Thursday, June 1, 2017 at 10:47:56 PM UTC+10, Merce wrote:
Yes, of course, I agree :)
While this is probably more important for software citation, I think having PIDs for individual versions of a dataset is basically a must going forward. How else are you going to have machine-actionable citations. Or, in the word of some obscure working paper on the topic:
Persistent identifiers for datasets must support multiple levels of granularity to support both the
citation of a specific version and/or individual dataset, as well the citation of an unspecified
version of a dataset and/or a collection of primary data.I also think the Zenodo implementation is exactly right in the choices they made on how to do this (i.e. only force version changes on file changes -- similar to what DV does already -- not use suffixes)
On Thu, Jun 1, 2017 at 6:26 AM, Philip Durbin <philip...@harvard.edu> wrote:
Thanks for the link to the Zenodo article. There was some lively discussion on this topic on the Force11 Software Citation Working Group* mailing list in early April under the thread "Question: Who does DOI versioning well [and doesn't rely on dot suffixing to do it]" but I'm not aware of any plans to change the way Dataverse handles DOIs in the context of versioning.
What do you and others from the community think?
Phil
On Thu, Jun 1, 2017 at 1:49 AM, Philipp at UiT <uit.op...@gmail.com> wrote:
I just saw that Zenodo has introduced DOI versioning, cf. https://blogs.openaire.eu/?p=2010.I this something Dataverse is considering?
Best,Philipp
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
Sebastian Karcher
Jun 1, 2017, 3:56:14 PM6/1/17
to dataverse...@googlegroups.com
Hi all,
thanks for engaging this and happy to talk more.
Phil -
while adding version numbers in the metadata export would be good, what I am referring to is the ability to create citations _to_ the dataset that are machine actionable. - as Zenodo explains convincingly, DOIs should not be semantic, i.e. not include v.1 etc. The linking of versions is in the metadata
Best,
Sebastian
[1] For now this requires going through the DV API, but I think it's easy to imagine a future version where the availability of the actual data files is advertised in the response header so that this could work without API calls specific to DV.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
Philip Durbin
Jun 1, 2017, 7:21:49 PM6/1/17
to dataverse...@googlegroups.com
That makes sense, but isn't your R code going to operate on a specific file? You'd want to operated on the CSV file in your dataset rather than your README. In that case you're targeting a file, which in Dataverse is only known by it's database id.
Here's an R script I wrote a while back that downloads a specific file within a dataset based on the file's database id: https://github.com/IQSS/dataverse/blob/v4.6.1/scripts/issues/2438/download.RIn Dataverse, files are immutable so that database id for a file means the file has a specific checksum that will never change out from under you.
It sounds like people might be interested in a DOI per dataset version? If so, we need a brave soul to create a GitHub issue. :)
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.

Gautier, Julian
Jun 2, 2017, 7:19:07 AM6/2/17
to dataverse...@googlegroups.com
Another use case that might be obvious or not, or maybe just a different angle: If I'm a researcher trying to verify findings from an article I read, and look for the data using this citation -
Davey, Rohan, 2017, "Replication Data for: "Title", doi:10.7910/DVN/YP1HS9, Harvard Dataverse, V2
Will I know that that DOI points to the most current dataset version, which might not be version 2, and that I should find version 2 and download that data instead?
Also, the discussion's been mostly about the pros of versioned, non-semantic DOIs. Would one possible con be, as Steven said, that DOIs might be created for versions with changes that are insignificant? Could addressing that problem involve giving depositors better control over, and more info. to decide when, a new version and DOI are created?
Are there other cons?
And finally, if Gustavo clones himself, should each version get a different ORCID?
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
Philip Durbin
Jun 2, 2017, 7:55:44 AM6/2/17
to dataverse...@googlegroups.com
Heh. Oh, there's another quote I wanted to share about per-version DOIs at Zenodo from the "software citations" issue at https://github.com/IQSS/social_science_software_toolkit/issues/5 . I hope it's good food for thought. Here it is:
^^^
To kick this thread off, an email @mercecrosas received recently about per version DOIs over at Zenodo:
Dear Julie,
Please don’t feel that you shouldn’t single out Zenodo for things that you think we should do better. We’re happy to take critical feedback!
We’re fully aware that the current method which uses just related identifiers is fully insufficient for doing versioning nicely. That’s also why that we hopefully within the next two weeks with launch a complete revamped versioning system which will:
1) Mint a) concept DOI and b) per version DOI
2) Versioning will be done solely via metadata (concept DOI will link all versions in metadata, and version DOIs will link to their concept DOI - initially we use hasPart/isPartOf, but will move to isVersionOf/hasVersion once DataCite v4.1 is out). All DOIs will follow the usual pattern 10.5281/zenodo.<integer> (i.e. no versioning information in the identifier)
3) Concept DOI resolves to the latest minted version DOI.
4) Records clearly shows a) if it’s not the latest version and b) all available versions of a resource (and you can easily jump between them)
5) Our "Cite as” will use the version specific resource for citation.
I’ve included a couple of screenshots.
For impact measures we’re pretty far behind so we currently have no measures to “roll-up”, but clearly researchers don’t want to dilute their citations just because they use versioning so this is very important in my opinion as well.
Best regards,
Lars
---
Lars Holm Nielsen
CERN, IT Department
Tel: +41 22 76 79182 | Cel: +41 76 672 8927 | Twitter: @larshankat | Skype: larsholm-hankat
^^^
Hope this helps,
Phil
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.

James Turitto
Mar 7, 2018, 11:59:35 AM3/7/18
to Dataverse Users Community
Hi all,
I'm picking up on this thread from last summer.
Sebastian mentioned to me last week that this is something the Dataverse is working on/considering. The roadmap indicates there will be a release for file-level PIDs and nothing else so far. I just wanted to check in because we are working out ways to implement persistent identifiers for versions on the AEA Registry.
Thanks,
James
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.
Philip Durbin
Mar 7, 2018, 8:56:22 PM3/7/18
to dataverse...@googlegroups.com
Hi James,
I'm not sure if this helps answer your question or not but (as always) files are immutable in Dataverse so a persistent identifier (DOI or Handle) at the file level* will always identify a particular file with a particular MD5. Right now files in Dataverse are identified by their database ID but once https://github.com/IQSS/dataverse/pull/4350 is merged (and we cut a release) files will have persistent identifiers.To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/23db8f08-0354-4aa8-b0f8-4776afc55c35%40googlegroups.com.
Sebastian Karcher
Mar 8, 2018, 12:58:11 PM3/8/18
to Dataverse Users Community
Apologies, I somehow misremembered where Dataverse was on versioning DOIs and told James something incorrect.
I do still completely agree with past-me, though, that this needs to happen. A quick summary:
Userstory: As a researcher, I want to be able to cite, using a permanent identifier, a specific version of dataset to avoid any ambiguity and to make the citation machine-actionable.
How this should probably look: Zenodo would be a good template here.
1. A dataset has one "generic" DOI that always points to the latest version (this would be used if you e.g. just cite the data generically)
2. A dataset has one DOI per version to allow to point to a specific version
Why file DOIs are not enough:
File DOIs are great & we're excited to see them happen, but they are not a replacement for dataset version DOIs. Datasets are often made up of multiple files. An analysis script (which itself may be part of the data and thus versioned) may point to multiple files in a dataset. It's not feasible (or desirable) for a researcher to include the DOI for every file used in a citation. They want to point to one single DOI to reference the exact data (made up of multiple files) they've been using. This is equally true for quantiative and qualitative data, btw.
Thanks and sorry again for any confusion I created,
Sebastian
I do still completely agree with past-me, though, that this needs to happen. A quick summary:
Userstory: As a researcher, I want to be able to cite, using a permanent identifier, a specific version of dataset to avoid any ambiguity and to make the citation machine-actionable.
How this should probably look: Zenodo would be a good template here.
1. A dataset has one "generic" DOI that always points to the latest version (this would be used if you e.g. just cite the data generically)
2. A dataset has one DOI per version to allow to point to a specific version
Why file DOIs are not enough:
File DOIs are great & we're excited to see them happen, but they are not a replacement for dataset version DOIs. Datasets are often made up of multiple files. An analysis script (which itself may be part of the data and thus versioned) may point to multiple files in a dataset. It's not feasible (or desirable) for a researcher to include the DOI for every file used in a citation. They want to point to one single DOI to reference the exact data (made up of multiple files) they've been using. This is equally true for quantiative and qualitative data, btw.
Thanks and sorry again for any confusion I created,
Sebastian
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/23db8f08-0354-4aa8-b0f8-4776afc55c35%40googlegroups.com.
Philip Durbin
Mar 8, 2018, 1:17:51 PM3/8/18
to dataverse...@googlegroups.com
Thanks, Sebastian. I know this thread is about DOIs but I feel like the conversation could be enriched by me mentioning that when a dataset includes at least one file that has successfully ingested as tabular data, a UNF is generated at the dataset level and added to the citation. Of course, this only helps if files are tabular and were successfully ingested. And the dataset-level UNF is calculated only from files that were successfully ingested (and each have a file level UNF) so it's not a great solution for when researchers don't have exclusively tabular data. For more on UNF, see http://guides.dataverse.org/en/4.8.5/developers/unf
Anyway, I hear what you're saying. If you have not already created a GitHub issue describing the feature you want, please consider going ahead and creating one.To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/23db8f08-0354-4aa8-b0f8-4776afc55c35%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/c3d9986e-4f9f-4330-96d3-6055b789c4e5%40googlegroups.com.
Durand, Gustavo
Mar 9, 2018, 3:13:55 AM3/9/18
to dataverse...@googlegroups.com
I looked to see if we already had an issue for version PIDs, but could not find one. I do plan on championing version PIDs soon after we get files done (we already started to think about them and how they could work as we were getting that issue done).
On Thu, Mar 8, 2018 at 1:17 PM, Durbin, Philip <philip...@harvard.edu> wrote:
PhilThanks!Thanks, Sebastian. I know this thread is about DOIs but I feel like the conversation could be enriched by me mentioning that when a dataset includes at least one file that has successfully ingested as tabular data, a UNF is generated at the dataset level and added to the citation. Of course, this only helps if files are tabular and were successfully ingested. And the dataset-level UNF is calculated only from files that were successfully ingested (and each have a file level UNF) so it's not a great solution for when researchers don't have exclusively tabular data. For more on UNF, see http://guides.dataverse.org/en/4.8.5/developers/unfAnyway, I hear what you're saying. If you have not already created a GitHub issue describing the feature you want, please consider going ahead and creating one.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/23db8f08-0354-4aa8-b0f8-4776afc55c35%40googlegroups.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/c3d9986e-4f9f-4330-96d3-6055b789c4e5%40googlegroups.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8ExX0oM7P1JnGBX%2BFkuQQySb%2Bki4iv2dpEHF7AWLevvFA%40mail.gmail.com.
Sebastian Karcher
Mar 9, 2018, 2:39:32 PM3/9/18
to Dataverse Users Community
github ticket here: https://github.com/IQSS/dataverse/issues/4499
On Friday, March 9, 2018 at 3:13:55 AM UTC-5, Gustavo Durand wrote:
I looked to see if we already had an issue for version PIDs, but could not find one. I do plan on championing version PIDs soon after we get files done (we already started to think about them and how they could work as we were getting that issue done).
On Thu, Mar 8, 2018 at 1:17 PM, Durbin, Philip <philip...@harvard.edu> wrote:
PhilThanks!Thanks, Sebastian. I know this thread is about DOIs but I feel like the conversation could be enriched by me mentioning that when a dataset includes at least one file that has successfully ingested as tabular data, a UNF is generated at the dataset level and added to the citation. Of course, this only helps if files are tabular and were successfully ingested. And the dataset-level UNF is calculated only from files that were successfully ingested (and each have a file level UNF) so it's not a great solution for when researchers don't have exclusively tabular data. For more on UNF, see http://guides.dataverse.org/en/4.8.5/developers/unfAnyway, I hear what you're saying. If you have not already created a GitHub issue describing the feature you want, please consider going ahead and creating one.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5ef3876b-9e70-4076-8b94-3d46c146ebe1%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8GArv0mn8q%3D8JBWPF6thRD8Jybdz5QZtK6Bi%3DNgHxeq2w%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7Ebmu5bXHtnVoNziCUW0xcMwTQBt7pH5TmaPwQXH6m9w%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e534651e-bd42-4052-9fa2-dc24cb71ee75%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAF2sSee%3DDNk6vdszRtaAeFe62NVeEud%3D4sump7XhvLwuQk4GCA%40mail.gmail.com.
--
Sebastian Karcher, PhD
www.sebastiankarcher.com
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CAOSYSD7do-E1HdDthgP4S_gWeUGy1Aqdf57Pp0QDWn3d9TQe1Q%40mail.gmail.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8EGBokWYBWRfW8EAXt9oEzJb4javM_dYjDdV3G4Jko1JA%40mail.gmail.com.
--
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CANK3XXxeNMtG0e%3DaHVLK3DBVmoz7XW0uW9UyT8S3CK38GrwSSw%40mail.gmail.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/23db8f08-0354-4aa8-b0f8-4776afc55c35%40googlegroups.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/c3d9986e-4f9f-4330-96d3-6055b789c4e5%40googlegroups.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
Durand, Gustavo
Mar 13, 2018, 12:58:21 PM3/13/18
to dataverse...@googlegroups.com
Thanks, Sebastian!
On Fri, Mar 9, 2018 at 2:39 PM, Sebastian Karcher <sebastiank...@u.northwestern.edu> wrote:
github ticket here: https://github.com/IQSS/dataverse/issues/4499
On Friday, March 9, 2018 at 3:13:55 AM UTC-5, Gustavo Durand wrote:
I looked to see if we already had an issue for version PIDs, but could not find one. I do plan on championing version PIDs soon after we get files done (we already started to think about them and how they could work as we were getting that issue done).
On Thu, Mar 8, 2018 at 1:17 PM, Durbin, Philip <philip...@harvard.edu> wrote:
PhilThanks!Thanks, Sebastian. I know this thread is about DOIs but I feel like the conversation could be enriched by me mentioning that when a dataset includes at least one file that has successfully ingested as tabular data, a UNF is generated at the dataset level and added to the citation. Of course, this only helps if files are tabular and were successfully ingested. And the dataset-level UNF is calculated only from files that were successfully ingested (and each have a file level UNF) so it's not a great solution for when researchers don't have exclusively tabular data. For more on UNF, see http://guides.dataverse.org/en/4.8.5/developers/unfAnyway, I hear what you're saying. If you have not already created a GitHub issue describing the feature you want, please consider going ahead and creating one.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/c3d9986e-4f9f-4330-96d3-6055b789c4e5%40googlegroups.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsubscribe...@googlegroups.com.
To post to this group, send email to dataverse...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8ExX0oM7P1JnGBX%2BFkuQQySb%2Bki4iv2dpEHF7AWLevvFA%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To post to this group, send email to dataverse-community@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/17c970b4-048a-4e40-9843-c6b7f7aae451%40googlegroups.com.

Philipp at UiT
Jan 21, 2021, 1:14:22 AM1/21/21
to Dataverse Users Community
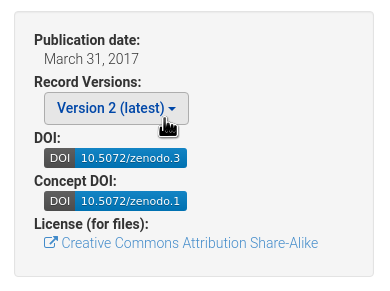
The following is a continuation from another discussion thread not primarily dealing with DOI versioning:
File DOIs are implemented in DataverseNO, and we find it a useful feature. Actually, I didn't notice that each new version of a file gets its own DOI (thanks, Amber!).
To my knowledge, there are two methods to upload a new version of a file:
a) "delete" the current version and upload a new file with the same file name;
b) replace the current version with the new version of the file (see the section "Replace Files" in the Dataverse User Guide).
Question 1:
In my own datasets, I have only used method (a). When I check one of my datasets, I see that two different versions of files with the same name, do have different DOIs. Is the same true for files that were versioned using method (b)?
Question 2:
What is that status for implementing dataset-level DOI versioning in Dataverse? I still agree with Sebastian that this is a desirable feature, because - as he has argued further up in this discussion thread:
"Datasets are often made up of multiple files. An analysis script (which itself may be part of the data and thus versioned) may point to multiple files in a dataset. It's not feasible (or desirable) for a researcher to include the DOI for every file used in a citation. They want to point to one single DOI to reference the exact data (made up of multiple files) they've been using. This is equally true for quantiative and qualitative data, btw."
Best, Philipp
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/17c970b4-048a-4e40-9843-c6b7f7aae451%40googlegroups.com.
Philipp at UiT
Jan 21, 2021, 1:17:08 AM1/21/21
to Dataverse Users Community
P.S.: The URL I provided in the initial post in this thread, does not work anymore. Please use the following URL:
Philip Durbin
Jan 21, 2021, 11:52:34 AM1/21/21
to dataverse...@googlegroups.com
Hi Philipp,
In both cases ("file replace" or "delete and re-upload"), the new file gets a new DOI. If it helps, think of the DOI as being assigned to a file with a certain checksum, a certain size, etc. This is important for reproducibility.
I believe the only thing to say status-wise about dataset-level DOI versioning in Dataverse is that an issue exists: https://github.com/IQSS/dataverse/issues/4499 . The current workaround is to use a combination of the dataset DOI and the version number (2.0 or whatever).
I hope this helps,
Phil
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5b297fd9-5c09-409c-b7da-f531575a46fdn%40googlegroups.com.
Durand, Gustavo
Jan 21, 2021, 12:04:43 PM1/21/21
to dataverse...@googlegroups.com
Hi Phillipp,
After we added file DOIs, I had advocated for version DOIs, but it has not yet been prioritized. I'd if suggest adding a comment to the issue to help demonstrate community interest.
After we added file DOIs, I had advocated for version DOIs, but it has not yet been prioritized. I'd if suggest adding a comment to the issue to help demonstrate community interest.
Thanks,
Gustavo
On Thu, Jan 21, 2021 at 11:52 AM Durbin, Philip <philip...@harvard.edu> wrote:
Hi Philipp,
In both cases ("file replace" or "delete and re-upload"), the new file gets a new DOI. If it helps, think of the DOI as being assigned to a file with a certain checksum, a certain size, etc. This is important for reproducibility.
I believe the only thing to say status-wise about dataset-level DOI versioning in Dataverse is that an issue exists: https://github.com/IQSS/dataverse/issues/4499 . The current workaround is to use a combination of the dataset DOI and the version number (2.0 or whatever).
I hope this helps,
Phil
On Thu, Jan 21, 2021 at 1:17 AM Philipp at UiT <uit.p...@gmail.com> wrote:
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5b297fd9-5c09-409c-b7da-f531575a46fdn%40googlegroups.com.
--
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/CABbxx8HwirJRR09HFsb%3DpfZiQ7igJ2WdCChN1zy%2BTsak3FgVNw%40mail.gmail.com.
Philipp at UiT
Jan 22, 2021, 2:18:39 AM1/22/21
to Dataverse Users Community
Thanks, Gustavo and Phil! I have left a note in the GitHub issue.

Amber Leahey
Mar 2, 2021, 11:15:00 AM3/2/21
to Dataverse Users Community
This may be a silly question, have many installations enabled the file DOI feature? I can't see this in the main Harvard installation is there any concern about doing so?
I'm not sure what kind of maintenance this will require long-term so we haven't yet.

{kind=link}
{kind=link}
{kind=link}
Sherry Lake
Mar 2, 2021, 11:49:31 AM3/2/21
to dataverse...@googlegroups.com
UVa has not enabled file DOIs.
danny...@g.harvard.edu
Mar 2, 2021, 12:01:16 PM3/2/21
to Dataverse Users Community
Hey Amber and all, on Harvard Dataverse we've temporarily disabled File PIDs while we work on this issue:
We were seeing some issues when datasets with large numbers of files were being registered, so we'd like to optimize this in order to ensure system stability before turning it back on a publish time or at create time using a new reserve feature.
Endpoints exist for minting File PIDs for all files (https://guides.dataverse.org/en/latest/admin/dataverses-datasets.html#mint-pids-for-files-that-do-not-have-them) and individual files (https://guides.dataverse.org/en/latest/admin/dataverses-datasets.html#mint-a-pid-for-a-file-that-does-not-have-one). We plan to periodically mint DOIs for files using this process in the meantime.
- Danny
Philipp at UiT
Mar 3, 2021, 2:15:35 AM3/3/21
to Dataverse Users Community
DataverseNO has enabled file DOIs. We're looking forward to some of the related issues being solved:
- Issues related to datasets with large numbers of files (see Danny's comment above)
- Issues related to granularity of PID reference in services like DataCite; see Dataverse GitHub issue #5086, and PID Forum posting 1084.
Best, Philipp
Reply all
Reply to author
Forward
0 new messages