Extremeley slow downloads
491 views
Skip to first unread message

Nikolay Kadochnikov
Aug 23, 2022, 10:08:55 AM8/23/22
to Common Crawl
Good day everyone.
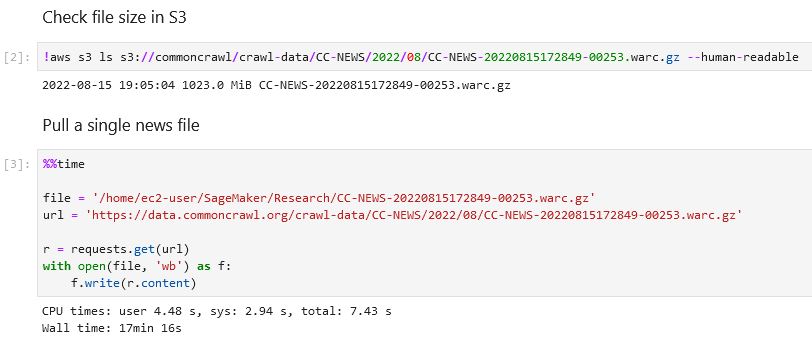
I am extracting data from Common Crawl news, as part of my research project. It used to take about 6 seconds seconds to download a single 1Gb WARC file, but starting from yesterday it is taking ~17 minutes on average.
I thought my traffic from Google Cloud was getting throttled, so I decided to try running it from AWS Sagemaker... but getting the same 17 minutes per file speeds. Can you please provide guidance on how to get the download speed back to normal?

Sebastian Nagel
Aug 23, 2022, 11:02:15 AM8/23/22
to common...@googlegroups.com
Hi Nikolay,
if you're using Amazon Sagemaker, it's strongly recommended
to use the S3 API and run the instance in the AWS region "us-east-1"
where the bucket s3://commoncrawl/ is located.
If just verified the download speed on an EC2 instance running
in us-east-1:
$> time aws s3 cp
s3://commoncrawl/crawl-data/CC-NEWS/2022/08/CC-NEWS-20220815172849-00253.warc.gz
.
download:
s3://commoncrawl/crawl-data/CC-NEWS/2022/08/CC-NEWS-20220815172849-00253.warc.gz
to ./CC-NEWS-20220815172849-00253.warc.gz
real 0m5.947s
user 0m4.668s
sys 0m4.262s
Accessing the same file via CloudFront may take longer (right now it
definitely takes longer). Could you try to use the S3 API?
From a Jupyter Python notebook, you typically would use boto3, e.g.
import boto3
s3client = boto3.client('s3', use_ssl=False)
with open('local_path', 'wb') as data:
s3client.download_fileobj(
'commoncrawl',
'crawl-data/CC-NEWS/2022/08/CC-NEWS-20220815172849-00253.warc.gz',
data
)
data.seek(0)
# process data
See also:
https://commoncrawl.org/access-the-data/
https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html
Best,
Sebastian
On 8/23/22 16:08, Nikolay Kadochnikov wrote:
> Good day everyone.
>
> I am extracting data from Common Crawl news, as part of my research
> project. It used to take about 6 seconds seconds to download a single
> 1Gb WARC file, but starting from yesterday it is taking ~17 minutes on
> average.
>
> I thought my traffic from Google Cloud was getting throttled, so I
> decided to try running it from AWS Sagemaker... but getting the same 17
> minutes per file speeds. Can you please provide guidance on how to get
> the download speed back to normal?
>
> 2022-08-23 09_04_02-JupyterLab — Mozilla Firefox.jpg
>
if you're using Amazon Sagemaker, it's strongly recommended
to use the S3 API and run the instance in the AWS region "us-east-1"
where the bucket s3://commoncrawl/ is located.
If just verified the download speed on an EC2 instance running
in us-east-1:
$> time aws s3 cp
s3://commoncrawl/crawl-data/CC-NEWS/2022/08/CC-NEWS-20220815172849-00253.warc.gz
.
download:
s3://commoncrawl/crawl-data/CC-NEWS/2022/08/CC-NEWS-20220815172849-00253.warc.gz
to ./CC-NEWS-20220815172849-00253.warc.gz
real 0m5.947s
user 0m4.668s
sys 0m4.262s
Accessing the same file via CloudFront may take longer (right now it
definitely takes longer). Could you try to use the S3 API?
From a Jupyter Python notebook, you typically would use boto3, e.g.
import boto3
s3client = boto3.client('s3', use_ssl=False)
with open('local_path', 'wb') as data:
s3client.download_fileobj(
'commoncrawl',
'crawl-data/CC-NEWS/2022/08/CC-NEWS-20220815172849-00253.warc.gz',
data
)
data.seek(0)
# process data
See also:
https://commoncrawl.org/access-the-data/
https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html
Best,
Sebastian
On 8/23/22 16:08, Nikolay Kadochnikov wrote:
> Good day everyone.
>
> I am extracting data from Common Crawl news, as part of my research
> project. It used to take about 6 seconds seconds to download a single
> 1Gb WARC file, but starting from yesterday it is taking ~17 minutes on
> average.
>
> I thought my traffic from Google Cloud was getting throttled, so I
> decided to try running it from AWS Sagemaker... but getting the same 17
> minutes per file speeds. Can you please provide guidance on how to get
> the download speed back to normal?
>
>
Nikolay Kadochnikov
Aug 23, 2022, 11:24:51 AM8/23/22
to common...@googlegroups.com
Thanks a lot for the quick response, Sebastian. Unfortunately, I have to run everytihng on GCP (I only used AWS Sagemaker for testing). And it looks like I can't use boto3 method without valid AWS credentials
NoCredentialsError: Unable to locate credentials
Do you know if there is any other way to make it faster or to use boto3 with anonymous credentials?
From: common...@googlegroups.com <common...@googlegroups.com> on behalf of Sebastian Nagel <seba...@commoncrawl.org>
Sent: Tuesday, August 23, 2022 10:02
To: common...@googlegroups.com <common...@googlegroups.com>
Subject: Re: [cc] Extremeley slow downloads
Sent: Tuesday, August 23, 2022 10:02
To: common...@googlegroups.com <common...@googlegroups.com>
Subject: Re: [cc] Extremeley slow downloads
--
You received this message because you are subscribed to a topic in the Google Groups "Common Crawl" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/common-crawl/atjkwHO6WwQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/80000238-2a31-8723-8839-ef36defc28a5%40commoncrawl.org.
You received this message because you are subscribed to a topic in the Google Groups "Common Crawl" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/common-crawl/atjkwHO6WwQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/80000238-2a31-8723-8839-ef36defc28a5%40commoncrawl.org.
Nikolay Kadochnikov
Aug 23, 2022, 11:39:17 AM8/23/22
to common...@googlegroups.com
FYI, I also tried
s3client = boto3.client('s3', use_ssl=False, config=Config(signature_version=UNSIGNED),region_name='us-east-1')
But this results in ClientError: An error occurred (403) when calling the HeadObject operation: Forbidden
From: common...@googlegroups.com <common...@googlegroups.com> on behalf of Nikolay Kadochnikov <kadoc...@uchicago.edu>
Sent: Tuesday, August 23, 2022 10:24
Sent: Tuesday, August 23, 2022 10:24
To view this discussion on the web visit
https://groups.google.com/d/msgid/common-crawl/BN6PR11MB40842F57238D37C4D878B992C2709%40BN6PR11MB4084.namprd11.prod.outlook.com.
Sebastian Nagel
Aug 24, 2022, 4:33:50 AM8/24/22
to common...@googlegroups.com
Hi Nikolay,
unauthenticated access via the S3 API was disabled in April, in order to
keep growing size and usage of the data manageable. See [1] for details.
> Unfortunately, I have to run everything on GCP (I only used AWS
> Sagemaker for testing).
Understood. The data resp. access bandwidth is shared among all users,
and it's clear that no resource is infinite, internet bandwidth for
sure. From time to time, and usually only for a short time (max. few
days) access may become slow. Please be patient!
Best and thanks,
Sebastian
[1]
https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/
On 8/23/22 17:39, Nikolay Kadochnikov wrote:
> FYI, I also tried
>
> s3client = boto3.client('s3', use_ssl=False,
> config=Config(signature_version=UNSIGNED),region_name='us-east-1')
>
> But this results in ClientError: An error occurred (403) when calling
> the HeadObject operation: Forbidden
> ------------------------------------------------------------------------
> *From:* common...@googlegroups.com <common...@googlegroups.com> on
> *To:* common...@googlegroups.com <common...@googlegroups.com>
> *Subject:* Re: [cc] Extremeley slow downloads
> *From:* common...@googlegroups.com <common...@googlegroups.com> on
> *To:* common...@googlegroups.com <common...@googlegroups.com>
> *Subject:* Re: [cc] Extremeley slow downloads
> <https://commoncrawl.org/access-the-data/>
>
> https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/
> <https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/>
>
> https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html
unauthenticated access via the S3 API was disabled in April, in order to
keep growing size and usage of the data manageable. See [1] for details.
> Unfortunately, I have to run everything on GCP (I only used AWS
> Sagemaker for testing).
Understood. The data resp. access bandwidth is shared among all users,
and it's clear that no resource is infinite, internet bandwidth for
sure. From time to time, and usually only for a short time (max. few
days) access may become slow. Please be patient!
Best and thanks,
Sebastian
[1]
https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/
On 8/23/22 17:39, Nikolay Kadochnikov wrote:
> FYI, I also tried
>
> s3client = boto3.client('s3', use_ssl=False,
> config=Config(signature_version=UNSIGNED),region_name='us-east-1')
>
> But this results in ClientError: An error occurred (403) when calling
> the HeadObject operation: Forbidden
> *From:* common...@googlegroups.com <common...@googlegroups.com> on
> behalf of Nikolay Kadochnikov <kadoc...@uchicago.edu>
> *Sent:* Tuesday, August 23, 2022 10:24
> *To:* common...@googlegroups.com <common...@googlegroups.com>
> *Subject:* Re: [cc] Extremeley slow downloads
>
> Thanks a lot for the quick response, Sebastian. Unfortunately, I have
> to run everytihng on GCP (I only used AWS Sagemaker for testing). And
> it looks like I can't use boto3 method without valid AWS credentials
>
> NoCredentialsError: Unable to locate credentials
>
> Do you know if there is any other way to make it faster or to use boto3
> with anonymous credentials?
>
>
>
> ------------------------------------------------------------------------
> Thanks a lot for the quick response, Sebastian. Unfortunately, I have
> to run everytihng on GCP (I only used AWS Sagemaker for testing). And
> it looks like I can't use boto3 method without valid AWS credentials
>
> NoCredentialsError: Unable to locate credentials
>
> Do you know if there is any other way to make it faster or to use boto3
> with anonymous credentials?
>
>
>
> *From:* common...@googlegroups.com <common...@googlegroups.com> on
> behalf of Sebastian Nagel <seba...@commoncrawl.org>
> *Sent:* Tuesday, August 23, 2022 10:02
> *To:* common...@googlegroups.com <common...@googlegroups.com>
> *Subject:* Re: [cc] Extremeley slow downloads
>
> https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/
> <https://commoncrawl.org/2022/03/introducing-cloudfront-access-to-common-crawl-data/>
>
> https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html
Nikolay Kadochnikov
Aug 24, 2022, 10:03:24 AM8/24/22
to common...@googlegroups.com
Thanks for your continuous support, Sebastian. I figured-out that I could use my AWS credentials to authenticate into boto3, while running it on GCP. All set for now.
From: common...@googlegroups.com <common...@googlegroups.com> on behalf of Sebastian Nagel <seba...@commoncrawl.org>
Sent: Wednesday, August 24, 2022 3:33
To: common...@googlegroups.com <common...@googlegroups.com>
Subject: Re: [cc] Extremeley slow downloads
Sent: Wednesday, August 24, 2022 3:33
To: common...@googlegroups.com <common...@googlegroups.com>
Subject: Re: [cc] Extremeley slow downloads
--
You received this message because you are subscribed to a topic in the Google Groups "Common Crawl" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/common-crawl/atjkwHO6WwQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to common-crawl...@googlegroups.com.
You received this message because you are subscribed to a topic in the Google Groups "Common Crawl" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/common-crawl/atjkwHO6WwQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit
https://groups.google.com/d/msgid/common-crawl/c282e632-4345-be4b-80b1-58655f0655b0%40commoncrawl.org.

AlexGahe
Aug 28, 2022, 4:59:05 AM8/28/22
to Common Crawl
Hi,
Will connection issues with Cloudfront (max bandwidth suddenly down to 1MB/s) be fixed or is it now permanent ?
Regards
AG
Reply all
Reply to author
Forward
0 new messages