is there a way to download data faster?
365 views
Skip to first unread message

Davood Hadiannejad
Aug 25, 2022, 10:46:26 AM8/25/22
to Common Crawl
I have like 100 URLs, and I wanna download data for these URLs from common crawl, but it takes so long time, is there any way/example, to download the data faster?
by the way, I am using this documentation to downloads:

Sebastian Nagel
Aug 25, 2022, 1:17:31 PM8/25/22
to common...@googlegroups.com
Hi Davood,
could you share what exactly you want to download?
If it's about the 100 page captures, you can send range
requests and download only the 100 WARC records. In short,
downloading and unpacking a single WARC record could be done
by running
curl --silent --range $offset-$(($offset+$length-1)) \
https://data.commoncrawl.org/path_to_warc.gz \
| gzip -dc
The paths to WARC files, record offsets and lenghts are
stored in the URL index.
Best,
Sebastian
could you share what exactly you want to download?
If it's about the 100 page captures, you can send range
requests and download only the 100 WARC records. In short,
downloading and unpacking a single WARC record could be done
by running
curl --silent --range $offset-$(($offset+$length-1)) \
https://data.commoncrawl.org/path_to_warc.gz \
| gzip -dc
The paths to WARC files, record offsets and lenghts are
stored in the URL index.
Best,
Sebastian
Davood Hadiannejad
Aug 26, 2022, 10:38:58 AM8/26/22
to common...@googlegroups.com
Hi Sebastian,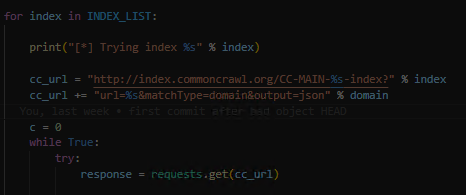
thank you for your reply. I have some domain lists Like: domains = ["rtl.de", "bunte.de", "gala.de"] . first, I do a query the corresponding index to each crawl listed in index_list = ['2022-05', '2021-49', '2021-43', '2021-39', '2021-31'] for the domain like:
this returns at the end: a list of records that contains URLs and meta informations corresponding to the domain.
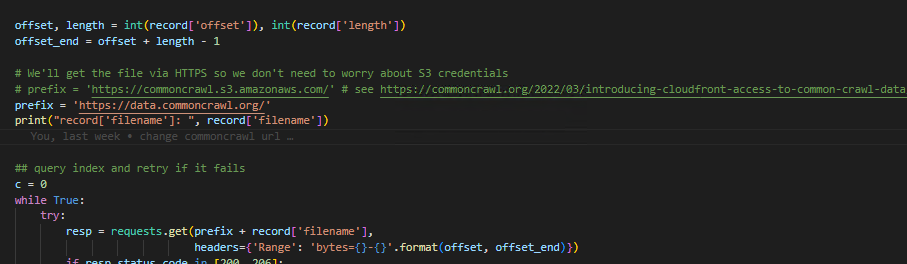
Then I try to download the records from commoncreal like:
But it takes a very long time, is there a way/example to do so faster?
Best
Davood
--
You received this message because you are subscribed to the Google Groups "Common Crawl" group.
To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/eea5a198-628d-4b1c-3a89-4eb57c01b728%40commoncrawl.org.
Sebastian Nagel
Aug 26, 2022, 1:53:19 PM8/26/22
to common...@googlegroups.com
Hi Davood,
the code to fetch the WARC records looks very reasonable.
The only way to speed it up:
- try concurrent requests (this should be possible up to a
certain limit)
- maybe shuffle the list of WARC records beforehand, so that
different path prefixes are intermixed
- of course, most effective would be to move the computation
closer to the data, ideally into AWS us-east-1
One point: depending whether there are many records for a domain
you'd need to iterate over result pages, see [1].
Best,
Sebastian
[1]
https://pywb.readthedocs.io/en/latest/manual/cdxserver_api.html#pagination-api
On 8/26/22 16:38, Davood Hadiannejad wrote:
> Hi Sebastian,
> thank you for your reply. I have some domain lists Like: domains =
> ["rtl.de <http://rtl.de>", "bunte.de <http://bunte.de>", "gala.de
> <http://gala.de>"] . first, I do a query the corresponding index to each
> <mailto:common-crawl%2Bunsu...@googlegroups.com>.
> <https://groups.google.com/d/msgid/common-crawl/CAGSSPFaKWS8Dve2oX7730Yw5x7%3D2yPBzE-C%3DUc0xwKpLb%2BrDxA%40mail.gmail.com?utm_medium=email&utm_source=footer>.
the code to fetch the WARC records looks very reasonable.
The only way to speed it up:
- try concurrent requests (this should be possible up to a
certain limit)
- maybe shuffle the list of WARC records beforehand, so that
different path prefixes are intermixed
- of course, most effective would be to move the computation
closer to the data, ideally into AWS us-east-1
One point: depending whether there are many records for a domain
you'd need to iterate over result pages, see [1].
Best,
Sebastian
[1]
https://pywb.readthedocs.io/en/latest/manual/cdxserver_api.html#pagination-api
On 8/26/22 16:38, Davood Hadiannejad wrote:
> Hi Sebastian,
> thank you for your reply. I have some domain lists Like: domains =
> <http://gala.de>"] . first, I do a query the corresponding index to each
> crawl listed in index_list = ['2022-05', '2021-49', '2021-43',
> '2021-39', '2021-31'] for the domain like:
> '2021-39', '2021-31'] for the domain like:
> image.png
>
> this returns at the end: a list of records that contains URLs and meta
> informations corresponding to the domain.
> Then I try to download the records from commoncreal like:
>
>
> this returns at the end: a list of records that contains URLs and meta
> informations corresponding to the domain.
> Then I try to download the records from commoncreal like:
>
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/eea5a198-628d-4b1c-3a89-4eb57c01b728%40commoncrawl.org
> <https://groups.google.com/d/msgid/common-crawl/eea5a198-628d-4b1c-3a89-4eb57c01b728%40commoncrawl.org>.
> https://groups.google.com/d/msgid/common-crawl/eea5a198-628d-4b1c-3a89-4eb57c01b728%40commoncrawl.org
>
> --
> You received this message because you are subscribed to the Google
> Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to common-crawl...@googlegroups.com
> <mailto:common-crawl...@googlegroups.com>.
> --
> You received this message because you are subscribed to the Google
> Groups "Common Crawl" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to common-crawl...@googlegroups.com
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/common-crawl/CAGSSPFaKWS8Dve2oX7730Yw5x7%3D2yPBzE-C%3DUc0xwKpLb%2BrDxA%40mail.gmail.com
> <https://groups.google.com/d/msgid/common-crawl/CAGSSPFaKWS8Dve2oX7730Yw5x7%3D2yPBzE-C%3DUc0xwKpLb%2BrDxA%40mail.gmail.com?utm_medium=email&utm_source=footer>.
Davood Hadiannejad
Aug 29, 2022, 10:04:02 AM8/29/22
to common...@googlegroups.com
Hi
Sebastian,
Thank you very much again for your help. If I wanna use AWS, which service is appropriate, for downloading the Data from the common crawl and preprocessing the data? there are a lot of services like EC2, Athena ...
Thank you in advance and best regards
Davood
To unsubscribe from this group and stop receiving emails from it, send an email to common-crawl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/common-crawl/6e406971-701d-08e4-9e6e-8f66b7068fdc%40commoncrawl.org.
Reply all
Reply to author
Forward
0 new messages