FLUCALC Question
17 views
Skip to first unread message

C J
Jul 25, 2019, 6:51:08 PM7/25/19
to chibolts
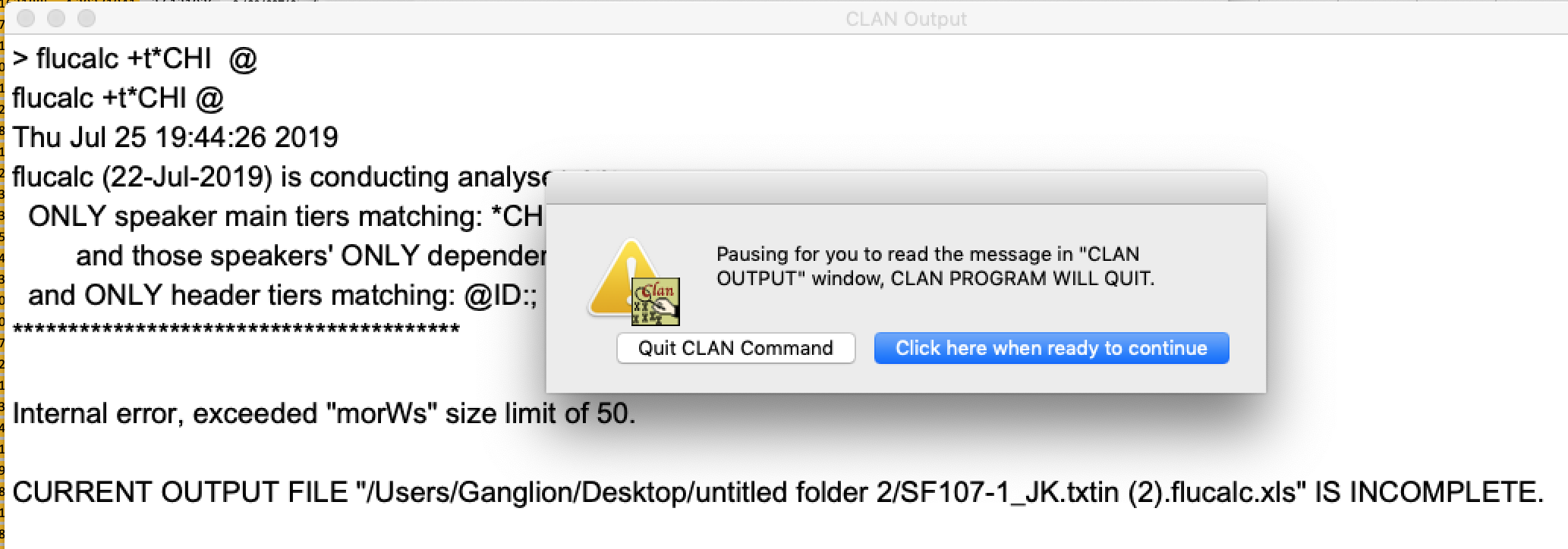
I have been attempting to run FLUCALC on a mac with the newest CLAN and most recent version of OS. Is there a way to override the error that doesn't let FLUCALC run on a file with utterances longer than 50 words? Anytime I include one of these files, the FLUCALC file is 0 bytes and empty, and I get an error in CLAN. Sometimes, CLAN also gives me the error message (attached as screenshot) and forces me to close the program.

Leonid Spektor
Jul 25, 2019, 7:39:02 PM7/25/19
to chib...@googlegroups.com
Hi CJ,
The screenshot that you attached to your email is cut short. The actual error message is at the bottom of Clan Output window. The dialog box just lets you read the message before CLAN quits automatically. I can't see the error message, so I can't help with it.
The 50 words limit can not be overwritten. If your file has exceeded that limit, then it likely wasn't transcribed correctly. FLUCALC shows the utterance that has exceeded that limit and should be changed in some way to make it shorter. Perhaps it can be broken up into two. If you think that this line is correct, then please email it or the file it is in to us and we will see if maybe the 50 words limit should be increased.
Leonid~
I have been attempting to run FLUCALC on a mac with the newest CLAN and most recent version of OS. Is there a way to override the error that doesn't let FLUCALC run on a file with utterances longer than 50 words? Anytime I include one of these files, the FLUCALC file is 0 bytes and empty, and I get an error in CLAN. Sometimes, CLAN also gives me the error message (attached as screenshot) and forces me to close the program.
--
You received this message because you are subscribed to the Google Groups "chibolts" group.
To unsubscribe from this group and stop receiving emails from it, send an email to chibolts+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/chibolts/a0c8e281-1ccd-4f48-bda7-6cef1ebb71b8%40googlegroups.com.
<Screen Shot 2019-07-25 at 6.50.13 PM.png>

C Johnson
Jul 25, 2019, 7:51:23 PM7/25/19
to chib...@googlegroups.com
Hi Leonid,
Thanks for your quick response! The error message that was cut off indicated that the utterance was more than 50 words. I have attached another screenshot here.
The error that keeps popping up often gives examples of utterances with multiple revisions or phrase repetitions as examples if the program does not force me to quit altogether. The content of the utterances which is not repeated seems to be under 50 words. I've attached another screenshot with an example.
Best,
Chelsea
You received this message because you are subscribed to a topic in the Google Groups "chibolts" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/chibolts/-ShkcvldQss/unsubscribe.
To unsubscribe from this group and all its topics, send an email to chibolts+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/chibolts/288DCB17-529E-4D03-83E9-92469A65630A%40andrew.cmu.edu.
Chelsea Johnson
Ph.D. Student, Dept of Communicative Sciences & Disorders
Michigan State University
1026 Red Cedar Road, Room 210C
Oyer Speech & Hearing Building
East Lansing, MI 48824
Leonid Spektor
Jul 25, 2019, 8:30:11 PM7/25/19
to chib...@googlegroups.com
Hi Chelsea,
The error that forces CLAN to quit shouldn't do that. I will try to change it. It would help a lot if you could send to me directly the SF107-1_JK file so that I could replicate the error.
The other error that shows an example of long utterance is something I would have to consult people at our end with to see if that utterance is legitimate and 50 words limit should be increased or if the utterance should be changed. The idea is that if the whole utterance is longer than 50 words, then there is likely something wrong wit it.
Leonid~
> On Jul 25, 2019, at 19:50, C Johnson <john...@msu.edu> wrote:
>
> Chelsea
The error that forces CLAN to quit shouldn't do that. I will try to change it. It would help a lot if you could send to me directly the SF107-1_JK file so that I could replicate the error.
The other error that shows an example of long utterance is something I would have to consult people at our end with to see if that utterance is legitimate and 50 words limit should be increased or if the utterance should be changed. The idea is that if the whole utterance is longer than 50 words, then there is likely something wrong wit it.
Leonid~
> On Jul 25, 2019, at 19:50, C Johnson <john...@msu.edu> wrote:
>
> Chelsea

Nan Bernstein Ratner
Jul 25, 2019, 11:40:35 PM7/25/19
to chib...@googlegroups.com
Chelsea, from what I can see, it is POSSIBLE that this utterance is best parsed into smaller units. Certainly the last phrase fulfills some definitions as its own utterance, structurally (it's a "sentence" in its own right), but utterances usually have more complex determinants. Criteria vary, but we tend to use "2 out of 3" set of criteria to potentially separate long turns like this into shorter utterances: is there a final contour to some phrases in the middle of this run, are there silences or respiratory intakes, and does something stand as a grammatical "sentence" or phrase. Only 2 need apply for us to segment something like this into smaller units. These sorts of determinations are important for other reasons, since so many kid language measures are proportioned over utterances, such as MLU, IPSYN, DSS, etc. If some transcribers are making "maximal" decisions about where utterances end, and others are more conservative, you will wind up with some very variable estimates of language, not just fluency.
It would be impossible to know if any part of this qualified to be divided out without the audio. If you wanted to share a clip with me privately, I might be able to provide some guidance.
I can definitely see a situation where, if a speaker were sufficiently disfluent, and each disfluency counts as a word as well as the actual words, that setting a limit of 50 per utterance COULD run up against some problems. But the current limit is an attempt to prevent people from placing turns, rather than utterances, on speaker tiers, since so many language variables proportion over utterances, not turns.
best,
N
Nan Bernstein Ratner, F-, H-ASHA, F-AAAS, ABCLD
Professor
Hearing and Speech Sciences
University of Maryland
0100 Lefrak Hall
College Park, MD 20742
Co-director: FluencyBank (www.fluency.talkbank.org); http://languagefluency.umd.edu/
President, International Fluency Association (IFA; http://theifa.org)
Director, University of Maryland Autism Research Consortium (UMARC), www.autism.umd.edu
Faculty, Language Science (languagescience.umd.edu; Neuroscience & Cognitive Neuroscience (NACS, nacs.umd.edu), Developmental Science Field Committee
To view this discussion on the web visit https://groups.google.com/d/msgid/chibolts/CAKvHuSfHQPai6gSrCLHo9rj8hqQf%2B93F7nX1KJyLyWXAKnoLUw%40mail.gmail.com.
C Johnson
Jul 26, 2019, 12:28:13 PM7/26/19
to chib...@googlegroups.com
Hi Dr. Ratner and Leonid,
Thanks so much for your input! I'm going to listen to these files again and see if I can get FLUCALC to work after another sweep. I will let you know if I have any other questions.
Best,
Chelsea
To view this discussion on the web visit https://groups.google.com/d/msgid/chibolts/CAAFocx6BwbpAHia1wqByQ64ztZPFK4zJX-vJFzDSxoeiM%3D0jjA%40mail.gmail.com.
Leonid Spektor
Jul 26, 2019, 2:59:15 PM7/26/19
to ChiBolts
Chelsea,
Leonid.
I have changed the error that quit CLAN to instead give you an example of utterance that has more than 50 words. The CLAN will not quit now. This should make it easier to find all tiers that might need to be changed. New CLAN is on the web.
Leonid.
On Jul 25, 2019, at 19:50, C Johnson <john...@msu.edu> wrote:
To view this discussion on the web visit https://groups.google.com/d/msgid/chibolts/CAKvHuSfHQPai6gSrCLHo9rj8hqQf%2B93F7nX1KJyLyWXAKnoLUw%40mail.gmail.com.


{kind=link}
{kind=link}
{kind=link}
Reply all
Reply to author
Forward
0 new messages