Identify sentences in standoff format

Shikhar Misra
I was wondering if is possible to identify the labels that belong to a single sentence from the standoff format. Is it possible to separate the sentences and get the labels separately for them?
Shikhar.

Goran Topic
brat_dir = '/PATH/TO/BRAT' # change this
import pathlib
import os
import sys
from collections import OrderedDict
document_path = sys.argv[1] # without extension!
sys.path.append(brat_dir)
sys.path.append(os.path.join(brat_dir, 'server', 'src'))
from document import _document_json_dict
json_dict = _document_json_dict(document_path)
sentence_offsets = json_dict['sentence_offsets']
spans = json_dict['triggers'] + json_dict['entities']
sentence_spans = OrderedDict((sentence_offset, [])
for sentence_offset in sentence_offsets)
for id, label, span_offsets in spans:
for sentence_offset, span_list in sentence_spans.items():
if sentence_offset[0] <= span_offsets[0][0] < sentence_offset[1]:
span_list.append(id)
continue
print(list(sentence_spans.values()))
--
---
You received this message because you are subscribed to the Google Groups "brat-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to brat-users+...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/brat-users/80846f70-1996-47b7-b59e-254b58f04f29%40googlegroups.com.
Shikhar Misra
To unsubscribe from this group and stop receiving emails from it, send an email to brat-...@googlegroups.com.

Shah Kash
--
---
You received this message because you are subscribed to the Google Groups "brat-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to brat-users+...@googlegroups.com.
Goran Topic
To unsubscribe from this group and stop receiving emails from it, send an email to brat-users+...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/brat-users/535ce949-0417-4ace-9df5-ef57992a7519%40googlegroups.com.
Goran Topic
To view this discussion on the web, visit https://groups.google.com/d/msgid/brat-users/CAJozNO4e3VYri1Kxf-nA9mzTD0qyJ-Sd2zDSder25wRKKH0Wow%40mail.gmail.com.
Shikhar Misra
I have attached the image of pandas dataframe with just one column having paragraph and its appropriate predicted labels which are obtained through a trained model in the brat format.
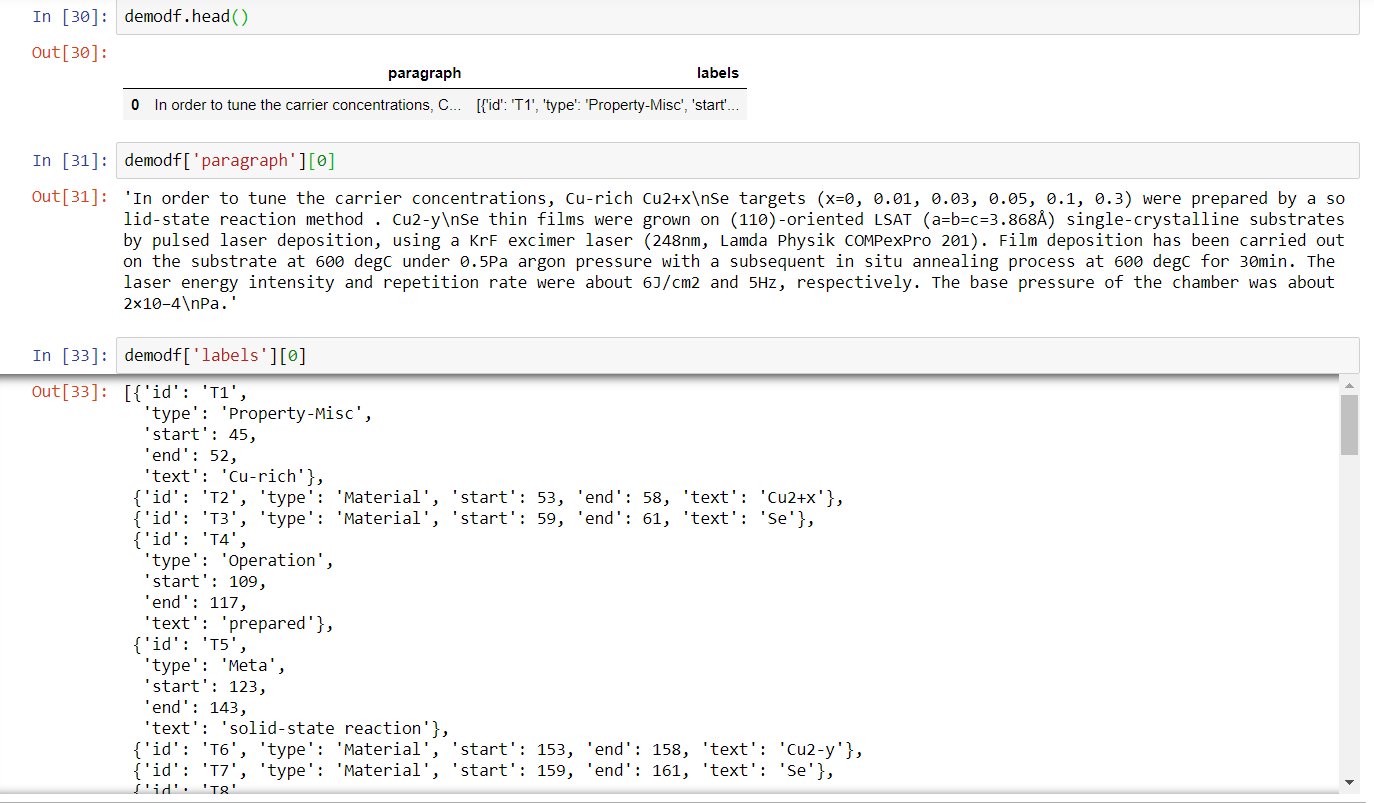
I have uploaded the sample .txt and .ann file. One alternative is to separate the paragraph into sentences and get the annotation prediction sentence-by-sentence but that takes a lot of time for a large dataset. I was wondering if I can directly separate the demodf['labels] into sentences using information from demodf['paragraph']. The desired output can be 2D list with each list corresponding to annotations from separate sentences like shown in the screenshot below:
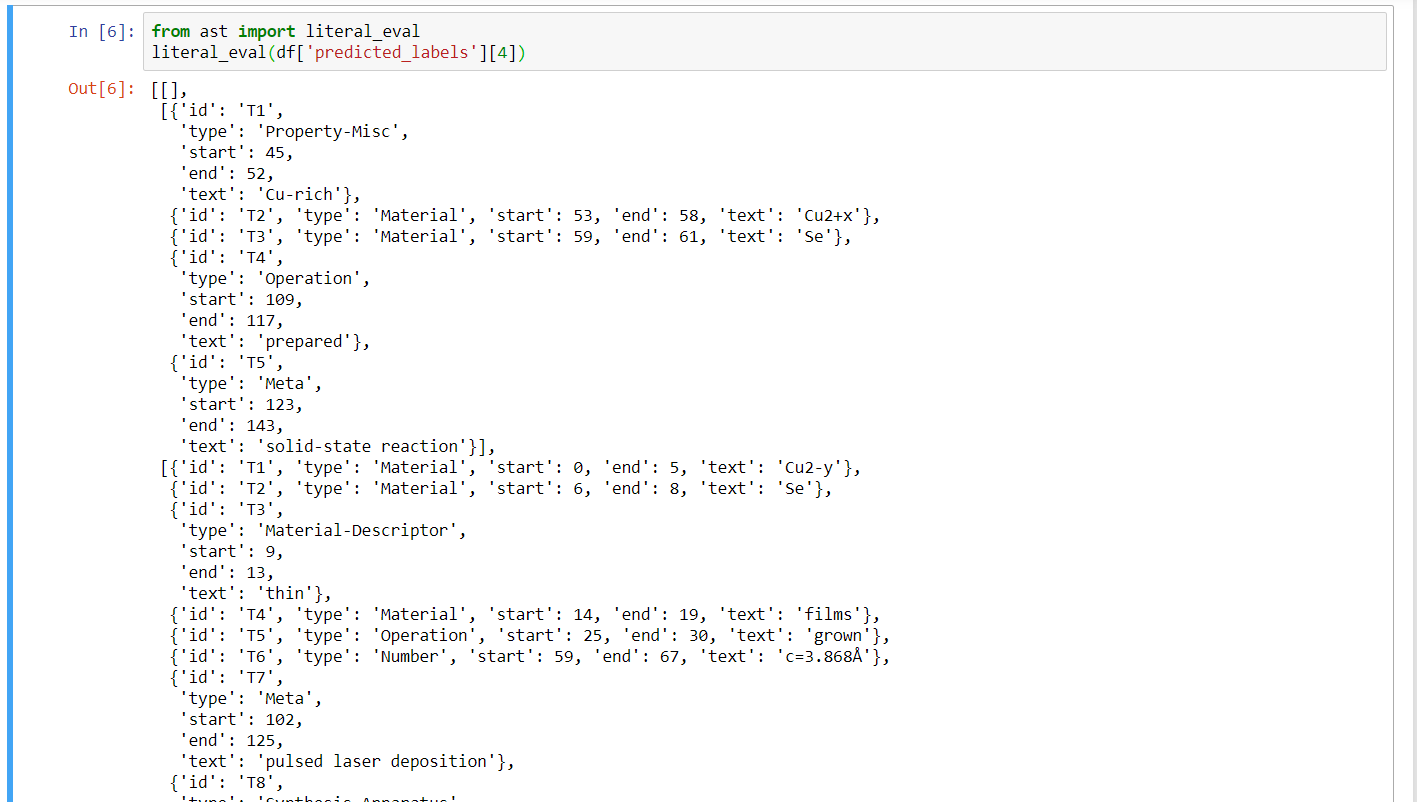
To view this discussion on the web, visit https://groups.google.com/d/msgid/brat-users/535ce949-0417-4ace-9df5-ef57992a7519%40googlegroups.com.
Goran Topic
To unsubscribe from this group and stop receiving emails from it, send an email to brat-users+...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/brat-users/fc732e0a-8fff-4102-b92e-7be03597352c%40googlegroups.com.
Shah Kash
To view this discussion on the web, visit https://groups.google.com/d/msgid/brat-users/CAGMASUNs7Kh9gj1tja9c1QMqVseJNMtE7BkeUpK2KsyNfekNOA%40mail.gmail.com.