Cell size
177 views
Skip to first unread message

thenewb...@gmail.com
Mar 14, 2019, 7:29:56 AM3/14/19
to Biodiverse Users
Hi,
I have a question about the cell size. I have coordinates of 1 Km of resolution, which cell size should I use for my analysis?
Thank you ver much.

Shawn Laffan
Mar 14, 2019, 7:39:43 AM3/14/19
to biodiver...@googlegroups.com
It depends what level of detail you need and how reliable your data are.
If the data are non-systematic point observations (e.g. museum or atlas data) then you will need to aggregate the data to a resolution at which the sampling artefacts are sufficiently reduced. This is a trade off, as if the size is too coarse then you will lose some or all of the patterns you are interested in.
One option is to experiment with different cell sizes to see what happens. Alternately, experiment with a relatively fine cell size and change the window size of your analyses.
https://github.com/shawnlaffan/biodiverse/wiki/FAQ#what-neighbourhood-size-should-i-use
There is also the data set size which can become an issue if you have many labels, many groups (cells), and/or a small cell size.
Can you provide some more specific details?
Shawn.
If the data are non-systematic point observations (e.g. museum or atlas data) then you will need to aggregate the data to a resolution at which the sampling artefacts are sufficiently reduced. This is a trade off, as if the size is too coarse then you will lose some or all of the patterns you are interested in.
One option is to experiment with different cell sizes to see what happens. Alternately, experiment with a relatively fine cell size and change the window size of your analyses.
https://github.com/shawnlaffan/biodiverse/wiki/FAQ#what-neighbourhood-size-should-i-use
There is also the data set size which can become an issue if you have many labels, many groups (cells), and/or a small cell size.
Can you provide some more specific details?
Shawn.
--
You received this message because you are subscribed to the Google Groups "Biodiverse Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to biodiverse-use...@googlegroups.com.
To post to this group, send email to biodiver...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/3597ed77-8a92-4b0d-83ab-f83990f46629%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Julio A
Jan 16, 2020, 11:22:55 AM1/16/20
to biodiver...@googlegroups.com
Hi,
Last year I used Biodiverse successfully. Nowadays I want to use it again because I think is a very useful tool, but I have some doubts again.
First of all: I must work with a grid whose little squares (Image 1) must have 1Km x 1 Km of resolution. And I´m not sure about what I have to write in this box (Image 2). What number should I use? I´m not using museum information. I´m using real information I mean field data.
Secondly: I Would like to know if is posible to export the map with the values of PD in each little square (image 3) to a raster file or something like that to work in QGis or ArcGis. How can I do it?
Thank you very much.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/48e35048-fd60-e3da-6acf-a7ffbae4a146%40unsw.edu.au.

Dillon Jones
Jan 16, 2020, 11:58:34 AM1/16/20
to biodiver...@googlegroups.com
Its been a bit since I used biodiverse but I tested with my data. It depends on the projection and the coordinates you use for your data. For example, I use lat/long decimal degrees in the WGS84 projection. In my format, 1 decimal degree (resolution of 1) is 111km, so assuming my math is correct a 1km resolution would be 1/111 = .009. That is what you would put in your image 2 box, but again, it depends on your data.
More info is here: https://github.com/shawnlaffan/biodiverse/wiki/SampleSession#importing-data
When you want to export your analyses, you should be able to just hit export on the left-hand side of the analysis screen and select the format you desire. I exported as a shapefile and got the values of a richness analysis when I opened in QGIS.
Hope this helps.
-Dillon
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/CAL3sgmENG9NcFKhynz5LbzWfMVodgHP-GFyWWVhViV%3DYezsbXw%40mail.gmail.com.
Julio A
Jan 16, 2020, 12:03:52 PM1/16/20
to biodiver...@googlegroups.com
Hi!
Thank you very very much. I'll try it as soon as posible and I will write to say if it worked.
I found how to export the information of the PD map and I tried to open it in QGis. I used a shapefile but I didn't work.
I think Im not doing It properly but if you say that it's possible I keep trying.
Thank you so much again.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/CAJOWYY2oF6Ddjoih%3DsbygEoHFXNwvgMDPDRFHs%2BkQnMMqpVQUg%40mail.gmail.com.
Julio A
Jan 16, 2020, 2:05:35 PM1/16/20
to biodiver...@googlegroups.com
Hi!
I've tried and I think that the resolutuion of 0,009 makes a very little squares. 0,09 isn't bad at all.
Do you know how can we check if the resolution of 1 is 111 Km?
PD: I think my data is like yours. Latitude and longitude WGSA84.
Thank you!
El jue., 16 ene. 2020 17:58, Dillon Jones <dillj...@gmail.com> escribió:
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/CAJOWYY2oF6Ddjoih%3DsbygEoHFXNwvgMDPDRFHs%2BkQnMMqpVQUg%40mail.gmail.com.
Shawn Laffan
Jan 16, 2020, 4:13:38 PM1/16/20
to biodiver...@googlegroups.com
Hello Julio,
and thanks Dillon,
The issue with using geographic coordinates (latitude and longitude) is that the true cell size differs depending on the latitude, as the meridians of longitude converge towards the poles.
https://www.usgs.gov/faqs/how-much-distance-does-a-degree-minute-and-second-cover-your-maps
If you are close to the equator then one degree of longitude is approximately 111 km, but at 45 degrees it is approximately 79 km across.
One degree of latitude is the same distance on the ground anywhere, so as you move towards the poles the shape of the cells on the ground becomes rectangular. If your study area is small then the effect of this convergence will be small. Square cells are also not necessarily better than rectangular.
If your input data are points then it is a good idea to project them into a projected coordinate system. QGIS provides many options for this, and a fuller list is at http://epsg.io/ It is hard to suggest one to use without knowing the region your data are from.
WRT the exports, you could also try GeoTIFF if you want a raster format. It will generate one file for each index in the list you export.
Could you provide more details about how you did the shapefile export?
Regards,
Shawn.
and thanks Dillon,
The issue with using geographic coordinates (latitude and longitude) is that the true cell size differs depending on the latitude, as the meridians of longitude converge towards the poles.
https://www.usgs.gov/faqs/how-much-distance-does-a-degree-minute-and-second-cover-your-maps
If you are close to the equator then one degree of longitude is approximately 111 km, but at 45 degrees it is approximately 79 km across.
One degree of latitude is the same distance on the ground anywhere, so as you move towards the poles the shape of the cells on the ground becomes rectangular. If your study area is small then the effect of this convergence will be small. Square cells are also not necessarily better than rectangular.
If your input data are points then it is a good idea to project them into a projected coordinate system. QGIS provides many options for this, and a fuller list is at http://epsg.io/ It is hard to suggest one to use without knowing the region your data are from.
WRT the exports, you could also try GeoTIFF if you want a raster format. It will generate one file for each index in the list you export.
Could you provide more details about how you did the shapefile export?
Regards,
Shawn.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/CAL3sgmFB8-aZUNM9%3D8djLKgdVc2uh07cyGFa_qg326-AP_04NQ%40mail.gmail.com.

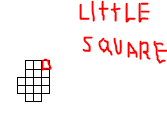{kind=link}
{kind=link}
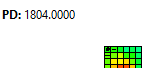{kind=link}
shuiyin liu
Jan 18, 2022, 3:49:05 AM1/18/22
to Biodiverse Users
Hi all,
I'm a new Biodiverse user. I have similar questions with Julio's. Could you please give me some suggestion on them? My research is about the global spatial diversity pattern of a plant genus (distributes globally but mainly in North Hemisphere).
(1) my locations data are in degrees (WGS84), does this mean I need to convert these locations to an equal area projection before loading into Biodiverse? If so, which
projected coordinate system should I use? At the same time, does this mean I also need to convert the shape file (a world map) to the same projected coordinate system when I plot the Biodivese results?
(2) For grid cell, I'm not sure, 50 * 50 km and 100 * 100 km, which could be better for my study area?
Best wishes
Shuiyin
Shawn Laffan
Jan 18, 2022, 6:39:42 PM1/18/22
to biodiver...@googlegroups.com, shuiyin liu
Hello Shuiyin,
Yes, it is usually better to project the data. This is especially the case if you are calculating any of the endemism indices as the ranges are analysed in units of grid cells, for which an equal area projection will ensure they all occupy the same amount of area on the earth's surface. (Although in saying that, it does not correct for cases such as coastal cells which are part land and part water and thus for many taxa will be an overestimate).
A useful projection to try in the first instance is the Mollweide, but there will be others. https://epsg.io/54009
You are also correct that you will also need to project any shapefile you want to display in Biodiverse so its coordinates match your points.
In terms of what cell size to use, it really depends on the spatial density of your data. As a general suggestion, if the extent is global then 100km will probably be sufficient to see many of the patterns. However, if you have good data then why not go finer? If you need smoother patterns to aid interpretation then you can try the moving window spatial conditions like sp_circle() and sp_block().
https://github.com/shawnlaffan/biodiverse/wiki/SpatialConditions
One additional consideration for cell size is the resultant size of the data sets and how much memory you have available on your computer. For comparison, the data sets in Mishler et al. (2020, https://doi.org/10.1111/jse.12590 ) used ~15GB for display. That was for ~10,000 cells with a tree containing ~20,000 terminals, and multiple display tabs open (each of which needs its own memory allocation). If you do not have a tree then less memory is needed.
Regards,
Shawn.
Yes, it is usually better to project the data. This is especially the case if you are calculating any of the endemism indices as the ranges are analysed in units of grid cells, for which an equal area projection will ensure they all occupy the same amount of area on the earth's surface. (Although in saying that, it does not correct for cases such as coastal cells which are part land and part water and thus for many taxa will be an overestimate).
A useful projection to try in the first instance is the Mollweide, but there will be others. https://epsg.io/54009
You are also correct that you will also need to project any shapefile you want to display in Biodiverse so its coordinates match your points.
In terms of what cell size to use, it really depends on the spatial density of your data. As a general suggestion, if the extent is global then 100km will probably be sufficient to see many of the patterns. However, if you have good data then why not go finer? If you need smoother patterns to aid interpretation then you can try the moving window spatial conditions like sp_circle() and sp_block().
https://github.com/shawnlaffan/biodiverse/wiki/SpatialConditions
One additional consideration for cell size is the resultant size of the data sets and how much memory you have available on your computer. For comparison, the data sets in Mishler et al. (2020, https://doi.org/10.1111/jse.12590 ) used ~15GB for display. That was for ~10,000 cells with a tree containing ~20,000 terminals, and multiple display tabs open (each of which needs its own memory allocation). If you do not have a tree then less memory is needed.
Regards,
Shawn.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/a27b65da-33f1-4ad0-bca4-80cad88aee15n%40googlegroups.com.
-- Prof Shawn Laffan, FMSSANZ School of Biological, Earth and Environmental Sciences UNSW, Sydney 2052, Australia Tel +61 2 9065 5607 https://www.bees.unsw.edu.au/our-people/shawn-laffan https://shawnlaffan.github.io/biodiverse (free diversity analysis software) International Journal of Geographical Information Science http://www.tandf.co.uk/journals/ijgis UNSW CRICOS Provider Code 00098G
shuiyin liu
Jan 18, 2022, 7:56:11 PM1/18/22
to Biodiverse Users
Dear Shawn,
Thanks a lot for your detailed and helpful suggestions on all of my questions! I will try to do later accordingly.
By the way, I noticed that http://epsg.io/6933 and http://epsg.io/3410 seem also to be worldwidely equal area projections. What's the difference between them and the Mollweide? or they are similar? which one is more common one to be used?
All the best,
Shuiyin
Shawn Laffan
Jan 18, 2022, 8:24:26 PM1/18/22
to biodiver...@googlegroups.com
The EASE-Grid 2.0 projection will also work.
Note that EPSG:3410 is version 1 and has been superseded (see note in http://epsg.io/3410 and details in Brodzic et al., 2012, https://www.mdpi.com/2220-9964/1/1/32/htm ).
Reading those docs, EASE is more complex than Mollweide. The main difference seems to be that the EASE method uses a cylindrical projection for mid to low latitudes and Lambert (conical) projections for polar regions. In comparison, Mollweide uses a single pseudocylindrical projection for all locations. It is worth remembering that the complexity is not much of an issue as it is handled by the GIS software.
https://proj.org/operations/projections/moll.html
There is also the equal earth projection that might be relevant.
https://proj.org/operations/projections/eqearth.html
And perhaps also have a look at the list of systems supported by the Proj library (used by QGIS), although maybe then there will be too much choice...
https://proj.org/operations/projections/index.html
Regards,
Shawn.
Note that EPSG:3410 is version 1 and has been superseded (see note in http://epsg.io/3410 and details in Brodzic et al., 2012, https://www.mdpi.com/2220-9964/1/1/32/htm ).
Reading those docs, EASE is more complex than Mollweide. The main difference seems to be that the EASE method uses a cylindrical projection for mid to low latitudes and Lambert (conical) projections for polar regions. In comparison, Mollweide uses a single pseudocylindrical projection for all locations. It is worth remembering that the complexity is not much of an issue as it is handled by the GIS software.
https://proj.org/operations/projections/moll.html
There is also the equal earth projection that might be relevant.
https://proj.org/operations/projections/eqearth.html
And perhaps also have a look at the list of systems supported by the Proj library (used by QGIS), although maybe then there will be too much choice...
https://proj.org/operations/projections/index.html
Regards,
Shawn.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/78886786-a17f-42a4-aa86-4544b747a247n%40googlegroups.com.
shuiyin liu
Jan 18, 2022, 10:06:46 PM1/18/22
to Biodiverse Users
Hi
Shawn,
Thank you so much! I think I get it now!
Best,
Shuiyin
Shawn Laffan
Jan 18, 2022, 11:28:31 PM1/18/22
to biodiver...@googlegroups.com
You're welcome Shuiyin,
Please do ask more questions if you need further help.
Regards,
Shawn.
Please do ask more questions if you need further help.
Regards,
Shawn.
To view this discussion on the web visit https://groups.google.com/d/msgid/biodiverse-users/8877d3ba-8673-4243-9d5c-7cbfd8375bc4n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages